在几乎所有现代计算机游戏中,存在物理引擎是前提。 旗帜和兔子在风中飘扬,被球轰炸-所有这些都需要适当的处决。 而且,当然,即使不是所有英雄都穿着雨衣……但是,那些穿着雨衣的人确实需要对绒毛织物进行充分的模拟。

然而,由于这种交互比实时游戏所需的速度慢几个数量级,因此通常无法进行此类交互的完整物理建模。 本文提供了一种新的建模方法,该方法可以加快物理仿真速度,使其速度提高300-5000倍。 其目的是尝试教一个神经网络来模拟物理力。
物理引擎的开发进度取决于技术设备不断增长的计算能力以及快速稳定的建模方法的发展。 此类方法包括,例如,通过将空间切成子空间进行建模以及数据驱动的方法(即基于数据)。 前者仅在缩小或压缩的子空间中工作,其中仅考虑了几种变形形式。 对于大型项目,这可能会导致技术要求大幅增加。 数据驱动的方法使用系统的内存和存储在其中的预先计算的数据,从而降低了这些要求。
在这里,我们着眼于将两种方法结合在一起的方法:通过这种方法,它旨在利用两种方法的优势。 可以通过两种方式来解释这种方法:作为由神经网络参数化的子空间建模方法,或者作为基于子空间建模来构建压缩模拟介质的DD方法。
其本质是这样的:首先,我们使用
Maya nCloth收集高精度的模拟数据,然后使用
主成分法(PCA)计算线性子空间。 下一步,我们将使用基于经典神经网络模型和新方法的机器学习,然后将经过训练的模型引入具有多种优化功能的交互式算法中,例如通过GPU进行的高效解压缩算法和逼近顶点法线的方法。
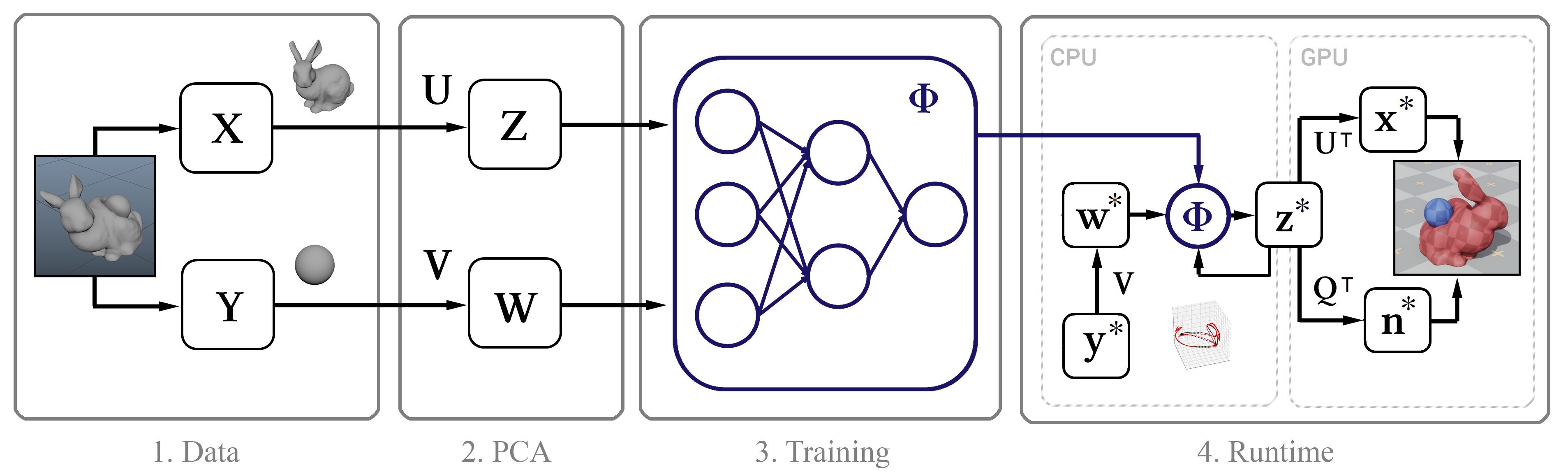 图1.该方法的结构图
图1.该方法的结构图训练数据
一般而言,此方法的唯一输入是对象顶点逐帧位置的原始时间戳。 接下来,我们描述收集此类数据的过程。
我们在Maya nCloth中执行模拟,以每秒60帧的速度捕获数据,并包含5或20个子步骤以及10或25个限制迭代,具体取决于模拟的稳定性。 对于织物,请选择T恤衫,其材料的重量会略微增加,并具有抗拉伸性;对于可变形的物体,应使用硬质橡胶并减少摩擦。 我们通过碰撞外部几何形状的三角形,自碰撞(顶点与织物的顶点以及三角形与橡胶的三角形)来执行外部碰撞。 在所有情况下,我们都使用相当大的碰撞厚度-大约5厘米-以确保模型稳定性并防止织物的夹挤和撕裂。
表1.建模对象的参数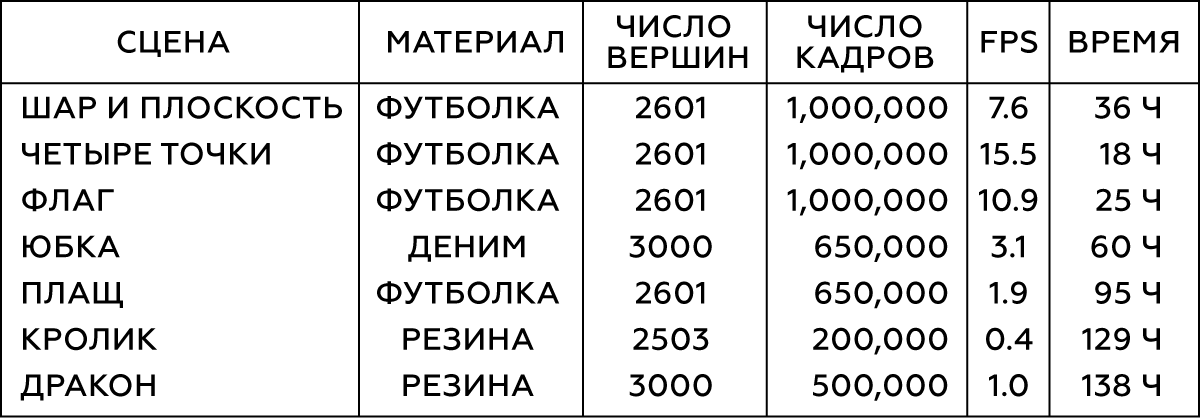
对于简单对象(例如球)的各种类型的交互,我们将通过在随机时间裁剪随机坐标来以随机方式生成其运动。 为了模拟组织与角色的交互,我们使用6.5×10
