我的同事Rafael Grigoryan eegdude 最近写了一篇文章,介绍了人类为何需要脑电图以及其中可以记录哪些重要现象。 今天,在继续神经接口这一主题时,我们使用P300机制在游戏中记录的一个开放数据集来可视化EEG信号,查看被称为电势的结构,构建主要的分类器,评估可以预测此类被称为电势存在的质量。
让我提醒您,P300是所谓的电位(VP),是与决策和区分刺激相关的大脑的特定反应(我们将在下面看到)。 它通常用于构建现代BCI。
为了进行EEG分类,您可以打电话给朋友,编写关于VR中的浣熊和恶魔的游戏,写下您自己的反应并撰写科学文章(我将在其他时间讨论),但是幸运的是,来自世界各地的科学家为我们进行了一些实验,仅下载数据即可。
在猫的帮助下,可以找到如何通过逐步的代码和可视化在P300上构建神经接口以及对存储库的链接的分析。
本文仅显示代码中的要点,在jupyter Notebook中的完整可复制版本可在此处搜索
从脑电图的角度来看,P300只是在某些时间的某些通道爆发。 调用它的方法有很多,例如,如果您专注于一个对象,并且在任意时刻激活了它(改变形状,颜色,亮度或从某处跳下)。 这是古代的实现方式。
概括地说,该方案如下:一个人的视野中有几种(通常是3到7种)刺激。 一个人选择其中一个并专注于此(一个好方法是计算激活次数),然后每个对象以随机顺序闪烁。 了解了每个刺激的激活时间,我们现在可以查看下一个EEG,并确定其中是否有特征峰(我们将在下面的可视化图中看到它)。 由于此人只专注于一种刺激,因此峰值应该是一种。 因此,在这些神经接口中,选择了多个选项之一(书写字母,游戏中的动作以及上帝知道其他什么)。 如果有七个以上的选项,则可以将它们放在网格上,并将任务简化为选择行+列。 如上所示,这就是经典矩阵P300拼写器的方式。
在今天考虑的数据集的情况下,视觉部分(以及名称)是从著名的游戏空间吸引者那里借来的。 看起来像这样

实际上,这是相同的拼写,只有字母被游戏外星人代替。
游戏过程的视频和技术报告也被保留。
一种或另一种方式,使用此游戏收集的数据出现在互联网上,我们可以访问它们。 数据包括16个EEG通道和一个事件通道,显示目标(玩家做出的)和非目标激励在何时启动,我们将与他们合作。
大多数BCI数据集是由神经生理学家编写的,这些人并不真正在乎兼容性,因此数据格式非常多样化:从.mat文件的不同版本到.edf和.gdf的“标准”格式。
关于这些格式,您需要了解的最重要的事情是您不想解析它们或直接使用它们。
幸运的是,来自NeuroTechX的一群爱好者直接在numpy中编写了一些数据集的下载器。
这些引导程序是moabb项目的一部分,该项目声称是BCI的通用解决方案。
下载原始数据集
