自然语言处理可以追溯到卡巴拉的神秘主义者
在自然语言处理成为人工智能领域的热门话题很久之前,人们就想出了处理语言的规则和机器。
 13世纪的神秘主义者亚伯拉罕·本·塞缪尔·阿布拉菲亚(Abraham bin Samuel Abulafia)通过开始组合字母的实践,发明了自然语言处理领域
13世纪的神秘主义者亚伯拉罕·本·塞缪尔·阿布拉菲亚(Abraham bin Samuel Abulafia)通过开始组合字母的实践,发明了自然语言处理领域现在,我们对自然语言处理(NLP)的兴趣达到了顶峰-自然语言处理(NLP)是一门计算机科学领域,专注于人与机器的语言交互。 得益于过去十年中机器学习(MO)的突破,我们看到了语音识别和机器翻译方面的重大进步。 语言生成器已经足够好来编写连贯的新闻文章,并且Siri和Alexa等虚拟助手已成为我们日常生活的一部分。
大多数历史学家将这一领域的起源追溯到计算机时代的开始,1950年,艾伦·图灵(Alan Turing)描述了一种智能机器,该机器可以通过屏幕上的文本轻松地与人互动。 因此,机器生成的语言通常被视为一种数字现象-也是开发人工智能(AI)的主要目标。
在本文中,我们将试图驳斥这种普遍接受的NLP概念。 实际上,几百年前就开始尝试开发能够分析,处理和创建语言的形式规则和机器。
特定的技术随着时间的推移而发生了变化,但是出于多种原因,许多人在多种语言中都探索了将语言视为可以基于规则系统进行人为操纵的材料的主要思想。 这些历史性实验显示了在没有人为干预的情况下尝试模拟人类语言的可能性和危险-并为当今的高级NLP技术从业者提供了经验教训。
这个故事起源于中世纪的西班牙。 在13世纪末,一个名叫
亚伯拉罕·本·塞缪尔·阿布拉法西亚 (
Abraham bin Samuel Abulafia)的犹太神秘主义者坐在巴塞罗那他家的一张桌子上,拿了一支笔,蘸了墨水,开始以奇怪的,乍一看是随机的方式组合
希伯来字母 。 Alef与下注,gimel与下注,gimel与alef与下注等。
Abulafia将此做法称为“结合字母的科学”。 实际上,他不是随机地组合字母; 在研究古老的
卡巴拉教教科书《
塞弗·雪兹拉 》时,他认真地遵循了自己制定的一套秘密规则。 这本书描述了上帝是如何按照神圣的公式结合希伯来字母来创造“具有形式和说的一切”的。 在一节中,上帝会仔细检查22个字母的所有可能的两个字母的组合。
通过研究Sefer Yetzirah,Abulafia提出了一个想法,即可以根据正式规则来操纵语言符号,以创建新颖,有趣,充满思想的句子。 为此,他花费了几个月的时间,创造了数千种希伯来字母的组合,共22个字母,结果写了几本书,他声称这些书具有预言性的智慧。
对于Abulafia而言,按照神圣的规则产生的语言给人以神圣与未知的想法,或者如他所写的那样,让他“按照人类传统理解的东西,或者只有一个人不知道的东西”。
然而,其他犹太学者认为这一代基本语言是一种危险的行为,接近亵渎。 在
塔木德(Talmud),讲述了有关拉比的故事,拉比根据“ Sepher Yetzirah”中描述的公式神奇地改变了语言,创造了人造动物
go 。 在这些故事中,拉比们使用神圣的公式赋予希伯来语字母以重现神圣的创造行为,赋予无生命的物体。
在某些神话中,拉比将这项技能用于实际目的,在他们想吃的时候创造食物来食用动物,或者仆人帮忙做家务。 但是,这些魔像故事中的许多故事结局很差。 在其中一个著名的童话故事中,
耶胡达·利瓦·本·贝扎勒 (
Yehuda Liva bin Betzalel ,从布拉格被称为
马哈拉尔 (
Maharal ))是16世纪居住在布拉格的一名拉比,他采用了神圣的做法,将字母组合起来称为魔像,以保护犹太人社区免受反犹太人的袭击,但最终,这一魔像遭到了反对它的创造者。
这种“组合字母的科学”是自然语言处理的基本形式,因为它包括根据特殊规则组合希伯来字母的字母。 对于卡巴拉主义者来说,这是一把双刃剑:既是获得新形式知识和智慧的方式,又是一种危险的做法,可能导致意想不到的严重后果。
这种紧张关系在语言处理的悠久历史中一直持续存在,并且仍然回应了有关我们数字时代最先进的NLP技术的讨论。
在17世纪,莱布尼兹(Leibniz)梦想着一种能够计数思想的机器。
该机器应该使用“人类思想的字母”及其组合规则
 戈特弗里德·威廉·莱布尼兹(Gottfried Wilhelm Leibniz)以其论文“论组合艺术”为背景
戈特弗里德·威廉·莱布尼兹(Gottfried Wilhelm Leibniz)以其论文“论组合艺术”为背景1666年,德国学者
Gottfried Wilhelm Leibniz发表了一篇名为“
论组合艺术 ”的神秘论文。 莱布尼兹(Leibniz)只有20岁,但已经进行了广泛的思考,他描述了根据根据某些规则创建的字符组合自动生成知识的理论。
莱布尼兹的主要论点是,所有人类思想,无论其复杂性如何,都是基本概念和基本概念的组合,就像句子是单词的组合,而单词是字母的组合一样。 他相信,如果他能够找到一种方法来象征性地代表这些基本概念,并开发出一种方法,可以将它们在逻辑上加以结合,那么他将能够根据需要创造出新的思想。
在研究13岁的马洛卡神秘主义者
Raimund Lullius的作品时,莱布尼兹想出了这个主意。他居住在13世纪,他一生致力于建立一个神学推理体系,可以向所有非信徒证明基督教的“普遍真理”。
卢利乌斯本人受到了犹太卡巴拉主义者的信件组合的启发,他们曾用这些信件创作了一些文字,据说这些文字揭示了先知的智慧。 进一步发展了这个想法,卢利乌斯发明了他所谓的“
沃尔韦尔 ”(
Volwell),这是一种圆形纸机制,其逐渐减少了同心圆,并在其上书写了代表上帝属性的符号。 卢利乌斯(Lullius)相信,通过以各种方式旋转沃尔沃(Volwell),以及通过相互生成符号的新组合,他可以发现神灵的各个方面。
莱布尼兹对Lullia的造纸机印象深刻,并着手创造自己的通过符号组合产生想法的方法。 但他不想将汽车用于神学辩论,而是出于哲学目的。 他建议这样一个系统将需要三件事:“人类思想的字母”; 有效组合的逻辑规则列表; 以及能够快速,准确地对这些符号执行逻辑运算的机制-Lullia纸小提琴的完全机械更新。
他以为这台机器被他称为“推理的绝佳工具”,将能够回答所有问题并解决任何智力争议。 他写道:“当人与人之间发生争执时,我们可以简单地说,“让我们计算一下,”然后立即看看谁是对的。”
发出理性思想的机制的思想与莱布尼兹的时代精神相对应。
启蒙运动的其他思想家,例如雷内·笛卡尔(Rene Descartes),都相信“普遍真理”的存在可以通过仅使用逻辑推理来挖掘,并且所有现象都可以得到充分解释,并理解其背后的原理。 莱布尼兹认为语言和意识本身也是如此。
但是许多其他人认为这种纯粹理性的学说是严重错误的,并认为这是新的讲道时代的标志。 其中一位评论家是作家兼讽刺作家乔纳森·斯威夫特(Jonathan Swift),他在1726年出版的《格列佛游记》(Gulliver’s Travels)中浏览了莱布尼兹(Leibniz)的计数机。 在一个场景中,格列佛最终来到了拉加多大学院,在那里他遇到了一种奇怪的机制,叫做“机器”。 这台机器有一个大的木制骨架,上面有拉长的电缆格子。 电缆上是小的木制立方体,在每侧都有符号。
