上学年四月。 学生越来越多地开始认为有必要做论文的想法。 从某种意义上说,要做到这一点就是要弄清楚如何快速制作出至少与主管认可的主题相吻合的东西。 而且,是的,您至少需要80页,还必须遵守各种GOST规范。。。很显然,您没有时间自己键入太多连接的文本(它们甚至可以进入工作的本质,好吧!)。 显然-您需要完成已经辩护的工作,质量工作,测试和批准的工作。 我们所有人都熟悉这种情况。 唯一悬而未决的问题是如何确保对作品进行借用测试...搜索Internet并与不幸的同事进行交流导致学生选择以下解决问题的方法:
自己写作品;- 改写文本(昂贵又困难);
- 通过“技术解决方案”胜过系统。

让我们看看是什么技术回合,我们如何抓住它们以及为什么不善用它们……
如果措辞得当,改写可以帮助您将别人的文本当作您自己的文本。 但是,高质量的措辞本身是一个非常费力的过程,因此学生很可能没有时间和金钱。 简单的表述方式(例如,同义词)将产生的结果不仅会被反Anti窃系统检测到 ,而且很可能会使主管和认证委员会感到困惑。
因此,我们找到了学生中最具创造力和最受欢迎的工具-技术解决方法-文档转换,该转换无需更改原始文档的显示,即可更改检查系统提取的文本。
从处理技术回合的角度(以下简称为“回合”) 来看 , Anti窃系统有两个任务:
- 检测潜在的旁路并通知用户有关旁路的信息;
- 从抓取中清除选中的文本。
处理回合的一般方案可以描述如下:
- 检测旁路,保存有关旁路的信息;
- 从抓取中清除提取的文本;
- 基于绕道而行的文件“可疑性”定义;
- 向用户显示有关可疑性的信息,显示发现的弯路。
这就是实际的样子。
docx格式的文件:
检查不具有爬网检测功能的文档:
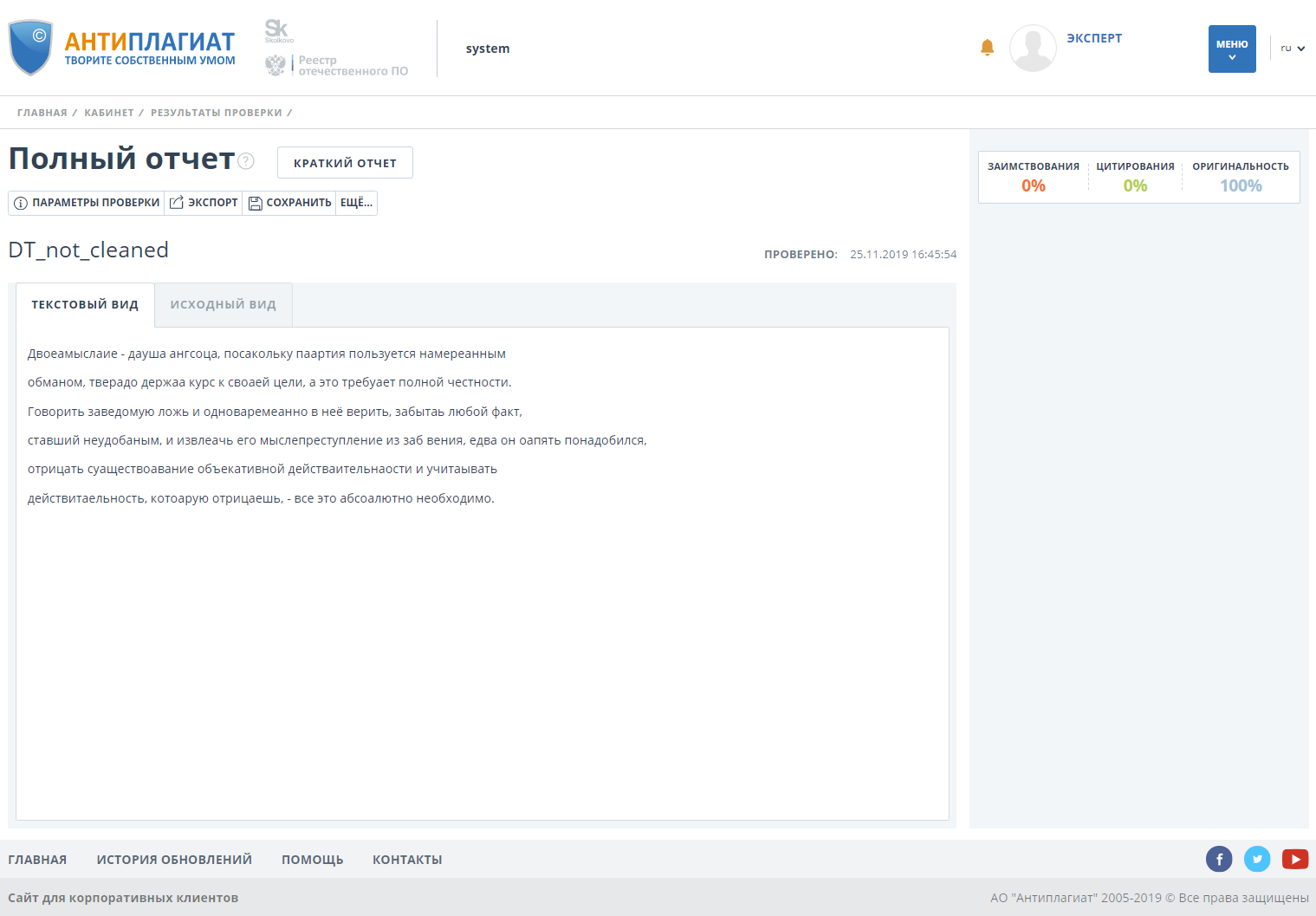
该文件具有百分之一百的原创性。
我们在打开旁路检测功能的情况下检查了文档,发现原创性下降到了0。

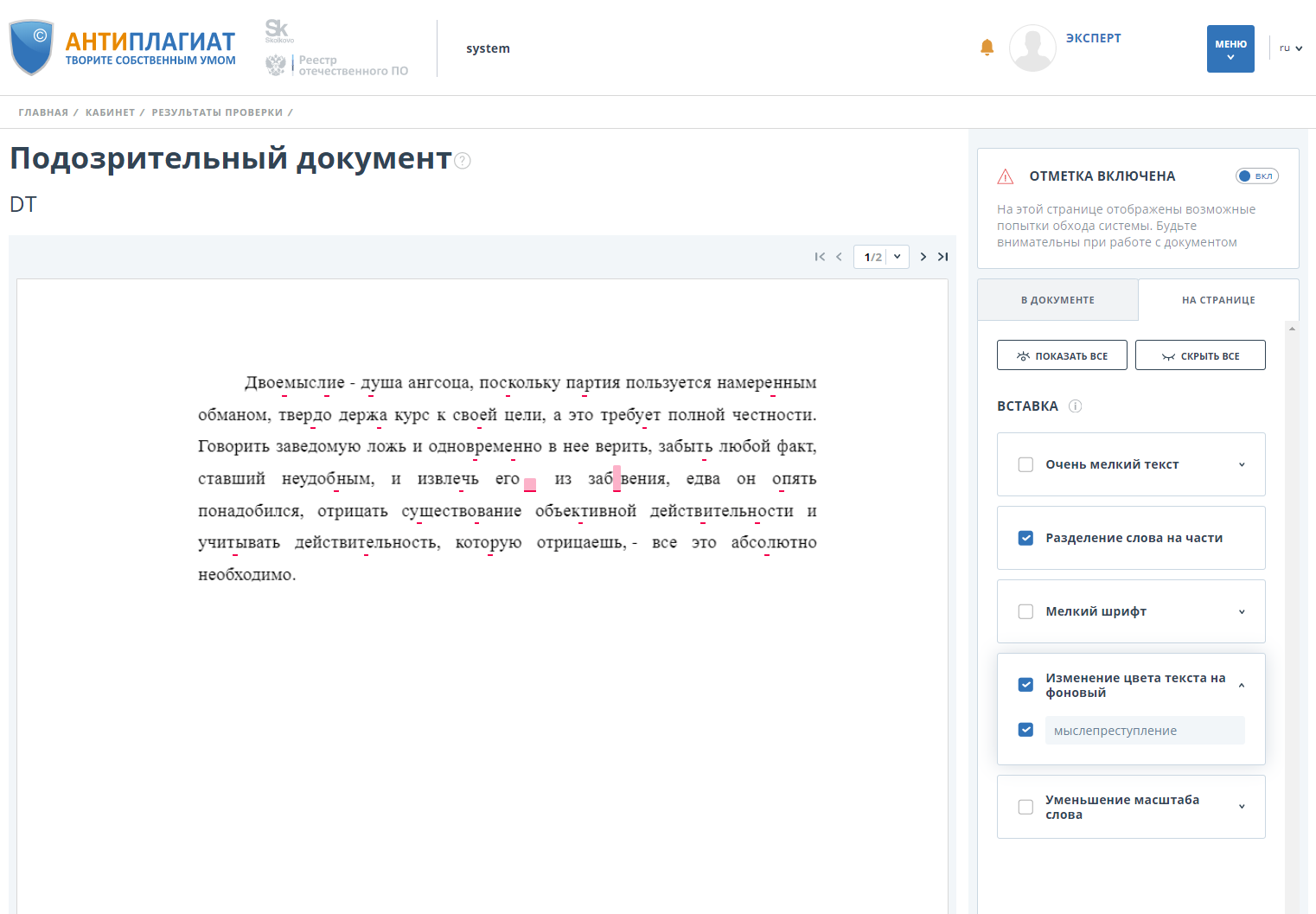
另外,系统将文档标记为“可疑”,并向用户显示在何处以及检测到哪些绕过:
由于技术解决方法的目的是增加文档的独创性,因此根据它们如何影响文档验证对它们进行分类很有趣。 基于检查文档是否借用的主要因素是文档的单词这一事实,根据其对提取的文档单词的影响,可以将变通方法分为以下几种类型:
- 更改单词(提取的文本中的单词与源文档中显示的单词不同);
- 添加一个单词(该单词在源文档中不可见,出现在文档的提取文本中);
- 删除单词(该单词在源文档中可见,而在文档的提取文本中不可见);
- 分词(原始文档中的单词正常显示,固化后的文本分为两个或更多部分);
- 合并单词(源文档中显示几个单词,它们在提取的文本中合并为一个单词)。
让我们看看我们面临的解决方法。 让我们从简单的故事开始,然后走向最有趣的故事。
文字检索
这种类型的旁路绝不与文档的格式相关;它们会更改单词的字符串值,以使它们继续看起来与原始单词相同。
文字
我们记录的第一种变通办法是用单形文字替换字母,这些文字在外观上与原始字母相似,但含义不同。 Omoglyphia从反古籍制度存在的最早开始就被使用,尽管事实上它已经被我们抓住了很长时间,但在学生工作中我们仍然遇到类似的弯路。
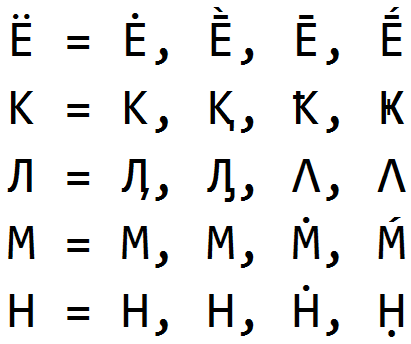
只要知道每个单词的语言,就可以轻松找到并清除文字。 即使文本包含多种语言和大量“垃圾”(象形文字和其他多余字符),我们也可以相当准确地确定文本中每个单词的语言。 单独文章的主题如何。 有了语言一词和该语言的可能同形文字列表,我们恢复了原始语言的字母并保存了有关找到的同形文字的信息。
无法打印的字符
更改单词的字符串值而不显着更改其显示的另一种方法是使用不可见或不明显的Unicode字符。 在单词中插入此类字符会更改单词的字符串含义,而实际上不会更改其显示。
这些字符中的许多字符都在Unicode类别的“其他,控件”和“标记,非间距”中 。
系统会简单地删除这些字符,并且当它们数量很多时,会通知用户文档的可疑性,并在报告中显示清除的不可打印字符。
PDF解决方法
如前所述 ,处理文档的关键格式是pdf。 我们将所有其他类型的文档转换为pdf,以便对所有支持的格式统一处理文档的基本逻辑。 因此,可以在pdf文档中实现的变通办法对我们特别感兴趣。
小文字
首先想到的一种变通办法是使某些东西变小且不可见。 这样获得的文本在查看原始文档时不可见,但由系统检索。 实现非常简单-设置文本的最小字体大小,更改文本的颜色。 捕获这种类型的旁路非常简单-只需检查文本的字体大小和单个单词的几何尺寸即可。 由于尺寸较小,学生经常将此类隐藏文本的整个段落添加到页面中:

显示检测到的爬网尝试:

将文字颜色更改为背景
尽管该方法经常与前一种方法结合使用,但其独立使用更为有趣。 事实是,对于我们来说,检测并清除旁路就足以确定单词/符号的至少一个参数具有“可疑”值。 并且,如果单词的小尺寸定义很简单,那么颜色与背景匹配的文本的定义将是一个更复杂的过程。
在以下情况下,检测到不可见的文本会变得很复杂:
- 并非总是能够从pdf中获取特定字符的颜色。
- 单词的背景可能不是白色。 而且,单词可能在图像的背景上;
- 单词和符号可以相互碰到。
为了消除前两个困难,可以通过分析文档页面的渲染图像来确定文本的“隐身性”:
- 确定包含单词的页面区域;
- 我们计算获得的区域的方差。 如果方差低于某个阈值-在分析区域中,我们具有统一的颜色,则看不到字母。 因此,尝试绕过系统。
单词和符号一个接一个地隐藏
如果将不可见字符隐藏在其他“可见”字符后面,则无法通过分析它们所在的区域来检测不可见字符。 因此,要检测此类“隐藏”字符,我们有一个单独的过程来分析符号区域的交集并标记那些其他字符大部分重叠的字符。

检测到的旁路:
文字为图片
如果我们将部分文本替换为包含该文本的图像会发生什么? 以适当的精度,所有内容看起来都像文档中没有任何变化一样,但是当您提取文本层时,自然地,将不会提取图片中的单词。 为了缩小这一差距,我们使用光学文本识别。
使用docx到pdf转换功能的解决方法
将文档转换为pdf并非易事。 您可以在此处阅读有关我们如何选择最适合的解决方案的信息 。 不幸的是,即使是我们分析过的最佳选项,也无法将文档转换为pdf。 尝试绕过系统时,会主动使用一些转换的“功能”。
公式
转换为pdf后,公式和许多其他包含文本的对象将“丢失”。 因此,您可以尝试隐藏文本的整个段落,例如,隐藏文本中的每个第二个单词:

转换为pdf时,我们得到以下结果:

为了检测和清除此方法以及其他变通方法(通过将docx转换为pdf的功能得到加强),我们分析并清除了源docx文件。 特别是,如果在文档中找到大量公式,我们将其替换为纯文本,当文档转换为pdf时将保存该纯文本。 此外,我们还记得我们处理过的公式的位置,并在必要时告知用户所检查文档的可疑性,并突出显示从公式中还原的文本。
比例尺,小符号/行距
转换为pdf时,不考虑许多文本属性:比例,符号间和行距。 这样,您就可以添加在源文档中不可见的文本(例如,比例很小),而pdf中的文本变成不突出的普通文本。 绕过实施(docx):

转换为pdf的结果(我们自己更改了颜色):

捕获此文本的唯一方法是在docx中找到它并保存有关它的信息。 如果我们在文档中找到很多此类文本,则会将文档标记为可疑,并向用户显示在文档中找到可疑属性的文本的位置。
把一个词弄成碎片
应用上一段中描述的属性的一个有趣的特殊情况是在单词上添加一个空格并将其隐藏。 在原始文档中,该单词看起来很普通,已合并,并且在将文档转换为pdf后,随着空间变大,它将分为两部分。 我们用与上一段相同的方式听到类似的假笑。 绕过实施(docx):

转换为pdf的结果:

显示绕行旁路:

在光秃秃的板栗树下,我背叛了你,而你我...
我们讨论了基本的方法,但绝不是解决方法的所有技术方法。 当然,我们不可能使防御绝对化。 但是,我们正在不断改进我们的系统,从而使“欺骗”它的机会越来越少。 在会话中,我们尝试特别快地关闭可检测到的漏洞-通常从发现漏洞的那一刻起直到产品被关闭为止,只过了几天。 这就是为什么有点滑稽和悲伤的同时阅读广告“承诺”的公司愿意帮助学生提高他们的工作的独创性,给他们的工作保障,有时高达30天。 学生,你会被出卖! 最好的情况是,这种“担保”可以将履带公司的服务成本退还给您,但如果文凭失败并可能被大学开除,则无济于事。
用自己的思想创造!