提取信息时,通常需要找到
此类文本片段。 在搜索的上下文中,查询可以由用户(例如,用户在搜索引擎中输入的文本)或系统本身生成。 通常,我们需要将传入查询与已经建立索引的查询进行匹配。 在本文中,我们将研究如何构建一个系统来解决数十亿个请求而无需在服务器基础结构上花费大量资金。
首先,我们正式定义问题:
给定一组固定的查询 传入请求 和整数 。 需要找到这样的查询子集 R = \左\ {q0,q1,...,qk \右\} \子集Q 对每个请求 更像 比中的任何其他请求 。
例如,使用这组查询
:
{tesla cybertruck, beginner bicycle gear, eggplant dishes, tesla new car, how expensive is cybertruck, vegetarian food, shimano 105 vs ultegra, building a carbon bike, zucchini recipes}
和
您可以预期以下结果:
请注意,我们尚未定义
相似性标准。 在这种情况下,这几乎意味着任何东西,但是通常可以归结为基于关键字或向量的某种形式的相似性。 使用基于关键字的相似性,如果两个查询包含足够的常用词,我们可以发现它们相似。 例如,查询“在慕尼黑开餐馆”和“慕尼黑最佳餐馆”类似,因为它们包含单词“ restaurant”和“ munich”。 而且“慕尼黑最佳餐厅”和“慕尼黑哪里吃饭”这两个查询已经不太相似了,因为它们只有一个通用词。 但是,如果第二对请求结果相似,那么在慕尼黑寻找餐厅的人会更好。 因此,我们将帮助基于向量的比较。
单词的向量表示
单词的向量表示是一种在自然语言处理中用于将文本或单词转换为向量的机器学习技术。 将任务移到向量空间中,我们可以对向量使用数学运算-求和和计算距离。 要在相似词之间建立链接,可以使用向量聚类的传统方法。 这些操作在原始词空间中
的含义可能并不明显,但优点是现在我们可以使用各种数学工具。 如果您对单词向量及其应用的详细信息感兴趣,请阅读有关
word2vec和
GloVe的信息 。
我们有一种从单词生成向量的方法,现在我们将它们收集到文本向量(文档或表达式的向量)中。 最简单的方法是添加(或平均)文本中所有单词的向量。
 图1:查询向量。
图1:查询向量。现在,您可以通过在向量空间中表示两个文本(或查询)并计算向量之间的距离来确定它们的相似性。 通常,为此使用角距离。
结果,单词的向量表示允许不同类型的文本匹配,这补充了基于关键字的匹配。 您可以探索请求的语义相似性(例如,“慕尼黑最好的餐馆”和“慕尼黑哪里吃饭”),这是我们以前无法做到的。
