
那是2019年,我们仍然没有Kubernetes中用于日志聚合的标准解决方案。 在本文中,我们希望使用实际操作中的示例来分享我们的搜索,遇到的问题及其解决方案。
但是,首先,我将保留一个保留意见,即不同的客户通过收集日志来了解完全不同的事情:
- 有人想查看安全和审核日志;
- 某人-整个基础结构的集中日志记录;
- 对于某人来说,仅收集应用程序日志就足够了,例如平衡器除外。
关于我们如何实施各种“愿望清单”以及在削减计划下遇到的困难。
理论:关于日志记录工具
日志记录系统组件的背景
日志记录已经走了很长一段路,因此,我们开发了一种用于收集和分析日志的方法,如今已使用。 早在1950年代,Fortran引入了标准I / O流的类似物,可帮助程序员调试程序。 这些是第一个使当时的程序员的生活变得更轻松的计算机日志。 今天,我们在其中看到了日志记录系统的第一部分-日志的
来源或“生产者” 。
计算机科学并没有停滞不前:计算机网络出现了,第一个集群出现了……由几台计算机组成的复杂系统开始起作用。 现在,系统管理员被迫从多台计算机上收集日志,在特殊情况下,他们可以添加OS内核消息,以防有必要调查系统故障。 为了描述集中式日志收集系统,
RFC 3164于2000年代初问世,该标准对remote_syslog进行了标准化。 因此出现了另一个重要组成部分:
日志及其存储的
收集器(收集器) 。
随着日志数量的增加和Web技术的广泛采用,出现了一个问题,即应该方便地向用户显示哪些日志。 简单的控制台工具(awk / sed / grep)已被更高级的
日志查看器取代-第三部分。
与日志数量的增加有关,另一件事变得很清楚:需要日志,但不是全部。 不同的日志需要不同的安全级别:有些日志可能每隔一天丢失一次,而另一些日志则需要保存5年。 因此,用于数据流的过滤和路由组件已添加到日志记录系统中-我们称其为
filter 。
存储库也取得了重大飞跃:它们从常规文件切换到关系数据库,然后又转换到面向文档的存储库(例如,Elasticsearch)。 因此,存储与收集器分开了。
最后,日志本身的概念已扩展为我们想要保留历史的某些抽象事件流。 更确切地说,在有必要进行调查或草拟分析报告的情况下...
结果,在相对较短的时间内,日志的收集已发展成为一个重要的子系统,可以合理地将其称为大数据中的一个小节。
 如果曾经的普通印刷足以用于“记录系统”,那么现在的情况已经发生了很大变化。
如果曾经的普通印刷足以用于“记录系统”,那么现在的情况已经发生了很大变化。Kubernetes和日志
当Kubernetes进入基础架构时,他没有解决现有的收集日志问题。 从某种意义上说,这变得更加痛苦:基础架构平台的管理不仅得到简化,而且变得复杂。 许多旧服务开始迁移到微服务轨道。 就日志而言,这导致了越来越多的日志源,它们的特殊生命周期以及需要通过日志跟踪所有系统组件的互连...
展望未来,我可以说,不幸的是,现在没有用于Kubernetes的标准化日志记录选项,该选项将与其他所有人完全不同。 社区中最受欢迎的方案如下:
- 有人正在部署EFK堆栈(Elasticsearch,Fluentd,Kibana);
- 有人正在尝试最近发布的Loki或使用Logging运算符 ;
- 我们(也许不仅是我们?..)对我们自己的发展非常满意- 木屋 ...
通常,我们在K8s群集中使用以下捆绑软件(用于自托管解决方案):
但是,我不会详细说明它们的安装和配置。 相反,我将集中讨论它们的缺点,并从总体上对有关情况的更全面的结论。
在K8s中练习日志

“每天的日志”,你们几个?
具有足够大的基础结构的集中日志收集需要大量资源,这些资源将用于收集,存储和处理日志。 在各种项目的运营过程中,我们面临着各种要求以及随之而来的运营问题。
让我们尝试一下ClickHouse
让我们看一下项目中的集中式存储库,其中的应用程序会生成大量日志:每秒超过5000行。 让我们开始处理他的日志,并将其添加到ClickHouse。
只要需要最大实时性,磁盘子系统上的4核ClickHouse服务器将已经过载:

这种下载类型是由于我们试图尽快写入ClickHouse。 并且数据库对此做出了响应,增加了磁盘负载,这可能导致以下错误:
DB::Exception: Too many parts (300). Merges are processing significantly slower than inserts事实是,
ClickHouse中的MergeTree表 (它们包含日志数据)在写入操作期间有其自身的困难。 插入其中的数据将生成一个临时分区,然后将其与主表合并。 结果,对磁盘的记录要求很高,并且对其有一定的限制,我们在上面收到的通知是:1秒内不能合并300个子分区(实际上,这是每秒300个insert'ov)。
为了避免这种现象,您
应该在ClickHouse中以尽可能大的块进行
写入,并且在2秒内不要超过1次。 但是,大量编写建议我们减少在ClickHouse中编写的频率。 反过来,这可能导致缓冲区溢出和日志丢失。 解决方案是增加Fluentd缓冲区,但随后会增加内存消耗。
注意 :ClickHouse解决方案的另一个问题是,在我们的案例(日志库)中,分区是通过Merge表链接的外部表实现的。 这导致这样一个事实,即在采样较大的时间间隔时,需要过多的RAM,因为该元表会遍历所有分区-即使那些显然不包含必需数据的分区也是如此。 但是,现在可以安全地宣布这种方法对于ClickHouse的当前版本(自18.16开始 )已经过时。结果,很明显,ClickHouse没有足够的资源供每个项目实时收集日志(更确切地说,分发日志不方便)。 另外,您将需要使用
电池 ,我们将返回给
电池 。 上述情况是真实的。 那时我们还无法提供适合客户并允许以最小延迟收集日志的可靠稳定的解决方案...
