
问候哈伯。
如果有人运行石墨网系统并遇到低语的存储性能问题(IO,磁盘空间消耗),则将ClickHouse替换为替代产品的机会应该针对一个。 该语句表示第三方实现(例如carbonwriter或go-carbon)已用作守护程序的接收指标。
ClickHouse很好地解决了上述问题。 例如,从耳语中传输2TiB数据后,它们就适合300GiB。 我不会详细介绍比较;有关该主题的文章足够多。 此外,直到最近,我们的ClickHouse储存装置还算完美。
消费问题
乍一看,一切都应该运作良好。 根据文档 ,我们为度量标准存储方案创建一个配置(以下简称为``reservation'' ),然后根据所选的石墨网后端建议创建表: carbon-clickhouse + 石墨-clickhouse或graphouse ,具体取决于所使用的堆栈。 而且...定时炸弹来了。
为了了解哪一个,您需要知道* MergeTree ClickHouse引擎系列的表中数据的插入方式和进一步的生命周期(图表摘自Alexei Zatelepin的演示文稿 ):
- 插入一个数据

- 根据创建表时指定的
ORDER BY键对写入磁盘之前的每个此类块进行排序。 - 排序后,将
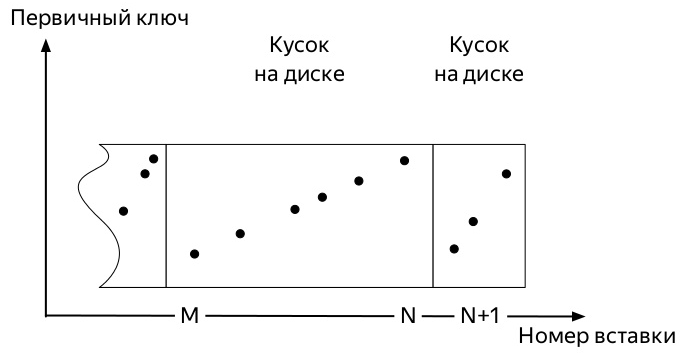
- 服务器在后台监视此类碎片不多,并开始后台
merge ,以下称为merge)。

- 一旦数据不再主动
partition ,服务器将立即停止运行合并,但是您可以使用OPTIMIZE命令手动启动该过程。 - 如果分区中仅剩一块,则无法使用通常的命令启动合并,必须使用
OPTIMIZE ... FINAL
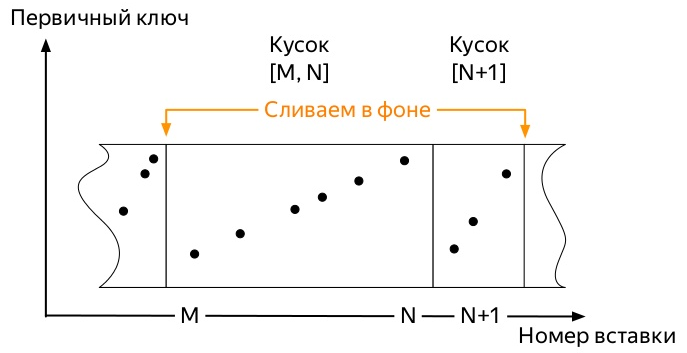
因此,第一个指标到来了。 而且它们占据了一定的空间。 随后的事件可能会因许多因素而略有不同:
- 分区密钥可以很小(一天)也可以很大(几个月)。
- 保留配置可以在活动分区(度量记录所在的位置)内容纳几个重要的数据聚合阈值,也可以不容纳。
- 如果有大量数据,则最早的碎片(由于背景合并而已)可能已经非常庞大(当选择次优分区键时),将无法摆弄新鲜的小碎片。
一切总是一样的。 只有在以下情况下,ClickHouse中的指标所占的位置才会增加:
- 不要手动应用
OPTIMIZE ... FINAL或 - 请勿将数据持续不断地插入所有分区中,以免迟早启动后台合并
第二种方法似乎最容易实现 因此,他错了 并先经过测试。
我编写了一个相当简单的python脚本,该脚本在过去4年中每天发送虚拟指标,然后每小时运行一次。
由于ClickHouse DBMS的所有工作都基于这样一个事实,即该系统迟早会完成所有后台工作,但是尚不知道何时,我迫不及待要等到那些庞大的旧文件开始与新的小型文件合并。 很明显,我们必须寻找一种自动化强制优化的方法。

看一下system.parts表的结构。 这是有关ClickHouse服务器上所有表的每个部分的全面信息。 除其他外,它包含以下各列:
- 数据库名称(
database ); - 表名(
table ); - 分区名称和ID(
partition & partition_id ); - 作品创建的时间(
modification_time ); - 一块中的最小和最大日期(按天划分)(
min_date和max_date );
还有一个system.graphite_retentions表,其中包含以下有趣的字段:
- 数据库名称(
Tables.database ); - 表名(
Tables.table ); - 应当应用下一个汇总(
age )的度量标准的age ;
因此:
- 我们有一个表和一个汇总规则表。
- 合并它们的交集并获得所有* GraphiteMergeTree表。
- 我们正在寻找以下所有分区:
- 一件以上
- 或应用以下聚合规则的时间到了,而且
modification_time早于该时刻。
实作
这个要求 SELECT concat(p.database, '.', p.table) AS table, p.partition_id AS partition_id, p.partition AS partition,
返回* GraphiteMergeTree表的每个分区,这些分区的合并应释放磁盘空间。 剩下的就是小事情:用OPTIMIZE ... FINAL请求对它们进行遍历。 最终实现还考虑了无需触摸具有活动记录的分区的那一刻。
这正是石墨通道优化器项目所做的。 Yandex.Market的前同事在产品中对其进行了测试,其工作结果如下所示。

如果您使用ClickHouse在服务器上运行该程序,则它将仅在守护程序模式下开始工作。 一个小时执行一次请求,检查是否有超过三天的新分区可以优化。
在不久的将来-至少提供deb软件包,并在可能的情况下-rpm。
UPD:软件包可在github版本上找到 ,工作映像可在innogames /石墨-ch-optimizer存储库中的docker-hub上找到。
而不是结论
在过去的9个月里,我在InnoGames公司的ClickHouse和石墨网交界处度过了很多时间。 这是一个很好的体验,它使从耳语快速转换为ClickHouse作为指标存储区成为可能。 我希望本文就像一个周期的开始一样,内容是关于我们对堆栈的各个部分进行了哪些改进以及将来将要进行的改进。
我与v0devil一起花了几公升啤酒和管理天来进行请求开发,对此我要表示感谢。 并且也用于阅读本文。
github上的项目页面