 什么啊
什么啊 视频编解码器是压缩和/或解压缩数字视频的一部分软件/硬件。
为了什么 尽管在带宽方面有某些限制,
并且在存储空间量方面,市场需要越来越多的高质量视频。 还记得上一篇文章中我们如何计算每秒30帧,每像素24位,分辨率为480x240的必要最小值吗? 无需压缩即可接收82.944 Mbps。 压缩是将HD / FullHD / 4K传输到电视屏幕和Internet的唯一方法。 如何实现的? 现在我们将简要考虑主要方法。

翻译是在EDISON Software的支持下进行的。
我们从事视频监控系统的集成 ,以及开发显微照相仪 。
编解码器与容器
新手经常犯的错误是混淆数字视频编解码器和数字视频容器。 容器是某种格式。 一个包含视频元数据(可能还有音频)的包装器。 压缩视频可以视为容器有效负载。
通常,视频文件扩展名指示容器的类型。 例如,video.mp4文件很可能是
MPEG-4 Part 14容器,而名为video.mkv的文件很可能是俄罗斯
玩偶 。 要对编解码器和容器格式完全有信心,可以使用
FFmpeg或
MediaInfo 。
一点历史
在我们开始之前
如何? ,让我们深入了解一下历史,以更好地了解一些旧编解码器。
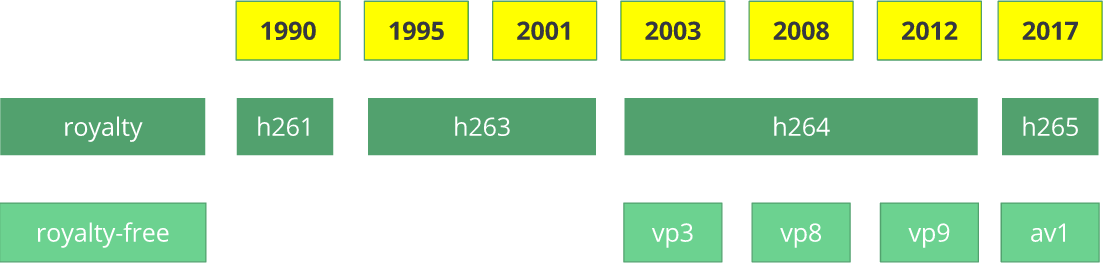
H.261视频编解码器出现在1990年(技术上是1988年),其创建目的是为了以64 Kbps的数据传输速率工作。 它已经使用了一些想法,例如颜色二次采样,宏块等。 1995年,发布了
H.263视频编解码器标准,该标准一直持续到2001年。
H.264 / AVC的第一个版本于2003年完成。 同年,TrueMotion发布了免费的视频编解码器,用于压缩有损视频,称为
VP3 。 Google在2008年收购了这家公司,并于同年发布了
VP8 。 Google在2012年12月发布了
VP9 ,并且在大约3/4的浏览器市场(包括移动设备)中得到了支持。
AV1是
由开放媒体联盟 (
AOMedia )开发
的一种新的免费开源视频编解码器,其中包括Google,Mozilla,Microsoft,Amazon,Netflix,AMD,ARM,NVidia,Intel和Cisco等知名公司。 编解码器0.1.0的第一版于2016年4月7日发布。
