
只是不要感到惊讶,但是这篇文章的第二个标题生成了一个神经网络,或者说是Sammarization算法。 什么是Sammarization?
这是
自然语言处理(NLP)的关键和经典
挑战之一 。 它包括创建一个将文本作为输入并输出其删节版本的算法。 而且,其中保留了正确的结构(对应于语言规范),并且正确传达了文本的主要思想。
这样的算法在工业中被广泛使用。 例如,它们对搜索引擎很有用:使用文本缩减,您可以轻松地了解网站或文档的主要思想是否与搜索查询相关。 它们用于在大量媒体数据流中搜索相关信息,并过滤掉信息垃圾。 文本减少有助于金融研究,法律合同分析,科学论文注释等。 顺便说一下,Sammarization算法生成了该帖子的所有子标题。
令我惊讶的是,在哈布雷(Habré)上几乎没有关于Sammarization的文章,因此我决定在这个方向上分享我的研究和结果。 今年,我参加了
对话会议上的赛道,并使用神经网络对新闻条目和诗歌的标题生成器进行了实验。 在这篇文章中,我将首先简要介绍一下语法化的理论部分,然后我将给出有关标题生成的示例,我将告诉您减少文本时模型有哪些困难以及如何改进这些模型以获得更好的标题。
以下是新闻条目及其原始参考标题的示例。 我将要讨论的模型将通过以下示例进行训练以生成标头:

削减文本seq2seq架构的秘密
有两种类型的文本缩小方法:
- 提取物 。 它包括找到文本中最有用的部分,并从中构造出针对给定语言正确的注释。 这组方法仅使用源文本中的那些单词。
- 摘要 它包括从文本中提取语义链接,同时考虑到语言依赖性。 使用抽象语法化时,不是从缩写文本中选择注释单词,而是从字典(给定语言的单词列表)中选择注释单词,从而改写了主要思想。
第二种方法意味着该算法应考虑语言依赖性,重新表述和概括。 他还希望对现实世界有所了解,以防止事实错误。 长期以来,这被认为是一项艰巨的任务,研究人员无法获得高质量的解决方案-在保留主要思想的同时,语法上正确的文本。 这就是为什么过去大多数算法都基于提取方法的原因,因为选择整段文本并将其传输到结果中可以使您保持与源代码相同的读写水平。
但这是在神经网络蓬勃发展和即将渗透到NLP中之前。 2014年,
引入了
seq2seq架构并
引入了一种关注机制 ,
该机制可以读取一些文本序列并生成其他文本序列(这取决于模型学习输出的内容)(Sutskever等人的
文章 )。 在2016年,这种体系结构直接用于解决Sammarization问题,从而实现了一种抽象方法,并获得了与有能力的人可以写的东西相媲美的结果(Nallapati等人,2016年; Rush等人,2015年; ) 这个架构如何运作?
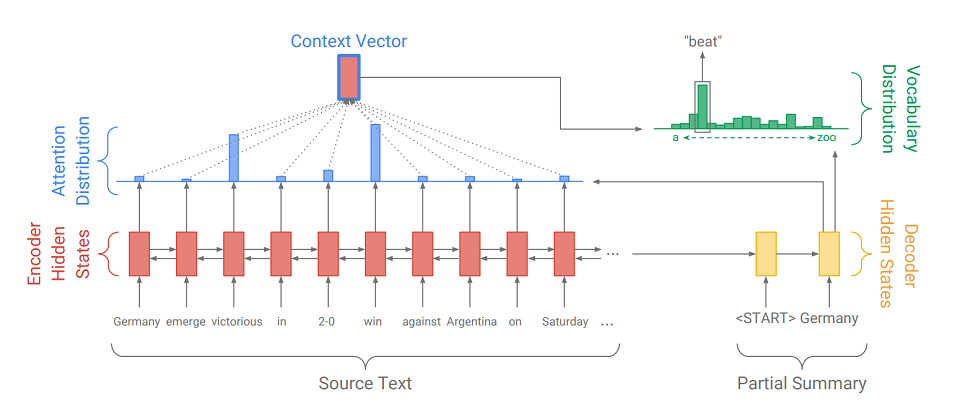
Seq2Seq由两部分组成:
- 编码器 (Encoder)-双向RNN,用于读取输入序列,即从左到右和从右到左同时顺序处理输入元素,以更好地考虑上下文。
- 解码器 (Decoder)-单向RNN,按顺序逐元素生成输出序列。
首先,将输入序列转换为嵌入序列(简而言之,嵌入是单词作为向量的简洁表示)。 嵌入然后通过编码器的递归网络。 因此,对于每个单词,我们获得编码器的隐藏状态(
在图中用红色矩形表示 ),并且它们包含有关令牌本身及其上下文的信息,从而使我们能够考虑单词之间的语言联系。
处理完输入后,编码器将其最后一个隐藏状态(包含有关整个文本的压缩信息)传输到解码器,该解码器接收一个特殊令牌

