
我在研讨会上安静地坐着,听了学生关于过去
CVPR上一篇文章的报告
,并同时搜索了该主题。
-本文的优点包括源代码的可用性。
我必须干预:
-有什么事,对不起?
-嗯...源代码...
“你看过吗?”
-不,但文章指出...
(母亲-母亲-母亲...习惯地回声)you您是否遵循链接?
的确,这篇文章的确令人鼓舞:“代码和模型可在项目页面上公开获得... / imtqy.com / ...”,但是,在两年前的提交中,鼓舞人心的“代码和模型将很快布局”链接:
搜索并找到,敲门然后打开……也许……也许不是。 根据我的悲惨经历,我会把它放在第二位,因为这种情况最近经常发生,哦,哦,经常。 即使是CVPR。 这只是问题的一部分! 可以使用源,但仅提供模型,而无需训练脚本。 可能会有学习脚本,但是几个月来写给作者的信不可能获得相同的结果。 或者,在使用常规Skype通话的另一个数据集上,一年的时间,美国的一位作者无法重现他的结果,这种结果是在业内最著名的实验室中就此主题得出的……某种Tryndets。
而且,显然,到目前为止,我们只看到花朵。 在不久的将来,情况将急剧恶化。
谁在乎科学界要去的
那个学生发生了什么 ,包括通过深度学习的“错误”,欢迎来到这只猫!
再现性危机
在2016年,是否
存在重现性危机? (现在是否存在再现性危机)? ,其中引用了对1576名研究人员的调查结果:
 来源:本节中的此图及以下图形是《自然》杂志上的文章。
来源:本节中的此图及以下图形是《自然》杂志上的文章。根据调查结果,有52%的研究人员认为尚有严重危机,有38%(轻度危机(总计90%!),有3%-没有危机,有7%)尚未确定。
作者的阴谋论-考虑到灾难的规模,后者根本不想引起对问题的“过度”关注:

如果看这些学科,结果发现化学是第一位的,生物学是第二位的,物理是第三位的:
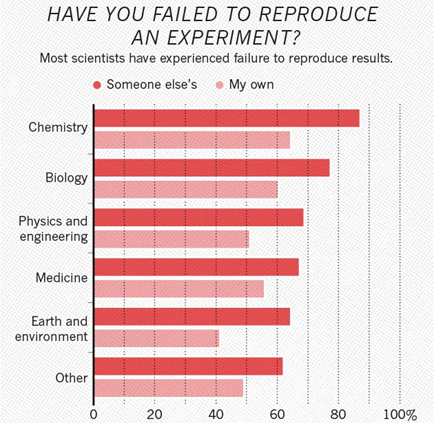
有趣的是,例如在化学领域,超过60%的研究人员发现不可能复制自己的研究成果。 在物理学中,这些比例也超过50%。
同样有趣的
是,从研究人员的角度来看,
到底是
什么对不可复制性危机做出了最大贡献:

首先是“选择性报告”。 对于计算机科学而言,这是一种情况,例如,作者选择了算法可以在其上发布的最佳示例,而没有详细描述哪些地方和哪些地方行不通。
有趣的是,第二个是“发布压力”。 这是一个众所周知的“出版或灭亡”的原则。
英文维基百科上的一篇文章很好地描述了这个问题。 俄语维基百科中没有关于此主题的文章,尽管在科学工作报酬很高的地方,这个问题变得很重要。 例如,在一所薪水高的顶尖大学中(ala,我不是在说我的母语国立莫斯科州立大学),高的出版分数对于重新认证至关重要,如果您想继续工作,请发表。 一个car体,一个稻草人,等等,但是要点是。
还要注意,“方法,代码不可用”在45%的情况下很常见,有时甚至在82%的情况下。 好吧,在40%的案件(即 经常。 我最近与一位在视频压缩算法领域工作的中国教授进行了交谈。 他说,中国内部有很多有意识的欺诈文章,它们只是祸害。 带有欺诈行为的外国出版物很快就被撤职,因此他们试图遵守,但内部却产生了噩梦(例如,参见
《自然
》中的
“在
中国出版或灭亡”一文)。 一场噩梦,包括由于“同行评议不充分”列表中的以下原因-没有足够的力量进行高质量的交叉评审。
一个单独的大问题,我将仅简要提及:如果无法复制结果,则几乎不可能发表有关此问题的文章...