5帧的运动捕捉数据库,这是一个大型动画。 仿真完成后,我们验证结果并排除行为不稳定或不良的帧。 对于带有裙摆的场景,我们将角色的手移开,因为它们通常与腿部网格的几何形状相交,并且现在已经不重要了。
 图2.表中的前两个场景
图2.表中的前两个场景通常我们需要10
5 -10
6帧训练数据。 根据我们的经验,在大多数情况下,10
5帧足以进行测试,而10
6帧可获得最佳结果。
培训课程
接下来,我们将讨论机器学习的过程:关于神经网络中的参数化,关于网络体系结构以及直接关于技术本身。
参数化
为了获得训练数据集,我们将每个帧
t中的顶点坐标收集到一个向量
x t中 ,然后将这些逐帧向量组合到一个大矩阵X中。此矩阵描述了建模对象的状态。 此外,我们必须了解每个帧中外部对象的状态。 对于简单的对象(例如球),您可以使用其三维坐标,而复杂模型的状态(字符)则通过每个关节相对于参考点的位置来描述:对于裙子来说,这样的支撑就是髋关节,对于披风来说就是脖子。 对于具有移动参考系统的对象,应考虑地球相对于地球的位置:然后我们的系统将知道重力的方向以及其线速度,加速度,旋转速度和旋转加速度。 对于旗帜,我们将考虑风速和风向。 结果,对于每个对象,我们得到一个描述外部对象状态的大向量,并且所有这些向量也被组合到矩阵Y中。
现在,我们将PCA应用于矩阵X和Y,并使用生成的变换矩阵Z和W构造子空间图像。 如果PCA程序需要太多内存,请首先对我们的数据进行采样。
PCA压缩不可避免地会导致细节损失,尤其是对于具有许多潜在条件(例如织物的细褶皱)的物体。 但是,如果子空间包含256个基本向量,则通常有助于保留大多数细节。 以下是斗篷的标准物理学的动画,以及分别具有256、128和64基本向量的模型。
 图3.在具有不同尺寸基准的空间中,控制模型(标准)与通过我们的方法获得的模型的比较
图3.在具有不同尺寸基准的空间中,控制模型(标准)与通过我们的方法获得的模型的比较源模型和扩展模型
有必要开发一个可以预测未来框架中模型向量状态的模型。 而且由于建模对象通常以惯性为特征,并且具有趋于某种平均静止状态的趋势(在PCA程序之后,该对象处于零值状态),因此好的初始模型应该是图4中算法第9行所表示的表达式。这里,α和β是模型参数, ⊙是爆炸产品。 这些参数的值将从源数据中通过分别求解α和β的
线性最小二乘方程获得:
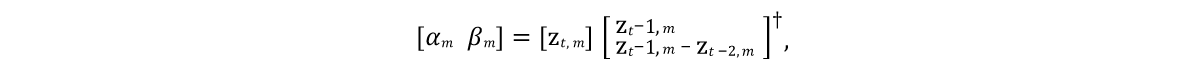
这里†是
矩阵的
伪逆变换 。
由于这样的预测只是一个非常粗略的近似,并且没有考虑外部对象w的影响,因此显然无法准确地对训练数据进行建模。 因此,我们根据算法的第11行训练了近似模型残差效果的神经网络Φ。 在这里,我们使用激活函数