并创建输出序列的第一个单词(
在图片中为“ Germany” )。 然后,他周期性地获取以前的输出,将其反馈给自己,并再次显示下一个输出元素(
因此,在“德国”之后是“ beat”,在“ beat”之后是下一个单词,依此类推 )。 重复此过程,直到发出特殊令牌为止
。 这意味着一代人的终结。
为了显示下一个元素,解码器就像编码器一样,将输入令牌转换为嵌入,执行递归网络的步骤,并接收解码器的下一个隐藏状态(图中的
黄色矩形 )。 然后,使用完全连接的层,从预编译的模型字典中获得所有单词的概率分布。 该模型将推导出最可能的单词。
添加
注意机制有助于解码器更好地利用输入信息。 生成的每个步骤的机制都会确定所谓的
注意力分布 (图中的
蓝色矩形是与原始序列的元素相对应的权重集合,权重之和为1,所有权重> = 0 ),并从中接收编码器所有隐藏状态的加权总和,从而形成上下文向量(
该图显示了一个带有蓝色笔划的红色矩形 )。 该矢量在计算潜在状态时嵌入解码器输入字,在确定下一个字时与潜在状态本身连接。 因此,在输出的每个步骤中,模型都可以确定当前哪个编码器状态对其最重要。 换句话说,它决定了最应该考虑哪个输入单词的上下文(例如,在图片中显示单词``beat'',注意机制将较大的权重分配给``胜利''和``获胜''标记,其余的则接近于零)。
由于标头的生成也是Sammarization的任务之一,因此仅以最小的可能输出(1-12个字),我决定将
seq2seq与注意机制一起用于我们的案例。 我们在带有标题的文本(例如新闻)上训练这种系统。 此外,建议在培训阶段不要向解码器提交自己的输出,而应向真实标题(教师强迫)这样的单词提交,从而使他自己和模型的工作更加轻松。 作为误差函数,我们使用标准的交叉熵损失函数,该函数说明输出字和真实标头中的字的概率分布接近:
当使用训练好的模型时,我们使用射线搜索来找到比使用贪婪算法更可能的单词序列。 为此,在生成的每个步骤中,我们都不导出最可能的单词,而是同时查看最可能的单词序列的beam_size。 当他们结束时(每个结束于
),我们得出最可能的序列。
模型演变
seq2seq上的模型的问题之一是无法引用不在词典中的单词。 例如,该模型没有机会从上面的文章中得出“ obamacare”。 同样适用于:
- 罕见的姓氏和名字
- 新条款
- 其他语言的单词,
- 由连字符连接的不同单词对(作为“共和党参议员”)
- 和其他设计。
当然,您可以扩展字典,但这会大大增加训练有素的参数的数量。 另外,有必要提供大量的文件,在这些文件中可以找到这些稀有词,以便生成器学习定性地使用它们。
在2017年的一篇文章中提出了解决此问题的另一种更为优雅的解决方案
:“直达主题:使用指针生成器网络进行汇总 ”(Abigail See等)。 她向我们的模型添加了一种新机制-指针
机制 ,该
机制可以从源文本中选择单词并直接插入到生成的序列中。 如果文本包含OOV(
超出词汇范围-不在词典中的单词 ),则模型(如果认为有必要)可以隔离OOV并将其插入到输出中。 这样的系统称为
“指针生成器”(pointer-generator或pg),是两种语法化方法的综合。 她自己可以决定应该在哪个步骤进行抽象,以及在哪个步骤进行提取。 她的操作方式,我们现在就解决。
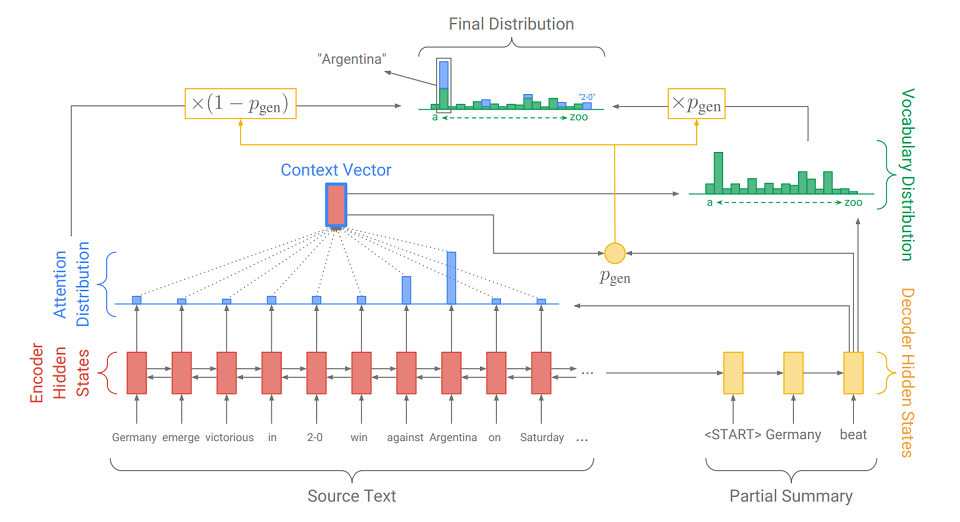
与通常的seq2seq模型的主要区别在于,要计算p
gen的附加操作-生成概率。 这是使用解码器的隐藏状态和上下文向量完成的。 附加动作的含义很简单。 p
gen越接近1,则该模型越有可能使用抽象生成从其词典中发布单词。 p
gen越接近0,在早先获得的注意力分布的指导下,生成器从文本中提取单词的可能性就越大。 单词结果的最终概率分布是单词的生成概率分布(其中没有OOV)乘以p
gen与注意分布(其中OOV例如是图片中的“ 2-0”)乘以(1- p
gen )。