近似最近邻居搜索
现在,我们可以优化原始查询匹配问题:
给定一组固定的查询向量 传入向量 和整数 。 您需要找到这样的向量子集 R = \左\ {q0,q1,...,qk \右\} \子集Q 这样从 每个向量 比到中任何其他向量的距离短 。
这称为寻找最接近的邻居的任务。 在低维空间中,有
许多算法可以快速解决问题。 但是当使用单词的矢量表示时,我们通常使用高维矢量(100-1000维)进行运算。 此处提到的方法不再起作用。
没有合适的方法可以快速确定高维空间中的最近邻居。 因此,我们通过允许使用近似结果来简化问题:我们将不满足于仅返回一些最接近或
在某种程度上接近的邻居,而不是总是返回最接近的向量。 这被称为最近邻居任务的近似搜索,并且是一个活跃的研究领域。
分层小世界
分层可导航小世界图(
HNSW )是用于近似搜索最近邻居的最快算法之一。 HNSW中的搜索索引是一个多层结构,其中每个层都是一个接近图。 每个图节点对应于查询向量之一。
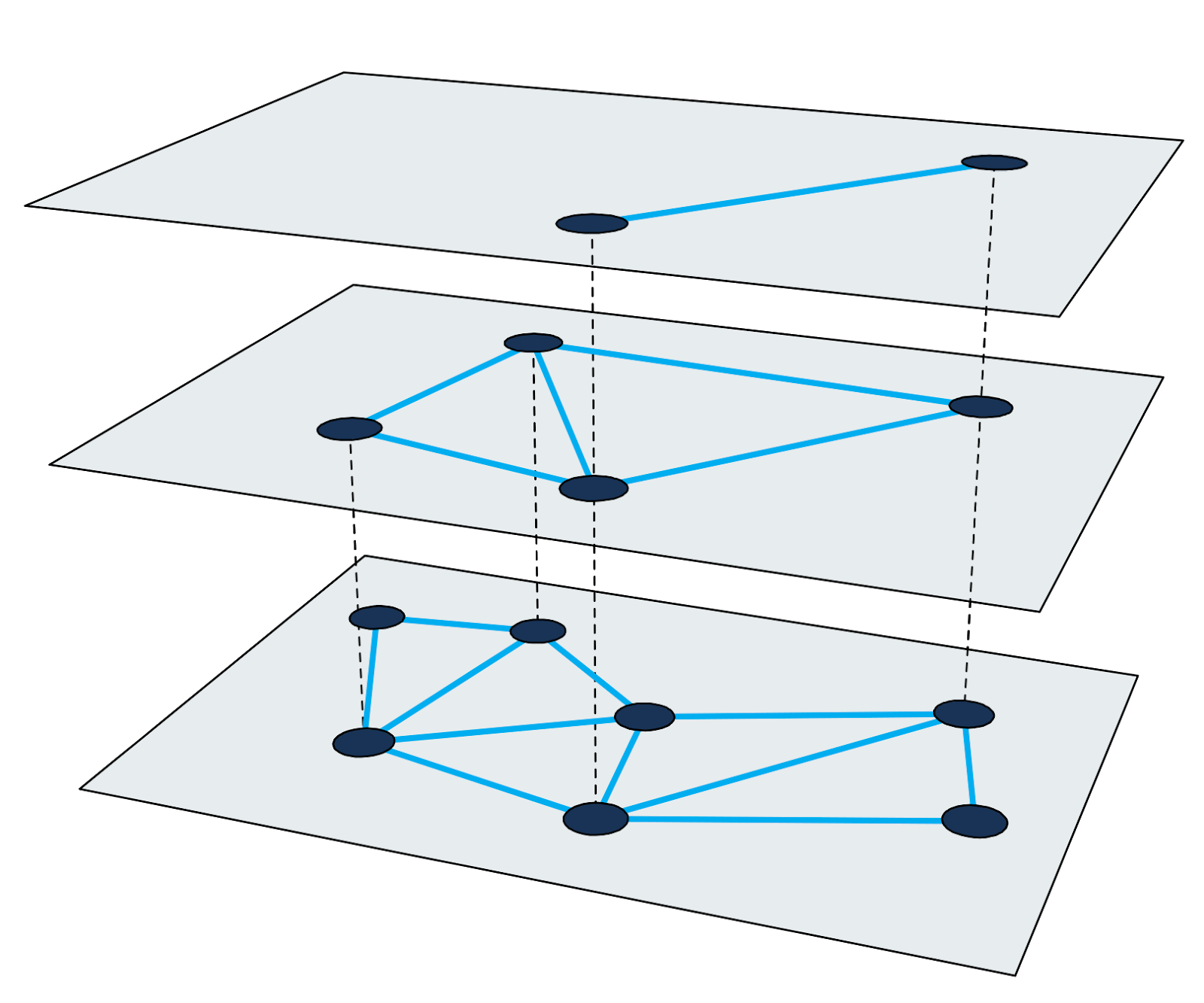 图2:多级接近图。
图2:多级接近图。使用放大方法在HNSW中查找最近的邻居。 它从最高级别的输入节点开始,并在每个级别上递归执行贪婪图遍历,直到在底部达到局部最小值。
有关算法和搜索技术的详细信息在科学工作中得到了很好的描述。 重要的是要记住,每个最近邻的搜索周期都包括遍历图的节点并计算向量之间的距离。 我们将在下面查看这些步骤,以使用此方法创建大型索引。
索引数十亿查询的难度
假设我们需要索引40亿个200维查询向量,每个维都由一个四字节浮点数表示(40亿个足以使任务有趣,但是您仍然可以将节点ID存储为常规的四字节数) 。 粗略的计算告诉我们,单独的向量大小将约为3 TB。 由于大多数现有库都使用RAM容量来近似搜索最近的邻居,因此我们将需要一个非常大的服务器,以便至少将向量推入RAM。 请注意,这并未考虑大多数方法所必需的附加搜索索引。
在我们搜索引擎发展的整个历史中,我们使用了几种不同的方法来解决此问题。 让我们考虑其中的一些。
数据子集
不允许我们完全解决问题的第一种也是最简单的方法是限制索引中向量的数量。 取十分之一的数据,我们创建了一个索引,该索引需要-令人惊讶-内存的10%。 但是,搜索的质量已经下降,因为现在我们操作的查询更少了。
量化
在这里,我们使用了所有数据,但是使用了
量化来减少了它们(我们使用了不同的量化技术,例如乘积量化,但是在这种数量的数据下无法达到预期的工作质量)。 通过消除一些错误,我们能够用量化的单字节版本替换原始向量中的所有四字节数字。 向量的RAM量减少了75%。 但是,我们仍然需要750 GB的内存(不计算索引本身的大小),这仍然是一个非常大的服务器。
