Python可以理解所有流行的文件格式。 此外,每个库都有自己的“热管”格式。 当然,每种格式的语法都是完全独立的。 我将所有用于处理不同格式文件的功能汇总在一张A4纸上,并以该应用程序为示例在jupyter笔记本中使用。
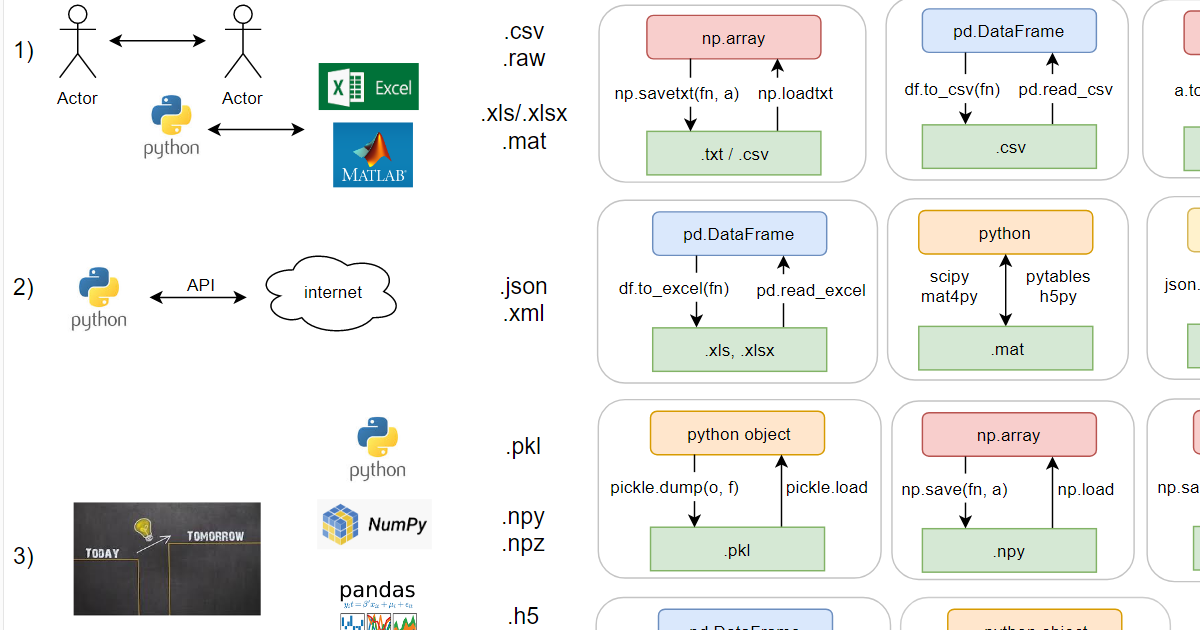
我根据使用方法有条件地将格式分为三个块。 如您所知,在人与人之间,程序之间(第一个程序段),计算机与网络之间(第二个程序)和“保存游戏”-在同一程序之间的不同时间点(第三步)之间交换文件是必需的。
简要介绍每个块:
1)通用格式:
- .csv-文本,原则上用逗号分隔的值,但是,例如,俄文exel更喜欢用分号分隔,因为逗号在俄文语言环境中已经用作小数点分隔符;
- .raw是不喜欢文件格式的人的二进制格式。 数据类型以及(如果数据是多维的)相应大小应分别传送,文件中的数据本身;
- .xls / .xlsx-旧的二进制文件(限制为65k行)和新的xml exel格式;
- .mat实际上也是两种格式(均为二进制):旧的专有格式和基于hdf5的新格式。 Python可以同时使用两者(通过库)。
2)“网络”格式:
- .json-文本,看起来像python中的字典,但是引号只能使用双引号;
- .xml-文本,类似于html。
3)原生python格式:
- .pkl是二进制格式,所有内置的Python对象都可以保存到其中。 自定义类也可以,如果python保存了错误的内容,则可以通过魔术方法来帮助它。 支持追加到现有文件的末尾。
- .npy和.npz-在numpy中,最多有两种格式(均为二进制)。 它们是对python v2-> v3过渡时pkl中向后兼容性丧失的一种反应。 开销是最小的(比相应的原始字节多100个字节;但是pkl稍大:比原始字节多150个字节)。 在.npy中,您只能保存一个数组,在npz中-一次保存多个数组,随后您可以按名称将它们保存在那里。
- .h5-二进制hdf5格式。 值得注意的是,您可以在其中存储整个分层数据结构,它几乎是一个文件中的一个文件系统。 另外,它可以在matlab中打开而无需转换。 缺点:
a)小文件占用了不合理的大空间(例如300字节pkl与h5的3.1兆字节),
b)很多错误 ,
c)在现有文件上追加了一个文件,但是如果发生错误(发生错误),则从该文件获取数据将是有问题的。
简而言之, 这里是对hdf5优缺点的详细分析-一种用作交换数据的好格式,对于一种用作文件系统的格式则很不利-例如,您不能擦除数组,只复制没有数组的文件即可。 - .parquet是大数据的二进制格式。 Apache Parquet不是本机Python格式,但已很好地集成到了熊猫中。 您可以即时压缩/扩展(rle,gzip,字典编码); 压缩比Apache Avro略好。 与avro不同,在avro中,数据是逐行存储的(例如C顺序),在拼花地板中,数据是逐列存储的(例如fortran顺序)。 因此,您可以有效地处理具有大量列的表。
- jupyter决定不重新设计wheel-%存储将其保存为.pkl格式,但是由于某种原因而没有扩展名。
速查表本身:
-pdf格式
-png格式:

使用图表中所有功能的示例:
带有目录和ipynb源的html