Infa对于希望深入了解使用Node.js和Event Loop的本质的JS开发人员很有用。 您可以自觉且更灵活地控制程序(Web服务器)的流程。
我根据最近给同事的报告编写了这篇文章。
本文结尾处有一些有用的材料可供独立研究。
Node.js怎么样。 异步功能
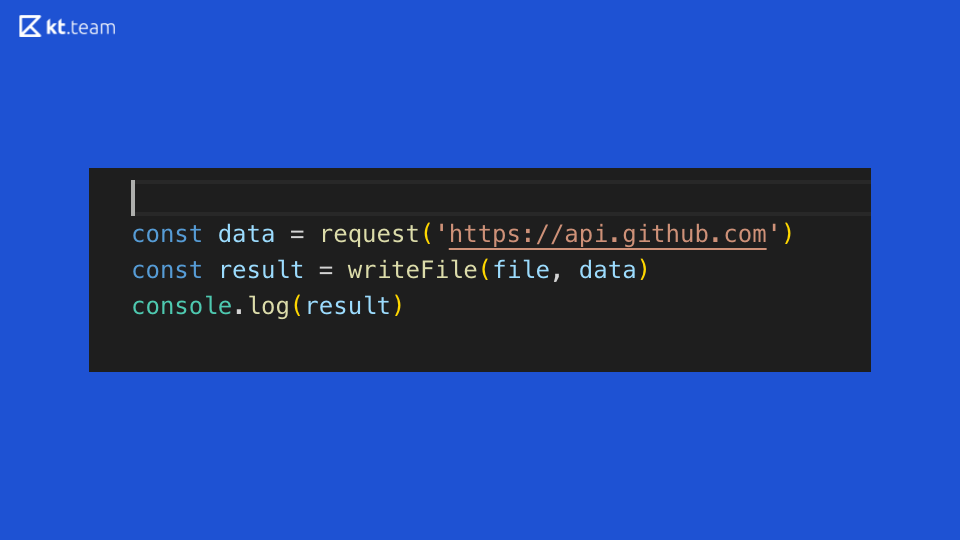
让我们看一下这段代码:它完美地演示了Node.js中代码执行的同步。 在GitHub上的某个地方发出请求,然后读取文件并将结果显示在控制台中。 从这个同步代码中有什么清楚的地方?
假设这是一个在路由器上执行操作的抽象Web服务器。 如果传入请求到达此路由器,我们会进一步发出请求,读取文件,然后将其打印到控制台。 因此,在请求和读取文件上花费的时间,服务器将被阻止,服务器将无法处理任何其他传入请求,也将无法执行其他操作。
解决此问题有哪些选择?
- 多线程
- 非阻塞I / O
对于第一种选择(多线程),Apache vs Nginx Web服务器是一个很好的例子。
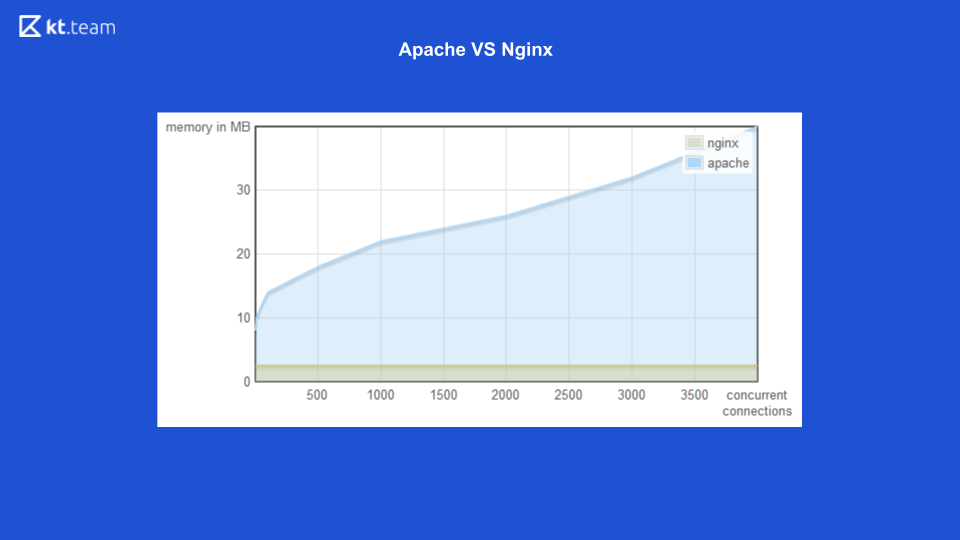
以前,Apache为每个传入的请求提出一个流:有多少个请求,相同数量的线程。 这时,Nginx具有使用非阻塞I / O的优势。 在这里,您可以看到随着传入请求数量的增加,Apache消耗的内存数量也增加了,在下一张幻灯片中,每秒处理的请求数量以及Nginx的连接数量都更高。
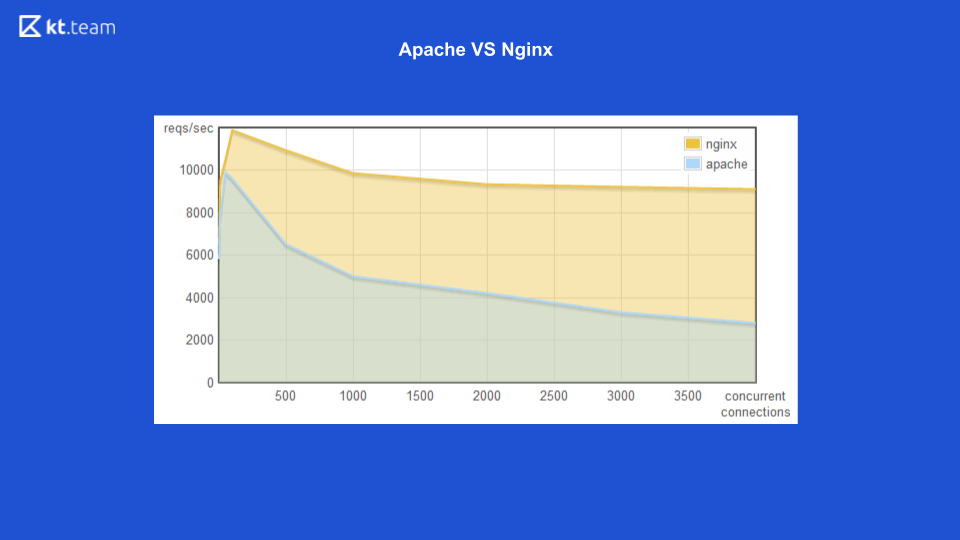
清楚地表明,非阻塞输入/输出效率更高。
借助提供此机制的现代操作系统-事件多路分解器,可以实现无阻塞的输入/输出。
解复用器是一种从应用程序接收请求,注册并执行请求的机制。
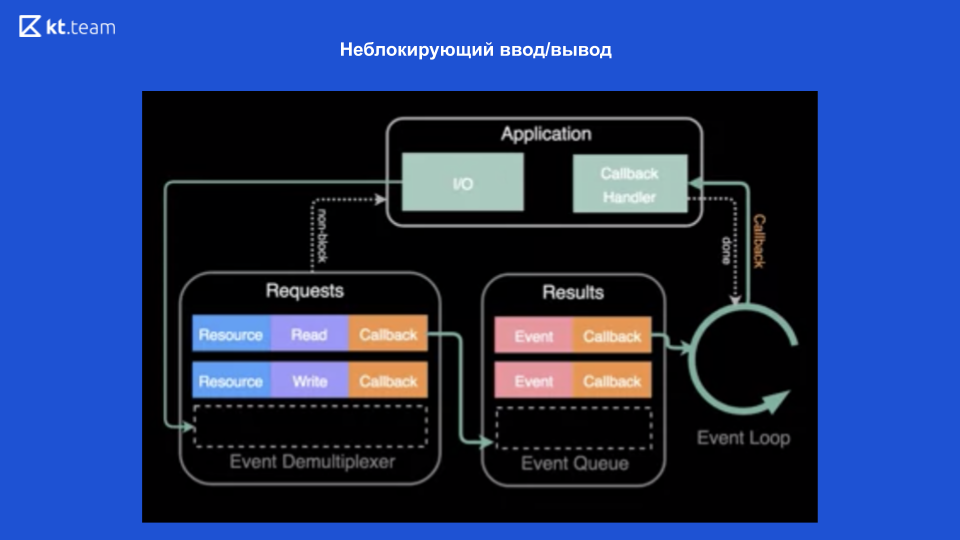