用Granne解决内存问题
所描述的方法具有其优点,但是它们需要大量资源并且搜索质量较差。 尽管
有些库的响应时间不到1毫秒,但我们可能会牺牲速度以换取较低的硬件要求。
Granne (基于图的近似最近邻居)是Cliqz开发并用于搜索此类查询的HNSW库。 它具有开源代码,但是该库仍在积极开发中。 改进的版本将于2020年在
crates.io上发布。 它是用Rust编写的,带有Python插件,旨在利用竞争力处理数十亿个向量。 从查询向量的角度来看,有趣的是Granne具有一种特殊的模式,与其他库相比,这种模式所需的内存要少得多。
查询向量的紧凑表示
减小查询向量的大小将为我们带来很多好处。 为此,让我们回头考虑创建向量。 由于查询由单词组成,而查询向量是单词向量的总和,因此我们可以明确拒绝存储查询向量,并根据需要对其进行计算。
您可以以单词集的形式存储查询,并使用查找表查找相应的向量。 但是,我们通过将每个查询存储为与查询中的单词向量相对应的整数ID列表来避免重定向。 例如,将查询“慕尼黑最佳餐厅”保存为
在哪里
-这是单词“ best”的向量ID,以此类推。假设我们有少于一千六百万个单词向量(超过这个数目,每个单词将花费1个字节),那么您可以使用3个字节来表示所有单词ID。 也就是说,除了存储800字节(或量化矢量的情况下为200字节)之外,我们将仅为此请求存储12个字节(这并非完全正确。由于请求包含不同数量的单词,因此我们还需要将列表偏移量存储在单词index中。每个请求将需要5个字节)。
至于词向量,我们都需要它们。 但是,单词的数量比通过组合这些单词可以创建的查询的数量小得多。 这意味着单词的大小不是那么重要。 如果将单词向量存储为简单数组中的四字节浮点版本
,那么每百万个字我们需要不到1 GB的空间。 此卷可以轻松放入RAM。 现在查询向量看起来像这样:
{v _ {{i_ {best}}} + {v _ {{i_ {rest}}}} + {v _ {{i_ {of}}} + {v _ {{i_ {munich}}}} 。
查询提交的最终大小取决于查询中的单词总数。 对于40亿个查询,这大约是80 GB(包括单词向量)。 换句话说,与原始单词向量相比,大小减少了97%,与量化向量相比减少了90%。
还有一件事。 一次搜索,我们需要访问图的大约200-300个节点。 每个节点有20-30个邻居。 因此,我们需要计算从输入查询向量到索引中4000-9000个向量的距离。 而且,我们需要生成向量。 动态创建查询向量需要多长时间?
