
我们成为我们所看到的。 首先,我们对工具进行成型,然后对我们进行成型。
麦克卢汉元帅
我要衷心感谢并感谢我的好朋友里卡多·苏埃拉斯 ( Ricardo Sueiras)的评论,贡献以及不让我留下这篇未完成的文章。 里卡多,你只是一个传奇!
重要的是要记住,当您释放猴子并随意输入失败时,混乱的工程并不是要发生的。 混沌工程是一种定义明确, 形式化的实验技术 。
“混沌工程涉及仔细观察,对观察对象持严重怀疑态度,因为认知假设扭曲了结果的解释。该技术涉及通过基于相似观察的归纳来提出假设;基于实验和基于测量的对相似假设得出的结论进行检验;调整或根据实验结果拒绝假设”
—维基百科
混沌工程学首先要了解您正在处理的系统的稳定状态,随后的假设表述,最后是要进行验证的实验,以帮助提高系统的安全性。
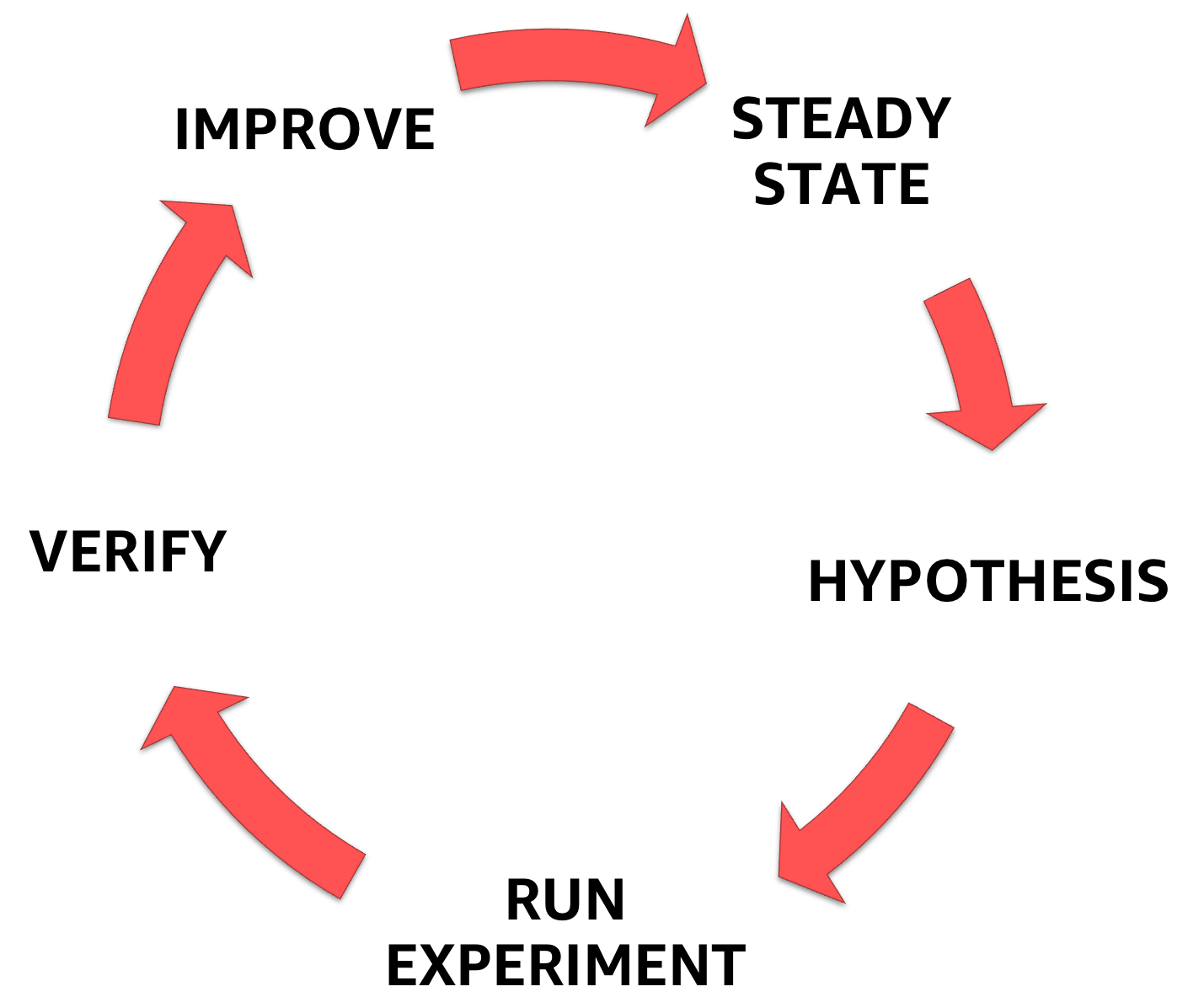
混沌工程阶段
在系列文章的第一部分中,我介绍了混沌工程,并讨论了上述方法的每个步骤。
在第二部分中 ,我研究了在设计混沌工程实验时需要投资的领域,以及如何选择正确的假设。
在第三部分中,我将重点介绍实验本身,并介绍涵盖广泛故障的一系列工具和方法。
该清单不是详尽无遗的,但从头开始并给予深思,它就足够了。
引入故障-它有什么作用?