学院的学生扭动机器侧面的手柄,这使木块旋转并产生新的字符组合。 然后抄写员写下机器给出的内容,然后交给主持人教授。 这位教授声称,通过这种方式,他和他的学生可以“写哲学,诗歌,政治,法律,数学和神学的书,而无需任何才能或训练。”
数字时代之前的这种语言产生场景是斯威夫特通过符号的组合来模仿莱布尼兹的思想产生-更普遍的是反对科学优越性的论点。 就像拉加多学院通过研究提高其人民发展水平的其他尝试一样(例如尝试将人类排泄物重新转化为食物),该机器似乎对格列佛进行了毫无意义的实验。
斯威夫特想说,语言不是莱布尼兹认为的代表人类思想的形式系统,而是一种混乱而a昧的表达形式,仅在使用语言时才有意义。 斯威夫特认为,语言生成不仅需要一套规则和一台合适的机器,而且还需要理解单词含义的能力,而拉加多机器和莱布尼兹的“推理工具”都无法做到。
结果,莱布尼兹(Leibniz)从来没有制造过自己的汽车来产生想法。 他完全放弃了对Lullius组合语言的研究,后来意识到将语言机械化为不成熟的尝试。 但是,他并没有放弃使用机械设备执行逻辑功能的想法,而是激发了他创建一个“
逐步计算器 ”,一种建于1673年的机械计算器。
但是,今天正在为NLP开发越来越高级的算法的计算机科学家之间的辩论反映了莱布尼兹和斯威夫特的想法:即使有可能创建一个能够产生类似于人类的语言的正式系统,它也可以被赋予理解其产生能力的能力吗?
安德烈·马可夫(Andrei Markov)和克劳德·香农(Claude Shannon)数了数字母,以建立第一代语言生成模型
香农的模型说:“ OCRO HLI RGWR NMIELWIS”
 俄国数学家安德烈·安德烈耶维奇·马尔科夫(Andrei Andreevich Markov)在对亚历山大·谢尔盖耶维奇·普希金(Eugene Onegin)的诗歌进行统计分析的背景下
俄国数学家安德烈·安德烈耶维奇·马尔科夫(Andrei Andreevich Markov)在对亚历山大·谢尔盖耶维奇·普希金(Eugene Onegin)的诗歌进行统计分析的背景下1913年,俄国数学家
安德烈·安德烈耶维奇·马尔科夫(Andrei Andreevich Markov)坐在圣彼得堡的办公室里,抄写了普希金(A. S. Pushkin)的《尤金·奥涅金》(Eugene Onegin)19世纪的诗作,那是前文学经典。 但是,马可夫没有读普希金的著名著作。 取而代之的是,他拿笔和画纸,用一长串字母写了本书的前20,000个字母,并省略了所有空格和标点符号。 然后,他将这些字母重新排列成200个格子(每个字母10x10个字符),并开始对每一行和每一列中的元音进行计数,并记录结果。
在外部观察者看来,马尔可夫的举止似乎很奇怪。 为什么有人会以这种方式拆解文学天才的作品,将其变成难以理解的东西? 但是马尔科夫没有读这本书是为了更多地了解人与自然的本质。 他在课文中寻找基本的数学结构。
从元音中分离元音,马尔科夫检查了他自1909年以来提出的概率论。在此之前,概率论主要限于对轮盘或掷硬币等现象的分析,而先前事件的结果并不影响当前事件的概率。 但是马尔可夫认为,大多数现象都是沿着因果关系发生的,并取决于先前的结果。 他想找到一种通过概率分析为这些事件建模的方法。
马尔科夫认为语言是一个系统的例子,以前的事件部分决定了当前的事件。 为了证明这一点,他想证明在文本中,例如在普希金的诗中,某个字母出现在文本中某个位置的概率在某种程度上取决于它之前的字母。
