哈勃!
房屋信贷是一个大型且动态的系统,有时很难跟踪。 为了帮助员工及时了解所有新闻和变化并与时俱进,我们正在积极引入机器学习算法。 在我们的银行中,聊天机器人已经承担了运营商的一部分工作,不仅通过专家分析客户评论,还通过处理自然语言的智能算法来分析客户评论。
今天,我将告诉您,我们如何帮助银行服务运营专家摆脱经常查看监视系统仪表板的需要,即他们要求机器学习提供帮助。 那就是我们得到的。

手动监控如何工作?
操作专家的典型工作场所如上图所示,他大部分时间都花在仪表板上。 系统中的任何可疑活动(例如,当网络中断或NullPointerException降雨时)都会立即引起注意-调查将立即开始。
人不是机器。 他会分心,去吃饭,接电话。 而且,当图表的数量超过一百时,将它们全部绑在一起并触及本质是困难的。
另一个问题是,有一系列错误会不断发生,但不会严重影响系统的行为。 例如,第三方微服务掉线,仪表板明显晃动,但实际上该系统已处于危险之中。 乍一看,并不总是很清楚异常行为的严重性以及其背后的原因。 要详细确定原因,您需要转到服务器并彻底研究日志。 每天必须进行数十次这样的操作。 让我们至少部分地将她托付给汽车。
机器学习作为智能助手
数据主要有三个来源:Zabbix,ElasticSearch和一个内部业务指标监视系统。 我们使用Zabbix监视系统的各种入口点的硬件,网络和可用性。 使用ElasticSearch,解析并提取消息日志。 各种错误,执行和查询都用作指标。 但是,业务分析师会监视用户的绩效:转移,销售和其他业务活动的数量。 数据以每分钟一次的频率收集并添加到数据库中。 好了,数据已经收集到了,现在该写一堆if了,将机器学习付诸实践。
我们将问题表述为:在输入系统指标时,我们将对系统的最终状态进行分类:正常或异常。 在这种情况下,问题完全适合与老师一起学习的范式。 这意味着必须标记我们的整个训练数据集。 换句话说,系统操作的每一分钟都应带有0(正常行为)或-1(异常行为)的标签。
在生活中,事实证明并非所有事物都像我们想要的那样乐观。 通常,并非所有事件都记录在JIRA中,很多残留在邮件中并且没有超出它,有时异常的时间限制是模糊的或不准确的。 事实证明,在历史数据领域中构建高质量的数据集并不是一件容易的事。
当新数据刚刚开始布局时,让我们尝试从现有的资源中压缩收益。 对于数据没有标记的情况,使用没有老师的学习算法。 我们将从以下事实出发:大多数情况下,系统正常运行,但偶尔会发生不可预见的事件:错误(没有错误的情况),基座掉落或例如挖掘机Petr碰到数据中心电缆。 因此,我们将任务简化为寻找异常,即寻找新的系统行为(新颖性检测)。
为此,请使用隔离林算法。 它已经在sklearn库中实现。 我们将使用来自监视系统的指标作为功能。
clf = IsolationForest(behaviour='new', max_samples=100, random_state=rng, contamination='auto')
我们将根据历史数据对孤立森林进行培训,并将使用已经设法标记的新数据来评估质量。 因此,仍然需要选择模型超参数和训练数据集的大小。
现在,每分钟收集一次的状态数据将输入到经过训练的模型中,并得到标签0或-1。
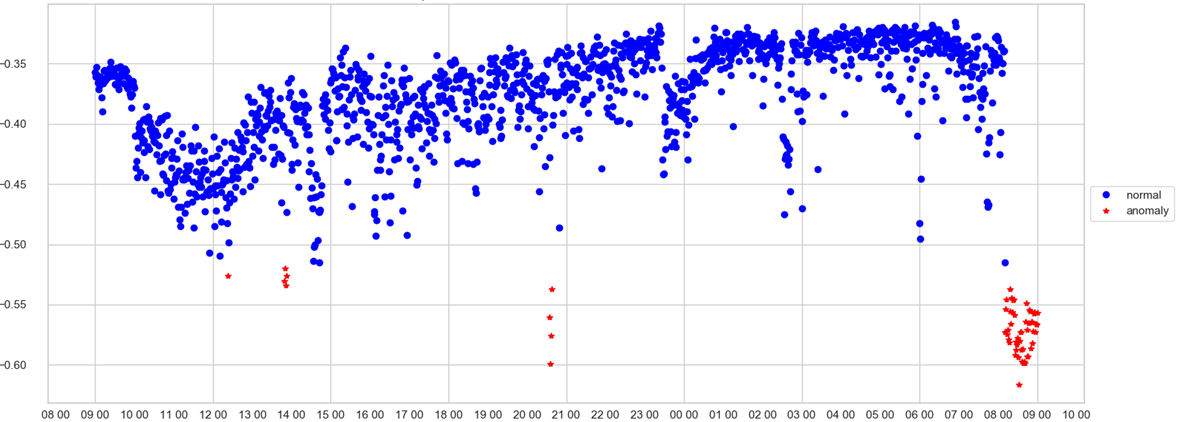
操作员只能跟踪一个时间表。 在X轴上-时间上,在Y轴上-异常分数,即模型在这一分钟异常情况下对系统状态的考虑程度。 如果速度值已通过垃圾箱(模型自行选择),则该点将以红色着色并记录异常。