事实证明,使用相当新的处理器,可以在几毫秒内解决此问题。 以前在1毫秒内运行的请求现在可以在5毫秒内运行。 但是随后我们将向量的内存量减少了90%。 我们很高兴接受这种妥协。
在向量和索引的内存中显示
上面,我们解决了减少向量的内存量的问题。 但是,在解决了这个问题之后,索引结构本身成为了限制因素。 现在您需要减小其大小。
在Granne中,图结构以邻接列表的形式紧凑地存储,每个节点的邻居数量可变。 也就是说,内存几乎不会浪费在元数据上。 索引结构的大小在很大程度上取决于设计参数和图形属性。 不过,要了解索引的大小,可以说我们可以为40亿个向量建立索引,总大小约为240 GB。 对于大型服务器上的内存使用,这可能是可以接受的,但可以做得更好。
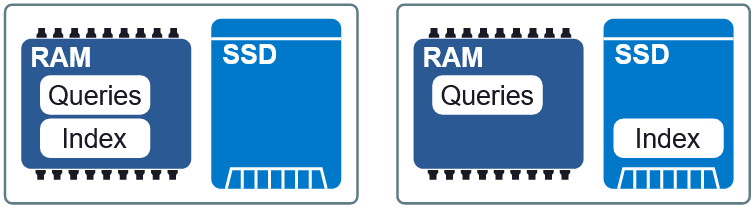 图3:RAM和SSD中的两种不同布局。
图3:RAM和SSD中的两种不同布局。Granne的一个重要特性是能够
在内存中显示索引和查询向量。 这使我们可以延迟加载索引并与多个进程共享内存。 索引和查询文件在内存中分为单独的显示文件,可以在RAM和SSD上以不同的布局使用。 如果对延迟的要求略低,则将索引放在SSD上,请求到RAM,我们将保持可接受的速度,而不会占用过多的内存。 在本文的结尾,我们将看到这种折衷的外观。
改善数据局部性
在我们当前的配置中,当索引位于SSD上时,每个请求最多需要从磁盘读取200-300次。 您可以尝试通过排列其向量非常接近以使它们的HNSW节点位于索引中且彼此之间也不远的元素来增加数据的局部性。 数据局部性提高了性能,因为单个读取操作(通常从4 KB中提取)更可能包含遍历图形所需的其他节点。 从而减少了每次搜索的数据检索次数。
 图4:数据局部性减少了信息检索。
图4:数据局部性减少了信息检索。应当注意,对元素进行重新排序不会影响搜索结果,这是一种加快搜索速度的方法。 也就是说,顺序可以是任意顺序,但并非每个选项都会加快搜索速度。 找到最佳顺序非常困难。 但是,我们成功使用的启发式方法是按每个查询中最
重要的单词对查询进行排序。
结论
我们使用Granne来创建和维护具有查询向量的数十亿美元的索引,以便搜索内存消耗相对较低的类似查询。 下表显示了不同方法的要求。 对搜索过程中的延迟的绝对值表示怀疑,因为它们在很大程度上取决于被认为是可接受的响应。 但是,此信息描述了这些方法的相对性能。
*分配大于所需数量的内存索引会导致某些节点(经常访问)的缓存,从而减少了搜索的延迟。 为此,不使用内部缓存,仅使用内部OS工具(Linux内核)。应该注意的是,本文中提到的某些优化不适用于解决用不可分解的向量查找最近邻居的一般问题。 但是,它们适用于可以从更少的部分生成元素的任何情况(如单词和查询的情况)。 否则,您仍然可以将Granne与源向量一起使用,与其他库一样,它只占用更多的内存。