故障用于验证系统响应在正常负载条件下是否符合规格。 通过改变设备上的电信号,在“铁”级(触点级) 引入故障时,首次使用了该技术。
在编程中,引入故障有助于提高软件系统的稳定性,并允许您纠正对系统潜在故障的抵抗力方面的缺陷。 这称为故障排除。 它还有助于评估故障造成的损害-即 甚至在生产环境中发生故障之前的损坏半径。 这称为故障预测。
引入故障有几个主要好处,有助于:
- 了解并实践对事故和事件的响应。
- 了解实际失败的后果。
- 了解容错机制的有效性和局限性。
- 消除设计错误并检测常见的故障点。
- 了解并提高系统的可观察性。
- 了解失败的失败半径并缩小范围。
- 了解系统组件之间的错误分布。
失败类别
引入故障有5种类型:(1)资源级别; (2)网络与依存关系; (3)应用,流程和服务; (4)基础设施; (5)人身**。
接下来,我将研究每种类别,并举例说明每种类别的故障。 我还将考虑引入故障和多合一编排工具的示例。
**重要! 在这篇文章中,我不会在人的层面上介绍失败的内容,但是我将在下面进行介绍。
1-在资源级别引入失败,也就是缺乏资源。
是的,云技术告诉我们资源几乎是无限的,但是我赶紧让您失望:它们不是无限的。 实例,容器,函数等 -无论抽象如何,资源最终都会耗尽。 超出资源的最大允许消耗称为消耗。

资源的缺乏模仿了拒绝服务攻击,但无法渗透到预期的服务器。 故障的引入可能很普遍,因为可能不难使用。
耗尽CPU,内存和I / O资源
我最喜欢的工具之一是Stress-ng,它是由Amos Waterland编写的原始压力测试工具 的对应物。
使用Stress-ng,可以通过加载计算机的各个物理子系统以及使用压力测试控制系统核心的接口来输入故障。 提供以下压力测试:CPU,CPU缓存,设备,I / O,中断,文件系统,内存,网络,OS,管道,调度程序和VM。 手册页包括所有可用压力测试的完整说明,其中只有220个!
以下是一些有关如何使用Stress-ng的实际示例:
CPU matrixprod上的负载可以正确地混合使用内存,缓存和浮点运算。 这也许。 充分预热CPU的最佳方法。
❯ stress-ng —-cpu 0 --cpu-method matrixprod -t 60s
iomix-bytes负载为每个iomix处理程序iomix写入N个字节; 默认值为1 GB,非常适合执行I / O压力测试。 在此示例中,我将在文件系统上设置80%的可用空间。
❯ stress-ng --iomix 1 --iomix-bytes 80% -t 60s
vm-bytes非常适合进行内存压力测试。 在此示例中,Stress-ng对虚拟内存运行9个压力测试,每小时总共消耗90%的可用内存。 因此,每个发束测试会消耗10%的可用内存。
❯ stress-ng --vm 9 --vm-bytes 90% -t 60s
硬盘驱动器上的磁盘空间不足
dd是编译用于转换和复制文件的命令行实用程序。 但是, dd可以从特殊设备(例如/dev/zero和/dev/random文件中读取和/或写入,以执行诸如备份硬盘的引导扇区并获取固定数量的随机数据之类的任务。 因此,它可用于在服务器上引入故障并模拟磁盘溢出。 您的日志文件是否使服务器溢出并删除了应用程序? 因此, dd会有所帮助-而且会很痛!
小心使用dd 。 输入错误的命令-硬盘上的数据将被擦除,破坏或覆盖!
❯ dd if=/dev/urandom of=/burn bs=1M count=65536 iflag=fullblock &
应用程序API速度降低
API的性能,弹性和可伸缩性很重要。 API对于构建应用程序和发展业务至关重要。
负载测试是在您的应用程序投入生产之前对其进行测试的好方法。 这也是一种很酷的压力加载方法,因为它通常会显示出例外和限制,在其他情况下,这些例外和限制在遇到实际流量之前仍然不可见。
wrk是一个HTTP基准测试工具,对系统造成很大的压力。 我特别喜欢测试API可访问性检查,尤其是在性能检查方面 ,因为它们在开发人员代码级别上揭示了许多有关设计决策的内容:如何配置缓存? 限速如何实施? 系统是否优先考虑有关负载均衡器的运行状况检查?
从这里开始:
❯ wrk -t12 -c400 -d20s http://127.0.0.1/api/health
此命令启动12个线程,并保持400个HTTP连接打开20秒钟。
2-引入网络级故障和依赖关系
彼得·德意志(Peter Deutsch)的书《分布式计算的八个谬论》是开发人员在设计分布式系统时所做的一系列假设。 然后答案以无法访问的形式出现,您必须重做所有事情。 这些错误的假设是:
- 网络是可靠的。
- 延迟为0。
- 带宽是无限的。
- 网络是安全的。
- 拓扑不会更改。
- 只有一名管理员。
- 转移费用0。
- 网络是同质的。
如果要测试分布式系统是否可以处理网络故障,此列表是选择故障转移的一个很好的起点。
引入网络延迟,丢失和中断
引入网络延迟,丢失或中断
tc ( 流量控制 )是用于配置Linux内核批处理调度程序的Linux命令行工具。 它定义了数据包如何在网络接口中排队以进行发送和接收。 操作包括排队,策略定义,分类,计划,调整和丢失。
tc可用于模拟UDP或TCP应用程序的延迟和数据包丢失,或限制特定服务带宽的使用-模拟Internet流量的状况。
-引入100 ms的延迟
#Start ❯ tc qdisc add dev etho root netem delay 100ms #Stop ❯ tc qdisc del dev etho root netem delay 100ms
-引入100 ms的延迟和50 ms的增量
#Start ❯ tc qdisc add dev eth0 root netem delay 100ms 50ms #Stop ❯ tc qdisc del dev eth0 root netem delay 100ms 50ms
-损坏5%的网络数据包
#Start ❯ tc qdisc add dev eth0 root netem corrupt 5% #Stop ❯ tc qdisc del dev eth0 root netem corrupt 5%
-7%的封包丢失率和25%的相关性
#Start ❯ tc qdisc add dev eth0 root netem loss 7% 25% #Stop ❯ tc qdisc del dev eth0 root netem loss 7% 25%
重要! 7%足以使TCP应用程序不丢失。
玩“ / etc / hosts”-主机名的静态查找表
/etc/hosts是一个简单的文本文件,该文件将IP地址与主机名关联起来,一次仅一行。 每个节点需要一行包含以下信息:
IP_address canonical_hostname [aliases...]