那么Elasticsearch呢?
众所周知,Elasticsearch可以处理重负载。 让我们在同一项目中尝试一下。 现在的负载如下:
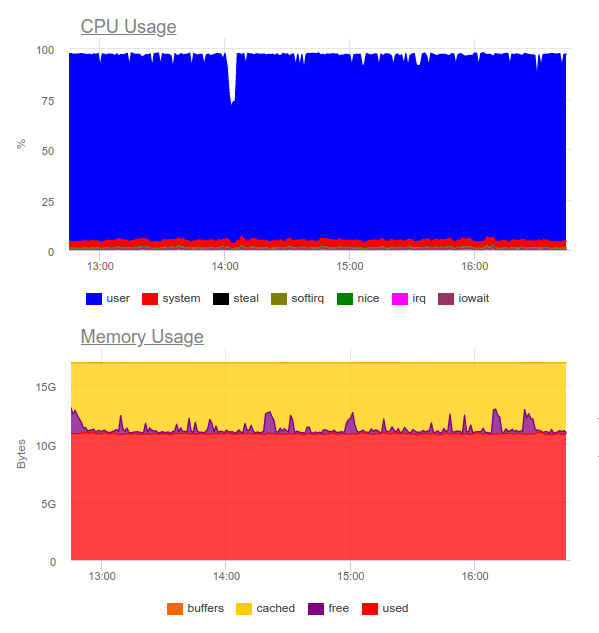
Elasticsearch能够消化数据流,但是,将这样的卷写入数据流极大地利用了CPU。 这由集群的组织决定。 纯粹从技术上讲,这不是问题,但是事实证明,仅对于日志收集系统的操作,我们已经使用了大约8个内核,并且系统中还有一个额外的高负载组件。
底线:此选项是合理的,但前提是项目规模较大且其管理已准备好在集中式日志记录系统上花费大量资源。
然后出现一个逻辑问题:
真正需要什么日志?

让我们尝试更改方法本身:日志应同时提供信息,而不是覆盖系统中的
每个事件。
假设我们有一个繁荣的在线商店。 哪些日志很重要? 例如,从支付网关收集尽可能多的信息是一个好主意。 但是从产品目录中的图像切片服务来看,并非所有日志对我们来说都是至关重要的:仅错误和高级监视就足够了(例如,此组件生成的500个错误的百分比)。
因此,我们
得出的结论是,
集中记录远非总是合理的 。 通常,客户端希望将所有日志收集在一个地方,尽管实际上,整个日志只需要5%的对业务至关重要的消息:
- 有时仅配置容器日志和错误收集器的大小就足够了(例如Sentry)。
- 要调查事件,错误警报和大量本地日志本身通常就足够了。
- 我们的项目完全只花费功能测试和错误收集系统。 开发人员不需要这样的日志-他们看到了错误跟踪中的所有内容。
生活图
一个很好的例子是另一个故事。 我们收到了其中一个客户的安全团队的要求,该客户已经拥有在Kubernetes实施之前开发的商业解决方案。
它需要“结交朋友”一个带有公司传感器以检测问题的集中式日志收集系统-QRadar。 该系统能够使用syslog协议接收日志,以从FTP获取日志。 但是,将其与fluentd的remote_syslog插件集成并不能立即生效
(事实证明, 我们并不是唯一的 ) 。 配置QRadar的问题在于客户的安全团队。
结果,对业务至关重要的日志的一部分已上载到FTP QRadar,另一部分通过远程syslog直接从节点重定向。 为此,我们甚至编写了一个
简单的图表 -也许可以帮助某人解决类似的问题...由于采用了这种方案,客户自己(使用他最喜欢的工具)接收并分析了关键日志,因此我们能够减少日志系统的成本,仅保留最后一个一个月。
另一个例子很好地说明了如何不这样做。 我们的一位处理用户事件的客户将多行
非结构化信息
输出到日志。 您可能会猜到,这样的日志非常不便阅读和存储。
日志标准
这些示例得出的结论是,除了选择收集日志的系统之外,还必须
自己设计日志 ! 这里有什么要求?