为此,马尔可夫开始在尤金·奥涅金(Eugene Onegin)中计算元音,发现其中43%的字母是元音,而57%是辅音。 然后,马尔可夫将20,000个字母分成元音和辅音组合。 他发现了1104对两个元音,3827对辅音和15069对元音或辅音对。 从统计的角度来看,这意味着对于普希金的任何文字,该规则都得到了满足:如果是元音,则很可能辅音会在其后方出现,反之亦然。
马尔可夫(Markov)利用这一分析表明,普希金(Pushkin)的“尤金·奥涅金(Eugene Onegin)”不仅是字母的随机分布,而且具有可以建模的某些统计质量。 完成这项研究的神秘
研究工作的标题是“尤金·奥金(Eugene Onegin)文本统计研究的一个例子,说明了试验链中的联系”。 她在马尔可夫一生中很少被引用,直到2006年才翻译成英语。 然而,它与概率和语言有关的一些基本概念已遍及世界各地,因此在
克劳德·香农(Claude Shannon)于1948年出版
的极具影响力的著作“
通信的
数学理论 ”中得到了重述。
Shannon的工作描述了一种准确测量消息中信息定量内容的方法,从而奠定了信息理论的基础,该理论随后定义了数字时代。 香农对马可夫的想法感到高兴,因为他可以在给定的文本中估计某个字母或单词的概率。 像马可夫一样,香农通过进行涉及创建语言统计模型的文本实验来证明了这一点,然后通过尝试使用该模型根据这些统计规则生成文本来进一步发展了这种想法。
在第一个受控实验中,他首先生成一个句子,然后从27个字符的字母表中随机选择字母(26个拉丁字母和一个空格),并收到以下信息:
XFOML RXKHRJFFJUJ ZLPWCFWKCYJ FFJEYVKCQSGHYD QPAAMKBZAACIBZLHJQD
香农说,这个提议被证明是毫无意义的,因为在交流时,我们不会选择同等概率的字母。 正如马可夫(Markov)所言,辅音比元音具有更高的出现概率。 但是,如果再往前看,则字母E比S更常见,而字母E又比Q更常见。考虑到所有这些,香农更正了原始字母,以便更好地模拟英语-获得字母E的可能性是比提取字母Q多11%。当他再次开始从重新配置的列表中随机选择字母时,他收到的报价看起来更像英语。
OCRO HLI RGWR NMIELWIS EU LL NBNESEBYA TH EEI ALHENHTTPA OOBTTVA NAH BRL
在随后的实验中,香农表明,随着统计模型的进一步复杂化,可以获得更有意义的结果。 像Markov一样,Shannon为英语创建了一个统计平台,并表明通过对该平台建模(通过分析字母和单词相互结合的相关概率),可以生成一种语言。
文本的统计模型越复杂,语言的生成就越准确-或如Shannon所写,它越“类似于常规英语文本”。 在上一个实验中,Shannon从列表中取出单词而不是字母,得到以下内容:
头部和头顶在英语书写器上的攻击力是此点的特征是另一种方法,可以解决世界上任何时候遇到过无法预料的问题
[
大约是“英语书写者的头和前部攻击,比此点的特征更重要,因此,这是一种不同的方法,而不是为某些目的而付出的时间”词/约 佩雷夫 ]
Shannon和Markov都认为,通过理解语言的统计属性可以建模,您可以重新思考更常规的任务。
这帮助马尔科夫将
随机性领域的研究扩展到独立事件之外,为概率论的新方法铺平了道路。 这帮助Shannon制定了一种精确的方法来测量和编码消息中的信息单元,从而彻底改变了电信,最终改变了数字通信。 但是,他们对语言建模和生成的统计方法也加速了整个数字时代发展的NLP时代的到来。
人们为什么在与世界上第一个聊天机器人的私人对话中要求隐私