在该图的上部,可以看到我们有一个应用程序,并且在其中执行了操作(让它正在读取文件)。 为此,向事件多路分解器发出请求,在此处发送资源(链接到文件),所需的操作和回调。 事件多路分解器注册该请求并将控制权直接返回给应用程序-因此,它不会被阻塞。 然后,它对文件执行操作,然后,当读取文件时,回调将被注册到执行队列中。 然后,事件循环逐渐同步处理此队列中的每个回调。 然后,将结果返回给应用程序。 进一步(如有必要),将再次进行所有操作。
因此,由于有了这种非阻塞的I / O,Node.js可以是异步的。
我要澄清的是,在这种情况下,正是操作系统为我们提供了非阻塞的输入/输出。 对于非阻塞的输入/输出(通常,原则上是输入/输出操作),我们包含网络请求并处理文件。
这是非阻塞I / O的一般概念。 当机会出现时,Node.js开发人员Ryan Dahl受到Nginx经验的启发,该经验使用了非阻塞I / O,并决定创建一个专门为开发人员设计的平台。 他需要做的第一件事是使用事件多路分解器“结交朋友”他的平台。 问题在于,在每个操作系统中,解复用器的实现方式都不同,他必须编写一个包装器,该包装器后来被称为libuv。 这是一个用C语言编写的库。它提供了一个用于处理这些事件多路分解器的接口。
Libuv库功能
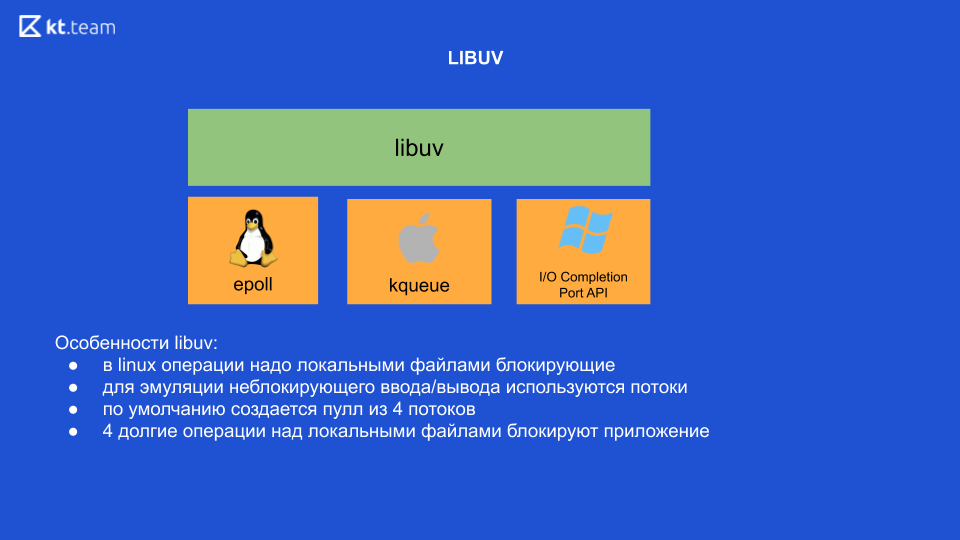
目前,在Linux中,原则上,所有对本地文件的操作都处于阻塞状态。 也就是说,似乎有无阻塞的输入/输出,但是恰恰是在处理本地文件时,操作仍在阻塞。 这就是为什么libuv在内部使用线程来模拟非阻塞I / O的原因。 开箱即用4个线程,在这里我们需要做出最重要的结论:如果我们对本地文件执行4个繁重的操作,相应地,我们将阻止我们的整个应用程序(在Linux上,而其他OS则没有)。
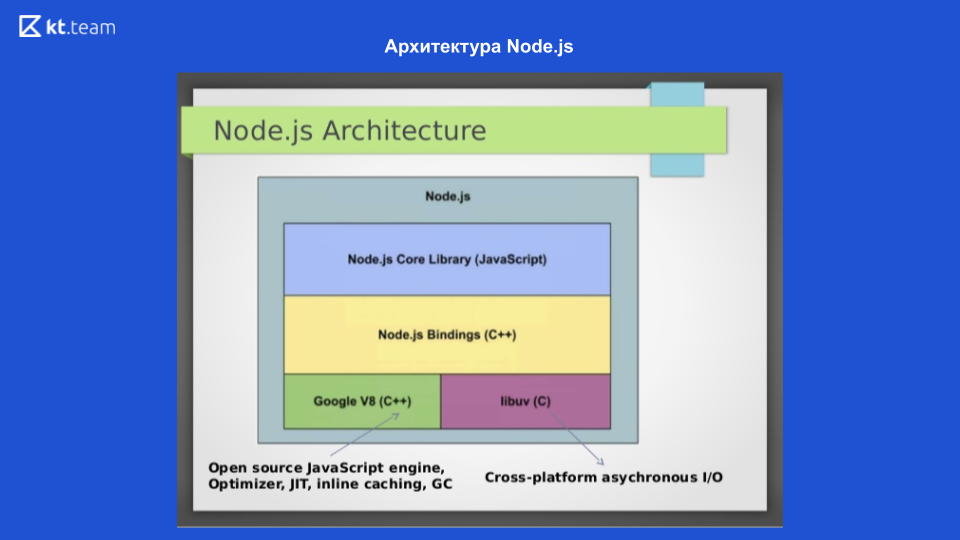