除了指向机制之外,本文还介绍
了一种coverage机制 ,该
机制有助于避免重复单词。 我也进行了试验,但是没有注意到标题质量的显着提高-并不是真正需要的。 很有可能,这是由于任务的细节:由于必须输出少量的单词,因此生成器根本没有时间重复自己。 但是对于其他的语法化任务,例如注释,它可以派上用场。 如果有兴趣,可以在原始
文章中阅读 。

俄语单词种类繁多
提高输出标头质量的另一种方法是适当地预处理输入序列。 除了明显使用大写字符外,我还尝试将源文本中的单词转换为样式和变形(即基础和结尾)对。 要进行分割,请使用Porter Stemmer。
我们会在开头用“ +”号标记所有变化,以将其与其他标记区分开。 我们将每个主题和拐点都视为一个单独的词,并以与词相同的方式向它们学习。 就是说,我们从它们中获取嵌入,并得出一个可以轻松转换为单词的序列(也分解为基础和结尾)。
当使用形态丰富的语言(例如俄语)时,这种转换非常有用。 您可以将自己限制在这些单词的大量词干(它们比单词形式的数量小几倍)和很少的结尾(我有450个屈折),而不是用各种各样的俄语单词形式来编写庞大的词典。 因此,我们使模型更容易使用这种“财富”,同时我们不会增加架构的复杂性和参数数量。