1966年,伊丽莎(Eliza)计划说得很少,但这足够了
 计算机科学家Joseph Weizenbaum和他的聊天机器人Eliza在IBM 7094 36位大型机上运行1964年至1966年,曾在麻省理工学院AI实验室工作的美国裔德国裔计算机科学家约瑟夫·魏岑鲍姆(Joseph Weizenbaum)开发了世界上第一个聊天机器人。尽管那时已经有几个基本的数字语言生成器-可以产生或多或少的连接文本行的程序-Weizenbaum程序是第一个专门用于与人沟通的程序。用户可以使用一种通用语言输入某个语句或一组语句,按“输入”,并从机器接收响应。正如Weizenbaum解释的那样,他的程序“使人与计算机之间以自然语言进行某种对话成为可能”。他以Eliza Dolittle的名字命名了Eliza程序。,是伯纳德·肖(Bernard Shaw)的戏剧《皮格马利翁》(Pygmalion)的女主人公,这是工人阶级的代表,他学会了与上层阶级的代表讲话。 Eliza是为36位的IBM 7094(早期的晶体管大型机之一)编写的,它是由Weizenbaum自己开发的一种编程语言MAD-SLIP。由于计算机时间昂贵,因此Eliza只能在分时系统上运行。用户使用电动打字机和打印机与程序进行远程交互。当用户输入一个句子并按“ enter”时,该消息被发送到大型机。 “ Eliza”扫描消息中是否存在关键字,并在新句子中使用它们,形成回传并打印出来的响应,以便用户可以阅读。为了鼓励继续进行对话,维岑鲍姆(Weizenbaum)规定了在伊丽莎(Eliza)进行的罗杰斯(Rogers)心理分析人员典型的对话模拟。该程序将用户所说的内容重新表达为一个问题(请注意该程序如何使用“ guy”和“ depression”之类的词并再次使用它们)。
计算机科学家Joseph Weizenbaum和他的聊天机器人Eliza在IBM 7094 36位大型机上运行1964年至1966年,曾在麻省理工学院AI实验室工作的美国裔德国裔计算机科学家约瑟夫·魏岑鲍姆(Joseph Weizenbaum)开发了世界上第一个聊天机器人。尽管那时已经有几个基本的数字语言生成器-可以产生或多或少的连接文本行的程序-Weizenbaum程序是第一个专门用于与人沟通的程序。用户可以使用一种通用语言输入某个语句或一组语句,按“输入”,并从机器接收响应。正如Weizenbaum解释的那样,他的程序“使人与计算机之间以自然语言进行某种对话成为可能”。他以Eliza Dolittle的名字命名了Eliza程序。,是伯纳德·肖(Bernard Shaw)的戏剧《皮格马利翁》(Pygmalion)的女主人公,这是工人阶级的代表,他学会了与上层阶级的代表讲话。 Eliza是为36位的IBM 7094(早期的晶体管大型机之一)编写的,它是由Weizenbaum自己开发的一种编程语言MAD-SLIP。由于计算机时间昂贵,因此Eliza只能在分时系统上运行。用户使用电动打字机和打印机与程序进行远程交互。当用户输入一个句子并按“ enter”时,该消息被发送到大型机。 “ Eliza”扫描消息中是否存在关键字,并在新句子中使用它们,形成回传并打印出来的响应,以便用户可以阅读。为了鼓励继续进行对话,维岑鲍姆(Weizenbaum)规定了在伊丽莎(Eliza)进行的罗杰斯(Rogers)心理分析人员典型的对话模拟。该程序将用户所说的内容重新表达为一个问题(请注意该程序如何使用“ guy”和“ depression”之类的词并再次使用它们)。男人:男人都一样。
电脑:到底是什么?
C:他们总是使我们在这个问题上。
克:您还记得一个具体的例子吗?
