根据活动的类型,开发人员在编写请求并认为“
基础很聪明,可以处理所有事情! ”时
,就必须应对这种情况。在某些情况下(部分是由于对数据库功能的不了解,部分是由于过早的优化),这种方法导致出现“ Frankenstein”。
首先,我将举例说明这种查询:
为了客观地评估请求的质量,让我们创建一些任意数据集:
CREATE TABLE tbl AS SELECT (random() * 1000)::integer key_a , (random() * 1000)::integer key_b , (random() * 10000)::integer fld1 , (random() * 10000)::integer fld2 FROM generate_series(1, 10000); CREATE INDEX ON tbl(key_a, key_b);
事实证明,
读取数据本身
花费的查询
时间不到总查询
时间的四分之一 :
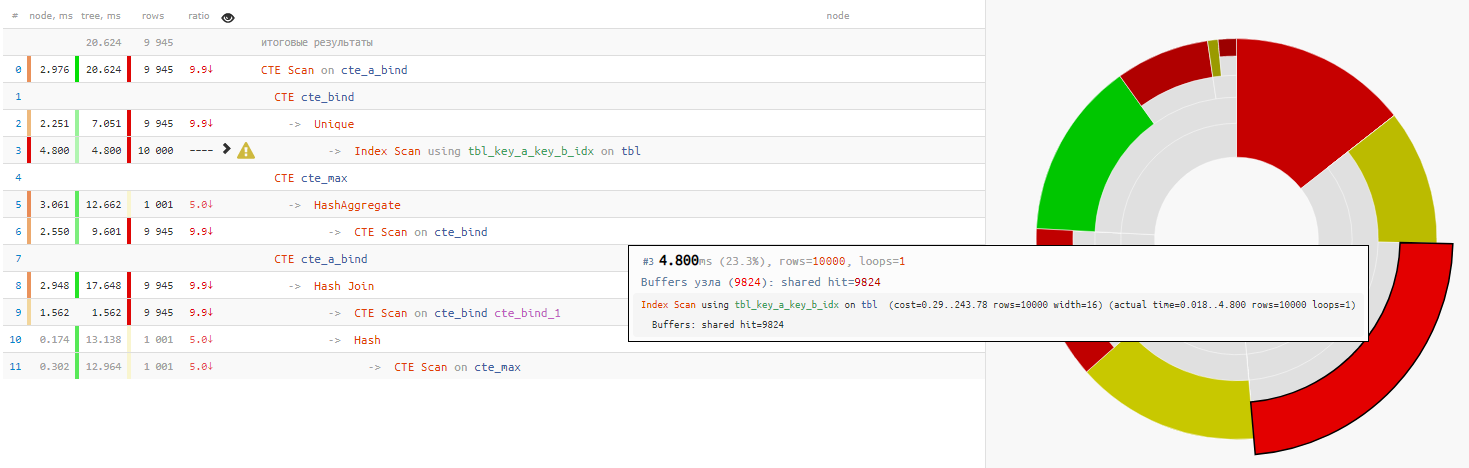 [看explain.tensor.ru]
[看explain.tensor.ru]骨头分解
我们将仔细查看该请求,我们会感到困惑:
- 如果没有递归CTE,为什么在这里使用WITH RECURSIVE?
- 如果将最小值/最大值仍然与原始样本连接,为什么还要在单独的CTE中将其分组?
+ 25%的时间 - 为什么最后通过无条件的“ SELECT * FROM”使用上一个CTE的重读?
+ 14%的时间
在这种情况下,我们很幸运,选择了哈希联接作为连接,而不是嵌套循环,因为那样我们将不会获得一次CTE扫描通行证,而是10K!
关于CTE扫描的一些知识在这里,我们必须记住, CTE扫描是Seq扫描的类似物 -也就是说,没有索引,而只是穷举搜索, 对于cte_max周期 ,这将需要10K x 0.3ms = 3000ms;对于cte_bind周期 ,则需要1K x 1.5ms = 1500ms !
其实,您想要得到什么?
是的,通常在他对“三层”要求进行分析的第5分钟内,他访问了这个问题。我们希望每个唯一的键对都
通过key_a从组中删除
min / max 。
因此,我们将使用
窗口函数 :
SELECT DISTINCT ON(key_a, key_b) key_a a , key_b b , max(fld1) OVER(w) bind_fld1 , min(fld2) OVER(w) bind_fld2 FROM tbl WINDOW w AS (PARTITION BY key_a);
 [看explain.tensor.ru]
[看explain.tensor.ru]由于在两个版本中读取数据平均花费大约4-5ms,因此,如果这样的请求执行得很频繁,则整个
-32%的时间增益是
从基本CPU上清除了纯
负载 。
通常,您不应该将底座强制为“圆形-磨损,方形-滚动”。