AV1的诞生
2015年初,Google开发了
VP10 ,Xiph(属于Mozilla)开发了
Daala ,思科开发了免费的视频编解码器
Thor 。
然后
MPEG LA首次宣布了
HEVC (
H.265 )的年度限制,其费用是H.264的8倍,但他们很快又改变了规则:
没有年度上限,
内容费(收入的0.5%)和
单位成本约为H.264的10倍。
开放媒体联盟是由来自各个领域的公司创建的:设备制造商(英特尔,AMD,ARM,Nvidia,思科),内容提供商(谷歌,Netflix,亚马逊),浏览器制造商(谷歌,Mozilla)等。
两家公司有一个共同的目标-一个没有版税的视频编解码器。 然后是带有更简单的专利许可的
AV1 。 蒂莫西·B·特里贝里(Timothy B. Terriberry)作了精彩的演讲,成为了当前AV1概念及其许可模型的源泉。
得知您可以通过浏览器分析AV1编解码器(您有兴趣的人士可以去
aomanalyzer.org ),您会感到惊讶。

通用编解码器
让我们分析通用视频编解码器的基本机制。 这些概念中的大多数都是有用的,并在
VP9 ,
AV1和
HEVC等现代编解码器中使用。 我警告您,许多解释将被简化。 有时会使用实际示例(与H.264相同)来演示技术。
第一步-分割图像
第一步是将框架分为几个部分,小节等。

为了什么 原因有很多。 分割图片时,我们可以使用较小的部分来预测较小的运动部件,从而更准确地预测运动矢量。 对于静态背景,您可以将自己限制在较大的部分。
通常,编解码器将这些部分组织为部分(或片段),宏块(或编码树的块)和许多子部分。 这些分区的最大大小各不相同,HEVC设置为64x64,而AVC使用16x16,并且每个小节最多可拆分为4x4。
还记得上一篇文章中的各种镜框吗? 可以将同样的方法应用于块,因此,我们可以具有I片段,B块,P宏块等。
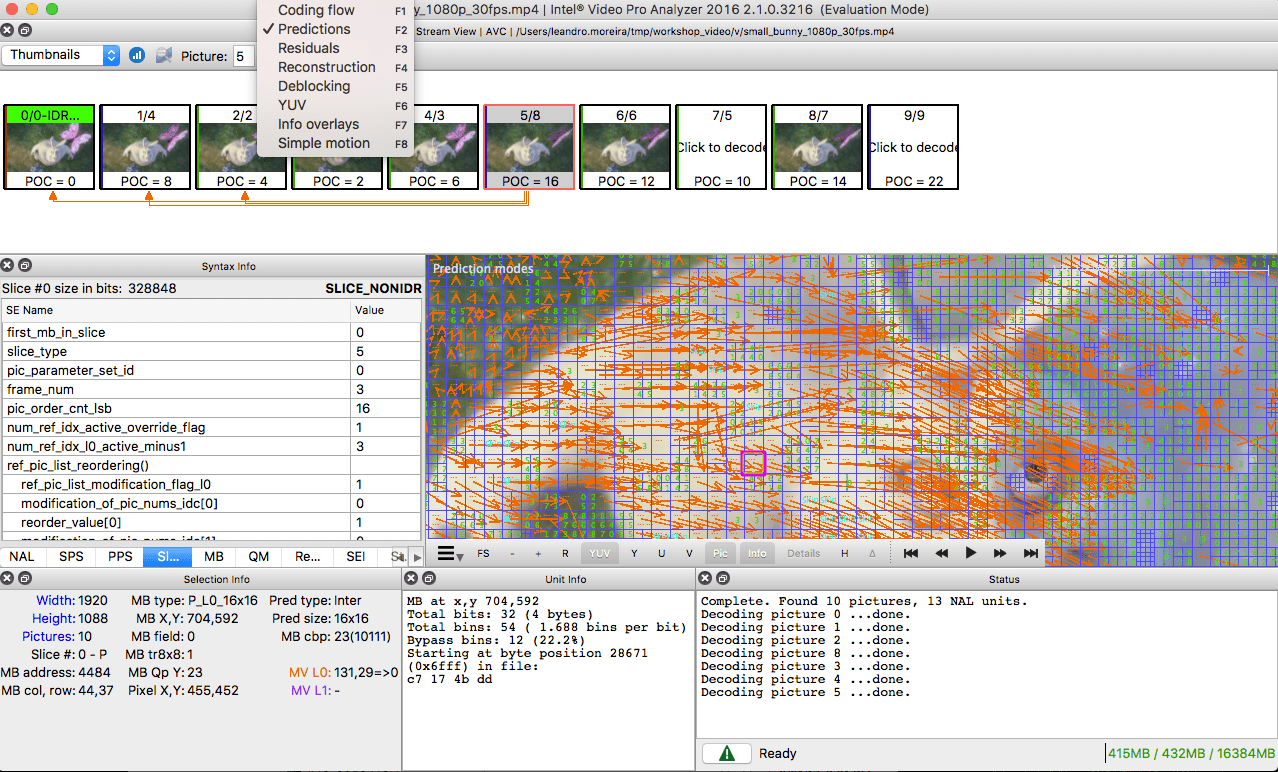
对于那些想练习的人,看看如何将图像分为几个部分和小部分。 为此,您可以使用上一篇文章中已经提到的
Intel Video Pro Analyzer (已付费,但有免费试用版,前10帧有限制)。 此处分析了
VP9的各个部分:

第二步-预测
