自从Julia语言世界上的上一本书出版以来,发生了很多有趣的事情:
同时,开发者的兴趣显着增加,这可以通过丰富的基准测试来表示:
我们只是为新的便捷工具而高兴,并继续对其进行研究。 今晚将致力于文本分析,本着莎士比亚和朱莉娅程序员的精神在总统的讲话中寻找隐藏的含义并生成文本,而对于甜点,我们则提供了一个由40,000人组成的循环网络。
最近,在哈布雷(Habré)上,对Julia的包装进行了审核,从而可以在NLP - Julia NLP领域进行研究。 我们处理文本 。 因此,让我们立即开始工作,从TextAnalysis包开始。
TextAnalisys
给出一些文本,我们将其表示为字符串文档:
using TextAnalysis str = """ Ich mag die Sonne, die Palmen und das Meer, Ich mag den Himmel schauen, den Wolken hinterher. Ich mag den kalten Mond, wenn der Vollmond rund, Und ich mag dich mit einem Knebel in dem Mund. """; sd = StringDocument(str)
StringDocument{String}("Ich mag die ... dem Mund.\n", TextAnalysis.DocumentMetadata(Languages.Default(), "Untitled Document", "Unknown Author", "Unknown Time"))
为了方便处理大量文档,可以更改字段(例如标题),并且为了简化处理,我们可以删除标点符号和大写字母:
title!(sd, "Knebel") prepare!(sd, strip_punctuation) remove_case!(sd) text(sd)
"ich mag die sonne die palmen und das meer \nich mag den himmel schauen den wolken hinterher \nich mag den kalten mond wenn der vollmond rund \nund ich mag dich mit einem knebel in dem mund \n"
这使您可以为单词构建整齐的n-gram :
dict1 = ngrams(sd) Dict{String,Int64} with 26 entries: "dem" => 1 "himmel" => 1 "knebel" => 1 "der" => 1 "schauen" => 1 "mund" => 1 "rund" => 1 "in" => 1 "mond" => 1 "dich" => 1 "einem" => 1 "ich" => 4 "hinterher" => 1 "wolken" => 1 "den" => 3 "das" => 1 "palmen" => 1 "kalten" => 1 "mag" => 4 "sonne" => 1 "vollmond" => 1 "die" => 2 "mit" => 1 "meer" => 1 "wenn" => 1 "und" => 2
显然,标点符号和带大写字母的单词在词典中将是独立的单元,这将干扰对文本中特定术语的出现频率的定性评估,因此我们将其删除。 对于n-gram,很容易找到许多有趣的应用,例如,可以将它们用于文本的模糊搜索 ,但是由于我们只是游客,因此我们将通过玩具示例,即使用马尔可夫链生成文本
Procházenímodelovéhografu
马尔可夫链是马尔可夫过程的离散模型,其特征在于系统中的更改仅考虑其(模型)先前状态。 形象地说,人们可以把这种结构看作是概率性的细胞自动机。 N-grams与这个概念相当共存:词典中的任何单词都与其他不同厚度的连接相关联,这取决于文本中特定单词对(grams)的出现频率。

字符串“ ABABD”的马尔可夫链
算法本身的实现已经是当晚的绝佳活动,但是Julia已经有了一个出色的Markovify软件包,该软件包正是出于这些目的而创建的。 仔细浏览捷克语手册 ,我们进行语言处理。
将文字分解为标记(例如单词)
using Markovify, Markovify.Tokenizer tokens = tokenize(str, on = words) 2-element Array{Array{String,1},1}: ["Ich", "mag", "die", "Sonne,", "die", "Palmen", "und", "das", "Meer,", "Ich", "mag", "den", "Himmel", "schauen,", "den", "Wolken", "hinterher."] ["Ich", "mag", "den", "kalten", "Mond,", "wenn", "der", "Vollmond", "rund,", "Und", "ich", "mag", "dich", "mit", "einem", "Knebel", "in", "dem", "Mund."]
我们组成一阶模型(仅考虑最近的邻居):
mdl = Model(tokens; order=1) Model{String}(1, Dict(["dich"] => Dict("mit" => 1),["den"] => Dict("Himmel" => 1,"kalten" => 1,"Wolken" => 1),["in"] => Dict("dem" => 1),["Palmen"] => Dict("und" => 1),["wenn"] => Dict("der" => 1),["rund,"] => Dict("Und" => 1),[:begin] => Dict("Ich" => 2),["Vollmond"] => Dict("rund," => 1),["die"] => Dict("Sonne," => 1,"Palmen" => 1),["kalten"] => Dict("Mond," => 1)…))
然后,我们基于提供的模型来实现生成短语的功能。 实际上,它需要一个模型,一种解决方法以及您想要获得的短语数量:
代号 function gensentences(model, fun, n) sentences = []
程序包的开发人员提供了两个绕过功能: walk和walk2 (第二个功能工作时间更长,但是提供了更多独特的设计),您始终可以确定自己的选择。 让我们尝试一下:
gensentences(mdl, walk, 4) 4-element Array{Any,1}: "Ich mag den Wolken hinterher." "Ich mag die Palmen und das Meer, Ich mag den Himmel schauen, den Wolken hinterher." "Ich mag den Wolken hinterher." "Ich mag die Palmen und das Meer, Ich mag dich mit einem Knebel in dem Mund." gensentences(mdl, walk2, 4) 4-element Array{Any,1}: "Ich mag den Wolken hinterher." "Ich mag dich mit einem Knebel in dem Mund." "Ich mag den Himmel schauen, den kalten Mond, wenn der Vollmond rund, Und ich mag den Wolken hinterher." "Ich mag die Sonne, die Palmen und das Meer, Ich mag dich mit einem Knebel in dem Mund."
当然,尝试俄语文本,尤其是白色经文,极有诱惑力。 对于俄语,由于其复杂性,大多数短语都不可读。 另外,正如已经提到的 ,特殊字符需要特别注意,因此,我们要么保存用于收集以UTF-8编码的文本的文档,要么使用其他工具 。
在他姐姐的建议下,清除了几本Oster的书中的特殊字符和任何分隔符,并为n-gram设置了第二顺序,我得到了以下措词单元:
", !" ". , : !" ", , , , ?" " !" ". , !" ". , ?" " , !" " ?" " , , ?" " ?" ", . ?"
她保证通过这种技术可以在女性大脑中构造思想…………哼,我是谁?
分析一下
在TextAnalysis程序包的目录中,您可以找到文本数据的示例,其中之一是美国总统在国会之前的讲话集。

代号 using TextAnalysis, Clustering, Plots
29-element Array{String,1}: "Bush_1989.txt" "Bush_1990.txt" "Bush_1991.txt" "Bush_1992.txt" "Bush_2001.txt" "Bush_2002.txt" "Bush_2003.txt" "Bush_2004.txt" "Bush_2005.txt" "Bush_2006.txt" "Bush_2007.txt" "Bush_2008.txt" "Clinton_1993.txt" ⋮ "Clinton_1998.txt" "Clinton_1999.txt" "Clinton_2000.txt" "Obama_2009.txt" "Obama_2010.txt" "Obama_2011.txt" "Obama_2012.txt" "Obama_2013.txt" "Obama_2014.txt" "Obama_2015.txt" "Obama_2016.txt" "Trump_2017.txt"
阅读这些文件并从中形成军团并将其清除为标点符号后,我们将复查所有演讲的一般词汇:
代号 crps = DirectoryCorpus(pth) standardize!(crps, StringDocument) crps = Corpus(crps[1:29]);
remove_case!(crps) prepare!(crps, strip_punctuation) update_lexicon!(crps) update_inverse_index!(crps) lexicon(crps)
Dict{String,Int64} with 9078 entries: "enriching" => 1 "ferret" => 1 "offend" => 1 "enjoy" => 4 "limousines" => 1 "shouldn" => 21 "fight" => 85 "everywhere" => 17 "vigilance" => 4 "helping" => 62 "whose" => 22 "'" => 725 "manufacture" => 3 "sleepless" => 2 "favor" => 6 "incoherent" => 1 "parenting" => 2 "wrongful" => 1 "poised" => 3 "henry" => 3 "borders" => 30 "worship" => 3 "star" => 10 "strand" => 1 "rejoin" => 3 ⋮ => ⋮
看看哪些文档包含特定词可能会很有趣,例如,看看我们如何处理承诺:
crps["promise"]' 1×24 LinearAlgebra.Adjoint{Int64,Array{Int64,1}}: 1 2 3 4 6 7 9 10 11 12 15 … 21 22 23 24 25 26 27 28 29 crps["reached"]' 1×7 LinearAlgebra.Adjoint{Int64,Array{Int64,1}}: 12 14 15 17 19 20 22
或代词频率:
lexical_frequency(crps, "i"), lexical_frequency(crps, "you") (0.010942182388035081, 0.005905479339070189)
所以大概 科学家和强奸记者 对正在研究的数据有一种错误的态度。
矩阵
真正的分布语义始于文本,克和标记变成矢量和矩阵 。
术语文档矩阵( DTM )是具有大小的矩阵 在哪里 -案件中的文件数量,以及 -语料库字典大小,即 在我们的语料库中找到的单词(唯一)的数量。 在第i行中,矩阵的第j列是一个数字-在第i个文本中找到第j个单词的次数。
代号 dtm1 = DocumentTermMatrix(crps)
D = dtm(dtm1, :dense) 29×9078 Array{Int64,2}: 0 0 1 4 0 0 0 0 0 0 0 0 0 … 1 0 0 16 0 0 0 0 0 0 0 1 4 0 0 0 0 0 0 0 0 0 1 0 0 4 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 3 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 6 5 8 0 0 0 0 0 0 0 0 0 0 0 0 10 38 0 0 0 0 0 3 0 0 0 0 0 0 0 0 5 0 … 0 0 0 22 0 0 0 0 0 0 0 12 4 2 0 0 0 0 0 1 3 0 0 0 0 41 0 0 0 0 0 0 0 1 1 2 1 0 0 0 0 0 5 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 44 0 0 0 0 0 0 0 2 1 1 0 0 0 0 0 0 2 0 0 0 67 0 0 14 1 1 31 2 0 8 2 1 1 0 0 0 0 0 4 0 … 0 0 0 50 0 0 0 0 0 2 0 3 3 0 2 0 0 0 0 0 2 1 0 0 0 11 0 0 0 0 0 0 0 8 3 6 3 0 0 0 0 0 0 0 1 0 0 4 0 0 0 0 0 ⋮ ⋮ ⋮ ⋱ ⋮ ⋮ 0 1 11 5 3 3 0 0 0 1 0 1 0 1 0 0 44 0 0 0 0 0 0 0 11 5 4 5 0 0 0 0 0 1 0 1 0 0 48 0 0 0 0 0 0 0 18 6 8 4 0 0 0 0 0 0 1 1 0 0 80 0 0 0 0 0 0 0 1 2 0 0 0 0 0 0 0 0 0 … 0 0 0 26 0 0 0 0 0 1 0 4 5 5 1 0 0 0 0 0 1 0 0 0 45 0 0 0 0 0 1 1 0 8 2 1 3 0 0 0 0 0 2 0 0 0 47 0 0 170 11 11 1 0 0 7 1 1 1 0 0 0 0 0 0 0 0 0 3 2 0 208 2 2 0 1 0 5 2 0 1 1 0 0 0 0 1 0 0 0 41 0 0 122 7 7 1 0 0 4 3 4 1 0 0 0 0 0 0 0 … 0 0 62 0 0 173 11 11 7 2 0 6 0 0 0 0 0 0 0 0 3 0 0 0 0 0 0 0 0 0 0 0 0 3 0 3 0 0 0 0 0 0 0 0 0 0 0 35 0 0 0 0 0 1 0 2 2 0 2 0 0 0 0 0 1 0 0 0 0 30 0 0 0 0 0
这里的原始单位是术语
m.terms[3450:3465] 16-element Array{String,1}: "franklin" "frankly" "frankness" "fraud" "frayed" "fraying" "fre" "freak" "freddie" "free" "freed" "freedom" "freedoms" "freely" "freer" "frees"
等一下...
crps["freak"] 1-element Array{Int64,1}: 25 files[25] "Obama_2013.txt"
有必要更详细地阅读...
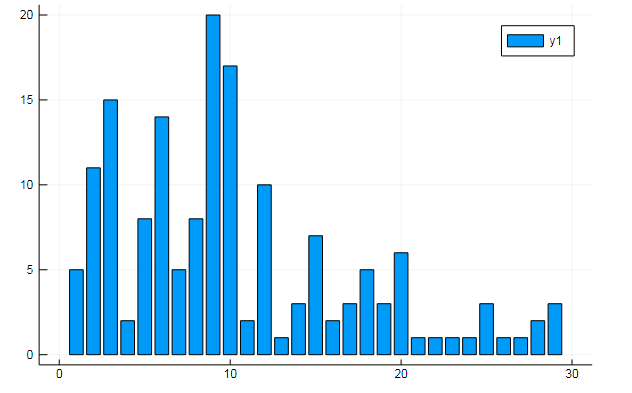
您还可以从术语矩阵中提取各种有趣的数据。 说出文档中特定单词的出现频率
w1, w2 = dtm1.column_indices["freedom"], dtm1.column_indices["terror"] (3452, 8101)
D[:, w1] |> bar
D[:, w1] |> bar
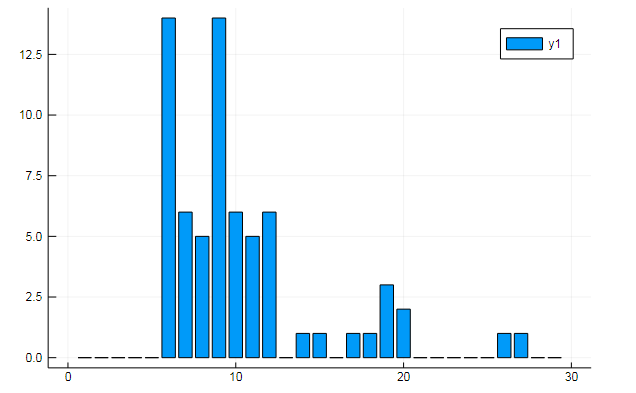
或有关某些隐藏主题的文档的相似性:
k = 3

这些图表显示了演讲中三个主题的披露方式
或按主题对单词进行聚类 ,例如,词汇的相似性以及不同文档中某些主题的偏好
T = tf_idf(D) cl = kmeans(T, 5)
s1 = scatter(T[10, 1:10:end], assign, yaxis = "Bush 2006") s2 = scatter(T[29, 1:10:end], assign, yaxis = "Obama 2016") s3 = scatter(T[30, 1:10:end], assign, yaxis = "Trump 2017") plot(s1, s2, s3, layout = (3,1), legend=false )
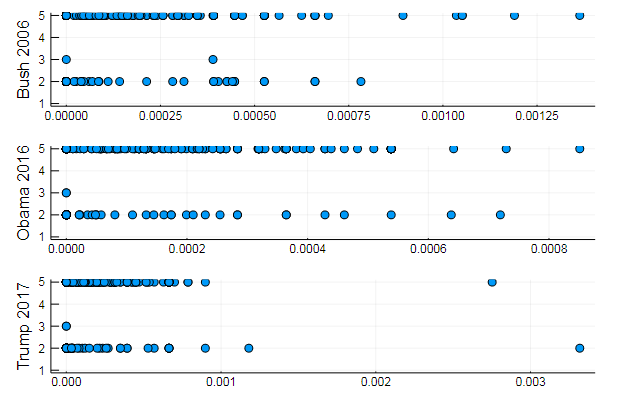
非常自然的结果,相同类型的表演。 实际上,NLP是一门有趣的科学,您可以从正确准备的数据中提取很多有用的信息:您可以在该资源上找到许多示例( 注释中作者的认可 ,LDA的使用等)。
好吧,以免走得太远,我们将为理想的总统生成一些短语:
代号 function loadfiles(filenames) return ( open(filename) do file text = read(file, String)
7-element Array{Any,1}: "I want harmony and fathers, sons and we mark the jobkilling TransPacific Partnership." "I am asking all across our partners must be one very happy, indeed." "At the health insurance and terrorismrelated offenses since my Inauguration, and the future and pay their jobs, their community." "Millions lifted from this Nation, and Jessica Davis." "It will expand choice, increase access, lower the Director of our aspirations, not working." "We will defend our freedom." "The challenges we will celebrate the audience tonight, has come for a record."
长期记忆
好吧,没有神经网络怎么可能! 他们以更快的速度在这一领域收集桂冠,朱莉娅语言的环境在各个方面都对此做出了贡献。 出于好奇,您可以建议使用Knet软件包,该软件包与我们之前检查过的Flux不同,它不能与神经网络体系结构作为模块的构造函数一起使用,而在大多数情况下可以与迭代器和流一起使用。 这可能具有学术兴趣,有助于更深入地了解学习过程,并且还可以提供高性能的计算。 通过单击上面提供的链接,您将找到指导,示例和自学材料(例如,它显示了如何在循环网络上创建莎士比亚文本生成器或法律代码)。 但是,Knet软件包的某些功能仅针对GPU实现,因此,现在让我们继续围绕Flux运行。
递归网络操作的典型示例之一通常是莎士比亚十四行诗被象征性地馈送的模型:
QUEN: Chiet? The buswievest by his seld me not report. Good eurronish too in me will lide upon the name; Nor pain eat, comes, like my nature is night. GRUMIO: What for the Patrople: While Antony ere the madable sut killing! I think, bull call. I have what is that from the mock of France: Then, let me? CAMILLE: Who! we break be what you known, shade well? PRINCE HOTHEM: If I kiss my go reas, if he will leave; which my king myself. BENEDICH: The aunest hathing rouman can as? Come, my arms and haste. This weal the humens? Come sifen, shall as some best smine? You would hain to all make on, That that herself: whom will you come, lords and lafe to overwark the could king to me, My shall it foul thou art not from her. A time he must seep ablies in the genely sunsition. BEATIAR: When hitherdin: so like it be vannen-brother; straight Edwolk, Wholimus'd you ainly. DUVERT: And do, still ene holy break the what, govy. Servant: I fearesed, Anto joy? Is it do this sweet lord Caesar: The dece
如果您斜视而不懂英语,那么这出戏似乎很真实 。

