我的职责范围是北奥塞梯共和国的签帐部门,该地区三个地区有十万个个人帐户。 对于背景,我将告诉您如何获取报表。
正如他们所说,他开始与Rosreestr一起工作:他通过访问USRN的联邦州财产检查局打开了请求 ,输入了密钥,填写了搜索表格,单击“查找”,选择了“住宅建筑”或“公寓”类型的对象,订购了摘录,下载了电子文件,将其转换为人类可读(*)格式,然后保存。 一切都很简单,但并非没有细微差别。
主要问题是,在许多情况下,搜索会产生几个合适的对象,因此您必须确定要为该语句排序的对象。 我没有发现任何明显的标准,也没有人帮助我。 我总是订购所有合适的选项-通常有两个,有时三个,偶尔四个。 在大多数情况下,一个文件被证明是摘录,其余文件是“假人”:“没有信息”。 在某些情况下,所有文件都被证明是“假人”。 僵局:花了钱,没有信息。
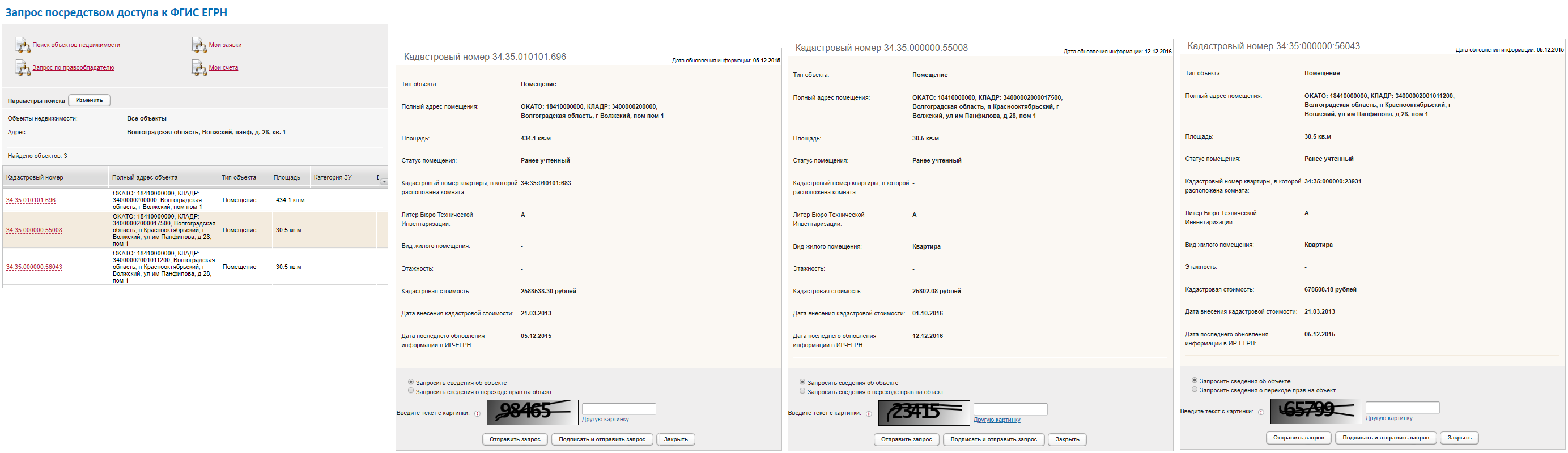
新同事在一个不经意的交谈中解决了这个问题:在进入FSIS USRN之前,您需要突破Rosreestr公开部分中的地址。 在那里,我们检查有关产权转让的信息的可用性,并且已经准备好地籍号,我们就订购摘录。 这稍微延长了(同时使它变得更容易,更快!)放电路径,但是它非常有用,因为 就我们的目的而言,通常只需提供带有权利移交日期的屏幕截图即可; 另外,我使用这些数据在GIS实用程序中工作。
因此:
- 在地址处,我们确定财产的地籍号码,其中(在财产中)有关于财产权转让的信息(第一验证码);
- 在这个地籍号上,我们订购了一个提取物(第二个验证码);
- 等待答案,保存文件;
- 我们会获得文档的人工可读(*)副本(第三个验证码)。
最初,我每个月要发表十二个声明,所以根本就没有自动化问题。 然后-笨蛋! 一百五十! 一包! 我崩溃了。
现在是幻灯片。
zoldaten 自动执行提取请求 ,甚至击败了验证码 。 我简化了将提取物简化为易于理解的形式(*)。
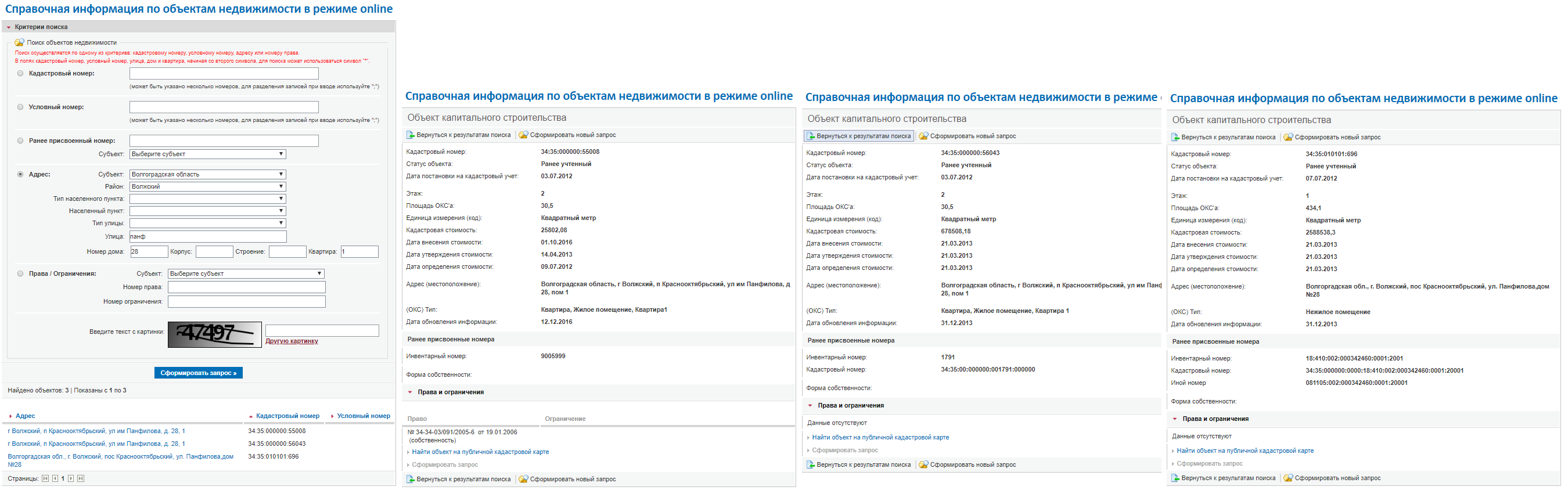
- 我们从工作表“#请求的地址列表”开始:
- 局域网和地址-我们从客户那里收到的初始数据; 接收到的语句将按照在“地址”列中写入的方式进行调用(但这并不准确,请参见下文);
