我将继续毫不费力地分析CPython中基本类型的实现,以前考虑过
字典和
整数 。 鼓励那些认为在其实现中没有任何有趣之处和技巧的人加入这些文章。 那些已经读过它们的人知道CPython具有许多有趣的功能和实现功能。 当您编写自己的脚本时,它们可能会很有用,或者作为体系结构和算法解决方案的指南。 字符串在这里也不例外。
让我们从简短的历史入手。 Python出现在1990-91年。 最初,在用python开发基本编码时,有一个单字节的旧式ascii。 但是,大约在同一时间(稍后),人类已经厌倦了处理编码的“动物园”,并于1991年提出了Unicode标准。 但是,第一次也是没有用。 开始引入两字节编码,但是很快就发现,对于每个人来说两个字节是不够的,因此提出了一种四字节编码。 不幸的是,为每个字符分配4个字节似乎浪费了磁盘空间和内存,尤其是在那些以前单字节ascii足够的国家。 几个拐杖被锯成一个2字节的编码,以支持更多的字符,所有这些都开始类似于以前的编码“ zoo”情况。
但在1993年推出了utf-8。 这是一个折衷方案:ascii是utf-8的有效子集,所有其他字符都对其进行了扩展,但是为了支持这种可能性,我必须将每个字符的长度固定下来。 但是正是他注定要
统治所有人,使其成为完全统一的Unicode,也就是说,大多数程序在其中存储了大多数文件的情况下都支持单一编码。 这尤其受Internet发展的影响,因为网页通常仅使用utf-8。
对这种编码的支持逐渐引入到编程语言中,像utf-8之前开发的python这样的编程语言,因此使用了其他编码。 有一个
PEP很好的数字100,讨论了Unicode支持。 在
PEP-0263中,可以声明源文件的编码。 ascoding仍然是基本编码,`u`前缀用于声明unicode字符串,使用它们仍然不够方便和自然。 但是有机会制造以下异端:
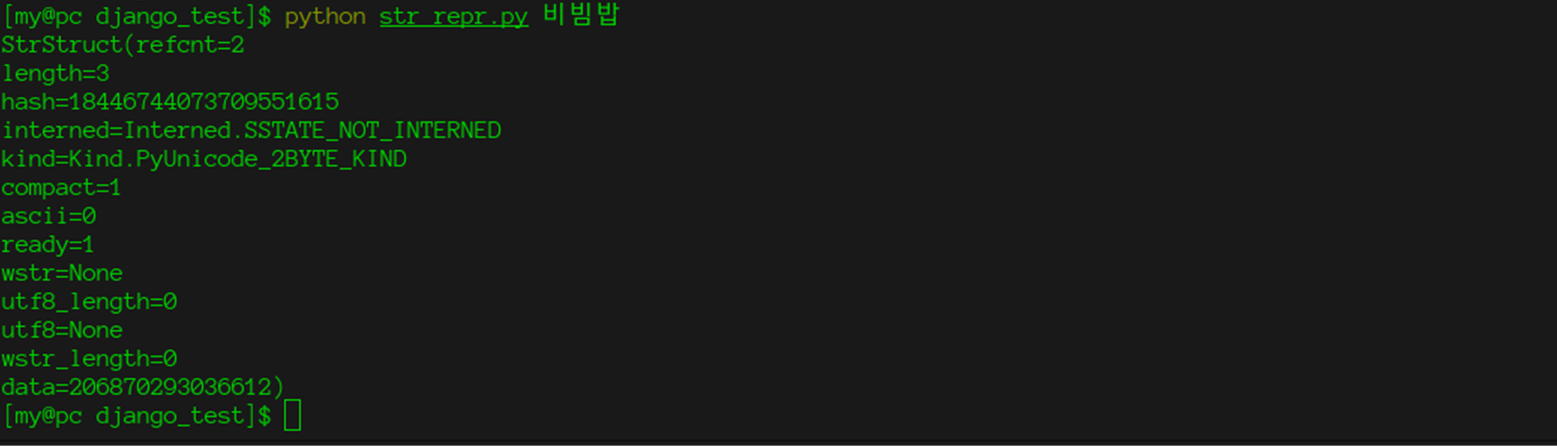
class 비빔밥: _ = 2 א = 비빔밥() print(א)
2008年12月3日,整个python社区发生了一次历史性事件(考虑到该语言现在的传播范围,然后可能是整个世界的广泛传播)-python 3发布了,因此决定彻底解决这些问题,许多编码,因此Unicode已成为基本编码。 但是我们记得编码很复杂,而且第一次也不可行。 这次也没有成功。
utf-8的最大缺点是字符长度不固定,这导致以下事实:访问索引这样简单的操作具有O(N)复杂度,因为事先不知道元素偏移量,此外,还知道缓冲区的大小,为存储字符串而分配的,您不能以字符为单位计算其长度。
为了避免python中的所有这些问题,决定使用2字节和4字节编码(取决于平台)。 简化了索引处理-只需要将索引乘以2或4。但是,这带来了以下问题:
- 每个平台都有自己的编码,这可能导致代码可移植性问题
- 对于不适合两个字节的棘手字符,增加了内存消耗和/或编码问题
PEP-393中提出了解决这些问题的方法,我们将讨论它。
决定将行保留为字符数组,以方便通过索引和其他操作进行访问,但是,字符的长度开始变化。 创建字符串时,解释器将扫描所有字符并为每个字符分配存储“最大”字符串所需的字节数,即,如果您声明一个ascii字符串,则所有字符均为单字节,但是,如果您决定向该字符串添加一个字符从西里尔文开始,所有字符将已经是两个字节。 有三个可能的选项:每个字符1、2和4个字节。
字符串类型(PyUnicodeObject)声明
如下 :
typedef struct { PyCompactUnicodeObject _base; union { void *any; Py_UCS1 *latin1; Py_UCS2 *ucs2; Py_UCS4 *ucs4; } data; } PyUnicodeObject;
反过来,PyCompactUnicodeObject表示
以下结构 (提供一些简化和我的评论):
typedef struct { PyASCIIObject _base; Py_ssize_t utf8_length; char *utf8; Py_ssize_t wstr_length; } PyCompactUnicodeObject; typedef struct { PyObject_HEAD Py_ssize_t length; Py_hash_t hash; struct { unsigned int interned:2; unsigned int kind:3; unsigned int compact:1; unsigned int ascii:1; unsigned int ready:1; unsigned int :24; } state; wchar_t *wstr; } PyASCIIObject;