- 日志必须采用机器可读的格式(例如JSON)。
- 日志应紧凑,并具有更改日志记录程度的能力,以便调试可能的问题。 同时,在生产环境中,您应该以警告或错误等日志记录级别运行系统。
- 日志必须规范化,也就是说,在日志对象中,所有行都必须具有相同的字段类型。
非结构化日志可能导致将日志加载到存储库中并完全停止对其进行处理的问题。 为了说明这一点,下面是一个错误为400的示例,在流畅的日志中肯定会遇到许多错误:
2019-10-29 13:10:43 +0000 [warn]: dump an error event: error_class=Fluent::Plugin::ElasticsearchErrorHandler::ElasticsearchError error="400 - Rejected by Elasticsearch"错误表示您正在使用准备就绪的映射向索引发送类型不稳定的字段。 最简单的示例是nginx日志中的变量
$upstream_status的字段。 它可以有数字或字符串。 例如:
{ "ip": "1.2.3.4", "http_user": "-", "request_id": "17ee8a579e833b5ab9843a0aca10b941", "time": "29/Oct/2019:16:18:57 +0300", "method": "GET", "uri": "/staffs/265.png", "protocol": "HTTP/1.1", "status": "200", "body_size": "906", "referrer": "https://example.com/staff", "user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36", "request_time": "0.001", "cache_status": "-", "upstream_response_time": "0.001, 0.007", "upstream_addr": "127.0.0.1:9000", "upstream_status": "200", "upstream_response_length": "906", "location": "staff"}
{ "ip": "1.2.3.4", "http_user": "-", "request_id": "47fe42807f2a7d8d5467511d7d553a1b", "time": "29/Oct/2019:16:18:57 +0300", "method": "GET", "uri": "/staff", "protocol": "HTTP/1.1", "status": "200", "body_size": "2984", "referrer": "-", "user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36", "request_time": "0.010", "cache_status": "-", "upstream_response_time": "0.001, 0.007", "upstream_addr": "10.100.0.10:9000, 10.100.0.11:9000", "upstream_status": "404, 200", "upstream_response_length": "0, 2984", "location": "staff"}日志显示服务器10.100.0.10响应第404错误,并且请求转到了另一个内容存储。 结果,日志中的值变成了这样:
"upstream_response_time": "0.001, 0.007"这种情况非常普遍,甚至
在文档中也有
提及 。
那么可靠性呢?
有时所有日志都是至关重要的,无一例外。 因此,上面提出/讨论的K8的典型日志收集方案存在问题。
例如,fluentd无法从短命容器中收集日志。 在我们的一个项目中,具有数据库迁移功能的容器存活了不到4秒钟,然后根据相应的注释被删除:
"helm.sh/hook-delete-policy": hook-succeeded因此,迁移日志未进入存储库。 在这种情况下,
before-hook-creation策略可以提供帮助。
另一个示例是Docker日志的轮换。 假设有一个应用程序主动写入日志。 在正常情况下,我们设法处理所有日志,但是一旦出现问题(例如,如上所述,格式错误),处理就会停止,并且Docker会旋转文件。 底线-关键业务日志可能会丢失。
这就是
分离日志流 ,将最有价值
的日志的发送直接嵌入到应用程序中以确保其安全性的
重要性 。 此外,创建一种
日志的
“累加器”在保留短暂的消息不可用的同时仍能保留重要消息的情况下,并不是多余的。
最后,不要忘记
以质量方式监视任何子系统很重要 。 否则,很容易遇到这样的情况:流利的处于
CrashLoopBackOff状态,并且不发送任何东西,这将导致重要信息的丢失。
结论
在本文中,我们不考虑像Datadog这样的SaaS解决方案。 专门收集日志的商业公司已经以一种或另一种方式解决了此处描述的许多问题,但是由于各种原因,并不是每个人都可以使用SaaS
(主要原因是成本和符合152-) 。
最初,集中式收集日志看起来很简单,但根本不是。 重要的是要记住:
- 详细记录只是关键组件,对于其他系统,您可以配置监视和错误收集。
- 应尽量减少生产中的原木,以免增加负荷。
- 日志必须是机器可读的,规范化的,并且格式严格。
- 真正重要的日志应在单独的流中发送,该流应与主要日志分开。
- 值得考虑的是原木电池,它可以避免突发高负载,并使存储设备上的负载更均匀。

这些简单的规则(如果应用到所有地方)将允许上述电路工作-即使它们缺少重要的组件(电池)。 如果您不遵守这些原则,则该任务将很容易将您和基础架构引导至系统的另一个负载很高(同时无效)的组件。
聚苯乙烯
另请参阅我们的博客: