第一部分,补充。
Cotans,嗨。
我是Sasha,我沉迷于神经元。
在工作人员的要求下,我终于集思广益,并决定编写一系列简短且几乎循序渐进的说明。
有关如何从头开始训练和部署神经网络的说明,同时与电报机器人交朋友。
有关像我这样的假人的说明。
今天,我们将选择神经网络的体系结构,对其进行测试,并收集我们的第一个训练数据集。
架构选择
在成功完成了
selfie2anime bot的启动后(使用现成的
UGATIT模型),我想做同样的事情,但是我的。 例如,将您的照片变成漫画的模型。
这是我的
photo2comicsbot的一些示例,我们将做类似的事情。



由于
UGATIT模型对于我的视频卡来说太重了,因此我提请注意一个较旧但不那么
令人讨厌的类比
-CycleGAN在此实现中,存在几种模型体系结构以及浏览器中学习过程的便捷可视化显示。
与
用于在单个图像上
传递样式的体系结构一样
, CycleGAN不需要成对的图像进行训练。 这很重要,因为否则我们将不得不将所有照片重新绘制到漫画中以创建训练集。
我们将为算法设置的任务包括两部分。
在输出中,我们应该得到一张图片:
a)类似于漫画书
b)与原始图片相似
可以使用通常的GAN来实现“ a”点,受过训练的评论家将负责“模仿漫画”。
有关GAN的更多信息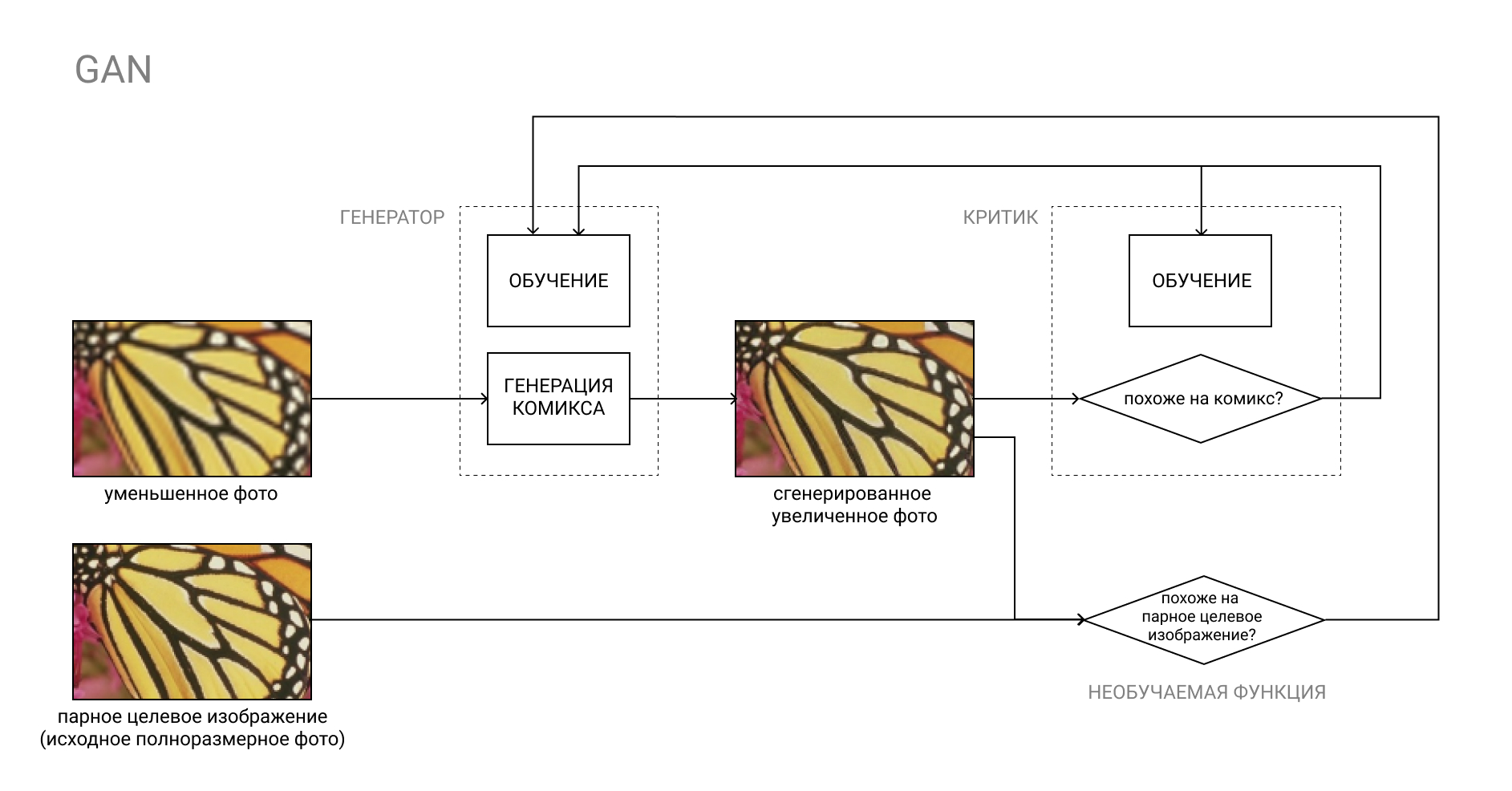
GAN(即生成对抗网络)是两个神经网络的对:生成器网络和评论家网络。
生成器将输入内容(例如,从照片转换为漫画书),然后批评者将得到的“伪造”结果与真实漫画书进行比较。 生成器的工作是欺骗评论家,反之亦然。
在学习过程中,生成器学习创建与真实漫画越来越相似的漫画,而评论家则学会更好地区分漫画。
第二部分比较复杂。 如果我们将图片配对,则在“ A”组中有照片,而在“ B”组中有照片,但是将它们重绘为漫画(也就是我们希望从模型中得到的照片),我们可以只是将生成器产生的结果与训练集“ B”中的配对图像进行比较。
在我们的情况下,集合“ A”和“ B”绝没有相互连接。 在“ A”组中-随机照片,在“ B”组中-随机漫画。
将假漫画与“ B”中的一些随机漫画进行比较是毫无意义的,因为这将至少复制评论家的功能,更不用说不可预测的结果了。
这就是CycleGAN架构的得力之处。
简而言之,这是GAN对,其中第一对将图像从类别“ A”(例如照片)转换为类别“ B”(例如漫画书),第二对将图像从类别“ B”转换为类别“ A”。