import moabb.datasets sampling_rate = 512 m_dataset = moabb.datasets.bi2013a( NonAdaptive=True, Adaptive=True, Training=True, Online=True, ) m_dataset.download() m_data = m_dataset.get_data()
在这一阶段,我们获得了包含EEG记录的RawEDF结构。 这是mne软件包中的结构,生物学家通常使用它与信号进行交互:此结构具有用于过滤,可视化,存储标签的内置方法,这是您所不知道的。 但是我们不会这样走,因为 程序包的界面往往不稳定(当前版本为0.19 ,但由于新版本不再读取数据集,因此我们将使用0.17 )并且文档记录不充分,由此得出的结果可能无法再现。
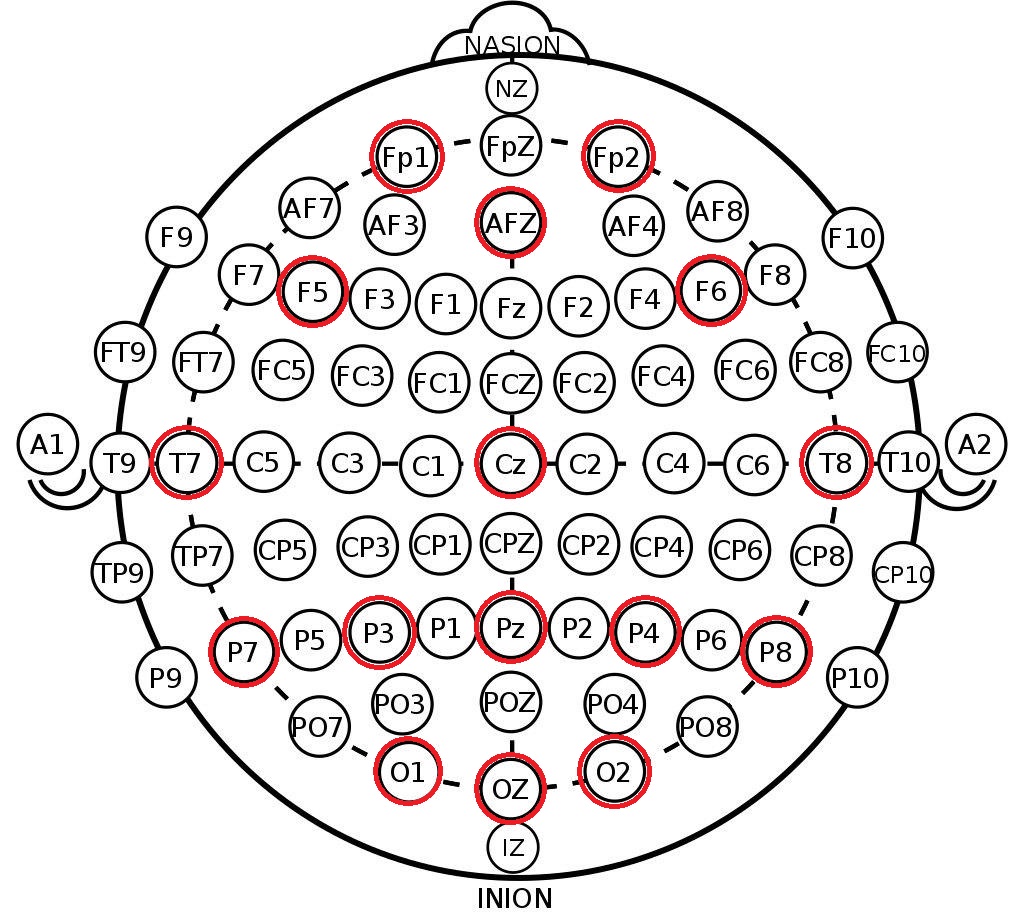
我们从得到的结构中得到的是10-20系统中的通道标签。 这是电极在人头上的一种国际排列方式,旨在使科学家可以关联大脑区域和EEG通道位置。 以下是10-10系统中电极的排列方式(与10-20的差异为标记密度的两倍),并且此数据集中记录的通道以红色标记。
print(m_data[1]['session_1']['run_1'])
首先,从每个主题的下载数据中,我们为16秒分配连续的EEG数组,并分配此间隔的所有标签(在数据中,这只是另一个通道,其中记录了我们感兴趣的事件的开始)。
在此阶段,我们保持连续脑电图的最大长度,以免在进一步过滤时遇到边缘效应。
raw_dataset = [] for _, sessions in sorted(m_data.items()): eegs, markers = [], [] for item, run in sorted(sessions['session_1'].items()): data = run.get_data() eegs.append(data[:-1]) markers.append(data[-1]) raw_dataset.append((eegs, markers))
过滤与分离
通常,要回顾脑电图的预处理和分类方法,我可以向神经计算机接口大师推荐一个很好的概述 。 同样不久前,发布了对神经网络测试的最新评论 。
对EEG信号进行分类的最小预处理包括3个步骤:
为了实现这些步骤,我们将使用旧的sklearn及其范例作为变压器和管道的模型,以便我们的预处理可以轻松扩展。
变压器代码放置在单独的文件中,下面我们将描述一些详细信息。
抽取