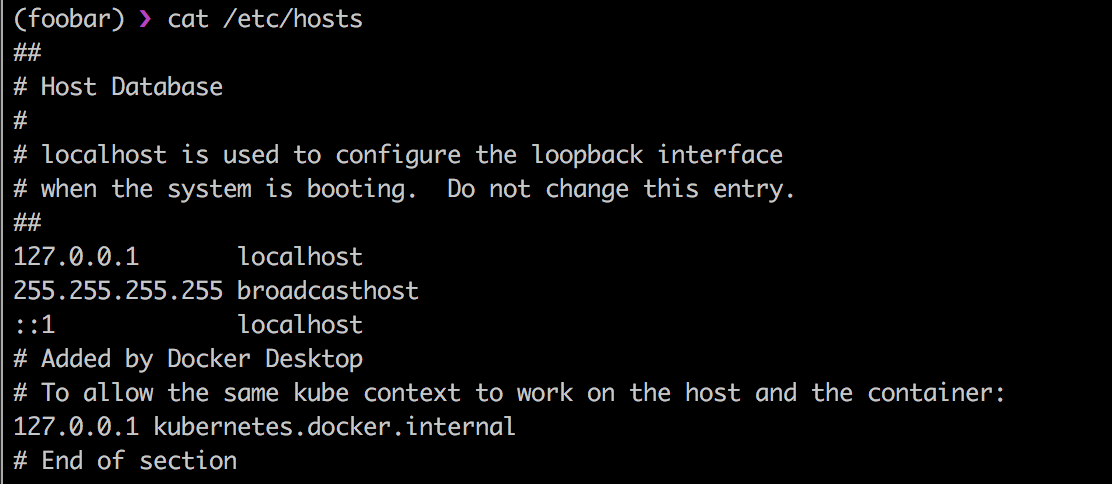
主机文件是访问计算机网络上的网络节点并将人们理解的主机名转换为IP地址的几种系统之一。 是的,您猜对了:由于它,欺骗计算机很方便。 以下是一些示例:
-阻止对EC2实例的DynamoDB API的访问
#Start # make copy of /etc/hosts to /etc/host.back ❯ cp /etc/hosts /etc/hosts.back ❯ echo "127.0.0.1 dynamodb.us-east-1.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 dynamodb.us-east-2.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 dynamodb.us-west-1.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 dynamodb.us-west-2.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 dynamodb.eu-west-1.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 dynamodb.eu-north-1.amazonaws.com" >> /etc/hosts #Stop # copy back the old version /etc/hosts ❯ cp /etc/hosts.back /etc/hosts
-阻止从EC2实例访问EC2 API
#Start # make copy of /etc/hosts to /etc/host.back ❯ cp /etc/hosts /etc/hosts.back ❯ echo "127.0.0.1 ec2.us-east-1.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 ec2.us-east-2.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 ec2.us-west-1.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 ec2.us-west-2.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 ec2.eu-west-1.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 ec2.eu-north-1.amazonaws.com" >> /etc/hosts #Stop # copy back the old version /etc/hosts ❯ cp /etc/hosts.back /etc/hosts
实时观看:首先,EC2 API可用,并且ec2 describe-instances成功返回。
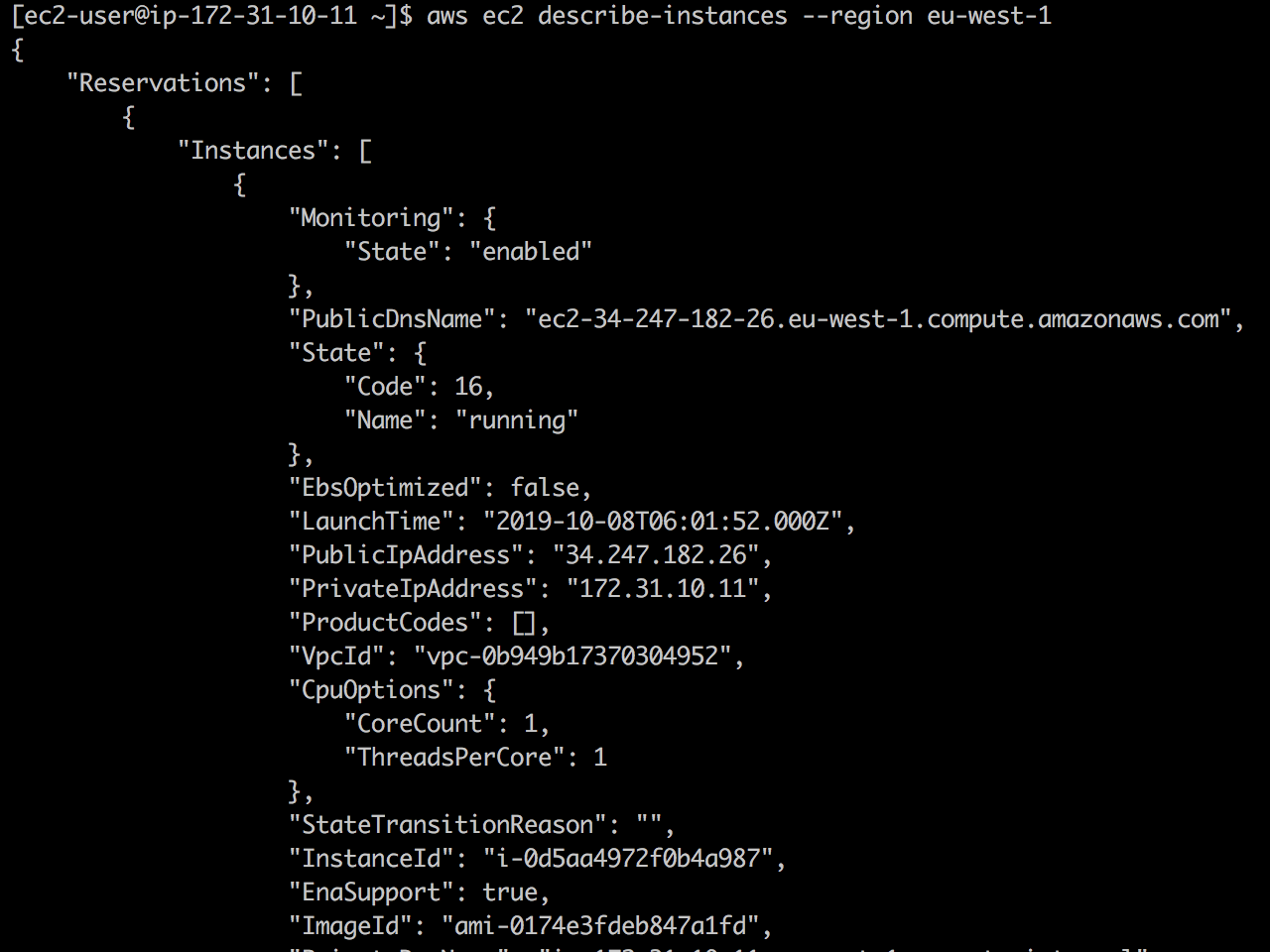
将127.0.01 ec2.eu-west-1.amazonaws.com添加到/etc/hosts ,EC2 API调用就会127.0.01 ec2.eu-west-1.amazonaws.com 。

当然,这适用于所有AWS API。
我会讲一个关于DNS的玩笑...

