
在2016年6月9日至10日于喀山(Kazan)在Innopolis举行的系统和工具软件开发人员会议-OS DAY 2016上,讨论了关于多细胞架构的报告时,他表示这将是解决人工智能问题最有效的想法。 今年已经开发出了新的专注于AI任务的通用处理器的条件。
神经处理器S2 Multiclet是多单元架构的进一步发展,该项目首次在2019年华为创新论坛上提出。 它不同于先前使用命令系统创建的多单元,即引入新型的小型数据(具有定点和浮点)并对其进行操作。 单元数量增加了-256个,频率增加了-2.5 GHz,在16F时应提供81.9 TFlops的峰值性能,因此,就神经计算而言,它可以与现代专用ASIC TPU(TPU-3:90 TFlops)相提并论。 16F)。
由于使用处理器的效率在很大程度上取决于编译器的最优性,因此已经开发了开发的代码优化方案。
让我们更详细地考虑它。
上一篇文章提到了值得实现的编译器优化。 如果您还不熟悉多细胞架构,则可以在那里找到材料。
生成带有两个常量的两个参数的命令
处理器S1引入了新的指令格式,允许将两个参数都指定为常数。 这使您可以减少代码中的命令数量,摆脱不必要的命令,例如将常数加载到开关中。
例如:
load_l func wr_l @1, #SP
可以替换为:
wr_l func, #SP
甚至一次两个团队:
load_l [foo] load_l [bar] add_l @1, @2
有两个常量地址,从它们中读取也可以直接替换为命令的参数:
add_l [foo], [bar]
此优化是为支持此格式的每个人实施的。 不幸的是,事实证明它是无效的,原因有两个:
- 可以进行这种优化的情况数量很少。 在仲裁代码中,当您需要以某种方式处理预先已知的两个值时,很少出现这种情况。 通常,这些事情是在编译阶段决定的,在运行时只需要做一些工作。 通常,这些是对地址的一些操作,同样,它也是常量。
- 删除加载命令不会使处理器从生成常数的过程中解放出来,而只能从获取单独的加载命令中释放,这只会产生微弱的加速度,甚至不能总是如此。
优化基本单元之间虚拟寄存器的传输
在LLVM中,基本块是线性部分,在其中执行代码而不会分支。 多单元体系结构中的段落执行完全相同的功能,因此,大多数情况下,在生成代码时,一个段落反映了一个基本块。 在处理器R1中,通过将所需寄存器的值写入堆栈并将其读回到需要此寄存器的段中,可以通过内存执行段之间虚拟寄存器的任何传输。 该机制分为两部分:将虚拟寄存器传输到另一段以直接使用,以及将虚拟寄存器作为phi节点的参数进行传输。
Phi节点是表示LLVM表示语言的
SSA(静态单一分配)形式的结果。 以这种形式,一个变量(或者,就LLVM IR而言,就是虚拟寄存器)只能被写入一次。 例如,此伪代码:
a = 1; if (v < 10) a = 2; else a = 3; b = a;
不会以SSA形式显示,因为变量
a的值可以被覆盖。 如果使用phi节点,则可以用以下形式重写代码:
a1 = 1; if (v < 10) a2 = 2; else a3 = 3; b = phi(a2, a3);
phi节点选择a2或a3,具体取决于控制流的来源:
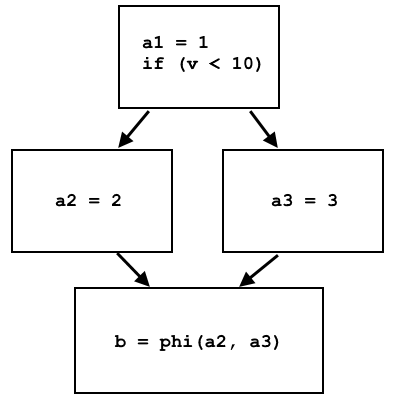
在LLVM IR phi中,节点被实现为单独的指令,该指令根据控件来自哪个基本单元来选择不同的虚拟寄存器。 该指令通过存储器在处理器上的实现非常简单:不同的基本块将不同的数据写入同一存储单元,并且在站点phi节点处读取此存储单元,并且数据将取决于先前的基本块。