一旦有了部分,我们就可以对其进行
占星术预测。 对于
INTER预测,有必要传输
运动矢量和余数,对于INTRA预测,则要传输预测
方向和余数。
第三步-转换
在获得残差块(预测部分→实际部分)之后,可以在保持整体质量的同时对它进行转换,以便知道可以丢弃哪些像素。 有一些转换可以提供准确的行为。
尽管还有其他方法,但让我们更详细地考虑
离散余弦变换 (
DCT-来自
离散余弦变换 )。 DCT的主要功能:
- 将像素块转换为大小相等的频率系数块。
- 密封电源,帮助消除空间冗余。
- 提供可逆性。
2017年2月2日,辛特拉·R·J。 (辛特拉,RJ)和拜耳F.M. (Bayer FM)发表了一篇关于类似DCT的图像压缩转换的文章,仅需添加14个即可。
如果您不了解每个项目的好处,请不要担心。 现在,通过具体示例,我们将验证其实际价值。
让我们来像这样一个8x8像素块:
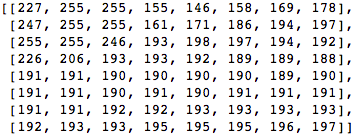
将该块渲染为8 x 8像素的以下图像:
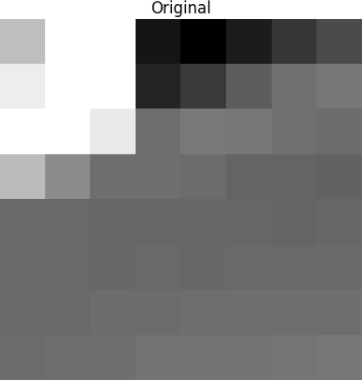
将DCT应用于此像素块,并获得一个大小为8x8的系数块:
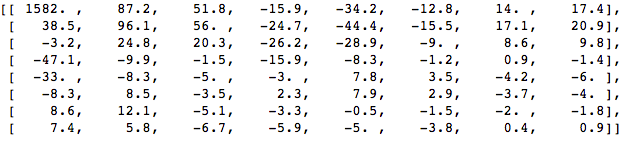
如果渲染此系数块,则会得到以下图像:
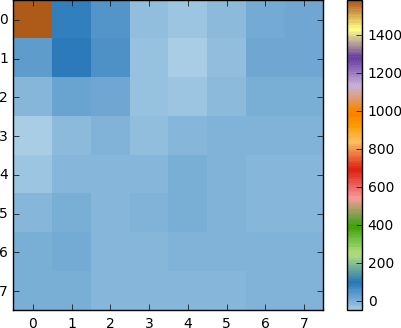
如您所见,这与原始图像不同。 您可能会注意到,第一个系数与所有其他系数有很大不同。 该第一系数称为DC系数,代表输入阵列中的所有样本,类似于平均值。
此系数块具有一个有趣的属性:它将高频分量与低频分量分开。
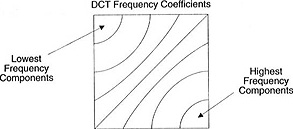
在图像中,大多数功率集中在较低的频率上,因此,如果将图像转换成其频率分量并放弃较高的频率系数,则可以减少描述图像所需的数据量,而不会过多降低图像质量。
频率表示信号变化的速度。
让我们尝试通过使用DCT将原始图像转换为其频率(系数块),然后丢弃一些最不重要的系数,来应用在测试示例中获得的知识。
首先,将其转换为频域。
接下来,我们丢弃部分系数(67%),主要是右下角。
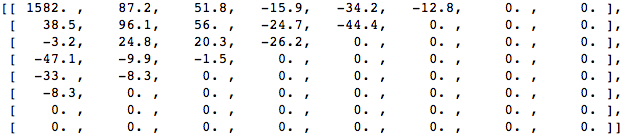