因此,可能有4种线表示形式:
- 旧式字符串,准备好了
* structure = PyUnicodeObject structure * : !PyUnicode_IS_COMPACT(op) && kind != PyUnicode_WCHAR_KIND * kind = PyUnicode_1BYTE_KIND, PyUnicode_2BYTE_KIND or PyUnicode_4BYTE_KIND * compact = 0 * ready = 1 * data.any is not NULL * utf8 data.any utf8_length = length ascii = 1 * utf8_length = 0 utf8 is NULL * wstr with data.any wstr_length = length kind=PyUnicode_2BYTE_KIND and sizeof(wchar_t)=2 or if kind=PyUnicode_4BYTE_KIND and sizeof(wchar_4)=4 * wstr_length = 0 wstr is NULL
- 旧式字串,尚未准备好
* structure = PyUnicodeObject * : kind == PyUnicode_WCHAR_KIND * length = 0 (use wstr_length) * hash = -1 * kind = PyUnicode_WCHAR_KIND * compact = 0 * ascii = 0 * ready = 0 * interned = SSTATE_NOT_INTERNED * wstr is not NULL * data.any is NULL * utf8 is NULL * utf8_length = 0
- 紧凑的ASCII
* structure = PyASCIIObject * : PyUnicode_IS_COMPACT_ASCII(op) * kind = PyUnicode_1BYTE_KIND * compact = 1 * ascii = 1 * ready = 1 * (length — utf8 wstr ) * (data ) * ( ascii utf8 string data)
- 紧凑的
* structure = PyCompactUnicodeObject * : PyUnicode_IS_COMPACT(op) && !PyUnicode_IS_ASCII(op) * kind = PyUnicode_1BYTE_KIND, PyUnicode_2BYTE_KIND or PyUnicode_4BYTE_KIND * compact = 1 * ready = 1 * ascii = 0 * utf8 data * utf8_length = 0 utf8 is NULL * wstr data wstr_length=length kind=PyUnicode_2BYTE_KIND and sizeof(wchar_t)=2 or if kind=PyUnicode_4BYTE_KIND and sizeof(wchar_t)=4 * wstr_length = 0 wstr is NULL * (data )
应该注意的是,python 3还支持通过`u`前缀声明unicode字符串的语法。
>>> b = u"" >>> b ''
添加此功能是为了便于仅在2012年2月将代码从第二个版本移植到python 3.3中的
PEP-414中的第三个版本,让我提醒您python 3是在2008年12月发布的,但是没有人着急进行此过渡。
有了这些知识和标准的ctypes模块,我们就可以访问字符串的内部字段。
import ctypes import enum import sys class Interned(enum.Enum):
甚至像
上一部分中那样“破坏”解释器。