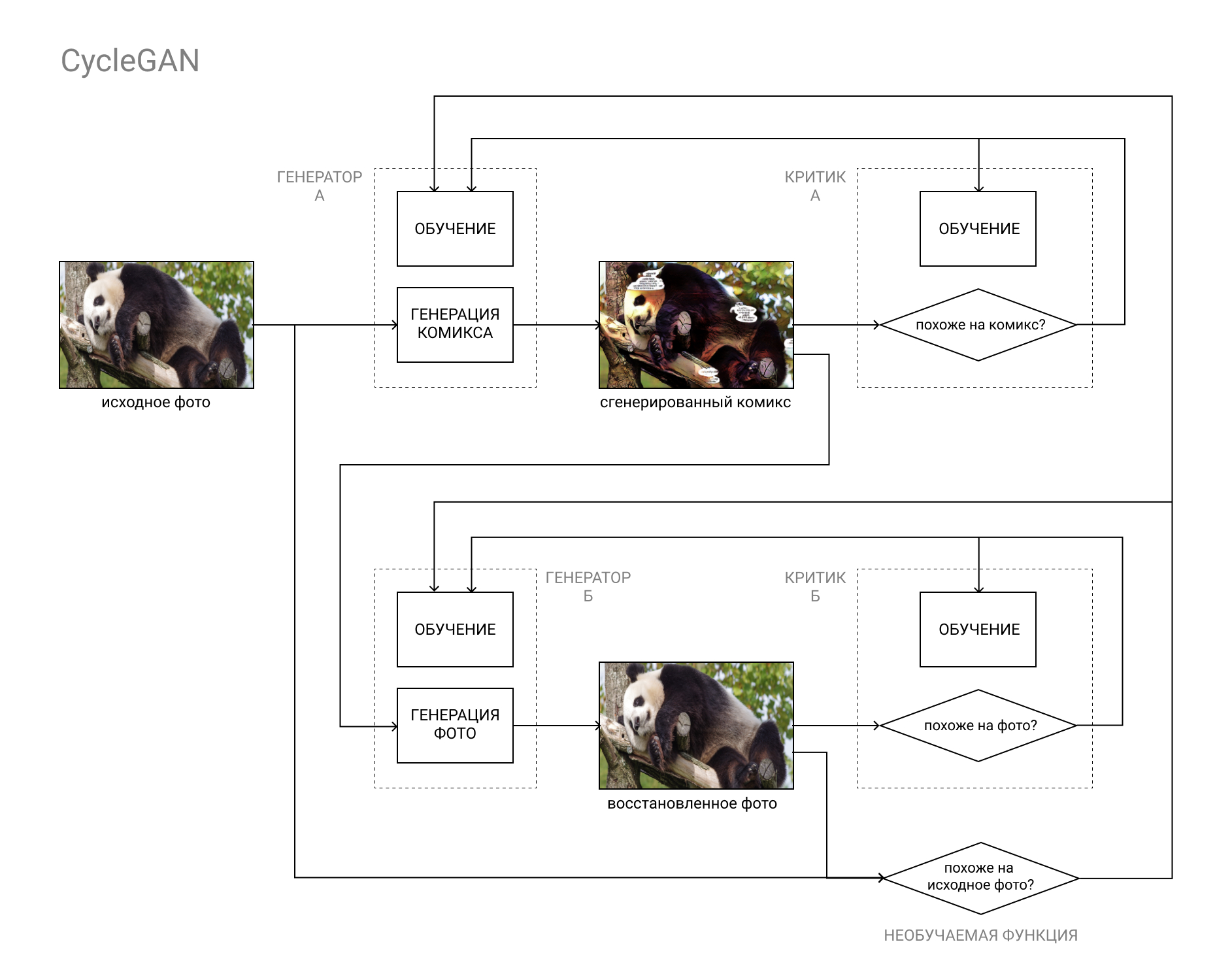
模型的训练既基于原始照片与还原照片的比较(作为循环“ A”-“ B”-“ A”,“照片漫画照片”的结果),也包括在常规GAN中的评论家数据。
这样就可以完成我们的任务的两个部分:生成与其他漫画没有区别的漫画书,同时又类似于原始照片。
模型安装和验证
要实施我们的狡猾计划,我们需要:
- 具有CUDA的图形卡,具有8GB RAM
- Linux操作系统
- 带有Python 3.5+的Miniconda / Anaconda
如果您不满意设置,则RAM小于8GB的视频卡也可以工作。 它也可以在Windows上运行,但速度较慢,相差至少1.5到2倍。
如果您没有支持CUDA的GPU,或者太懒惰而无法全部设置,则可以随时使用Google Colab。 如果有足够多的人想要,我将填写该教程以及如何在Google云中启动以下所有步骤。迷你康达可以在这里安装说明安装Anaconda / Miniconda(以下称为conda)后,为我们的实验创建一个新环境并激活它:
(Windows用户需要首先从“开始”菜单启动Anaconda Prompt)conda create --name cyclegan conda activate cyclegan
现在,所有软件包都将安装在活动环境中,而不会影响环境的其余部分。 如果您需要各种软件包的特定版本组合,例如,如果您使用别人的旧代码,并且需要安装过时的软件包而又不破坏您的生活和主要工作环境,那么这将很方便。
接下来,只需按照发行版中的README.MD说明进行操作:
保存CycleGAN分发:
(或只是从GitHub下载档案) git clone https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix cd pytorch-CycleGAN-and-pix2pix
安装必要的软件包:
conda install numpy pyyaml mkl mkl-include setuptools cmake cffi typing conda install pytorch torchvision -c pytorch conda install visdom dominate -c conda-forge
下载完成的数据集和相应的模型:
bash ./datasets/download_cyclegan_dataset.sh horse2zebra bash ./scripts/download_cyclegan_model.sh horse2zebra
