有时,任务是将线性参数中作为参数传递到SQL查询中的相同数据“按列”“粘合”到整数选择中。
有时是怎么做的:
WITH T1 AS ( SELECT row_number() OVER() rn , unnest v1 FROM unnest('{1,2,3,4}'::integer[]) ) , T2 AS ( SELECT row_number() OVER() rn , unnest v2 FROM unnest('{5,6}'::integer[]) ) SELECT T1.v1 , T2.v2 FROM T1 LEFT JOIN T2 USING(rn);
v1 | v2 ------- 1 | 5 2 | 6 3 | 4 |
也就是说,首先将每个阵列“扩展”到样本中,进行编号,然后将此数字用作CTE连接密钥...
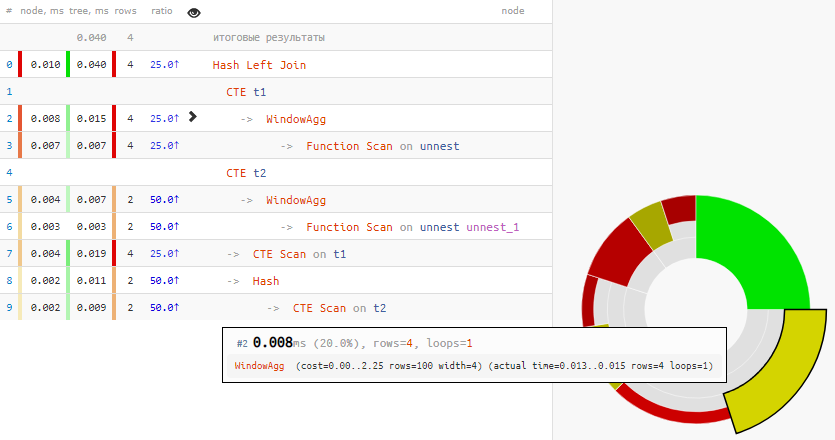 [看explain.tensor.ru]
[看explain.tensor.ru]平凡的
超过四分之一的时间都花在了几个WindowAgg上!
但是,如果我们使用的PG版本不低于9.4,则
可以使用WITH ORDINALITY对任何SRF的结果进行编号,包括unnest:
WITH T1 AS ( SELECT * FROM unnest('{1,2,3,4}'::integer[]) WITH ORDINALITY T(v1, rn) ) , T2 AS ( SELECT * FROM unnest('{5,6}'::integer[]) WITH ORDINALITY T(v2, rn) ) SELECT T1.v1 , T2.v2 FROM T1 LEFT JOIN T2 USING(rn);
 [看explain.tensor.ru]
[看explain.tensor.ru] 。
因此,我们完全摆脱了窗口函数的使用。
多参数UNNEST
但是从效率的角度来看,到目前为止并不是所有的事情都很好-几乎一半的时间都花在了Hash Left Join上。
作者显然是从第一个数组确实更长的假设出发的,这就是他使用LEFT JOIN的原因。 但是这种假设并不总是正确的,并且会引起问题。
为了解决这个问题,我们将同时
对多个数组使用
unnest ,它们是在同一版本9.4中出现的:
SELECT * FROM unnest( '{1,2,3,4}'::integer[] , '{5,6}'::integer[] ) T(v1, v2);
结果,请求和计划几乎一无所有:
Function Scan on t (cost=0.01..1.00 rows=100 width=8) (actual time=0.006..0.007 rows=4 loops=1)
因此,犯错的机会要少得多。 是的,执行时间提高了数倍-在更长的数组上,效果将更加明显。