由于某些原因,在一些文章和处理示例中,我通过简单地抛出样式为eeg = eeg[:, ::10]样本来降低信号频率。 这是完全不正确的(为什么-参见任何有关信号处理的书)。 我们使用 scipy的标准 scipy 。
筛选
在这里,我们还通过选择4阶Butterworth带通滤波器并在正向和反向( filtfilt )上应用该滤波器来维持相位。 截止频率-从0.5到20 Hz,这是我们任务的标准范围。
缩放比例
我们使用了每个通道的StandardScaler (减去平均值,除以标准差),该程序可以查看样本中的所有信号。 实际上,此时会引入少量数据泄漏。 正式地,定标器还可以从测试样本中看到数据,但是如果数据量足够大,则均值和偏差是相同的。
逐个通道进行手淫,以便在同一数据集中可以汇总来自具有不同数量级和性质的不同传感器的数据(例如, 皮肤电反应(RAG) )
除了上述操作之外,还可以区分EEG中的伪影(闪烁,咀嚼运动,头部运动),但是此数据集已经非常干净了,因此让我们将其保留到下一次。
reload(transformers) decimation_factor = 10 final_rate = sampling_rate // decimation_factor epoch_duration = 0.9
接下来,我们将对数据应用预处理流水线,并将连续的EEG信号切成历元。 我们将激活刺激后的时间间隔称为一个时期,其特征持续时间为0.5-1秒,在我们的情况下,持续时间为900毫秒,尽管可以缩短。
在我们的数据集中,有16个EEG通道,应用抽取后,频率将下降到50 Hz,因此一个时长将由矩阵(16, 45)描述-50 Hz时900 ms是45个时间采样。
此数据集中的标签仅是二进制文件-它们标记目标(被玩家隐藏,活动1)和非目标(空0)信号。
for eegs, _ in raw_dataset: eeg_pipe.fit(eegs) dataset = [] for eegs, markers in raw_dataset: epochs = [] labels = [] filtered = eeg_pipe.transform(eegs) markups = markers_pipe.transform(markers) for signal, markup in zip(filtered, markups): epochs.extend([signal[:, start:(start + epoch_count)] for start in markup[:, 0]]) labels.extend(markup[:, 1]) dataset.append((np.array(epochs), np.array(labels)))