ReLU对每层(输出除外)的10层标准
直接分布神经网络进行参数化。 不包括输入和输出层,我们将每个剩余层上的隐藏单元数设置为PCA数据大小的一半,这导致了硬盘驱动器上的占用空间与性能之间的良好折衷。
 图4.神经网络学习算法
图4.神经网络学习算法神经网络训练
训练神经网络的标准方法是遍历整个数据集并训练网络为每个帧做出预测。 当然,这种方法将导致较低的学习错误,但是这种预测中的反馈将导致其结果不稳定。 因此,为了确保稳定的长期预测,我们的算法在整个集成过程中都使用了
误差的反向传播方法。
通常,它的工作方式是这样的:从训练数据
z和
w的一个小窗口中
,我们获取前两个帧
z 0和
z 1 ,
并向它们添加一点噪声
r 0 ,
r 1 ,以稍微破坏学习路径。 然后,为了预测下一帧,我们将算法运行几次,并在每个新的时间步长返回到先前的预测结果。 一旦获得整个轨迹的预测,就可以计算平均坐标误差,然后使用使用TensorFlow计算的自动导数将其传递给AmsGrad优化器。
我们将在16个帧的微型样本上使用32个帧的重叠窗口重复此算法100个时代,直到训练收敛为止。 我们使用0.0001的学习率,0.999的学习率的衰减系数以及从PCA空间的前三个分量计算出的噪声标准差。 根据安装的复杂性和PCA数据的大小,这种培训需要10到48个小时。
 图5.基准裙边和我们的神经网络学会建立的裙边的视觉比较
图5.基准裙边和我们的神经网络学会建立的裙边的视觉比较系统实施
我们将详细描述在交互式环境中该方法的实现,包括评估神经网络,计算要渲染的对象表面的法线以及如何处理可见的相交。
渲染应用
我们在用C ++和DirectX编写的简单交互式3D应用程序中渲染结果模型:我们再次在单线程C ++代码中实现预处理和神经网络操作,并加载在训练过程中获得的二进制网络权重。 然后,我们对网络估计应用了一些简单的优化方法,特别是内存缓冲区和稀疏向量矩阵数据的重用,这归功于由于ReLU激活功能而获得的零隐藏单元。
GPU解压缩
将压缩的z状态数据发送到GPU并解压缩以进行进一步渲染。 为此,我们使用一个简单的计算着色器,该着色器为对象的每个顶点计算向量z和矩阵U
T的前三行(对应于该顶点的坐标)的点积,然后加上平均值
x µ 。 与
朴素的解压缩
方法相比,这种方法有两个优点。 首先,GPU的并行性显着加快了模型状态向量的计算,这可能需要1毫秒的时间。 其次,它将中央和GPU之间的数据传输时间减少了一个数量级,这对于整个对象的整个状态的传输速度太慢的平台而言尤其重要。
顶点法向预测