现在我们了解到该系统以异常模式运行,或者紧急情况几乎实时发生。 这很好,但是在收到有关异常信号时,操作员该怎么办? 要看什么仪表板? 让我们尝试打开模型的“黑匣子”,并了解其如何制定决策。
使用LIME解释模型
有多种方法可以打开训练有素的模型的黑匣子,并了解机器的想法。 使用逻辑回归或决策树,一切都变得清晰,不难理解做出决策的依据。 使用“孤立森林”,事情变得更加复杂。 首先,算法内部存在意外;其次,这是一种没有老师的学习算法。
第一个候选者是LIME库,它使用模型不可知的方法,该方法有助于解释任何模型,主要是模型的输出在类之间具有概率分布。 好的,当然,结果不是概率,而是很快,但是让我们尝试将其归一化为0到1并将其视为概率。 因此,我们能够提供与LIME兼容的输入格式。
LIME解释结果的方式令人失望。 首先,作为一种解释,输出中有几个最重要的标志,在大多数情况下,只有其中一个真正能充分反映决策的实质,其余的则增加了噪音。 第二个缺点是解释不稳定,并且经常会产生不同的征兆列表。 为了获得更稳定的结果,您必须运行几次解释并以某种方式对结果求平均。 我真的不想这么做。
SHAP-人与车之间的桥梁
之后,我们的目光投向了另一个用于解释模型的库-SHAP。 库背后的想法来自博弈论。 该库还具有漂亮的可视化效果。 看完这些示例之后,我们沮丧地意识到SHAP无法解释孤立森林,我们真的想要! 但是,另一方面,SHAP可以自信地剖析XGBoost。 我们以为,如果我们被教导做XGBoost就像孤立森林可以做的一样? 为此,我们提取了整个数据集,并用“孤立森林”标记了它。 而且,作为目标,他们没有上课,而是获得了分数,该分数被分配给“孤立森林”。 我们将通过所有指标来预测“隔离林”所能提供的速度,但只能使用XGBoot! 言归正传。 我们将通过XGBoost运行标记的数据集。 现在,他现在知道如何以与孤立森林相同的方式预测速度。 万岁,现在我们可以使用SHAP!
第一步是创建一个TreeExplainer对象,将模型本身作为参数传递。 接下来,计算shap值,这使我们能够说明模型如何做出此决定。
explainer = shap.TreeExplainer(model) shap_values = explainer.shap_values(X)
SHAP允许您整体解释模型以及特定示例的结果。 例如,您可以使用force_plot()方法获得特定示例的说明,该方法接收输入值和示例本身的值。
shap.force_plot(explainer.expected_value,shap_values[0,:], X.iloc[0,:])
事实证明,以下图表显示了模型的哪些功能以及对决策有多大影响。

我们帮助业务
现在,知道哪些指标对总体异常率有重大贡献,就可以确定问题出现在什么级别,最重要的是确定问题是否对系统的最终用户产生了影响。

每次检测到异常时,都会获得对决策影响最大的指标列表。 如果列表中包含直接跟踪与业务相关的指标的指标,则警报中会以特殊方式提及此指标,从而自动增加异常的优先级。
这只是使用机器学习来增强和自动化监视系统的第一步,也是重要的一步,这可以显着提高识别异常系统行为的原因和影响的速度。
参考文献:scikit-learn.org/stable/modules/generation/sklearn.ensemble.IsolationForest.htmlgithub.com/marcotcr/limegithub.com/slundberg/shap