最后,我们从这个废弃的系数块中还原图像(请记住,它必须是可逆的)并与原始图像进行比较。
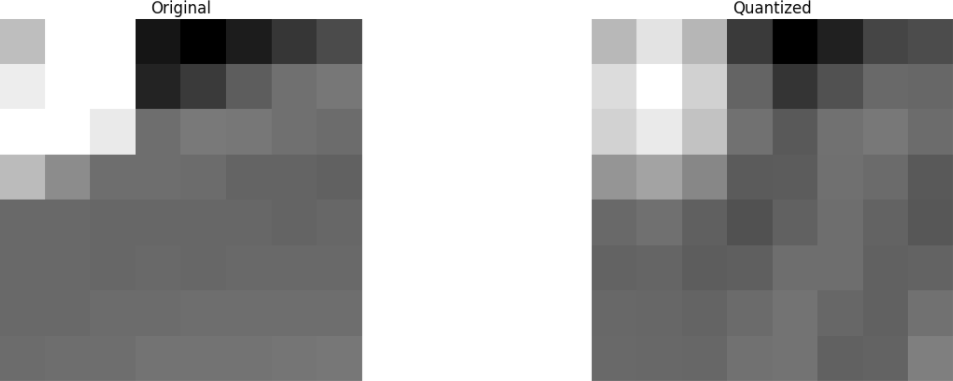
我们看到它类似于原始图像,但是与原始图像有很多差异。 我们投入了67.1875%,但仍然得到了与原始来源相似的东西。 您可以有意地舍弃这些系数以获得质量更好的图像,但这是下一个主题。
使用所有像素生成每个系数。
重要提示:每个系数都不直接显示在一个像素上,而是所有像素的加权和。 这个惊人的图表显示了如何使用每个索引唯一的权重来计算第一和第二系数。
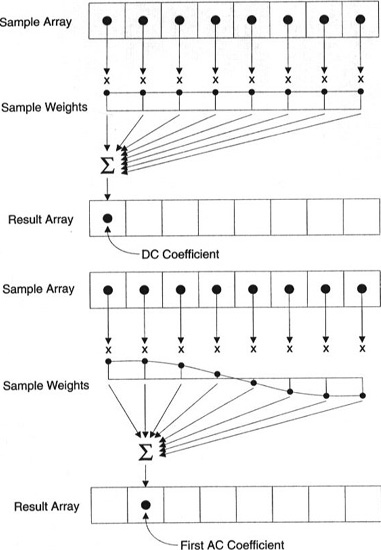
您也可以通过查看基于DCT的简单图像来尝试使其形象化。 例如,这是使用每个系数权重生成的符号A:

第四步-量化
在上一步,最后一步(变换)中丢掉一些系数之后,我们产生了一种特殊的量化形式。 此时,允许丢失信息。 或者,更简单地说,我们将量化系数以实现压缩。
如何量化系数块? 最简单的方法之一是均匀量化,即当我们采用一个块时,将其除以一个值(乘以10)并四舍五入。
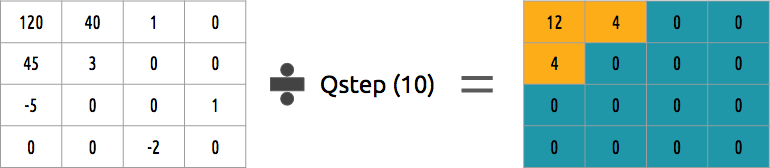
我们可以逆转这个系数块吗? 是的,我们可以乘以除以相同的值。
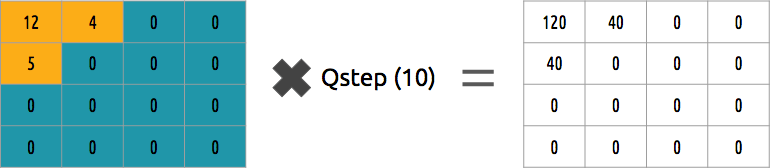
这种方法不是最佳方法,因为它没有考虑每个系数的重要性。 可以使用量化矩阵而不是单个值,并且该矩阵可以使用DCT属性,对大部分右下角和少数左上角进行量化。
5步-熵编码
量化数据(图像块,片段,帧)后,我们仍然可以对其进行压缩而不会丢失。 有许多算法可以压缩数据。 我们将简要地了解其中一些内容,为了更深入地了解,您可以阅读《
理解压缩:现代开发人员的数据压缩 》一书(“
了解压缩:现代开发人员的数据压缩 ”)。
使用VLC进行视频编码
假设我们有一个字符流:
a ,
e ,
r和
t 。 此表中显示了每个符号在流中出现的频率(从0到1)。
我们可以将唯一的二进制代码(最好是较小的)分配给最可能的代码,而将较大的代码分配给不太可能的代码。
我们压缩流,假设最后每个字符花费8位。 如果不对字符进行压缩,则需要24位。 如果每个字符都用其代码替换,那么我们可以节省!
第一步是对字符
e进行编码,该字符
e为10,第二个字符为
a ,该字符被添加(不是在数学上):[10] [0],最后,第三个字符
t ,使我们最终的压缩比特流相等[10] [0] [1110]或
1001110 ,仅需要7位(比原始空间少3.4倍)。
请注意,每个代码都必须是带有前缀的唯一代码。
霍夫曼算法将帮助找到这些数字。 尽管此方法并非没有缺陷,但仍有一些视频编解码器提供此算法来进行压缩。
编码器和解码器都必须使用其二进制代码访问符号表。 因此,也有必要在输入中发送表。
算术编码
假设我们有一串字符:
a ,
e ,
r ,
s和
t ,并且它们的概率由此表表示。
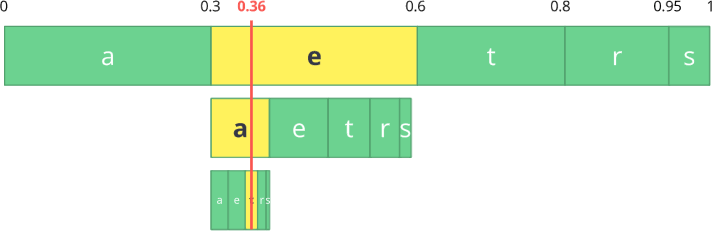
使用此表,我们构造了包含所有可能字符的范围,并按最大数字排序。

现在,让我们编码三个字符的流:
eat 。
首先,选择第一个字符
e ,该字符在0.3到0.6(不包括)的子范围内。 我们采用该子范围,并按照与以前相同的比例再次将其划分,但已经是这个新范围。

让我们继续编码我们的
饮食流。 现在我们取第二个符号
a ,它在0.3到0.39的新子范围内,然后我们取最后一个符号
t ,再次重复相同的过程,我们得到的最后一个子范围从0.354到0.372。
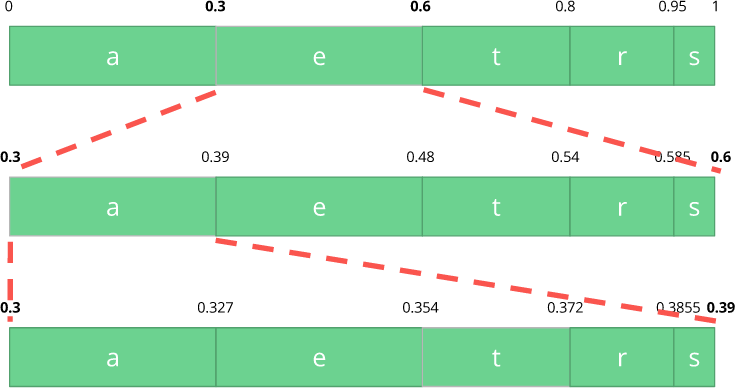
我们只需要在最后一个子范围(从0.354到0.372)中选择一个数字即可。 让我们选择0.36(但您可以在此子范围中选择其他任何数字)。 只有有了这个数字,我们才能恢复原始流程。 就像我们在范围内画一条线来编码流一样。
反向操作(即
解码 )非常简单:使用数字0.36和初始范围,我们可以启动相同的过程。 但是现在,使用此数字,我们将揭示使用此数字编码的流。
在第一个范围内,我们注意到我们的数字对应于一个切片,因此,这是我们的第一个字符。 现在,我们再次共享该子带,执行与以前相同的过程。 在这里,您可以看到0.36对应于字符
a ,并且在重复该过程之后,我们来到了最后一个字符
t (形成了原始的编码流
eat )。
编码器和解码器都必须具有符号概率表,因此,有必要在输入数据中发送它。
非常优雅,不是吗? 提出这个解决方案的人真该死。 某些视频编解码器使用此技术(或者在任何情况下都可以选择使用此技术)。
想法是压缩无损量化比特流。 当然,本文中没有大量的细节,原因,折衷等。 但是,如果您是开发人员,则应该了解更多。 新的编解码器正在尝试使用不同的熵编码算法,例如
ANS 。
6步-比特流格式
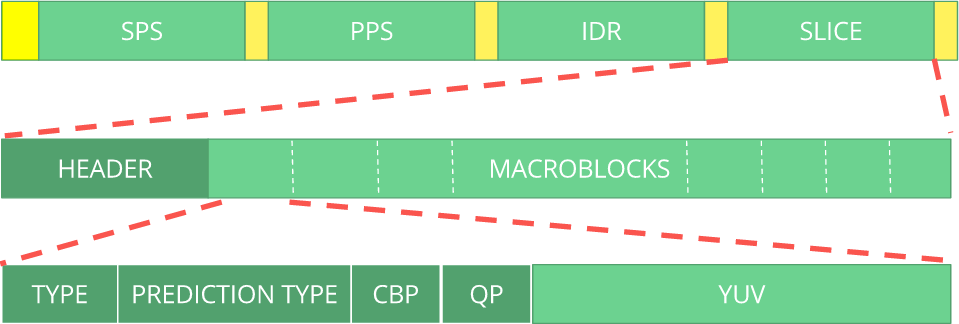
完成所有这些操作后,仍然需要根据所采取的步骤来解压缩压缩帧。 必须将编码器做出的决定明确告知解码器。 解码器应提供所有必要的信息:比特深度,色彩空间,分辨率,预测信息(运动矢量,方向性INTER-prediction),配置文件,级别,帧速率,帧类型,帧号等等。
我们将看一下
H.264比特流。 我们的第一步是创建最小的H.264比特流(默认情况下,FFmpeg添加所有编码参数,例如
SEI NAL-再进一步我们会发现它是什么)。 我们可以使用我们自己的存储库和FFmpeg进行此操作。
./s/ffmpeg -i /files/i/minimal.png -pix_fmt yuv420p /files/v/minimal_yuv420.h264此命令将生成原始帧的
H.264比特流,分辨率为64x64,颜色空间为
YUV420 。 下图用作框架。

H.264比特流
AVC标准 (
H.264 )定义了信息将在称为
NAL的宏帧中(在理解网络的情况下)发送(这是网络抽象的级别)。 NAL的主要目标是提供视频的“网络友好”演示。 该标准应在电视(基于流),互联网(基于包)上工作。

有一个用于定义NAL元素边界的同步标记。 每个同步标记都包含值
0x00 0x00 0x01,除了第一个是
0x00 0x00 0x00 0x01。 如果我们对生成的H.264比特流运行
hexdump ,则将在文件开头至少标识三个NAL模式。
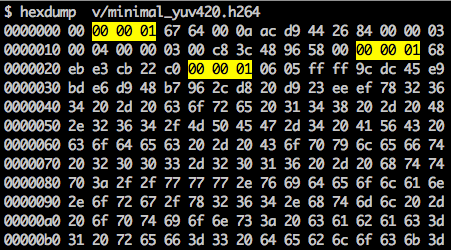
如上所述,解码器不仅必须知道图像数据,而且还必须知道视频,帧,颜色,所用参数等的详细信息。 每个NAL的第一个字节定义其类别和类型。
通常,第一个NAL比特流是
SPS 。 此类NAL负责报告常见的编码变量,例如配置文件,级别,分辨率等。
如果我们跳过第一个同步令牌,则可以解码第一个字节以找出第一个字节是哪种类型的NAL。
例如,同步标记之后的第一个字节是
01100111 ,其中第一位(
0 )在f
orbidden_zero_bit字段中。 接下来的2位(
11 )告诉我们
nal_ref_idc字段
,该字段指示此NAL是否为参考字段。 其余5位(
00111 )告诉我们
nal_unit_type字段
,在这种情况下,它是一个SPS(
7 )NAL块。
SPS NAL中的第二个字节(
二进制 =
01100100 ,
十六进制 =
0x64 ,
dec =
100 )是
profile_idc字段