SSA形式表示初始化寄存器时,该值始终是相同的。 当执行虚拟寄存器的直接传输时,将每个虚拟寄存器的值写入其自己的单独存储单元时,SSA条件将毫无问题地得到满足:数据一直在内存中,直到被覆盖为止。 但是,如果要通过开关传输寄存器,则必须记住:它的大小只有63个单元,当执行任何63条命令时,任何值都会消失。 因此,如果虚拟寄存器写在第一段中,并在其他数百段完成后使用,则无法通过开关进行传输; 只保留内存。
该优化的实现正是从phi节点的优化开始的,因为与直接传输虚拟寄存器不同,phi节点的参数值总是直接在前面的段落(基础块)中初始化,这使您不必过多考虑开关是否足够大如果我们想通过这些参数。
多单元汇编程序允许您为命令结果分配名称,并通过该名称使用它们的结果。 汇编程序不需要自己计算每个命令返回的结果数量,而是由汇编程序自己计算:
result := add_l [A], [B] ; ; ; wr_l @result, C
该机制在当前段落中完美运行,因为它是一个线性部分,并且在那里知道命令的顺序。 在编译器生成代码时会积极使用此方法:为所有命令分配了名称,并且编译器无需担心对命令进行编号。 更确切地说,这是没有必要的,因为如果我们想获得在另一段中执行的命令的结果,则该机制将无法正常工作:在汇编阶段,如果当前段中有多个输入,则不可能找出上一段实际执行了哪个段。 因此,唯一的选择是通过数字访问团队的结果。 因此,您不能只从相邻段落中的内存中抛出多余的记录/读数,而不能将read命令中的寄存器引用替换为上一段中的命令。
这里值得关注一个非常重要的结果:如果一个段落有多个输入,则本节第一个命令中的
@ 1可以指代完全不同的结果,具体取决于前一个段落。 披结就是这样的情况。 以前,在初始化phi节点的所有基本块中,数据都写入了相同的存储单元,并且代替phi节点,对该单元进行了读取。 因此,在前面的段落中,此单元格中有记录的位置绝对不重要,就像读取该单元格的位置一样。 如果您摆脱了内存的使用-它会改变。
为了允许phi主机使用开关而不是内存,请执行以下操作:
- 对当前基本单元中的所有phi节点进行计数(可能有几个),并用序列号标记并按此顺序排列
- 对于每个phi节点,将绕过对其进行初始化的基本块;将这些值加载到开关( loadu_q )中的命令(由相应phi节点的序列号标记)
- 节点本身的phi指令也被其序列号的loadu_q代替
- 所有添加的命令均以给定顺序重新排列
由于已经指出的原因,第四点是必要的:如果我们希望
loadu_q @ 3命令专门为其phi节点访问结果,那么将数据加载到交换机的命令的所有初始化段都应该完全相同。 让我们给出一个实际的编译代码结果示例,其中一个基本单元中有两个phi节点。
带有初始化器phi节点的段落:
LBB1_27: LBB1_30: SR4 := loadu_q @1 setjf_l @0, LBB1_31 setjf_l @0, LBB1_31 SR4 := loadu_q [#SP + 8] SR5 := loadu_q [#SP + 16] SR5 := loadu_q [#SP] SR6 := loadu_l 0x1 SR6 := add_l @SR4, 0xffffffff SR7 := add_l @SR6, [@SR4] loadu_q @SR5 wr_l @SR7, @SR4 loadu_q @SR6 loadu_q @SR6 complete loadu_q @SR5 complete
有两个phi节点的段落:
LBB1_31: SR4 := loadu_q @2 SR5 := loadu_q @2 SR6 := loadu_l [#SP + 124] SR7 := loadu_l [#SP + 120] setjf_l @0, @SR7 setrg_q #RETV, @SR4 wr_l @SR5, @SR6 setrg_q #SP, #SP + 120 complete