注意下载的数据集中的照片。
如果打开上一段中的脚本文件,则可以看到还有其他现成的数据集和模型。
最后,在下载的数据集上测试模型:
python test.py --dataroot datasets/horse2zebra/testA --name horse2zebra_pretrained --model test --no_dropout
结果将保存在/ results / horse2zebra_pretrained /文件夹中
创建训练集
选择未来模型的体系结构(并在github上搜索完成的实现)之后,同样重要的一步是编译一个数据集或数据集,我们将在该数据集或数据集上进行训练和测试。
几乎所有内容都取决于我们使用什么数据。 例如,用于selfie2动漫机器人的UGATIT在女性自拍照和动漫女性面孔方面接受了培训。 因此,在拍摄男性照片时,她的行为至少很有趣,用高领的小女孩代替了残酷的胡须男人。 在照片中,您谦卑的仆人得知他正在观看动漫后,便开始活动。

正如您已经了解的那样,值得选择要在输入中使用并在输出中使用的照片/漫画。 您是否打算处理自拍照-从漫画,建筑物照片添加自拍照和脸部特写-在建筑物中添加建筑物照片和漫画中的页面。
作为示例照片,我使用了
DIV2K和
Urban100 ,并用Google明星的照片进行了
修饰 ,以增强多样性。
我从漫威宇宙中拿出了漫画,整个页面,丢掉了广告和公告,而这些照片和图片看起来都不像漫画书。 出于明显的原因,我无法附加该链接,但是如果您知道我的意思,那么在Marvel Comics的要求下,您可以轻松地在喜爱的网站上找到带有漫画的扫描选项。
重要的是要注意绘图,它在不同的系列和配色方案中有所不同。

我有很多死侍和蜘蛛侠,所以皮肤变得非常红。
其他公共数据集的不完整列表可以在
此处找到。
我们的数据集中的文件夹结构应如下所示:
selfie2comics
├──火车A
├──火车B
├──测试A
└──testB
trainA-我们的照片(约1000个)
testA-一些用于模型测试的照片(30张就足够了)
trainB-我们的漫画(约1000个)
testB-测试漫画(30个)
如果可能,建议将数据集放置在SSD上。
今天就这些了,在下一期中,我们将开始训练模型并获得第一个结果!
如果您遇到问题,请务必写信,这将有助于提高领导能力并减轻后续读者的痛苦。
如果您已经尝试训练模型,请随时在评论中分享结果。 待会见!
⇨下一部分