在此幻灯片上,我们看到了Node.js的体系结构。 为了与操作系统交互,使用了用C编写的libuv库。 为了将JavaScript代码编译为机器代码,使用了Google V8引擎,还有一个Node.js Core库,该库包含用于处理网络请求的模块,文件系统和用于日志记录的模块。 由于所有这些相互交互,因此编写了Node.js绑定。 这4个组件构成了Node.js的结构。 事件循环机制本身在libuv中。
事件循环
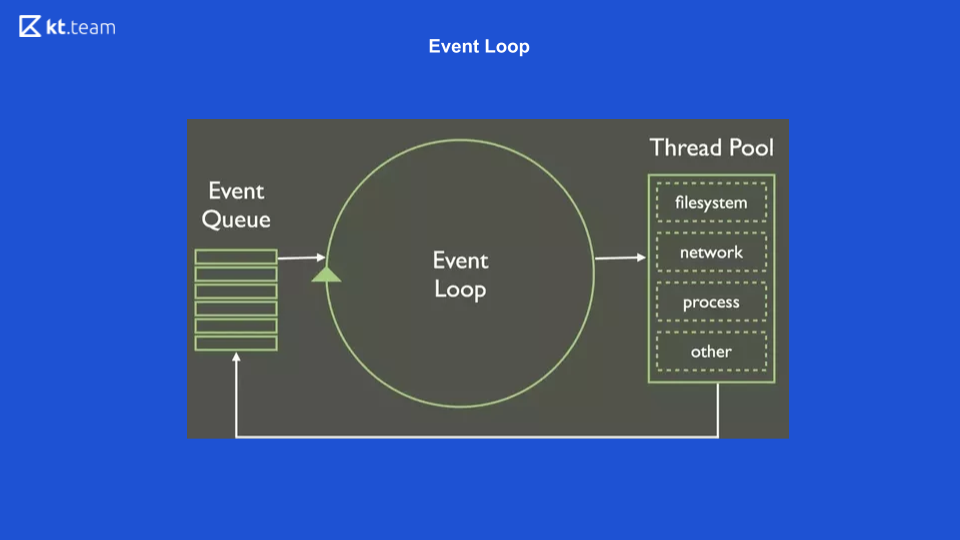
这是事件循环外观的最简单表示。 有一定数量的事件队列,有无数个事件周期,这些事件周期从队列同步执行操作,并将其进一步分配。
这张幻灯片显示了Event Loop在Node.js中的外观。
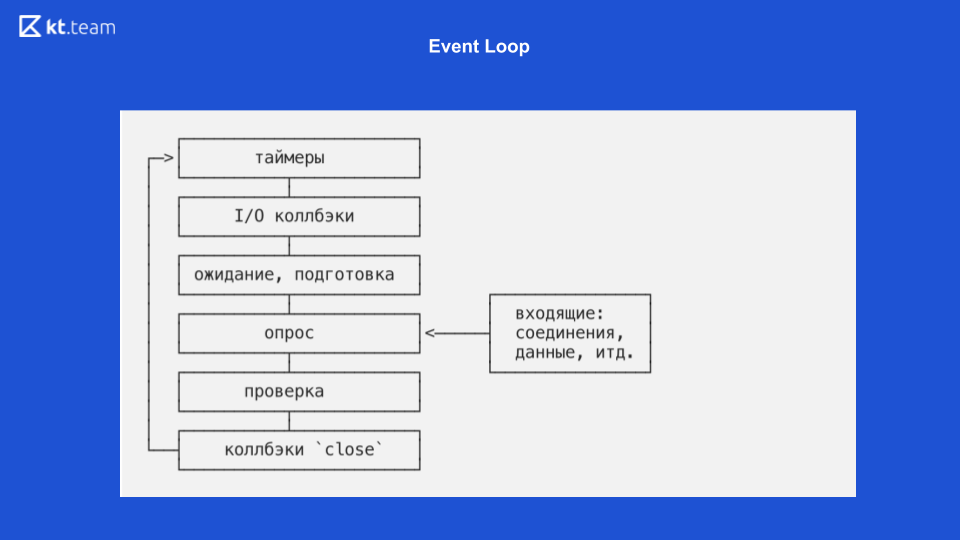
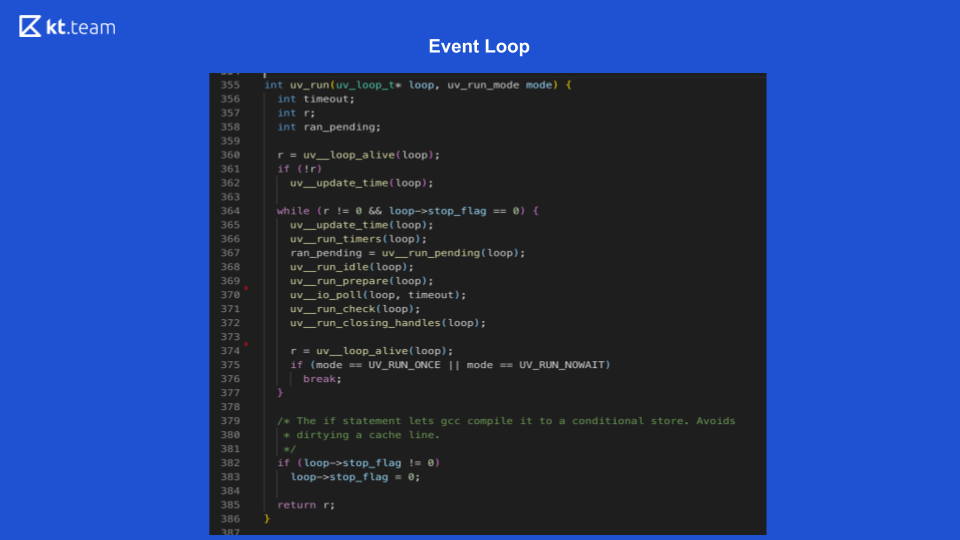
在那里,实现更有趣,更复杂。 本质上,事件循环是事件循环,只要有事情要做,它是无限的。 Node.js中的事件循环分为几个阶段。 (必须将幻灯片8中的阶段与幻灯片9中的源代码进行比较。)
阶段1-计时器
此阶段由事件循环直接执行。 (带有uv_update_time的代码段)-这里事件循环开始工作的时间只是简单地更新。
uv_run_timers-在此方法中,将执行下一个计时器操作。 有一定的堆栈,更确切地说,是一堆计时器,这与计时器所在的队列本质上是相同的。 与事件循环的当前时间相比,将使用时间最短的计时器,如果是执行该计时器的时间,则执行其回调。 在这里值得注意的是,Node.js具有setTimeout的实现,并且有setInterval。 对于libuv,这本质上是相同的,只有setInterval仍然具有重复标志。
因此,如果此计时器具有重复标志,则将其再次放置在事件队列中,然后以相同的方式进行处理。
第2阶段-I / O回调
在这里,我们需要返回有关非阻塞输入/输出的图。
当事件多路分解器读取文件并在回调中排队时,它仅对应于I / O回调阶段。 在这里,回调是针对非阻塞输入/输出执行的,也就是说,这些恰好是在请求数据库或其他资源或读取/写入文件后使用的功能。 它们恰好在此阶段执行。
在幻灯片9中,I / O回调函数的执行从第367行开始:ran_pending = uv_run_pending(循环)。
三相-等待,准备
这些是回调的内部操作,实际上,我们不能间接影响阶段。 有一个process.nextTick,它的回调可能在等待,准备阶段无意中执行。 process.nextTick在当前阶段执行,也就是说,实际上process.nextTick可以在任何阶段都可以工作。 在Node.js的“等待,准备”阶段,没有现成的工具可以运行代码。
在幻灯片9上,行368、369对应于此阶段:
uv_run_idle(循环)-等待;
uv_run_prepare(循环)-准备。
4阶段-调查
这是我们用JS编写的所有代码被执行的地方。 最初,我们发出的所有请求都到达了这里,这是可以阻止Node.js的地方。 如果有繁重的计算操作到这里,那么在此阶段,我们的应用程序可能会冻结并等待直到该操作完成。
在幻灯片9上,轮询功能在第370行:uv_io_poll(循环,超时)。
5阶段-检查
Node.js中有一个setImmediate计时器,其回调在此阶段执行。
在源代码中,这是第371行:uv_run_check(循环)。
6个阶段(最后一个)-回调事件关闭
例如,Web套接字需要关闭连接,在此阶段,将调用此事件的回调。
在源代码中,这是第372行:uv_run_closing_handless(循环)。
最后,事件循环Node.js如下
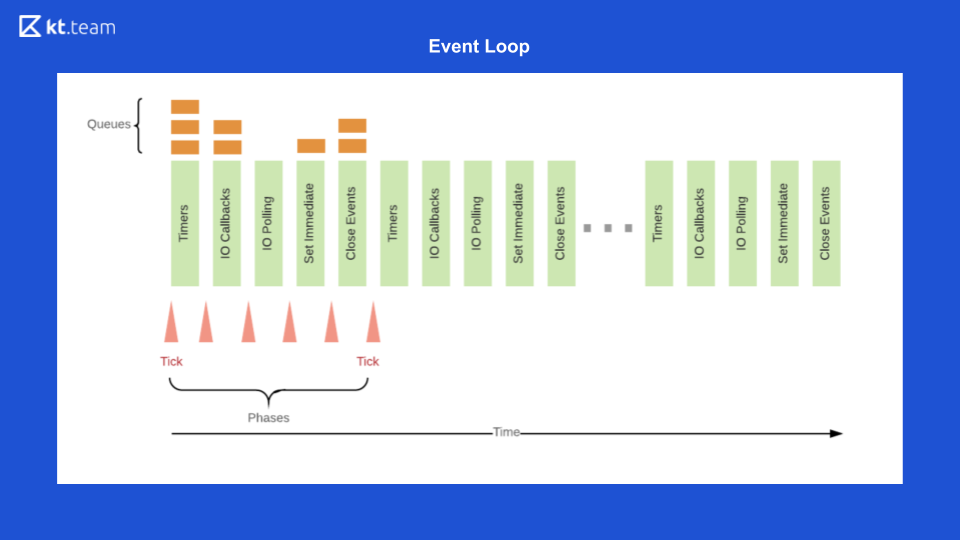
首先,在计时器队列中,执行计时器,该计时器的周期已到。
然后执行I / O回调。
然后,代码是基础,然后是setImmediate和close事件。
在那之后,一切都会重复一圈。 为了演示这一点,我将打开代码。 如何执行?
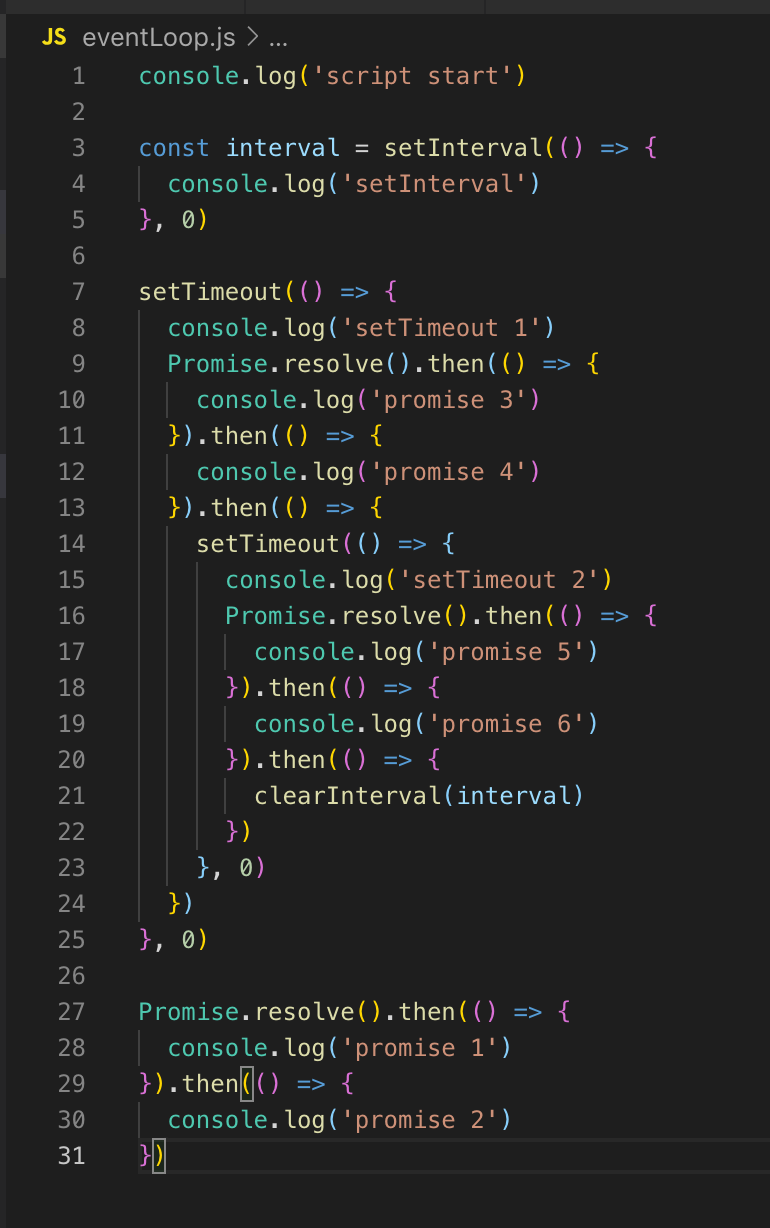
我们没有排队的计时器,因此事件循环继续进行。 也没有I / O回调,因此我们立即进入轮询阶段。 这里所有的代码最初都是在轮询阶段执行的。 因此,首先我们打印script_start,将setInterval放置在计时器队列中(不执行,仅放置)。 setTimeout也放置在计时器队列中,然后执行promise:首先是promise 1,然后是promise 2。
在下一个刻度(事件循环)中,我们返回计时器阶段,在队列中,这里已经有2个计时器:setInterval和setTimeout。 它们都分别延迟了0,可以执行了。
先执行SetInterval(输出到控制台),然后执行setTimeout1。没有非阻塞的I / O回调,然后将在控制台中显示一个轮询阶段,promise 3和promise 4。
接下来,记录setTimeout计时器。 这结束了刻度线,转到下一个刻度线。 再次有计时器,控制台的输出是setInterval和setTimeout 2,然后显示诺言5和诺言6。
我们回顾了事件循环,现在可以更详细地讨论多线程。