...但是,恐怕它只会在第二天到达您。 我的意思是24小时后。
2016年10月21日,由于DDoS Dyn攻击,欧洲和北美的大量平台和服务不可用。 根据ThousandEyes关于2018年全球DNS性能的报告 ,60%的企业和SaaS提供商仍依赖单一来源的DNS提供商,因此容易受到DNS故障的影响。 而且由于没有DNS,就不会有Internet,因此,模拟DNS故障以评估您对下一个DNS故障的适应性将非常有用。
Blackholing是一种传统上可以减少DDoS攻击损害的方法。 不良的网络流量被路由到黑洞,并被丢弃到无效位置。 用于网络上的/dev/null版本:-)您可以使用它来模拟网络流量的丢失或同一DNS的协议,例如。
对于此任务,您需要iptables工具,该工具用于在Linux内核中配置,维护和验证IP数据包。
要通过黑洞获取DNS流量,请尝试以下操作:
#Start ❯ iptables -A INPUT -p tcp -m tcp --dport 53 -j DROP ❯ iptables -A INPUT -p udp -m udp --dport 53 -j DROP #Stop ❯ iptables -D INPUT -p tcp -m tcp --dport 53 -j DROP ❯ iptables -D INPUT -p udp -m udp --dport 53 -j DROP
使用Toxiproxy进行故障介绍。
诸如tc和iptables类的Linux工具iptables一个(但不是唯一的)严重问题。 他们需要root权限才能运行,这给某些组织和环境带来了问题。 请爱与宠爱-Toxiproxy !
Toxiproxy是由Shopify工程师团队开发的开源TCP代理。 它有助于模拟混沌网络和系统状况或实际系统。 如下所示,将其放置在体系结构的各个组件之间。
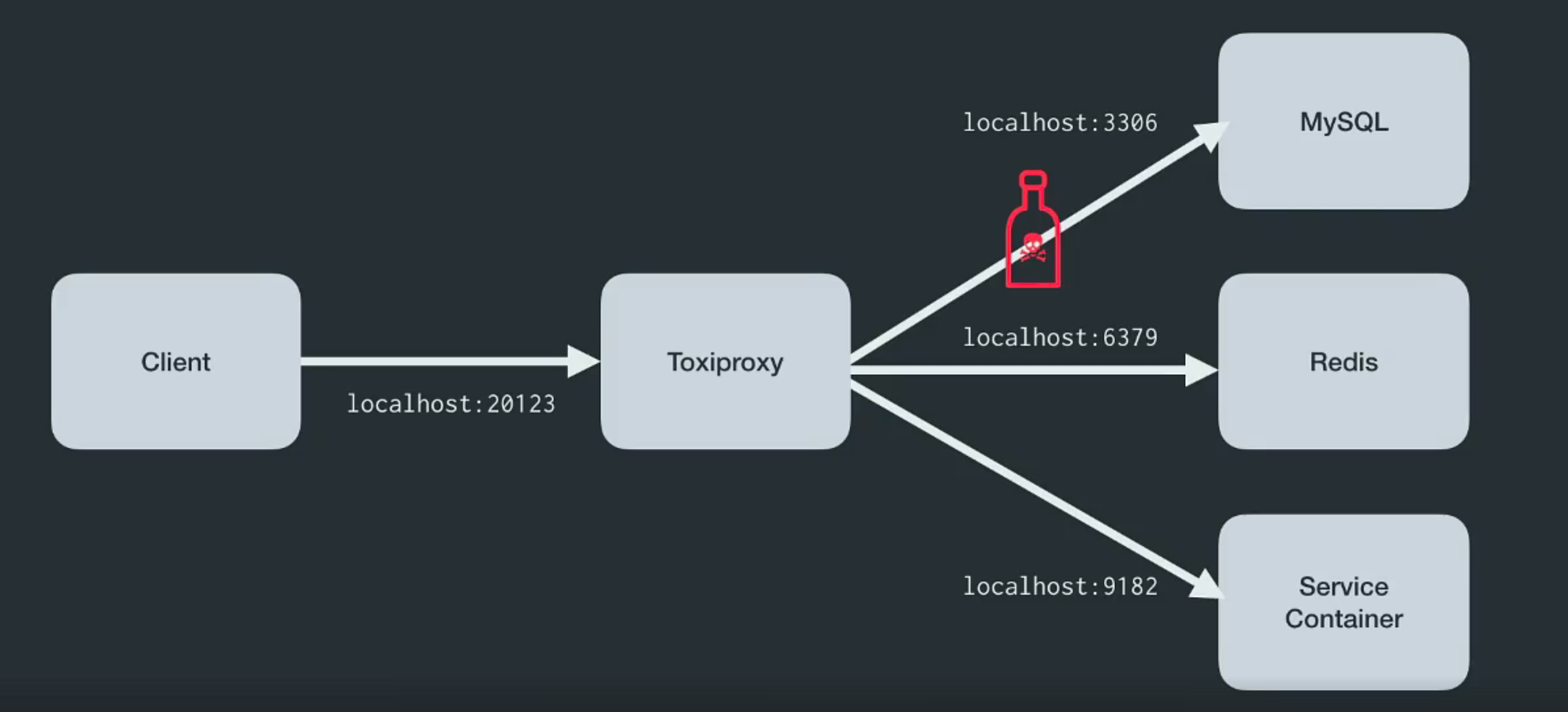
它是专门为测试,CI和开发环境而创建的,并引入了预定义的或随机的混乱,这些混乱可通过设置来控制。 Toxiproxy使用有毒物质来操纵客户端和开发人员代码之间的关系,并且可以通过HTTP API对其进行配置。 对他来说,药盒中有足够的毒物可以上手。
以下示例通过在我的Redis客户端,redis-cli和Redis本身之间的连接中引入1000毫秒的延迟,展示了Toxiproxy如何与有毒客户端代码一起工作。
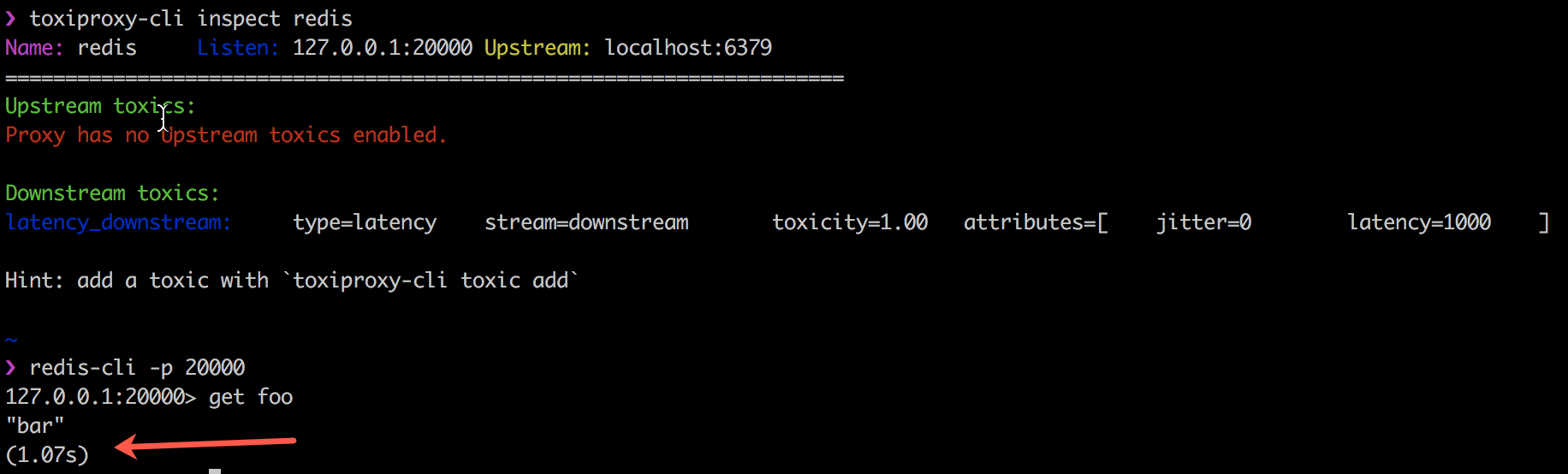
自2014年10月起,Shopify已成功在所有生产和开发环境中使用Toxiproxy。 更多信息在他们的博客上 。
3-在应用程序,流程和服务级别引入故障
该软件正在下降。 这是事实。 那你怎么办? 我是否应该通过SSH在服务器上登录并重新启动失败的进程? 过程控制系统提供启动,停止,重新启动类型的状态控制或状态更改功能。 控制系统通常用于确保稳定的过程控制。 systemd就是这样的工具,为Linux提供了基本的过程控制块。 Supervisord可控制诸如UNIX之类的操作系统上的多个进程。
部署应用程序时,应使用这些工具。 测试杀死关键进程所造成的损害当然是一种好习惯。 确保收到警报,并且该过程会自动重新启动。
-杀死Java进程
❯ pkill -KILL -f java #Alternative ❯ pkill -f 'java -jar'
-杀死Python进程
❯ pkill -KILL -f python
当然,您可以使用pkill命令杀死系统上运行的许多其他进程。
引入数据库故障
如果存在操作员不希望收到的故障消息,则这些故障消息与数据库故障有关。 数据价值不菲,因此,每当数据库崩溃时,丢失客户数据的风险就会增加。

它将很容易维护。 越来越等等...一切都下降了
有时,恢复数据并使数据库尽快进入工作状态的能力决定了公司的未来。 不幸的是,为各种模式的数据库故障做准备也不总是很容易-其中许多仅会在生产环境中弹出。
但是,如果您使用的是Amazon Aurora ,则可以使用故障转移请求来测试Amazon Aurora数据库集群对故障的恢复能力 。
Amazon Aurora崩溃介绍
失败请求作为SQL命令发布到Amazon Aurora实例,并允许您安排以下事件之一的模拟:
- 写入数据库实例失败。
- 极光副本失败。
- 磁盘故障。
- 磁盘过载。
发送故障请求时,还必须指定模拟故障事件的时间。
-导致Amazon Aurora实例故障:
ALTER SYSTEM CRASH [ INSTANCE | DISPATCHER | NODE ];
-模拟Aurora副本的故障:
ALTER SYSTEM SIMULATE percentage PERCENT READ REPLICA FAILURE [ TO ALL | TO "replica name" ] FOR INTERVAL quantity { YEAR | QUARTER | MONTH | WEEK | DAY | HOUR | MINUTE | SECOND };
-模拟Aurora数据库集群的磁盘故障:
ALTER SYSTEM SIMULATE percentage PERCENT DISK FAILURE [ IN DISK index | NODE index ] FOR INTERVAL quantity { YEAR | QUARTER | MONTH | WEEK | DAY | HOUR | MINUTE | SECOND };
-模拟Aurora数据库集群的磁盘故障:
ALTER SYSTEM SIMULATE percentage PERCENT DISK CONGESTION BETWEEN minimum AND maximum MILLISECONDS [ IN DISK index | NODE index ] FOR INTERVAL quantity { YEAR | QUARTER | MONTH | WEEK | DAY | HOUR | MINUTE | SECOND };
无服务器应用程序世界崩溃
如果您使用无服务器组件,那么失败可能是一个真正的挑战,因为无服务器服务(例如AWS Lambda)本身并不支持故障转移。
引入Lambda失败
为了理解此问题,我编写了一个小型python库和一个lambda层 -来介绍AWS Lambda中的故障。 当前,两者都支持延迟,错误,异常以及HTTP错误代码的引入。 通过如下配置AWS SSM参数存储来实现故障:
{ "isEnabled": true, "delay": 400, "error_code": 404, "exception_msg": "I really failed seriously", "rate": 1 }
您可以在处理函数中添加python装饰器,以引入故障。
-抛出异常:
@inject_exception def handler_with_exception(event, context): return { 'statusCode': 200, 'body': 'Hello from Lambda!' } >>> handler_with_exception('foo', 'bar') Injecting exception_type <class "Exception"> with message I really failed seriously a rate of 1 corrupting now Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/.../chaos_lambda.py", line 316, in wrapper raise _exception_type(_exception_msg) Exception: I really failed seriously
-输入错误代码“无效的HTTP”:
@inject_statuscode def handler_with_statuscode(event, context): return { 'statusCode': 200, 'body': 'Hello from Lambda!' } >>> handler_with_statuscode('foo', 'bar') Injecting Error 404 at a rate of 1 corrupting now {'statusCode': 404, 'body': 'Hello from Lambda!'}
-输入延迟:
@inject_delay def handler_with_delay(event, context): return { 'statusCode': 200, 'body': 'Hello from Lambda!' } >>> handler_with_delay('foo', 'bar') Injecting 400 of delay with a rate of 1 Added 402.20ms to handler_with_delay {'statusCode': 200, 'body': 'Hello from Lambda!'}
单击此处以了解有关此python库的更多信息。
通过并发限制介绍Lambda故障
出于安全原因,默认情况下,Lambda会调整每个帐户在特定区域中所有功能的并行执行。 并行执行是指功能代码在任何单个时间点发生的多次执行。 它们用于将函数调用扩展到传入的请求。 但这可以达到相反的目的:停止执行Lambda。
❯ aws lambda put-function-concurrency --function-name <value> --reserved-concurrent-executions 0
此命令会将并行性降低为零,从而导致查询失败,并显示诸如“制动”-DTC 429类的错误。
Thundra-无服务器传输跟踪
Thundra是一种无服务器应用程序监视工具,具有将故障注入无服务器应用程序的内置功能。 他使用包装处理程序来引入故障,例如使用DynamoDB进行操作时“无错误处理程序”,数据源“无错误中和”或“输出HTTP请求中无超时”。 我自己还没有尝试过,但是在这篇有关严翠的作者的帖子中以及在Marsha Villalba的这段宏伟的视频中 ,对过程进行了很好的描述。 看起来很有希望。
在关于无服务器应用程序这一节的总结中,我将说Yan Chui在一篇关于无服务器应用程序混乱工程的困难方面的文章非常出色 。 我建议大家阅读。
4-在基础架构级别引入故障
一切始于在基础架构级别引入故障-对于Amazon和Netflix。 在基础架构级别引入故障-从断开整个数据中心的连接到随机停止实例-可能是最容易实现的。
当然,首先想到“ 混乱的猴子 ”的例子。
停止在某个可用性区域中随机选择的EC2实例。
在起步阶段,Netflix希望引入严格的架构规则。 他将“混乱的猴子”部署为安装自动缩放无状态微服务的首批AWS应用程序之一-从某种意义上说,任何实例都可以自动销毁或替换,而不会造成任何状态损失。 混沌猴子确保没有人违反这一规则。
下一个场景(类似于“混乱的猴子”)是在同一区域内的特定可用性区域中随机停止任何实例。
❯ stop_random_instance(az="eu-west-1a", tag_name="chaos", tag_value="chaos-ready", region="eu-west-1")
import boto3 import random REGION = 'eu-west-1' def stop_random_instance(az, tag_name, tag_value, region=REGION): ''' >>> stop_random_instance(az="eu-west-1a", tag_name='chaos', tag_value="chaos-ready", region='eu-west-1') ['i-0ddce3c81bc836560'] ''' ec2 = boto3.client("ec2", region_name=region) paginator = ec2.get_paginator('describe_instances') pages = paginator.paginate( Filters=[ { "Name": "availability-zone", "Values": [ az ] }, { "Name": "tag:" + tag_name, "Values": [ tag_value ] } ] ) instance_list = [] for page in pages: for reservation in page['Reservations']: for instance in reservation['Instances']: instance_list.append(instance['InstanceId']) print("Going to stop any of these instances", instance_list) selected_instance = random.choice(instance_list) print("Randomly selected", selected_instance) response = ec2.stop_instances(InstanceIds=[selected_instance]) return response
您是否tag_name tag_value和tag_value ? 这样的小事将防止错误实例的失败。 #lessonlearned

是的...重新启动数据库-做得好[糟糕,不是该实例]
5-故障介绍和多合一编排工具
您可能迷失了太多工具。 幸运的是,有很多拒绝介绍和编排工具,其中包括大多数,并且易于使用。
我最喜欢的工具之一是Chaos Toolkit ,这是一个由伟大的ChaosIQ团队提供商业支持的开源混沌工程平台。 以下是其中一些: Russ Miles , Sylvain Helleguarch和Marc Parrien 。
Chaos Toolkit定义了一个声明性和可扩展的API,可方便地进行混沌工程实验。 它包括适用于AWS,Google Cloud Engine,Microsoft Azure,Cloud Foundry,Humino,Prometheus和Gremlin的驱动程序。
扩展是用于实验的一组检查和操作,如下所示:如果tag-key包含chaos-ready值,我们将在特定的可用区域中停止随机选择的实例。
{ "version": "1.0.0", "title": "What is the impact of randomly terminating an instance in an AZ", "description": "terminating EC2 instance at random should not impact my app from running", "tags": ["ec2"], "configuration": { "aws_region": "eu-west-1" }, "steady-state-hypothesis": { "title": "more than 0 instance in region", "probes": [ { "provider": { "module": "chaosaws.ec2.probes", "type": "python", "func": "count_instances", "arguments": { "filters": [ { "Name": "availability-zone", "Values": ["eu-west-1c"] } ] } }, "type": "probe", "name": "count-instances", "tolerance": [0, 1] } ] }, "method": [ { "type": "action", "name": "stop-random-instance", "provider": { "type": "python", "module": "chaosaws.ec2.actions", "func": "stop_instance", "arguments": { "az": "eu-west-1c" }, "filters": [ { "Name": "tag-key", "Values": ["chaos-ready"] } ] }, "pauses": { "after": 60 } } ], "rollbacks": [ { "type": "action", "name": "start-all-instances", "provider": { "type": "python", "module": "chaosaws.ec2.actions", "func": "start_instances", "arguments": { "az": "eu-west-1c" }, "filters": [ { "Name": "tag-key", "Values": ["chaos-ready"] } ] } } ] }
进行上述实验很简单:
❯ chaos run experiment_aws_random_instance.json
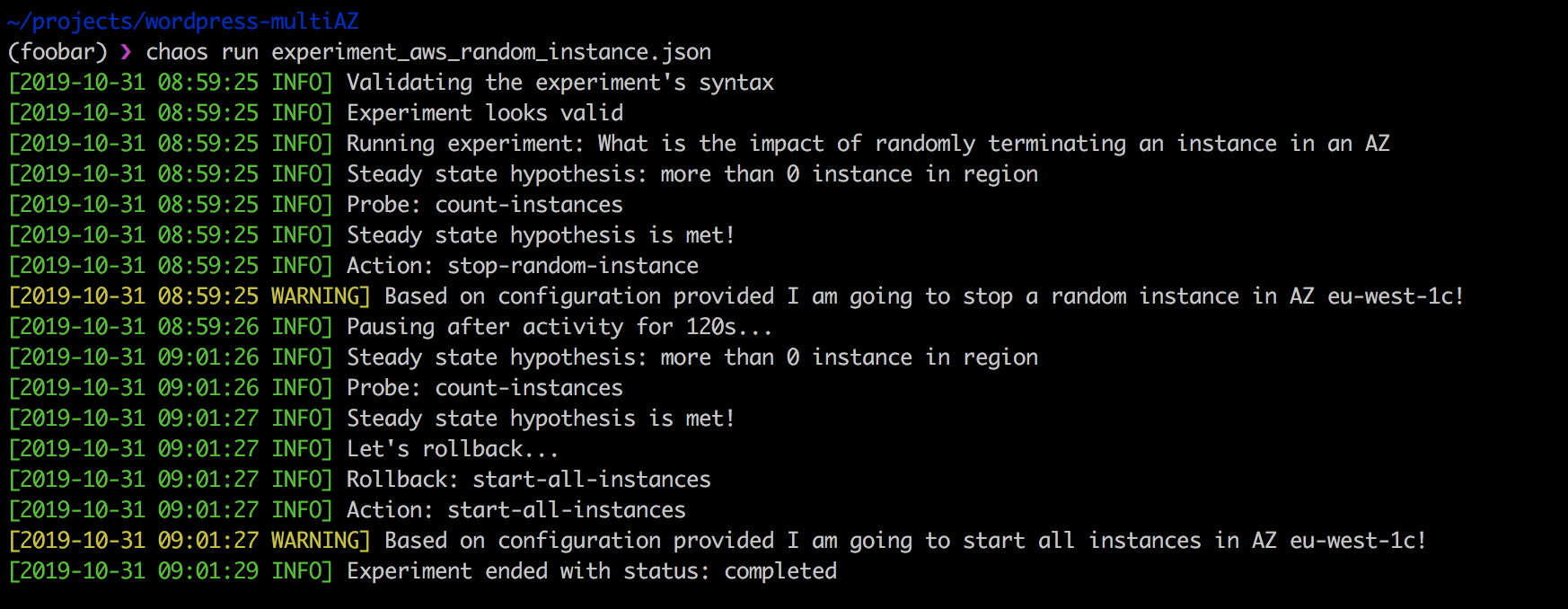
Chaos Toolkit的优势在于,首先,它是开源的,可以根据您的需求进行定制。 其次,它非常适合CI / CD管道,并支持连续的混乱测试。
Chaos Toolkit的缺点是需要花费时间来掌握它。 而且,其中没有现成的实验,因此您必须自己编写它们。 但是,我熟悉ChaosIQ的团队,该团队不懈地工作,了解此任务。
格林姆林
我的另一个最爱是Gremlin。 它包含一组全面的模式,用于在具有直观用户界面的简单工具中引入故障。 这样的混乱即服务。
Gremlin支持在资源,网络和查询级别引入故障,使您可以快速尝试整个系统,包括 硬件,各种云提供商,容器化环境(包括Kubernetes),应用程序以及某种程度上无服务器的应用程序。
再加上奖金-来自Gremlin的家伙们很棒,为博客写了很多精彩的文章 ,并随时准备提供帮助! 以下是其中一些: Matthew , Colton , Tammy , Rich , Ana和HML 。
Gremlin无处可使用:
首先进入Gremlin应用程序,然后选择“创建攻击”。
分配目标-实例。
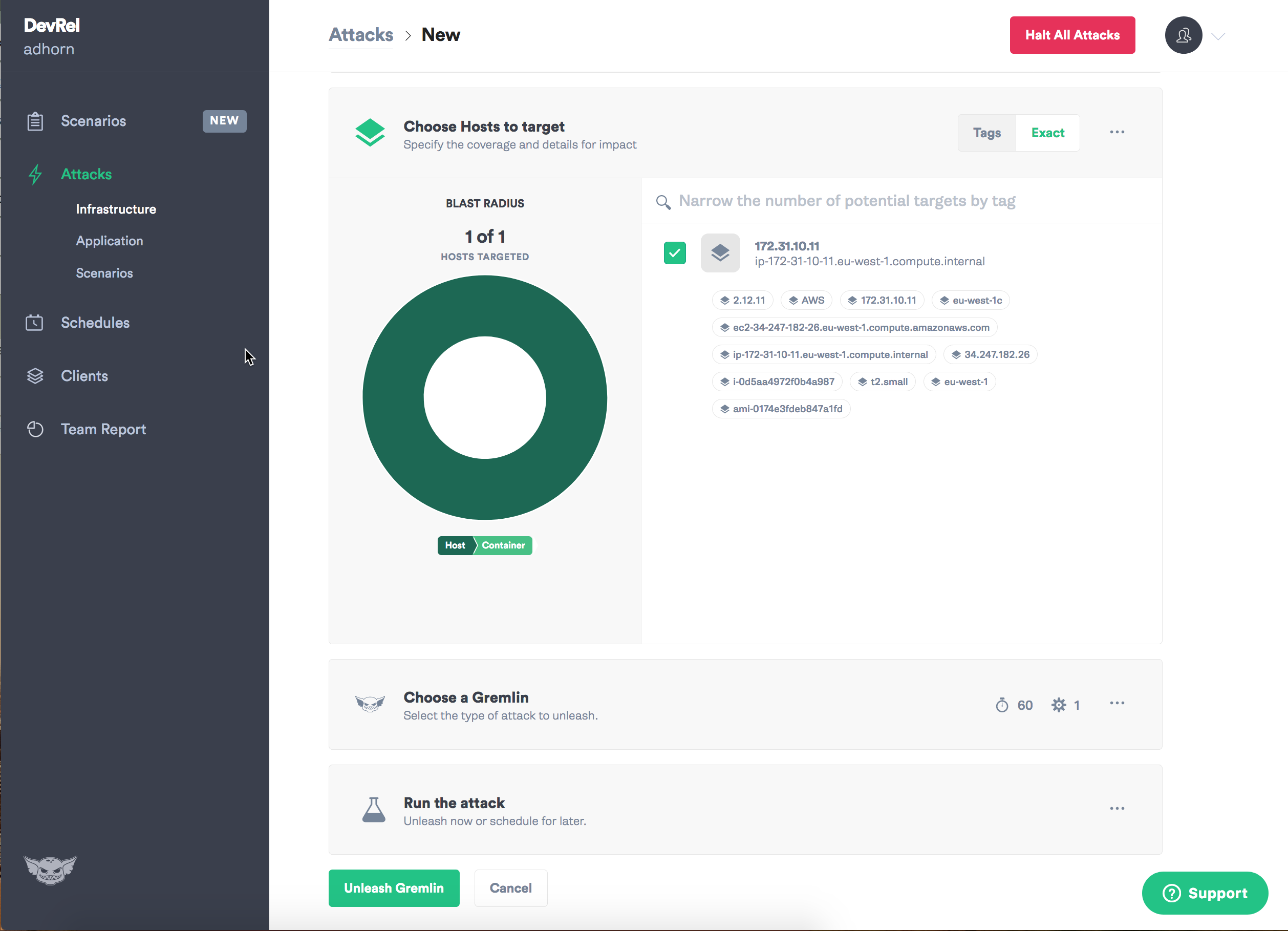
选择您要引入的故障类型,否则可能会造成混乱!