在渲染期间,仅访问顶点的坐标是不够的-还需要有关其法线变形的信息。 通常,在物理引擎中,要么忽略此计算,要么对法线进行幼稚的逐帧重新计算,然后将其随后重新分布到相邻顶点。 事实证明这可能是效率低下的,因为中央处理器的基本实现方式,除了解压缩和数据传输的成本外,还需要另外150 µs的时间用于此过程。 并且尽管可以在GPU上执行此计算,但是由于需要并行操作,因此很难实现。
取而代之的是,我们将子空间的状态线性回归为GPU着色器上的正常全状态向量。 知道每一帧中顶点法线的值,我们计算矩阵Q,该矩阵Q最好地表示子空间在顶点法线上的表示。
由于我们的方法从未预测过法线预测,因此无法保证这种方法的准确性,但是在实践中证明它确实是很好的,如下图所示。
 图6.通过我们的方法计算的模型与参考(地面真实情况)的比较,以及它们之间的差异
图6.通过我们的方法计算的模型与参考(地面真实情况)的比较,以及它们之间的差异交叉口打架
我们的神经网络学会了有效地执行碰撞,但是,由于预测的不准确和子空间压缩所导致的错误,外部对象和模拟对象之间可能会发生相交。 此外,由于我们将场景的完整状态的计算推迟到渲染的最开始,因此无法提前有效解决这些问题。 因此,为了保持高性能,在渲染过程中必须消除这些交集。
我们找到了一个简单有效的解决方案,其中包括将相交的顶点投影到构成角色的图元的表面上。 使用相同的可对结构进行解压缩并计算正常着色的计算着色器,可以在GPU上轻松进行此投影。
因此,首先,我们将从具有不同初始半径和最终半径的顶点连接的代理对象组成字符,然后将有关这些对象的坐标和半径的信息传输到计算着色器。 再次检查每个顶点的坐标,以使其与相应的代理对象相交,如果存在,则将此顶点投影到代理对象的表面上。 因此,我们仅校正顶点的位置,而不接触法线本身,以免损坏阴影。
如果顶点位移的误差不大到投影位于相应代理对象的相对侧,则此方法将删除对象的可见小交叉点。
 图7.由代理对象组成的字符模型以及使用我们的方法消除可见交集的结果:之前和之后
图7.由代理对象组成的字符模型以及使用我们的方法消除可见交集的结果:之前和之后结果分析
因此,我们的测试场景包括:
, .
- 16 , 120 240 .
 8. 16 . Party time!
8. 16 . Party time!, , , , .
, PCA. , , , .
 9. , , –
9. , , –― , . , . 300-5000 , . ,
- (HRPD) ,
(LSTM) (GRU) .
, . Intel Xeon E5-1650 3.5 GHz GeForce GTX 1080 Titan.
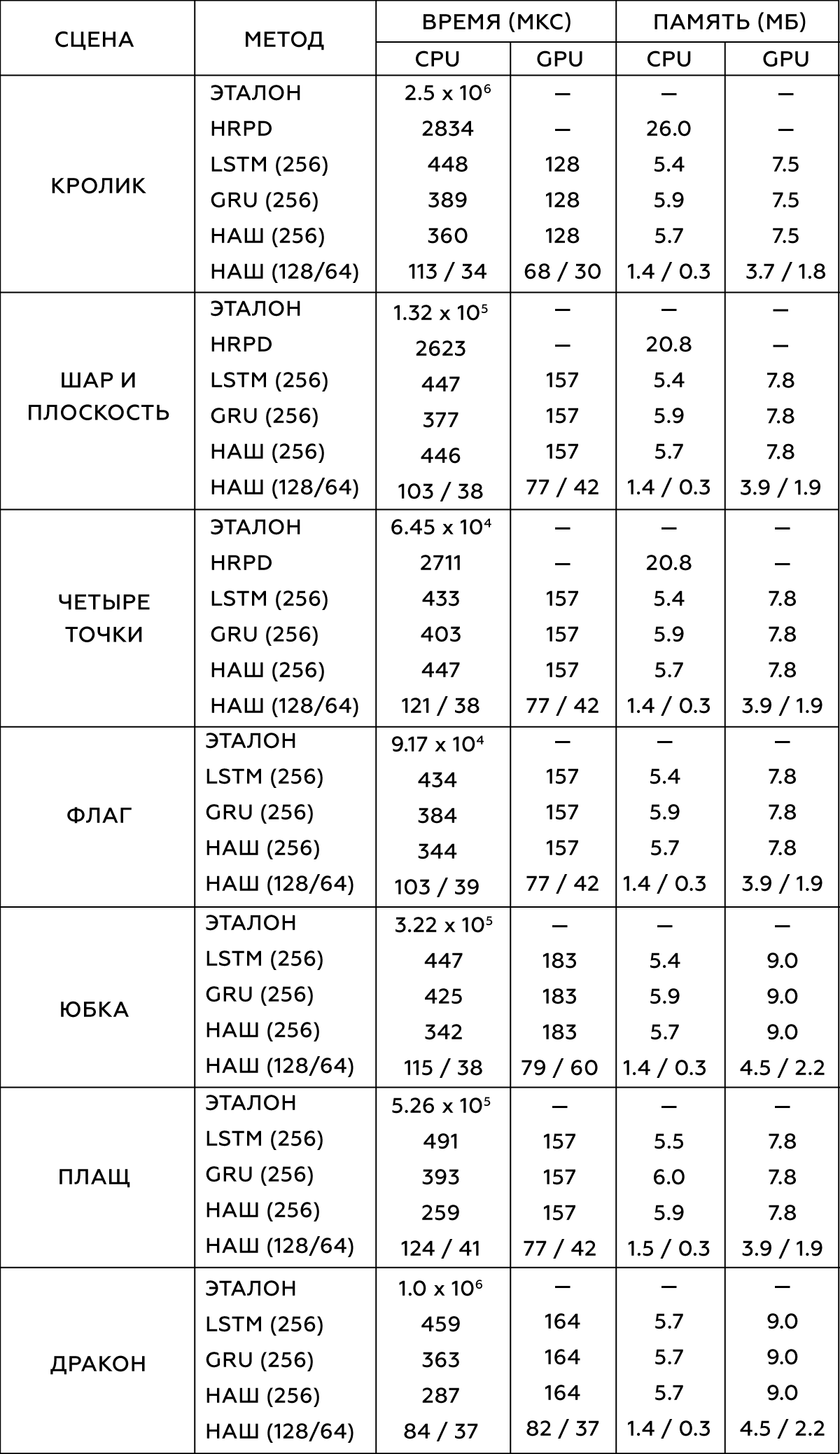
2.
, , . , .
data-driven , . , , , , , . , , ― , .
, , , .
, . data-driven , ― , . , , , . , , , .
, . .
, , , . , , ― , . -, , , - . .
, , , , . , , , , ― , , . .
.
 10. vs : choose your fighter
10. vs : choose your fighter