以前,不是
loadu_q命令,而是要写入内存并从中读取数据。
在实施此优化的过程中,还存在一些事先未预见到的问题:
- 现有的一些代码优化将命令重新安排在适当的位置,例如,将下一个段落的地址放在当前段落的开始处,或者将存储读/写命令的位置分别放置在该段落的开始/结尾。 这些优化是在使用phi节点进行操作之后发生的(所谓的在处理器指令之前降低LLVM指令),因此它们通常会破坏loadu_q命令的构建顺序。 为了不中断这些优化的工作,我必须创建一个单独的LLVM通道,该通道在使用命令进行所有其他操作之后,以正确的顺序排列phi节点的命令。
- 事实证明,可能出现一种情况,其中一个基本单元为两个不同的基本单元初始化phi节点。 即,按照指示的算法,将这些基本块添加到每个phi节点的loadu_q初始化命令中。 在这种情况下,即使它们只有一个phi节点,在初始化部分中也会有2个loadu_q命令 ,从逻辑上讲 ,这两个命令都应该放在最后一个位置,这当然是不可能的。 幸运的是,这种情况很少见,因此,如果有这样一个基本单元,其中phi节点被初始化为一个以上的其他基本单元,则只有第一个根据算法使用该开关,其余的-像以前一样,通过内存。
可以对phi节点的所有这些优化进行补充。 例如,如果您查看上面的
LBB1_30段,您会看到
loadu_q命令加载了其他地方未使用的值。 也就是说,如果删除
loadu_q并以相同顺序设置创建这些值的命令,则
下一节中的loadu_q @ 2命令也将加载正确的值。
基准测试
当前的优化结果已经在CoreMark和WhetStone基准测试中进行了测试,其描述可以在
上一篇文章中找到。 让我们先将S2内核上的CoreMark结果与旧结果(S1内核上的编译器的早期版本)进行比较。
相对CoreMark / MHz值显示在直方图中:

要仅通过优化phi节点来获得加速度的估计值,可以在1600 MHz频率下重新计算S1和S2内核上一个多单元的CoreMark指示器:它们分别为1147和1224,这意味着增加了6.7%。
使用WhetStone,情况有所不同。 内核的变化会影响结果,此外,该基准测试在一个内核(多单元)上运行,并以兆赫兹为单位进行计算,因此处理器频率没有任何作用。
磨刀石记分卡:
现在很明显,即使在S1内核上使用早期版本的编译器时,总体索引也更高,这主要是由于MFLOPS1-3浮点测试所致。 在测试过程中注意到了这一缺陷,这是由于与S1相比,S2中的浮点块的内部传送带多了一个步骤。 结果,连续的数据相关命令链在每个命令上丢失了一个度量。 之所以需要执行此步骤,是因为时钟周期的持续时间减少了(处理器频率从1.6 GHz增加到2.5 GHz,并且命令的名称增加了,例如乘法命令的出现以及MAC的累积)。 这个决定是暂时的。 缩短管线长度的工作正在进行中,将来会得到修复,但是对当前版本的S2进行了测试。
为了评估编译器优化的加速性,WhetStone还在旧版本上进行了编译,并在S2的当前版本上启动。 总指标为0.3068 MWIPS / MHz,而新编译器为0.3267 MWIPS / MHz。 由于上述优化,显示出6.5%的加速度。
经过开发和测试的优化系统可以使您将来实现下一个优化方案,即通过交换机直接传输虚拟寄存器。 如前所述,并非虚拟寄存器的每个副本都可以通过切换来完成。 由于开关的大小有限,并且如果当前条目有多个入口点,则无法正确访问前几段的结果(这由phi节点部分解决),唯一可能的选择是将虚拟寄存器从一个段直接复制到下一个段,但是前一个只有一个。 实际上,这样的情况并不多,尽管通常会事先说出多少代码加速是很困难的,但通常经常需要如此直接地传输数据。