dataset[0][0].shape, dataset[0][1].shape
因此,我们得到了一个Pytorch样式的Pytorch ,其中第一个索引计算出了不同的人。 通过这种结构,我们既可以在一个人的数据中进行交叉验证,又可以测试不同人之间分类器的容忍度(所谓的转移学习,无标定预测)。 一个人的数据由一系列的时代和类别标签组成。 由于录音的特性,每个人的时代数略有不同。
数据研究与可视化
首先,在分割为历元之前,先看看其中一个连续信号。
尽管事实已经被滤除,但它在眼睛上没有显示任何激活,看起来更像是某种噪音。
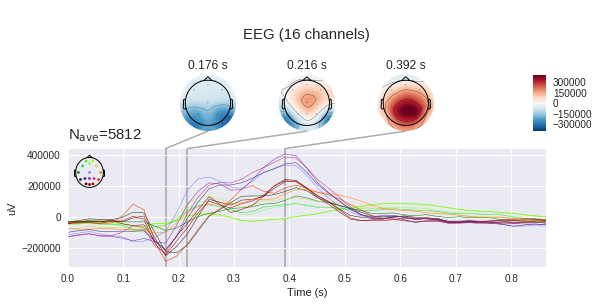
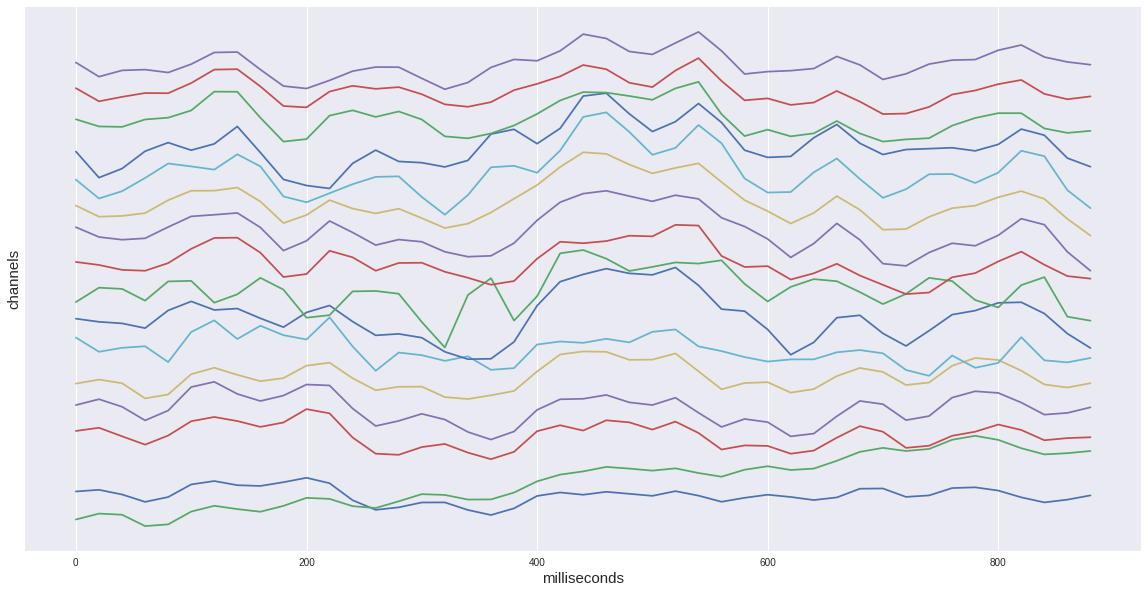
如果我们仅考虑数据集中的一个目标纪元,那么我们将看到400-600毫秒的间隔出现特征性上升。 这是我们广受欢迎的潜在P300。
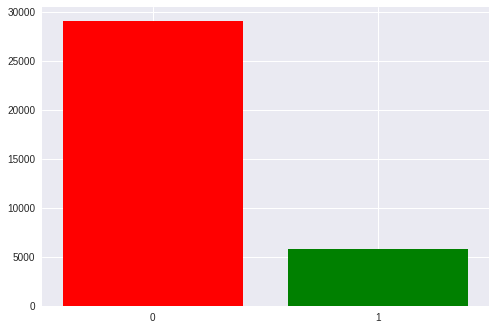
总共,在我们的数据集中大约有35,000个纪元,即刺激激活。 每个人大约有1300年至1750年(这是由于有人击落外星人的速度更快,而有人击落速度较慢的事实)。
班级中也存在明显的失衡:1到5倾向于空刺激。 我们在矩阵中有6行和几列,而其中只有一个是目标。 稍后,我们将在讨论获得的指标时回到这一点。
现在是时候查看目标信号与非目标信号之间的差异了
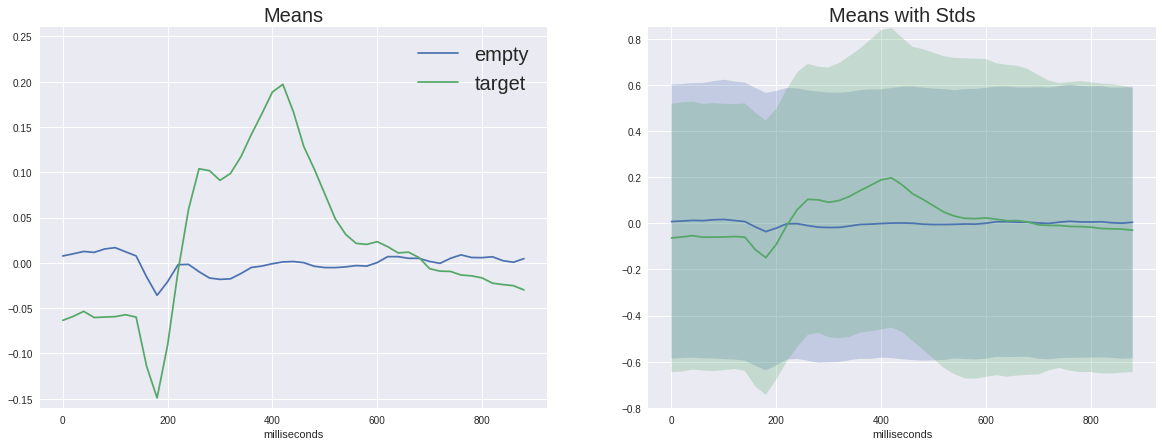
在左图上,您可以看到平均信号变化很大,并且两者均在180ms范围内具有非特定响应,但目标信号幅度更大,目标信号也具有250至500ms的特征峰-这就是臭名昭著的P300。
由于信号存在如此大的差异,我们的任务似乎有些琐碎,但是如果在图形的每个点上加上标准偏差,我们将看到图像不是那么红润-信号噪声很大。 尽管存在这样的事实,但P300的信噪比被认为是神经生理学中最高的信噪比之一。
(实际上,这些图并不是很诚实地构建的,因为空信号的平均平均值是不同样本的五倍,所以随机偏差被抑制得更多,但是正如我们从相同阶数的离散中可以看到的那样,这并没有太大帮助)

查看一个人的平均信号也很有用。
此处找到了有关“不诚实”平均的先前评论-空信号的幅度明显大于全部平均值的幅度。 此外,由于平均次数较少,一个人的P300峰值较高。
重要的是要注意一个人的信号的另一个特征-它的形式与广义形式略有不同。 神经生理反应的人际变异性很高,我们仍将在分类器的工作中看到该因素的影响。 但是,人际差异(一个人的心情不同,压力水平,疲劳程度)也很大。

接下来,我们看到信号的逐通道扫描。 这里的观点与上面的图片一致,该图片描述了电极的位置-上方的鼻子等。
