恐惧操作缓冲带...
以一个小的查询为例,考虑一些在PostgreSQL上优化查询的通用方法。 是否使用它们取决于您,但是值得了解它们。
在某些将来的PG版本中,情况可能会随着调度程序的“智慧”而改变,但是对于9.4 / 9.6来说,情况大致相同,如此处的示例所示。
我会提出一个非常真实的要求:
SELECT TRUE FROM "" d INNER JOIN "" doc_ex USING("@") INNER JOIN "" t_doc ON t_doc."@" = d."" WHERE (d."3" = 19091 or d."" = 19091) AND d."$" IS NULL AND d."" IS NOT TRUE AND doc_ex.""[1] IS TRUE AND t_doc."" = '' LIMIT 1;
关于表和字段的名称字段和表的“俄罗斯”名称可以区别对待,但这只是一个问题。 由于
我们在“ Tensor”中没有外国开发人员,并且PostgreSQL允许我们甚至用象形文字来命名,因此如果它们
用引号引起来 ,我们更愿意明确,明确地命名对象,以免产生误解。
让我们看一下最终的计划:
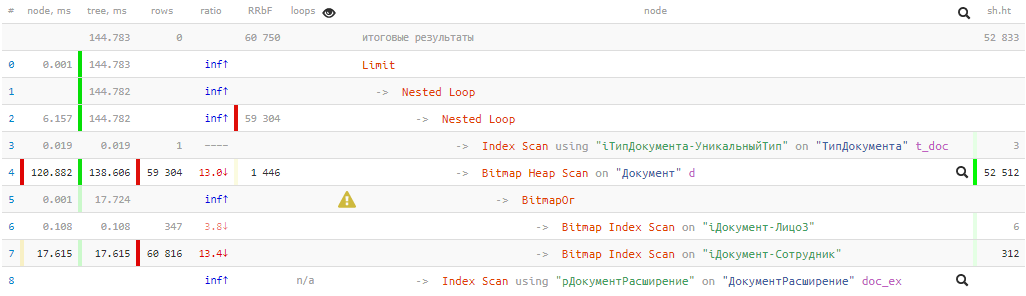 [看explain.tensor.ru]144ms和几乎53K缓冲区
[看explain.tensor.ru]144ms和几乎53K缓冲区 -即超过400MB的数据! 而且很幸运,如果在请求之前它们全部都在高速缓存中,否则从磁盘中减去时的时间会长几倍。
该算法最重要!
为了以某种方式优化任何请求,您必须首先了解它应该做什么。
现在,我们将数据库结构的开发置于本文的讨论范围之外,并同意我们可以相对“便宜地”
重写查询和/或将我们需要的任何
索引滚动到数据库中。
因此,请求是:
-检查至少一些文件的存在
-在我们需要的条件下并属于某种类型
-作者或执行者是我们需要的员工
JOIN + LIMIT 1
通常,对于开发人员来说,编写查询时比较容易,在查询中,首先要联接大量表,然后从整个表中只有一条记录。 但是对开发人员来说更容易-并不意味着对数据库更有效。
在我们的例子中,只有3张桌子-效果如何...
首先,让我们摆脱与“ TypeDocument”表的连接,同时告诉数据库我们的
类型记录是唯一的 (我们知道这一点,但是调度程序不知道):
WITH T AS ( SELECT "@" FROM "" WHERE "" = '' LIMIT 1 ) ... WHERE d."" = (TABLE T) ...
是的,如果表/ CTE由单个记录的单个字段组成,那么在PG中您甚至可以编写,而不是
d."" = (SELECT "@" FROM T LIMIT 1)
PostgreSQL查询中的延迟计算
位图或vs UNION
在某些情况下,位图堆扫描将使我们花费很多钱-例如,在我们这种情况下,当有足够的记录属于所需条件时。 我们之所以得到它是因为
OR条件,它在计划中
变成了BitmapOr操作。
让我们回到原始任务-您需要找到与
任何条件都匹配的记录-也就是说,无需在所有59K记录中搜索这两个条件。 有一种方法可以解决一个条件,
只有在第一个条件
没有发现时才转到第二个条件。 这种设计将帮助我们:
( SELECT ... LIMIT 1 ) UNION ALL ( SELECT ... LIMIT 1 ) LIMIT 1
“外部” LIMIT 1确保当找到第一条记录时搜索结束。 并且如果已经在第一个程序段中,则第二个程序段将不会
执行 (该计划中
永远不会执行 )。
“隐藏在情况下”困难的条件
初始请求中有一个非常不方便的时刻-使用链接表“文档扩展名”检查状态。 不管表达式中其余条件的真实性(例如
d。“已删除”都不是TRUE ),该连接始终会执行并且“值得资源”。 他们或多或少会花费-取决于此表的大小。
但是您可以修改请求,以便仅在确实必要时才搜索相关记录:
SELECT ... FROM "" d WHERE ... AND CASE WHEN "$" IS NULL AND "" IS NOT TRUE THEN ( SELECT ""[1] IS TRUE FROM "" WHERE "@" = d."@" ) END
由于我们
不需要链接表中
结果的任何字段,因此我们可以将JOIN变成子查询的条件。
我们将索引字段保留在CASE的“括号之外”,我们将记录中的简单条件添加到WHEN块中-现在仅在切换到THEN时才执行“繁重”查询。
我的姓是“总计”
我们使用上述所有机制收集结果查询:
WITH T AS ( SELECT "@" FROM "" WHERE "" = '' ) ( SELECT TRUE FROM "" d WHERE ("3", "") = (19091, (TABLE T)) AND CASE WHEN "$" IS NULL AND "" IS NOT TRUE THEN ( SELECT ""[1] IS TRUE FROM "" WHERE "@" = d."@" ) END LIMIT 1 ) UNION ALL ( SELECT TRUE FROM "" d WHERE ("", "") = ((TABLE T), 19091) AND CASE WHEN "$" IS NULL AND "" IS NOT TRUE THEN ( SELECT ""[1] IS TRUE FROM "" WHERE "@" = d."@" ) END LIMIT 1 ) LIMIT 1;
自定义[Under]指数
训练有素的眼睛注意到UNION子单元中的索引条件略有不同-这是因为我们已经在表上有了适当的索引。 如果他们不在那,那么就值得创建:
Document(文档3,文档类型)和
Document(文档类型,员工) 。
关于ROW条件中的字段顺序当然,从计划者的角度来看,您可以同时写(A,B)=(constA,constB)和(B,A)=(constB,constA) 。 但是,当按索引中字段的顺序写入时,这样的请求在以后调试时更方便。
有什么计划?
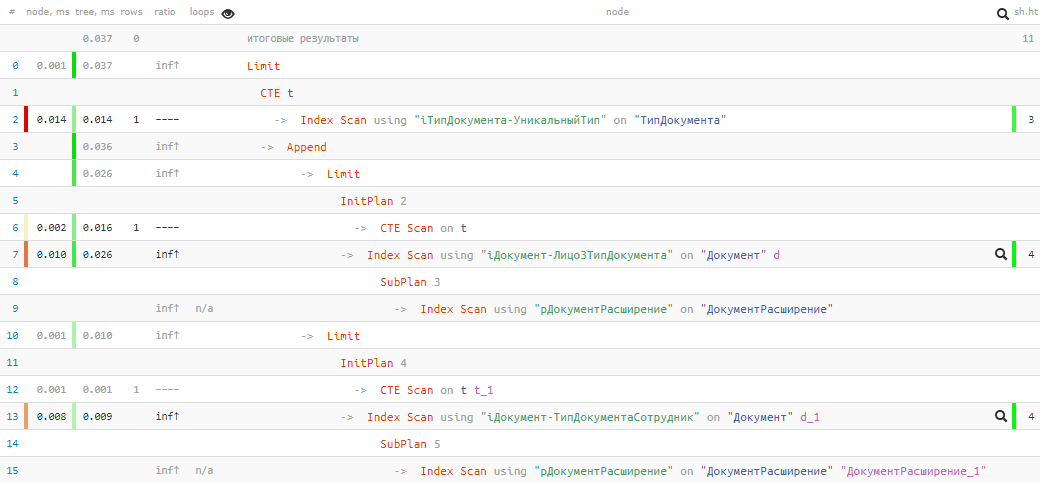 [看explain.tensor.ru]
[看explain.tensor.ru]不幸的是,我们并不幸运,在第一个UNION块中什么也没有发现,因此第二个仍然执行。 但是,即使只有
0.037ms和11个缓冲区 !
我们使用相当简单的方法,加快了请求的速度,并将内存中的数据“抽取”
次数减少
了数千次 ,这是一个很好的结果,并且复制粘贴很少。 :)