,该字段显示了编码器使用的配置文件。 在这种情况下,使用了有限的高轮廓(即不支持双向B段的高轮廓)。

如果我们熟悉SPS NAL的
H.264比特流的规范,我们将发现许多参数名称,类别和说明的值。 例如,让我们看一下
pic_width_in_mbs_minus_1和
pic_height_in_map_units_minus_1字段 。
如果我们使用这些字段的值执行一些数学运算,那么我们将获得许可。 您可以使用
pic_width_in_mbs_minus_1值为
119((119 + 1)* macroblock_size = 120 * 16 = 1920)来想象
1920 x 1080 。 同样,节省空间,而不是编码1920,而是使用119。
如果我们继续检查二进制格式的已创建视频(例如:
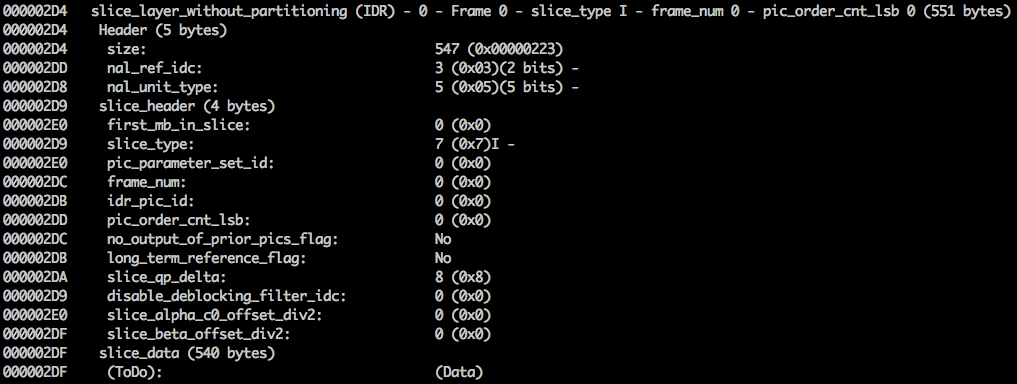
xxd -b -c 11 v / minimal_yuv420.h264 ),则可以转到最后一个NAL,即帧本身。

在这里我们看到它的前6个字节值:
01100101 10001000 10000100 00000000 00100001 11111111 。 由于已知第一个字节指示NAL的类型,因此在这种情况下(
00101 )这是IDR片段(5),因此有可能进一步研究它:

使用规范信息,可以在其他重要字段中解码片段类型(
slice_type )和帧号(
frame_num )。
要获取某些字段(
ue (
v ),
me (
v ),
se (
v )或
te (
v ))的值,我们需要使用基于
指数Golomb码的特殊解码器对片段进行解码。 此方法对于编码变量值非常有效,尤其是在存在许多默认值时。
该视频的
slice_type和
frame_num值为7(I片段)和0(第一帧)。
比特流可以被视为协议。 如果您想进一步了解比特流,则应参考
ITU H.264规范。 这是显示图像数据位置的宏(压缩形式的
YUV )。
您可以浏览其他比特流,例如
VP9 ,
H.265 (
HEVC ),甚至是我们最新的最佳
AV1比特流。 他们都一样吗? 不,但是与至少一个人打交道更容易理解其余内容。
想练习吗? 探索H.264比特流
您可以生成单帧视频,并使用MediaInfo检查H.264比特流。 实际上,没有什么可以阻止您甚至查看分析H.264 ( AVC )比特流的源代码。
作为练习,您可以使用Intel Video Pro Analyzer(我已经说过该程序是付费的,但是有免费的试用版吗(最多10帧)?)