头部各部位的反应不同。 在Fp1,2处,显着出现在正峰值之前的两个负峰值。 同样,在某些通道中有两个正峰,而在某些通道中-一个或多个过渡峰之间。
对于确定P300的存在,不同的渠道具有不同的重要性,可以使用不同的方法(计算互信息(互信息)或加删除法(又称为逐步回归))进行估算。 这些方法的应用我们将另作处理。
值得记住的是,我们测量的是电极与电极之间的电势差,这意味着我们可以使用各个点的电压变化在某些时间点构建整个头部的电压图。 显然,如果有16个电极,则这种卡的精度尚不理想,但是应该形成一些理解。 (默认情况下, mne预期会出现微伏,但我们已经应用了缩放比例,因此绝对值不正确)

分类
最后,是时候将机器学习方法应用于我们的样本了。
选择了几个基本的分类器-日志。 回归,支持向量法(SVM)以及使用pyriemann软件包进行相关分析的几种方法(每种方法的详细信息可以在文档中找到),值得注意的是,这些方法是专门为应用于EEG而开发的,并在它们的帮助下赢得了多项 竞赛笑话
clfs = { 'LR': ( make_pipeline(Vectorizer(), LogisticRegression()), {'logisticregression__C': np.exp(np.linspace(-4, 4, 9))}, ), 'LDA': ( make_pipeline(Vectorizer(), LDA(shrinkage='auto', solver='eigen')), {}, ), 'SVM': ( make_pipeline(Vectorizer(), SVC()), {'svc__C': np.exp(np.linspace(-4, 4, 9))}, ), 'CSP LDA': ( make_pipeline(CSP(), LDA(shrinkage='auto', solver='eigen')), {'csp__n_components': (6, 9, 13), 'csp__cov_est': ('concat', 'epoch')}, ), 'Xdawn LDA': ( make_pipeline(Xdawn(2, classes=[1]), Vectorizer(), LDA(shrinkage='auto', solver='eigen')), {}, ), 'ERPCov TS LR': ( make_pipeline(ERPCovariances(estimator='oas'), TangentSpace(), LogisticRegression()), {'erpcovariances__estimator': ('lwf', 'oas')}, ), 'ERPCov MDM': ( make_pipeline(ERPCovariances(), MDM()), {'erpcovariances__estimator': ('lwf', 'oas')}, ), }