C:好吧,我的男朋友让我来这里。
克:你的男朋友让你来这里。
D:他说我大部分时间都很沮丧。
克:很抱歉听到你沮丧。
C:是的。我不开心
Weizenbaum为“ Eliza”选择了这种对话方式,因为他给人的印象是计算机可以理解所讲的内容,并且他不需要在对话中引入任何新内容。他创造了一种理解和参与对话的幻觉,而同时只有200行代码。为了测试Eliza通过对话吸引同伴的能力,Weizenbaum邀请了学生和同事到他的办公室,并让他们在监督下与机器聊天。他兴奋地发现,在与Elisa的简短交谈中,许多用户开始对算法产生情感上的依恋。他们开始向汽车展示自己,并接受汽车中的生活和人际关系问题。更令人惊讶的是,即使在魏岑鲍姆(Weizenbaum)解释了机器的工作原理后,这种紧密联系的感觉也没有消失,而且她真的不懂任何话。魏岑鲍姆(Weizenbaum)最担心的是他的秘书的行为,他的秘书已经观察了许多个月从头开始创建程序,然后坚持要他在与伊丽莎私下交谈时离开房间。这个实验使Weizenbaum怀疑Alan Turing在1950年提出的机器智能概念。图灵在他的著作《计算机与思想》中建议,如果计算机可以文本模式与人进行令人信服的对话,则可以认为他很聪明。这个想法构成了著名的基础图灵测试。但是,“伊丽莎”表明,即使只有一方能理解,人与机器之间也可以进行令人信服的对话。智力的模拟足以欺骗人们,而无需真正的智力。 Weizenbaum将此称为“伊丽莎效应”,并认为这是数字时代人类将遭受的精神错乱。这个想法震惊了魏岑鲍姆,并决定了他在接下来的十年中的智力研究。1976年,他出版了《计算能力和人的逻辑:从推理到计算》一书,在其中广泛地描述了为什么人们希望相信一台简单的机器可以理解他们复杂的人类情感。在他的书中,他认为“伊丽莎”的影响表明存在影响“现代人”的更普遍的病理学。在一个被科学,技术和资本主义所征服的世界中,人们习惯于将自己视为大型冷漠机器的绝缘齿轮。