免责声明:以下代码按原样提供,在运行此代码后,作者不承担任何责任,也不能保证解释器的状态以及您和您的同事的心理健康。 该代码在cpython 3.7版上进行了测试,但不幸的是,不适用于ascii字符串。
为此,将上述代码更改为:
def make_some_magic(str1, str2): s1 = StrStruct.from_address(id(str1)) s2 = StrStruct.from_address(id(str2)) s2.data = s1.data if __name__ == '__main__': string = "비빔밥" string2 = "háč" print(string == string2)
这些示例使用
python 3.6中添加的字符串插值。 Python并没有立即采用这种输出字符串的方法:%语法,格式,
类似perl的尝试(
这里有示例的更详细描述)。
这段时间的变化(在python 3.8之前带有`:=`运算符)可能是最具争议的。 讨论(和谴责)是在
reddit上进行的 ,甚至是以
PEP的形式进行的。 改进/校正的想法以添加
i-line的形式表示,用户可以为其编写解析器,以更好地控制并避免SQL注入和其他问题。 但是,此更改被推迟了,以使人们习惯了f线并发现了问题(如果有)。
F线具有一种特殊性(缺点):您不能指定带有斜杠的特殊字符,例如'\ n''\ t'。 但是,可以通过声明包含特殊字符的单独行并将其传递给f行来轻松避开,这在上面的示例中已完成,但是您可以使用嵌套的方括号。
>>> number = 2 >>> precision = 3 >>> f"{number:.{precision}f}" 2.000
如您所见,字符串存储了它们的哈希值;
建议根据一个简单的规则使用此值比较字符串:如果字符串相同,则它们具有相同的哈希值,并且随之而来的是具有不同哈希值的字符串也不相同。 但是,它仍然没有实现。
比较两个字符串时,将检查指向字符串的指针是否指向相同的地址,如果不是,则在允许的情况下启动逐字符比较或memcmp。
int PyUnicode_Compare(PyObject *left, PyObject *right) { if (PyUnicode_Check(left) && PyUnicode_Check(right)) { if (PyUnicode_READY(left) == -1 || PyUnicode_READY(right) == -1) return -1; if (left == right) return 0; return unicode_compare(left, right);
但是,哈希值间接影响比较。 事实是,在cpython中,字符串是被固定的,即存储在单个字典中。 并非对于所有行都是如此;所有常量,字典键,字段和变量以及长度小于20的ascii行都将被插入。
if __name__ == '__main__': string = sys.argv[1] string2 = sys.argv[2] print(id(string) == id(string2))
$ python check_interned.py aa True $ python check_interned.py 비빔밥 비빔밥 False $ python check_interned.py aaaaaaaaaaaaaaaaaaaaaaaaaaaaa aaaaaaaaaaaaaaaaaaaaaaaaaaaaa False
而且空字符串通常是单例
static PyUnicodeObject * _PyUnicode_New(Py_ssize_t length) { PyUnicodeObject *unicode; size_t new_size; if (length == 0 && unicode_empty != NULL) { Py_INCREF(unicode_empty); return (PyUnicodeObject*)unicode_empty; } ... }
如我们所见,cpython能够创建一个简单但有效的字符串类型实现。 由于有了memcmp,memcpy函数,而不是逐个字符的操作,因此在某些情况下可以减少已使用的内存并加快操作速度。 如您所见,字符串类型的实现根本不像第一次那样简单。 但是cpython开发人员已经非常熟练地开展业务,因此我们可以使用它,甚至不用考虑背后的内容。