神经接口的最常见方案是“校准+功”,即 首先,一个人有必要在一段时间内专注于先前指示的刺激,只有在此之后我们才能预测他的选择。 这种方法的明显缺点是无聊的初始阶段。
为了评估在这种模式下我们方法的性能,我们将在一个人的时代内进行交叉验证。
由于数据集的不平衡(此处的基线为5/6〜83%),因此在这种情况下的准确性指标不相关,因此我更愿意看一下Precision-Recall-f1三。
为了查看整个数据集,我们对所有人的交叉验证结果进行了平均。 通常,最好的模型的性能与Neiry在游乐园的“现场”条件下的性能相比要高得多(我记得该数据集是在实验室中记录的)。
在此数据集中,只有数据的二进制标签。 通常,我们需要解决选择刺激之一的多类问题(顺便说一下,因为每个刺激被激活相同的次数,所以它是平衡的)。 为了解决这个问题,每个刺激的激活次数通常是固定的(例如,每个刺激有5个激活的6个刺激),并且所有刺激都被随机激活(30次),获得30个历元,并且将其激活的概率相加作为目标,之后达到最大刺激该金额被确认为目标。 我们将在以后的适当数据集上演示这种方法的实现。

第二种方案称为转移学习-即人与人之间的分类器转移。 事实是,进行校准时,我们实际上会重新训练到一个人的峰形,因此我们可以在以后的测试中很好地预测它。 在没有校准的情况下,预训练的分类器应该能够隔离P300概念,而无需事先知道特定人员的波形。
我们将进行两个实验-我们将在一个人上训练分类器,然后预测五个,然后将训练样本增加到10人并比较结果,以确保模型能够提高其泛化能力
1人培训

培训10人
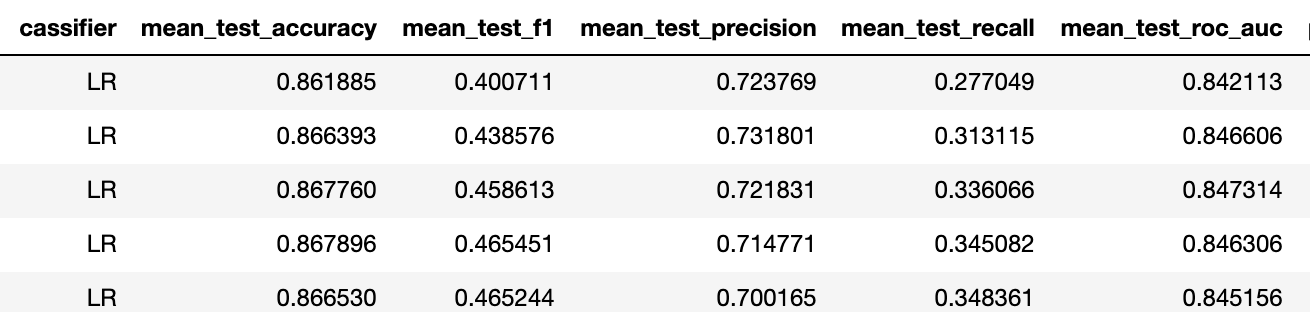
因此,对于更好的分类器来说,f1从0.23上升到0.4(在两种情况下都是具有相同正则化的对数回归)。
这意味着预测能力已从“否”增加到“可接受”。 根据我们的经验,使用这样的二元任务指标,每个刺激的5次激活足以达到约75%的多类问题的准确性。
最后,我想指出上述方法是非常原始的,例如可以通过对数回归的高度正则化来看出-数据中的通道具有很强的相关性,有几种方法可以解决这个问题。
结论
今天,我们更加熟悉了P300的潜力,并为神经接口建立了简单的管道。 我建议有兴趣的人自己打开笔记本电脑(位于资源库中 ),并尝试使用可视化选项和分类器。
对使用EEG信号的方法有基本的了解,我们将能够更深入地研究该主题-应用高级预处理方法以及神经网络来解决构建神经接口的问题。 待续...