- 地籍号码-我们在Rosreestr的公开部分找到的那个是过程的第一阶段;
- 请求-确认请求的创建后,我们将保存其编号,以后,需要该编号来控制整个流程,联系技术支持等。 -过程的第二阶段。
- 工作表“ #Main”:单击“处理所有文件”按钮。 以每分钟5至50件的速度(取决于对文件存储的访问速度),我们获得了PDF格式的人类可读(*)摘录。
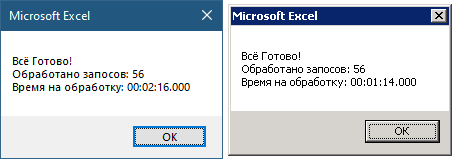
- 我们保存报告,然后发送给客户。
要使其正常工作需要做什么。
- 当然,允许宏;
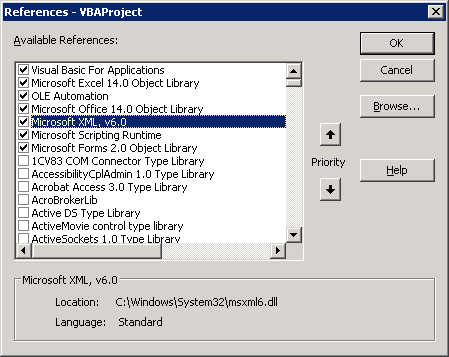
- 包括指向用于处理XML的组件的链接(Alt + F11>工具>引用,在列表中找到带有XML字母的内容,然后进行检查);
- 启用文件扩展名的显示-否则,Windows内置的存档器将无法运行;
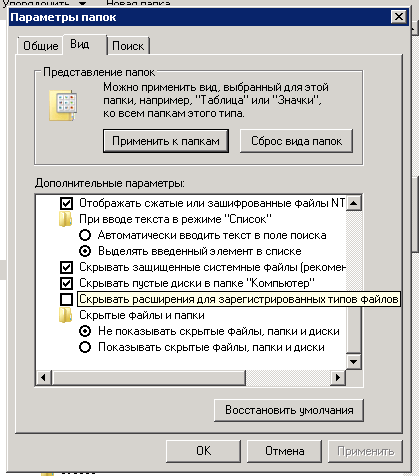
- 将从Rosrestrestra收到的所有文件“ Response-80- .zip”放在一个文件夹中; 在此过程中,“ Response-80- .zip” 以外的所有文件都将从该文件夹中删除 ; 语句将保存在此处; 所有文件将被处理。
在哪里检查:
- 终端服务器Windows 2008 + Office 2010-适用于XML版本3.0和6.0;
- Windows 10 + Office 365-仅适用于XML 3.0。
另外。
- 愚人的保护很少。
- 如果有两个具有相同地籍编号的陈述,则一切都落空。 您需要查看日志(在单独的文件中),删除多余的文件,并从头开始重新启动所有内容。
- 仅执行关于权利和“假人”转让的声明,不处理“关于对象的信息”类型的声明;
- 如果源数据不包含所需的地籍号(例如,工作表通常为空,我们开始处理),则在语句本身的地址处命名语句;
- 如果有两个或两个以上具有相同地址的语句,则在文件名中写入一个附加的数字;
- 工作表名称-硬编码,不能更改; 每次开始时,这些(和两个隐藏的)工作表之外的所有内容都会从书中删除。
我没有对代码发表评论,那里绝对没有有趣的东西-常规循环,遍历XML节点,将变量扩展到单元中。
该代码是开放的,没有任何限制。
(*)“可读”一词在此页面上出现了6次。