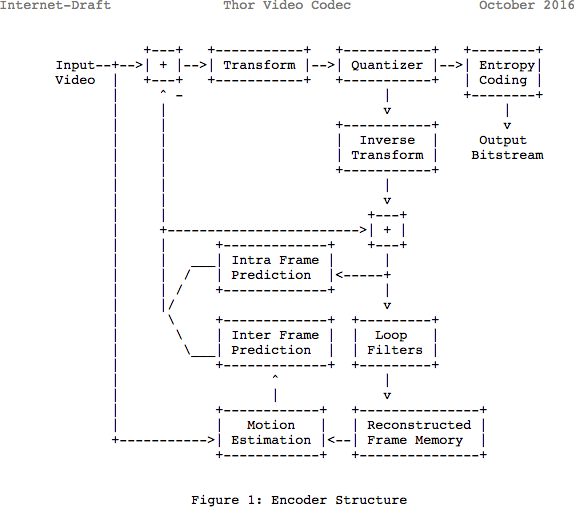
复习
请注意,许多现代编解码器都使用他们刚刚学习的相同模型。 在这里,让我们看一下
Thor视频编解码器的框图。 它包含我们已采取的所有步骤。 这篇文章的重点是让您至少更好地了解该领域的创新和文档。
以前,据估计,要以720p和30 fps的质量存储持续一小时的视频文件,需要139 GB的磁盘空间。 如果使用本文中讨论的方法(帧间和内部预测,转换,量化,熵编码等),则可以实现(假设我们每像素花费0.031位),视频的质量相当令人满意,它占用了仅367.82 MB,而不是139 GB的内存。
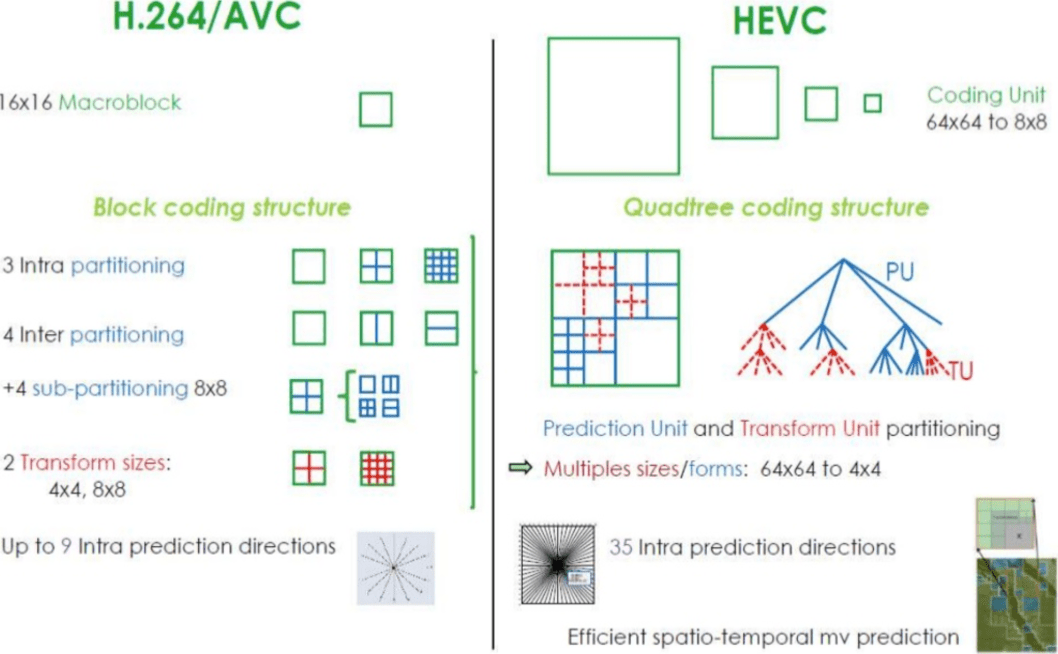
H.265如何获得比H.264更好的压缩率?
现在,您对编解码器的工作原理有了更多的了解,现在更容易理解新编解码器如何以更少的位数提供更高的分辨率。
在比较
AVC和
HEVC时 ,您不应忘记,这几乎总是在较高的CPU负载和压缩率之间进行选择。
与
AVC相比,
HEVC的部分(和子部分)选项更多,内部预测的方向更多,改进的熵编码等等。 所有这些改进使
H.265的压缩能力比
H.264高 50%。

另请阅读博客
EDISON公司:
20个图书馆
壮观的iOS应用程序