每个人都对新的成就,新的贡献和新的想法感兴趣,旧的行不通-有什么不同。 这自然会增加不可复制结果(包括故意欺诈)的份额。 最有可能的是,没人会理解,这是不被接受的。 显然,当其他人开始基于一个假结果时,整个系统就会变得不稳定,最终会影响每个人:
 您的赌注
您的赌注 -有
时间躲闪或暗恋他吗?总计:
- 根据《自然》杂志对1576名研究人员进行的一项调查,有52%的人认为现在存在严重的可复制性危机,而90%的人认为存在这种危机。
- 而且,当前的情况仍在蓬勃发展,很快一切都会变得更糟,尤其是在计算机科学领域。 怎么了 立即查找。
计算机科学中的可重复性
在亚利桑那州立大学(顺便说一句,学生人数是莫斯科国立大学的2倍),程序员部门专门建立了一个
http://repeatability.cs.arizona.edu/网站,专门研究期刊中601篇文章的结果可重复性和
ACM会议。 结果如下图:

 资料来源: 计算机科学中的可重复性
资料来源: 计算机科学中的可重复性他们没有检查106篇文章,因为他们不想违反实验的纯粹性(他们写信给作者并要求提供代码),其余的则是:
- 在93篇文章(占19%)中,没有代码,或者存在无法与它们进行比较的硬件,
- 在176篇文章(占35%)中,作者没有提供代码,
- 在226条文章(46%)中,代码是无法收集的;在9(2%)条中,代码是无法收集的;在87(64 + 23)条文章(18%)中,解决了组装项目的问题花费了超过半小时的时间(在23种情况下,这些问题被消除了)失败了,但是作者保证“付出更多的努力”一切都会聚集在一起)。
我必须说,根据我们在集会后的经验,最有趣的只是刚刚开始,但是在研究中,他们决定停止在这一阶段,并且有了这么多的知识,您就可以理解。 在任何情况下,统计数据都非常具有启发性,并且拒绝提供代码的35%与先前研究的“方法,代码不可用”行非常接近(第三张图)。
总的来说,这个话题很好地挖掘了。 特别是,“黄金标准”是易于获得完全重复结果的代码和数据的可用性,而最糟糕的方法是仅提交文章:
 资料来源: 概念化,衡量和研究可重复性
资料来源: 概念化,衡量和研究可重复性为什么会这样呢?
有多种原因,就像任何复杂的现象一样:
- 在西方,上述“出版或灭亡”非常有影响力。 在研讨会和讲习班上,年轻的绿色研究生受到了完全的认真和明确的指导-“一个想法来了, 首先发布! 然后才检查!”(谁说的是野蛮?先生们,严酷的现实!)科学的优先级真的很重要(包括臭名昭著的引述),因此,当出现一些有趣的想法时,它首先被出版(有时带有假数据)。 ,有时不是),只有这样,他们才能长时间痛苦地开始编写某些程序,常常在地球上拉猫头鹰。 在本文开头作为第一个示例引用的文章似乎只是其中的一个(致晕神经网络……我想知道他们吸烟了吗?但是它涉及到CVPR!)。 结果是一只超重的白色毛茸茸的动物,情况继续恶化:
- 按照惯例,国家会提供一半的研究经费(更多的地方,更少的地方)。 政府的资金激起了出版的疯狂(出版时只是为了出版)。 资金的另一半来自公司,公司显然在谈论发行限制。 根据一位同事的恰当表述,一家颇受欢迎的韩国公司为俄罗斯科学家提供了工作,“以珠子”为人所知,因为它在大学和大学中具有
黑人条件。 是的,现在他们甚至在薪资竞赛中打破了神经网络领域的市场,但是总的来说,提供糟糕合同的第一件事就是这些亚洲公司的公司形象。 而且,当不允许发表一篇写得很好的文章时,再发表另一篇,甚至更多,那无疑会大大降低他们的积极性。 即使经过几年,这也不会被忘记。
结果,获得了最少文章的专利。 我与来自芬兰,美国,法国等地的同事交谈很有趣。 那里有很多人紧紧地坐在赠款上,但是拥有许多公司的人也发布的结果远非全部,如果发布,他们会以某种方式(从文化上来说)减少对方法的描述,自然使复制变得复杂。 为此已经支付。
总计:
- 即使在紧急请求之后,也最多会在46%的情况下发送代码(顺便说一下,阅读研究 ,有一些有趣的“借口”示例,根据我们的经验,这些基本上都是发送的)。
- 科学筹资系统本身要么鼓励尽快发表未经验证的结果,要么限制出版物的发表,包括全面披露。 在这两种情况下,重现性都会降低。
为什么机器学习会使情况更糟
但这还不是全部! 近来,一般而言,机器学习尤其是神经网络已经迅速普及。 太棒了 它很棒。 昨天完全不可能的今天变成了可能! 只是某种假期! 那呢
不行 神经网络为计算机科学增添了新的沉迷于不可复制深渊的机会。
这是一个简单的示例:它看起来像没有跳过连接的
ResNet-56的损失函数(可视化数以千万计的几个参数)。 我们要进行合理数量的迭代(时代)的任务是找到最深的点:
 资料来源: 可视化神经网络的损失情况
资料来源: 可视化神经网络的损失情况您可以清楚地看到局部极小海洋,我们的梯度下降快乐地“落入”并且“无法”离开那里。 是的,很明显,对于ResNet来说,此示例是一个很好的说明,由
跳过连接提供(引入网络学习后得到了显着改善):
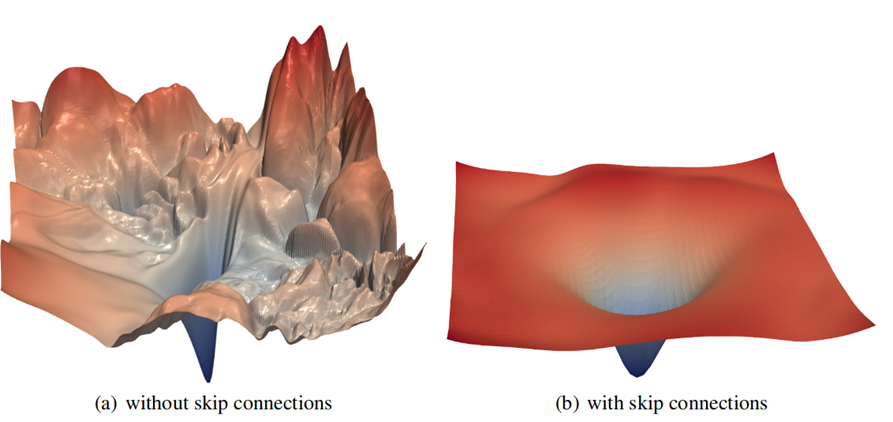
因为尝试在复杂的景观中找到最小值是一回事(并且只有搜索空间的总体尺寸会有所帮助),而查看相对最小的全局最小值则相对是另一回事。
这个故事很美,但是在我们严酷的现实中,层层遍地,我们不得不面对网络无法学习的事实。 一般而言。
甚至更有趣-有时可以训练它(误差急剧下降),但是过了一段时间,当尝试从头开始重现结果时(例如,当这些系数丢失时),就不可能重复聚焦,并且网络在远距离上显然很痛苦从最低限度。 数以百计的
时代相继成功,而购物车依然存在。 石花不是从大师丹妮拉出来的。
很难想象研究人员无法在计算机科学中复制自己的研究结果。 如今,它已变得司空见惯,因为它早已在物理,化学,生物学等领域出现,并在列表中进一步出现。
有了神经网络,计算机科学突然变成了实验科学! 欢迎来到这个美好的世界。 现在,您将越来越多地无法再现
自己的结果(例如64%的化学家,60%的生物学家,请参阅本文的第二张图)。
但这还不是全部的快乐。 更多会更有趣!
