PostgreSQL使用有关目标表中数据值分布的
累积统计信息来选择最有效的查询执行计划。
通过显式运行
ANALYZE和
VACUUM ANALYZE命令或在后台通过
autovacuum / autoanalyze进程对其进行更新 。 但是,如果统计信息没有时间更新,则可能会出现问题。
如何发现并解决此类问题?
完全可能发生这种情况的主要选项是表中的数据集发生了巨大变化。 也就是说,它在其上
驱动了大量INSERT / UPDATE / DELETE或只是将数据“倾倒”到一个空表中(例如,
从备份还原时) 。
标准
恢复实用程序pg_restore的帮助甚至明确指出:
恢复后,有必要对每个已还原的表运行ANALYZE,以便优化器接收最新的统计信息。
因此,如果您正在对数据库执行类似的操作-别偷懒,请立即对大多数“粗体”表或整个数据库运行
ANALYZE 。
我们确定问题的存在
“全为坏”的情况到底是什么原因造成的? 通常是这样的:
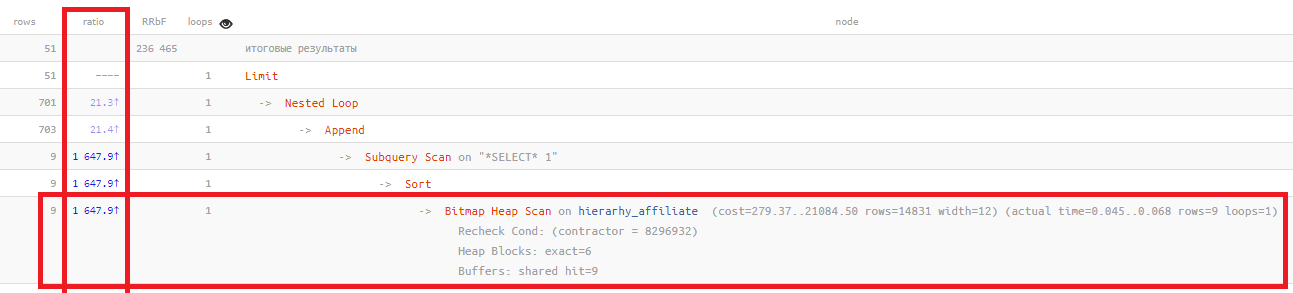 比率
比率列仅显示基于统计计划的记录数与实际读取的数之间的“时间”关系:
Bitmap Heap Scan on ... (... rows=14831 ...) (actual ... rows=9 ...)
该值越高,统计信息反映表中实际情况
的效果越差 。 通常,在此示例中,它通常不
超过数百 次,即数千次 。
这导致选择无效的计划,结果是
对基地的最大负担 。 要快速删除它,您只需要听取手册的建议并在主表上进行
ANALYZE 。
对于上面的示例,这是此操作前后数据库服务器上的CPU负载:
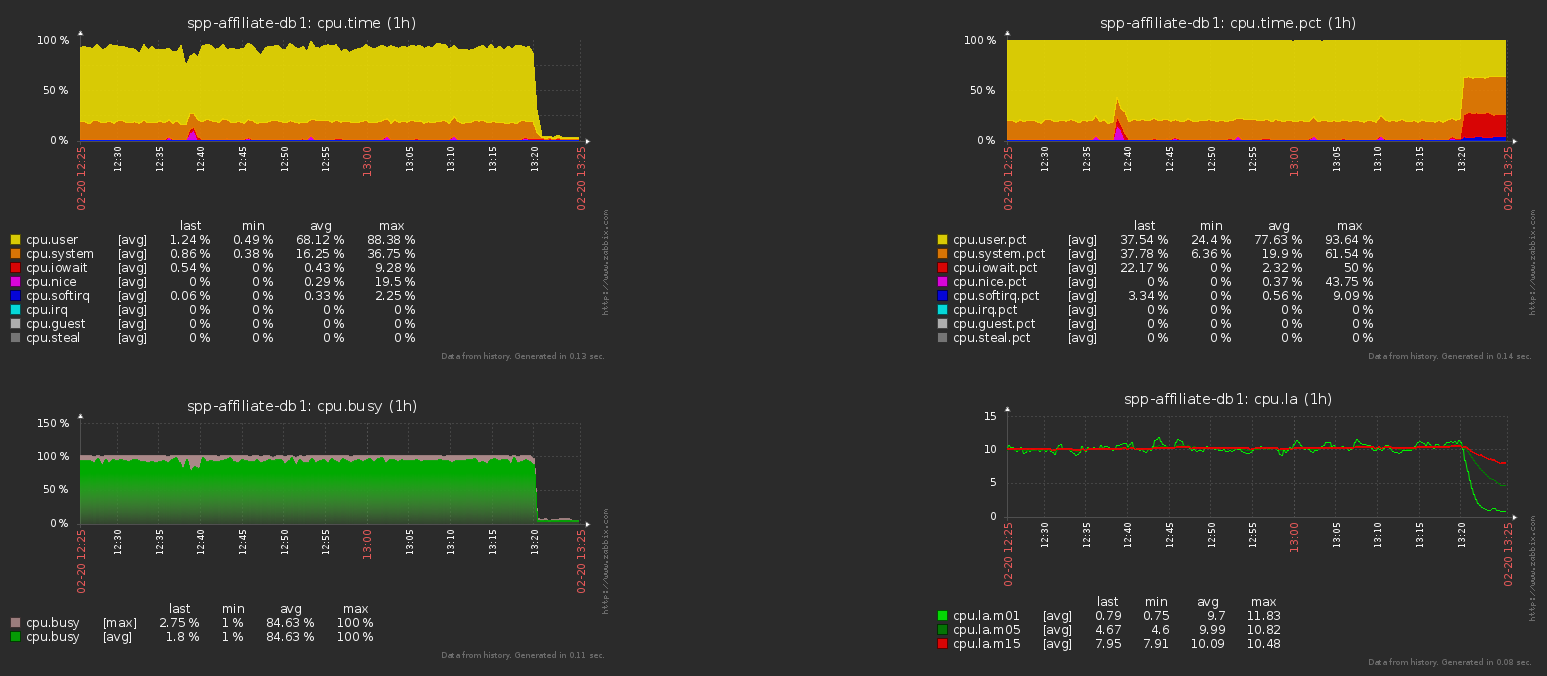
经常更新的表
但是,如果表确实更改了大量记录怎么办? 例如,这是某种缓冲区或处理队列,在其中不断添加新记录而删除旧记录。
在这种情况下,以下