线程-worker_threads模块
由于版本10.5中的worker_threads模块,线程已出现在Node.js中。 在第10版中,它仅使用-实验人员键启动,而从第11版开始,无需它就可以启动。
Node.js也有一个集群模块,但是它不引发线程-它引发了更多的进程。 应用程序可伸缩性是其主要目标。
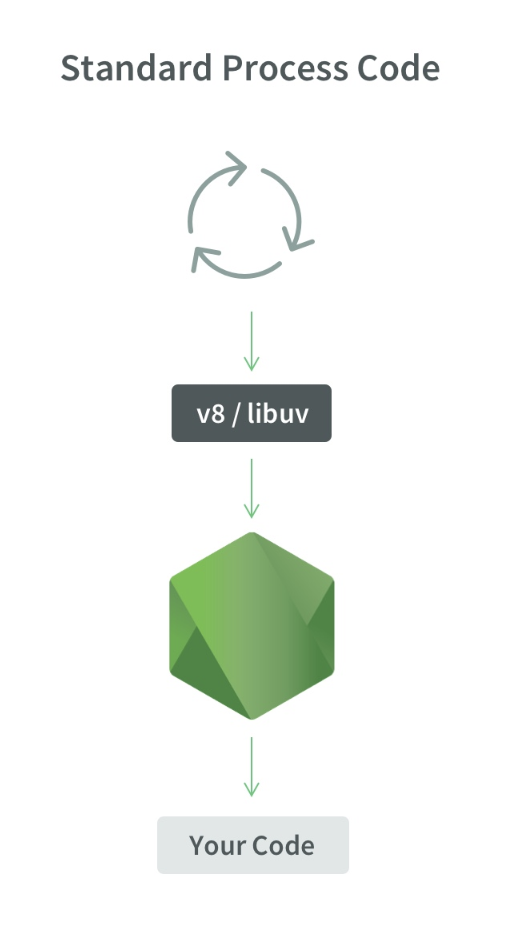
1个过程是什么样的:
1个Node.js进程,1个线程,1个事件循环,1个V8引擎和libuv。
如果我们启动X个线程,则它看起来像这样:
1个Node.js进程,X个线程,X个事件循环,X个V8引擎和X个libuv。
示意图如下
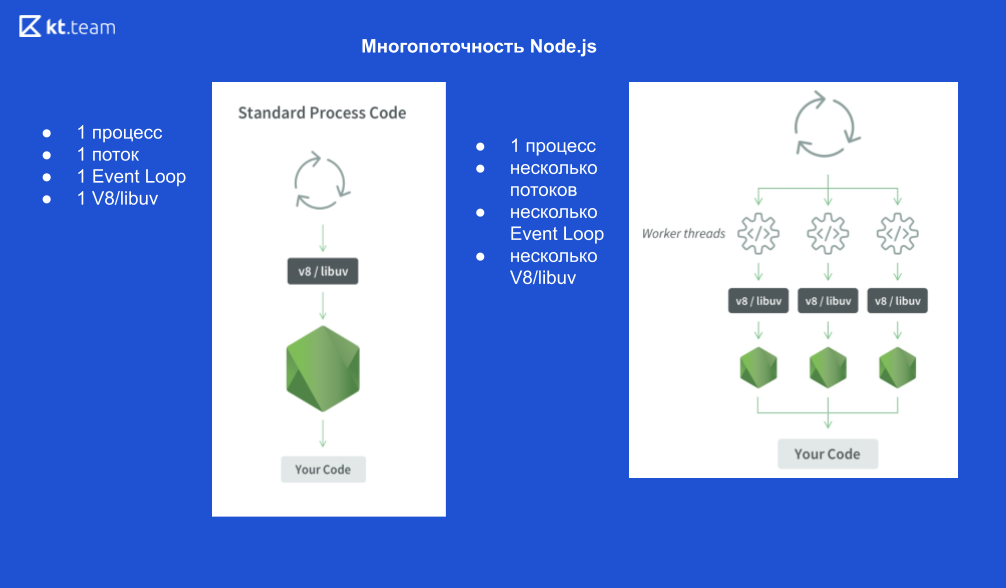
让我们举个例子。
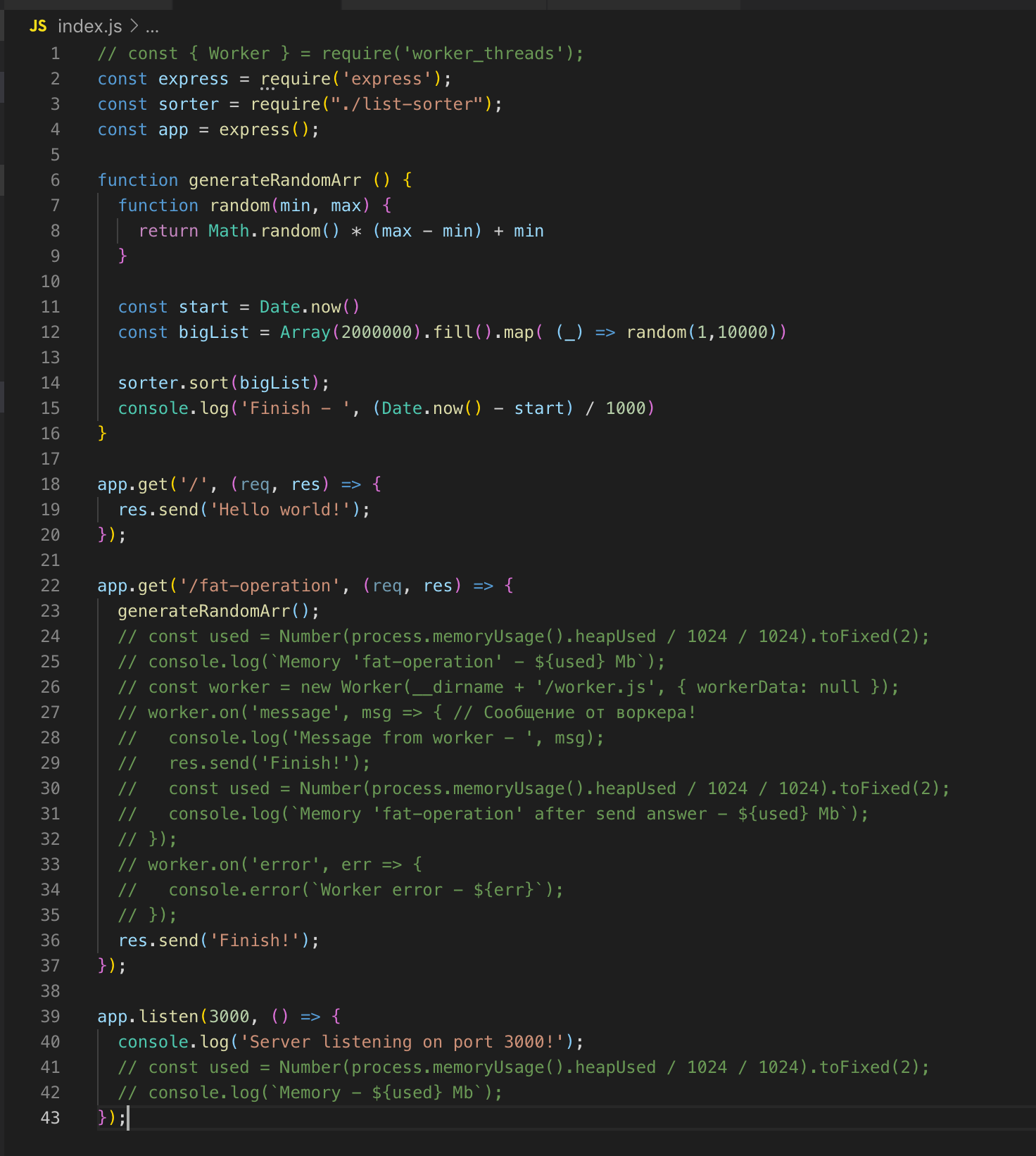
Express上最简单的Web服务器。 有2条路线'a-/和/ /胖操作。
还有一个generateRandomArr()函数。 她用200万条记录填充数组并对其进行排序。 让我们启动服务器。
我们要求进行/肥大手术。 并且在执行对数组进行排序的操作时,我们发送了另一个请求以路由/,但是要获得答案,我们必须等到对数组进行排序。 这是经典的单线程实现。 现在,我们连接worker_threads模块。
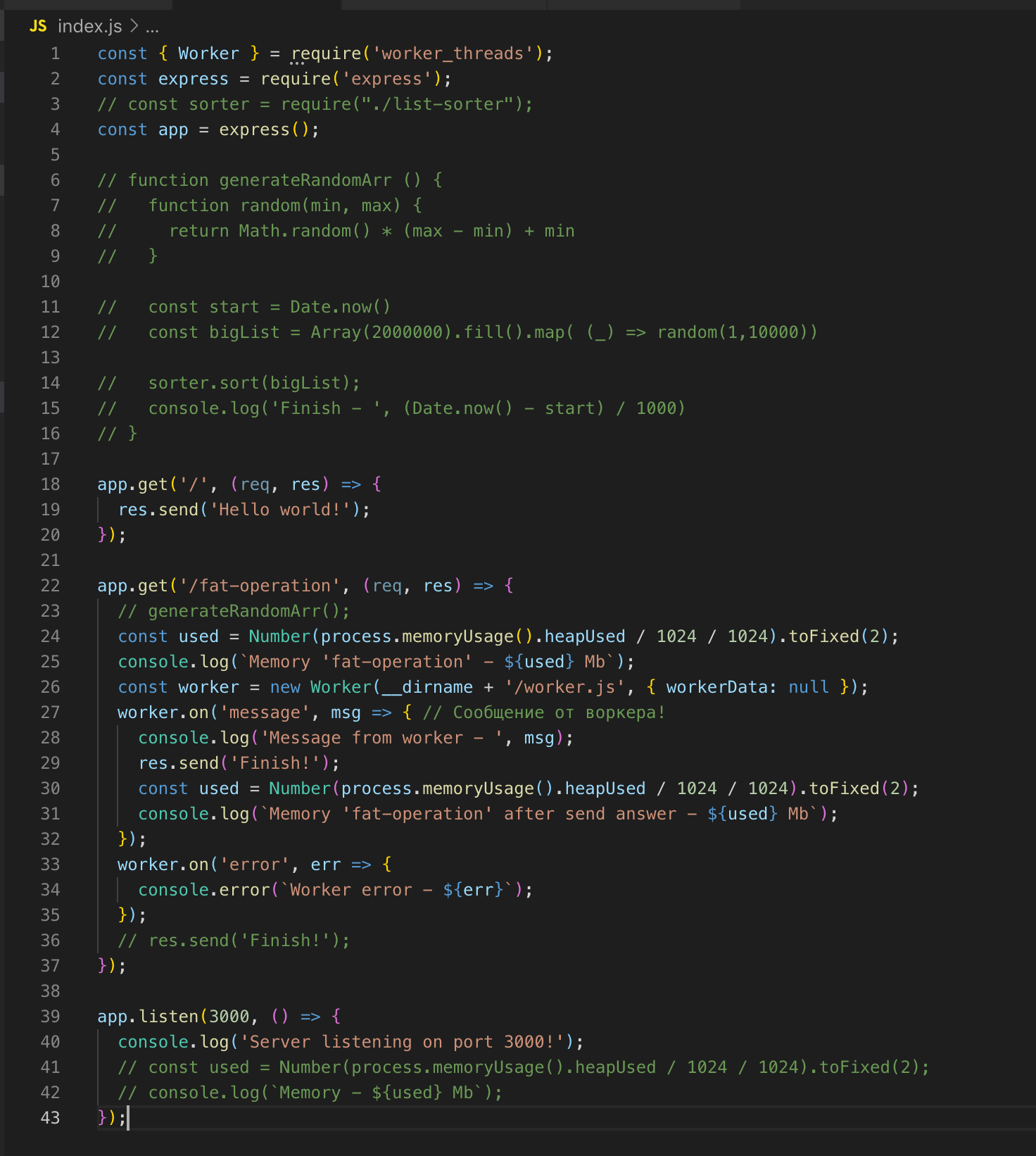
我们先请求/胖操作,然后再请求-,然后立即得到答案-世界您好!
对于对数组进行排序的操作,我们提出了一个单独的线程,该线程具有其自己的Event Loop实例,并且不影响主线程中代码的执行。
没有执行操作的线程将被“破坏”。
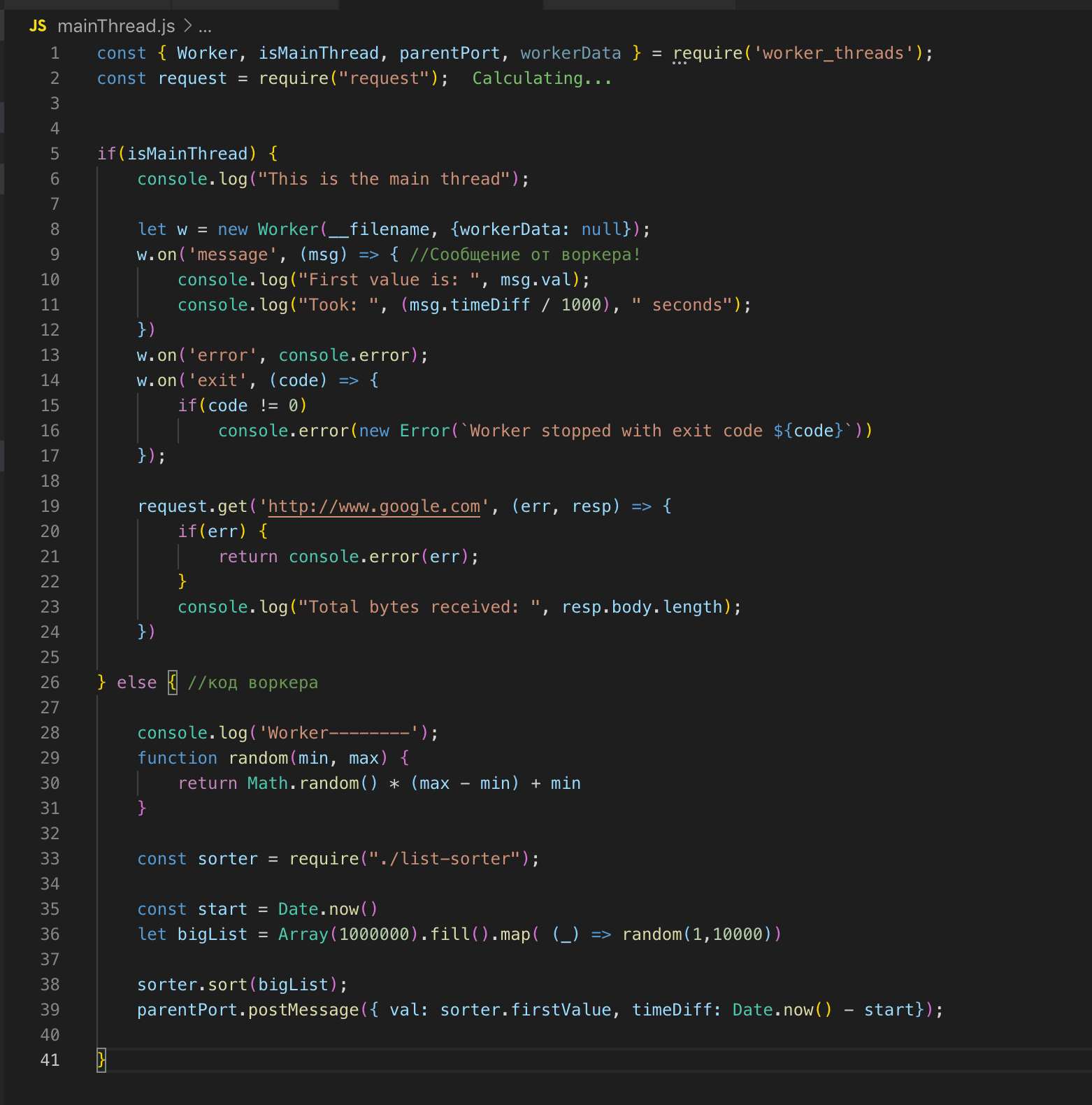
我们看一下源代码。 我们在第26行注册工作者,并在必要时将数据传递给它。 在这种情况下,我什么也不会传送。 然后我们订阅事件:错误和消息。 在工作程序中,该函数被调用,对两百万条记录的数组进行排序。 排序后,我们就通过post_message将结果发送到主流。
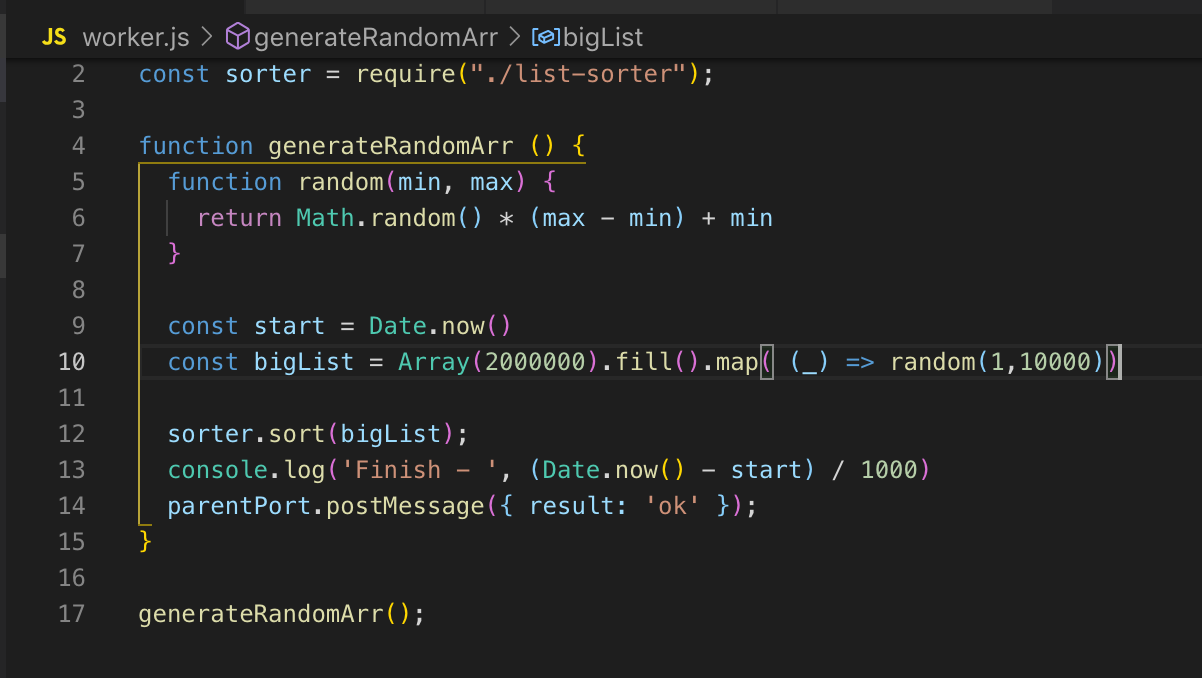
在主线程中,我们捕获此消息并将结果发送完成。 工作线程和主线程具有公共内存,因此我们可以访问整个过程的全局变量。 当我们将数据从主流传输到worker时,worker只得到一个副本。
我们可以在一个文件中描述主流和工作流。 worker_threads模块提供了一个API,通过它我们可以确定代码当前在哪个线程中执行。
我分享了有用资源的链接,以及Ryan Dahl展示事件循环时(Ryan Dahl)演讲的链接(很有趣)。
事件循环
- Node.js文档中文章的翻译
- https://blog.risingstack.com/node-js-at-scale-understanding-node-js-event-loop/
- https://habr.com/cn/post/336498/
Worker_threads
- https://nodejs.org/api/worker_threads.html#worker_threads_worker_workerdata-API
- https://habr.com/ru/company/ruvds/blog/415659/
- https://nodesource.com/blog/worker-threads-nodejs/
- Ryan Dahl的演示文稿的原始幻灯片(通过VPN)