通常,在相当长的一段时间里,我对神经网络持怀疑态度,因为基于神经网络的算法无法正常工作。 好吧……它们当然以某种方式工作了,但是在大样本上却被“经典”的最新算法所迷惑(这并没有阻止它们大规模发布)。 发生这种情况是因为神经网络非常适合各种欺诈行为。 最主要的是正确选择培训样本作为示例,您自然可以展示奇迹。 结果是精美的图片(有时甚至是精美的图形),并且文章进展顺利。 您甚至可以布置代码(它似乎已经变得很流行),但这并没有改变本质。 它不起作用。 但是,当红色的
PoP公鸡大而尖锐的喙在后面隐约出现时,该文章就是无花果,就可以打印了。

一个单独的主要问题是没有大量培训样本的区域。 来自医学界的同事抱怨-一场噩梦正在发生。 他们多年来一直在收集数据集。 甚至有数以万计的例子。 但是拥有深层神经网络的研究生来了。 Figak-figak超越了所有人……英俊! 科学巨人! 并以开心的笑脸报告结果。 他们被要求:
-为了防止过度拟合,您做了什么?
-为什么,对不起?
-为什么不进行再培训?
一个人绝对认真地告诉他如何使用正确的网络并严格按照培训手册进行培训,因此一切都很好。 即 年轻人(大量!)不了解再培训是什么! 不是一个,不是两个,而是相当一部分的研究生报告。 这就是年轻的神经网络革命者的新潮流。 我们回想起
Preobrazhensky教授 ,我们为年轻革命家的传统文盲感叹不已。 我们得出结论。
没关系。 在最近的
ITIS 2019上, Mikhail Belyaev给出了很好的例子,说明这种方法如何很好地应用于医疗生产! 在使用神经网络提供分析的真实公司中,他们通过了控制测试并收到了意外的可悲结果。 原因是投资者也感受到了一场革命,如果一个人在神经网络的基础上许诺新的视野,那么他们就会给他钱(精明的Anatoly Levenchuk在2015年就
警告了这一点,这是
巴特诺尔发明的
六个月 ,而ResNet则是六个月,那时许多层仍然训练不善)。 亲爱的先生们,请付出代价! 而且,是的,最好先进行小鼠实验,但是正如一个熟悉的愤世嫉俗的人所说,小鼠没有钱包! 因此,现在正在用消费者的钱,即用于培训的数据来收集(以文化表示)用于培训的数据。 用你的钱。 人,要保持警惕!
显然,不应该归咎于神经网络。 最大的问题是如何获取足够数量的相邻数据,
将它们放在一个小的样本上,避免
灾难性的遗忘,仅此
而已 。 但是,即使您有能干的研究人员,也需要时间。 投资者
在这里和昨天想要一个结果。 那么,对神经网络的成功热潮感到欣喜吗?
当无效方法实际上将大浪的冲浪拖到实际使用时,我们得到了
大浪的大
泡沫 。 请付账单!
总计:神经网络在三个方面恶化了计算机科学的状况:
- 随着神经网络的训练,前者的CS成为一门实验科学,具有所有随之而来的缺点。
- 将训练样本拟合到测试样本可以让您演示任何出色的结果(加剧不可重复性的主要原因-选择性报告)。
- 最后,在训练样本较少的区域,避免重新训练非常困难,许多人不知道如何重新训练和训练(正式而言,结果在数据集上很出色,但实际上该算法不起作用)。
该怎么办?
如果您(一个快乐的人!)在挖坑的区域工作,通常所有的工作都是准备数据集并将其馈送到网络。 除非值得一看建筑。 在这种情况下,观看没有代码的文章毫无意义。 这是一个真正的假期! 感到幸福,不是每个人都那么幸运!
甚至还有这样的网站
PapersWithCode.com ,它在机器学习领域中有目的地收集文章,自动从GitHub解析其存储库的等级,按类别列出所有内容,并添加基准和数据集。 总的来说-一切都是为了人! 顺便说一下,根据他们的计算,该代码现在仅适用于17-19%的文章:
 资料来源: 具有至少一种代码实现的已发表论文的百分比
资料来源: 具有至少一种代码实现的已发表论文的百分比但是他们,如果我们一秒钟分散注意力(并且仍然在广告中宣传这些合适的人),那么在过去的4年中,有一个非常有趣的时间表可以改变ML / DL框架的流行程度:
 资料来源: 按框架分组的论文实施
资料来源: 按框架分组的论文实施骑着火把的TF(谁最近想到了!)正在逐渐失去优势。 但是,这是一个不同的故事...