我还尝试使用引理+语法转换。 也就是说,您可以使用pymorphy包从处理之前的每个单词中获取其初始形式和语法含义(例如,“ was”
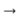
“成为”和“动词| impf |过去|唱歌| femn”)。 因此,我得到了一对并行序列(一种形式-初始形式,另一种-语法值)。 对于每种类型的序列,我都会编译我的嵌入,然后将其连接起来并提交到前面所述的管道。 在其中,解码器没有学习给出单词,而是学习了引理和语法。 但是,与该主题的pg相比,这样的系统没有带来明显的改进。 也许这是使用语法值的过于简单的体系结构,值得为输出中的每个语法类别创建一个单独的分类器。 但是我没有尝试使用这种或更复杂的模型。
我尝试过对指针生成器的原始体系结构进行另一种添加,但是该结构不适用于预处理。 这增加了编码器和解码器的递归网络的层数(最多3层)。 增加循环网络的深度可以提高输出质量,因为最后一层的隐藏状态可以包含有关输入子序列的信息,该信息比单层RNN的隐藏状态长得多。 这有助于考虑输入序列元素之间的复杂扩展语义连接。 没错,这会大大增加模型参数的数量,并使学习复杂化。

标头生成器实验
我对标题生成器的所有实验都可以分为两种类型:新闻报道和经文实验。 我将按顺序告诉您有关它们的信息。
新闻实验
处理新闻时,我使用了诸如seq2seq,pg,带有茎和拐点的pg之类的模型-单层和三层。 我还考虑了适用于g的模型,但是上面已经介绍了我想讲述的所有内容。 我必须立即说,本节中描述的所有pg都使用了包衣机制,尽管它对结果的影响是可疑的(因为没有它,情况不会更糟)。
我对RIA Novosti数据集进行了培训,该数据集由Rossiya Segodnya新闻社提供,用于在Dialog会议上进行标题生成。 该数据集包含2010年1月至2014年12月发布的1,003,869条新闻报道。
所有研究的模型都使用相同的嵌入(128),词汇(100k)和潜在状态(256),并接受了相同时代的训练。 因此,仅架构或预处理中的质变会影响结果。
与使用文字的模型相比,适用于预处理的文本的模型可提供更好的结果。 一个三层的pg使用关于主题和变形的信息是最好的。 使用任何pg时,与seq2seq相比,标头质量的预期改进也会出现,这暗示了在生成标头时指针的首选用法。 这是所有模型的操作示例:
查看生成的标头,我们可以从正在研究的模型中区分出以下问题:
- 模型通常使用不规则形式的单词。 带茎的模型(如上例所示)更加消除了这一缺点。
- 除适用于主题的模型外,所有模型都可以产生看似不完整的标头或语言中没有的奇怪设计(如上例所示);
- 所有研究过的模型通常会混淆所描述的人员,替换错误的日期或使用不太合适的词。


用经文进行实验
由于带有主题的三层pg在生成的标题中的错误最少,因此,这是我为经文实验选择的模型。 我教她有关此案的内容,其中包含来自“ stihi.ru”网站的600万首俄罗斯诗歌。 它们包括爱情(大约一半的经文致力于这个主题),公民(大约四分之一),城市诗和山水诗。 写作时间:2014年1月至2019年5月。我将举例说明经文的标题:
事实证明,该模型主要是提取的:几乎所有标头都是一行,通常从第一个或最后一个节中提取。 在特殊情况下,该模型可以生成诗中没有的单词。 这是由于以下事实:在这种情况下,大量文本确实具有其中一行作为名称。
最后,我将说,在词干上使用单层解码器和编码器的索引生成器,在计算机语言学对话科学会议上为新闻标题生成的
比赛中排名第二。 该会议的主要组织者是ABBYY,该公司从事自然语言处理的几乎所有现代领域的研究。
最后,我建议您进行一些交互:在评论中发送新闻,并查看神经网络将为它们生成哪些标题。
Matvey,ABBYY的NLP Group开发人员