俄语更容易理解
但是,尝试强大的功能会更有趣,尽管在词法上很难,但是您可以使用更多原始文献作为数据,即最近被称为现代诗歌的前卫潮流-押韵。
资料收集
馅饼和粉末-有节奏的四行诗,通常没有韵律,以小写字母键入,没有标点符号。
选择权在管理员hior同志的poetory.ru网站上。 对数据请求的长期缺乏响应是开始研究站点解析的原因。 快速浏览HTML教程可以使您对网页的设计有基本的了解。 接下来,我们找到在这些领域工作的Julia语言的方法:

然后,我们实现一个脚本,该脚本可以翻页诗歌并将其保存到文本文档中:
代号 using HTTP, Gumbo, Cascadia function grabit(npages) str = "" for i = 1:npages url = "https://poetory.ru/por/rating/$i"
更详细地说,它是在Jupiter笔记本电脑中拆卸的。 让我们在一行中收集馅饼和火药:
str = read("pies.txt", String) * read("poroh.txt", String); length(str)
并查看使用的字母:
prod(sort([unique(str)..., '_']) )

开始该过程之前,请检查下载的数据。
啊啊啊,真可耻! 一些用户违反了规则(有时人们只是通过在这些数据中制造噪音来表达自己)。 因此,我们将从垃圾中清除符号包
str = lowercase(str)
根据rssdev10的建议,使用正则表达式修改代码
有一个更可接受的字符集。 当今最大的启示是,从机器代码的角度来看,至少存在三个不同的空间-数据猎人很难生存。

现在,您可以将Flux与随后的数据以onehot向量的形式进行连接:
助焊剂发挥作用 using Flux using Flux: onehot, chunk, batchseq, throttle, crossentropy using StatsBase: wsample using Base.Iterators: partition texta = collect(str) println(length(texta))
我们从几个LSTM层,一个完全连接的感知器和softmax以及日常琐事以及损失函数和优化器中设置模型:
代号 m = Chain( LSTM(N, 256), LSTM(256, 128), Dense(128, N), softmax)
该模型已经准备好进行培训,因此,通过运行下面的代码行,您可以开展自己的业务,其成本根据计算机的功能来选择。 就我而言,这是两次关于哲学的讲座,由于一些该死的事情,这些讲座在深夜传给了我们...
@time Flux.train!(loss, params(m), zip(Xs, Ys), opt, cb = throttle(evalcb, 30))
组装好样品生成器后,您就可以开始收获劳动成果。
电磁发生器 function sample(m, alphabet, len)
由于期望值过高,有些失望。 尽管网络的输入端只有一个字符序列,并且只能以它们相遇的频率进行操作,但它完全抓住了数据集的结构,挑出了一些单词的外表,甚至在某些情况下甚至表现出保持节奏的能力。 可能, 语义相似性的识别将有助于改进。

训练有素的网络的权重可以保存到磁盘,然后轻松读取
weights = Tracker.data.(params(model)); using BSON: @save
散文也只有抽象的网络迷幻感出现。 已经尝试改善网络的宽度和深度的质量以及数据的多样性和丰富性。 对于给定的文字军,尤其要感谢俄语的最大传播者

! . ? , , , , , , , , . , , , , . , . ? , , , , , ,
但是,如果您在Julia语言的源代码上训练神经网络,那么结果会很酷:
加上元编程的可能性,我们得到了一个可以编写和运行的程序,甚至可能是我们自己的代码! 好吧,否则这将是电影设计师关于黑客的天赐之物。
总的来说,已经开始了,然后如幻想所示。 首先,您应该获得高质量的设备,以便长时间的计算不会扼杀实验的欲望。 其次,我们需要更深入地研究方法和启发式方法,这将使我们能够设计更好,更优化的模型。 在此资源上,可以找到与自然语言处理有关的所有内容,然后有可能教会您的神经网络如何生成诗歌或参加黑客马拉松进行文本分析 。
关于这一点,让我请假。 在云端进行训练的数据, 在 github上列出的清单,在眼睛中燃烧,在鸭子中生鸡蛋,大家晚安!