从经验来看,很明显,这17-20%的带有代码的文章(出于所述的原因)也不是万能的,但是至少您可以更快地检查它们的工作。 这太棒了。
另一个有效的方法是创建相当大的数据集和基准。
ImageNet拥有1400万张图像,分为20,000多个类别,是徒劳的神经网络的兴起。 是的,这很困难,但是通过深度学习,您只能处理
非常大的集合。 即使他们的创作是痛苦和困难的。
例如,前段时间我们创建了一个
基准,用于突出显示视频中的半透明对象 (羊毛,头发,织物,烟和其他不平凡的快乐)。 最初,计划在3个月内将其保留。 找到了伺服驱动器,屏幕,一台好相机
,买了一条蓝色胶带 ,从女孩的所有朋友
那里购得一百万个毛绒玩具,发现了一个真发模特,美发师在上面训练发型。 还有...
 资料来源: 作者的材料 ...显而易见,蓝色胶带起着关键的辅助作用
资料来源: 作者的材料 ...显而易见,蓝色胶带起着关键的辅助作用一切(不,不是这样……一切!)都错了。
一个人经过的地板有足够的振动来移动头发(记录运行被转移了一整夜),气流在头发上起伏(建立了一个盒子),伺服系统在盒子中开始过热(我不得不修改程序并等到达到一定温度后冷却下来) 。等等
等 结果,一年后建立了一个出色的数据集(它的创建值得一个单独的史诗般的传奇),并且我们已经出售了该技术的生产,其价格比借助其帮助而生成的算法还要昂贵。在美好的新世界中,数据规则,先生们!突然之间,事实证明,要使数据良好,整洁并适合进行培训,需要多年的技术工人。今天的基本趋势是在公司内部创建数据集。数据的价值得到确认,并在准备过程中投入了大量资金。幸运的是,许多公司知道他们不能独自应对复杂的任务,并且正在为开放数据集的创建提供资金(例如,在Kaggle上有25,000 个数据集的搜索引擎)。总计:
- 如果有这样的机会,请仅阅读带有代码的文章。
- , , .
- — , . ( ), .
从上面的文字看来,作者似乎认为一切都不好,一切都丢失了,总的来说……并非如此。如果仅仅是因为大量不可复制的作品对作者及其同事的工作产生了稳定的需求,而且情况的恶化意味着现在我们将不得不全天候工作,那么需求将只会更高。此外,必须清楚地理解,精确科学中无法再现的情况不能与人道主义科学中的灾难规模相提并论。维基百科上的“ 复制危机”(不幸的是,她再也没有俄文版)着重于人文学科,主要是心理学,这种情况长期以来一直令人难过: 资料来源:心理科学中的可再现性危机:一年后,顺便说一句,有许多很好的例子说明了不当使用的方式,例如条件概率……...,这在计算机科学中也很容易发生……简而言之!在20年内,当您必须处理机器人的心理学问题时,
资料来源:心理科学中的可再现性危机:一年后,顺便说一句,有许多很好的例子说明了不当使用的方式,例如条件概率……...,这在计算机科学中也很容易发生……简而言之!在20年内,当您必须处理机器人的心理学问题时,热管数学计算机科学将不仅成为实验性的,而且在相当程度上成为人道主义(教育家用和工业机器人的方法以及所有这些方面的差异),然后将开始真正的可复制性问题。 。同时,人们可以并且应该为当前的局势感到高兴,而不是将其理想化并清楚地看到负面趋势。
还有最后一个。
我答应说那位学生怎么了。他因准备本文的材料和图片而受到严惩。这样就不好了!途中所有可重复的研究!另请阅读:致谢
简介使用了来自研讨会复制危机和来自《待售的科学:企业资金的另一个问题》一文的图纸。此外,我还要衷心感谢:- . .. ,
- , , , , ,
- , , ,
- , , , , , , , , , , !