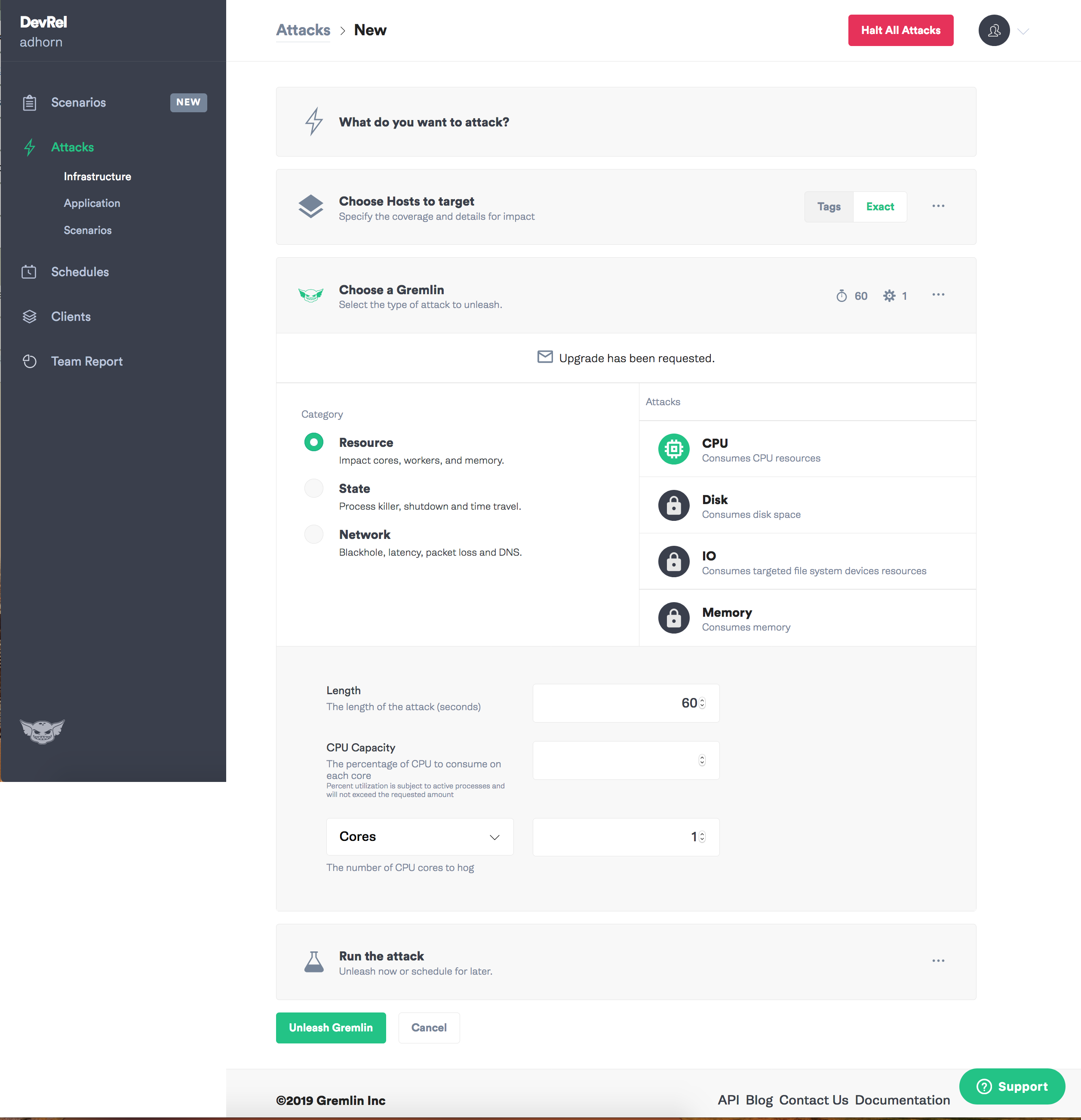
我必须承认,我一直都很喜欢Gremlin:与他一起,混沌工程的实验非常直观。
减价政策 -工作需要许可证,该许可证可能不适合新手用户或一次性工作。但是,最近添加了其免费版本。而且,Gremlin客户端和守护程序需要安装在需要受到攻击的实例中,这并不是每个人都喜欢的。
从AWS System Manager运行命令
Run command EC2 , 2015 , . — 2, . , , Systems Manager.
Run Command DevOps ad-hoc , .
, Run Command , Windows, -.
AWS System Manager . — !
!
, .
1 — - — , - . . — , — , , . , ! :
" . ".
— , - Amazon Prime Video
2 — , , . , -.
3 — , , .
4 — , , , . , - — , .
, , , . , . , , :-)
—