配置参数将为我们提供帮助:
autovacuum_naptime (整数)
设置单个数据库两次自动清理运行之间的最小延迟。 自动清理守护程序按指定的时间间隔扫描数据库,并在需要此数据库中的表时发出VACUUM和ANALYZE命令。 如果指定的该值不带单位,则视为以秒为单位设置。 默认情况下,延迟为一分钟(1分钟)。 服务器启动时,只能在postgresql.conf或命令行中设置此参数。
autovacuum_analyze_threshold (整数)
设置将对单个表执行ANALYZE的最小添加,修改或删除的元组数。 默认值为50元组。 服务器启动时,只能在postgresql.conf或命令行中设置此参数。 但是, 可以通过更改表的存储设置来覆盖此值。
autovacuum_analyze_scale_factor (浮点数)
指定选择ANALYZE命令阈值时将添加到autovacuum_analyze_threshold的表大小的百分比。 默认值为0.1(表大小的10%)。 服务器启动时,只能在postgresql.conf中或在命令行上设置此参数。 但是, 可以通过更改表的存储设置为该表重新定义该值。
SWSS
有时,在设置服务器时,
autovacuum_naptime被 “
压碎 ”为“一天一次”(1d),以
使autoVACUUM较少地遍历数据库并消耗较少的资源。
有时,尽管很少,但是甚至有道理-例如,如果您在一个数据库中有
成千上万个表/节 (即使它们以不同的模式布置)。
因为需要确定整个列表中特定表的确切定义,所以在自动清空过程的初始化期间,它
会占用相当大的资源份额并降低服务器的速度 。
只是在这种情况下,频繁修改表会遇到问题。
在这里-设置更适当的启动间隔,或者出于某些应用原因(例如,外部计时器或在队列处理的下一阶段结束之后),以“手动”模式根据此类表追踪ANALYZE。
同志,请保持最新统计!