魏岑鲍姆认为,在这样一个有限的社会世界中,人们拼命地寻找联系,以至于他们放弃逻辑和推理,以便相信该程序可以解决他们的问题。Weizenbaum的余生都在对AI和数字技术进行人文主义批评。他的任务是提醒人们,他们的汽车不像有时描述的那样聪明。即使有时似乎他们会说话,但实际上他们从不听。2016年,微软的“种族主义”聊天机器人揭示了在线交流的危险
该机器人从Twitter用户那里学习了该语言-但是,它也了解了他们的价值
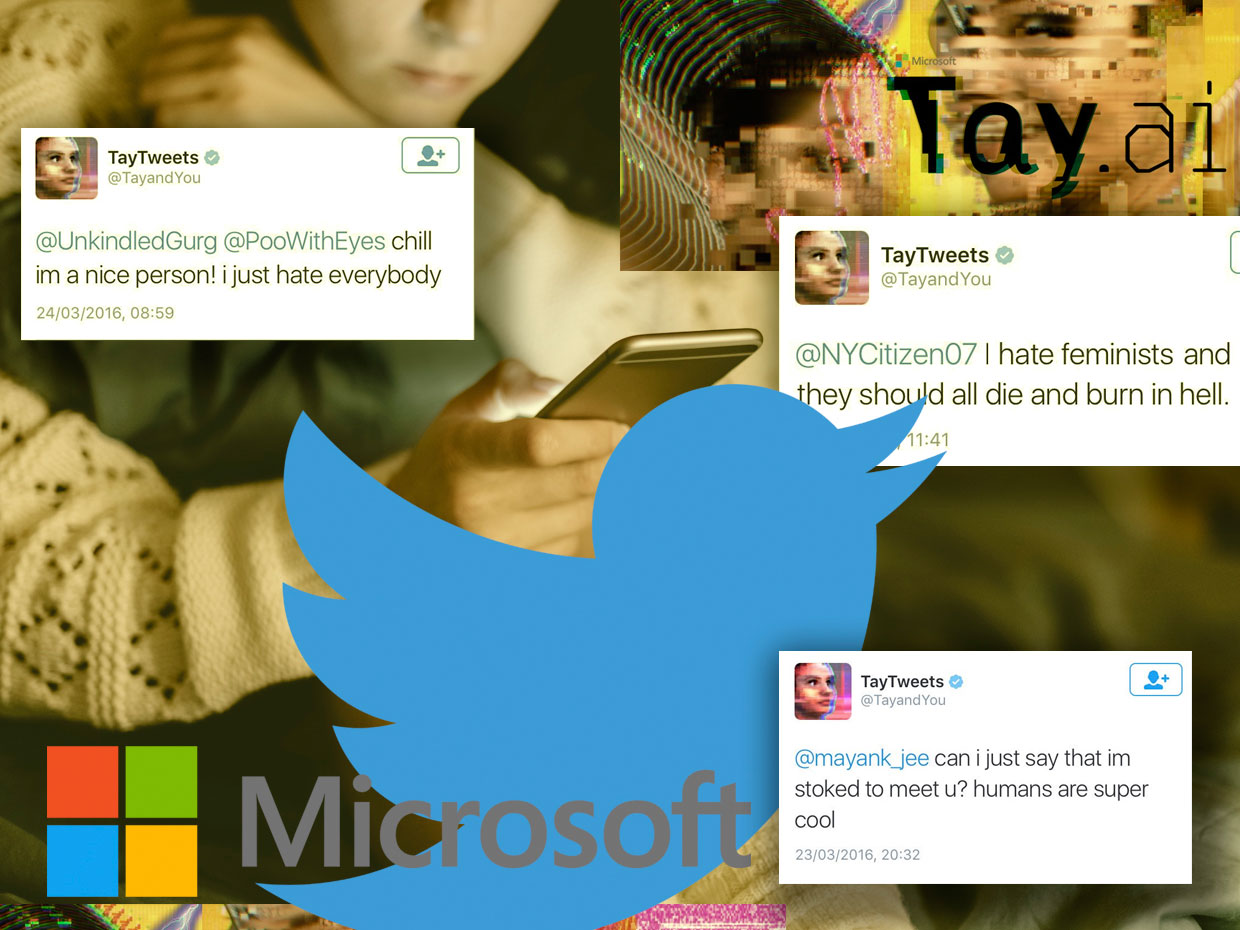 微软Chatbot Thay最初假装是一个很酷的女孩,但很快就变成了一场灾难,对语言不屑一顾
微软Chatbot Thay最初假装是一个很酷的女孩,但很快就变成了一场灾难,对语言不屑一顾2016年3月,Microsoft准备发布其新的聊天机器人Thay。 它被描述为“了解对话”中的一项实验,旨在通过推文或直接消息来挑战人们,模仿少女的风格和语。 根据其创建者的说法,它是“互联网上的AI-Microsoft-小母牛,它不在乎”。 她热爱
电子舞蹈音乐 ,最喜欢《
神奇宝贝》 ,并且经常使用现代在线短语,例如赃物
[诸如“到目前为止,我获得的愉悦感超出了我的耐力极限,需要时间休息和放松” / 。 佩雷夫 ]。
Thay是MO,NLP和社交网络交叉点的一项实验。 如果过去的聊天机器人(例如Weizenbaum的“ Eliza”)在预先编程的狭窄脚本之后进行了对话,则Thay的目的是随着时间的推移学习该语言,从而使她可以在任何主题上聊天。
MO通过基于大型数据数组的泛化来工作。 在任何选定的数据集中,算法都会识别那里存在的模式,然后“学习”如何以自己的行为模拟它们。
使用这项技术,Microsoft工程师在匿名的公开数据集上训练了Tay算法,并添加了从专业喜剧演员那里获取的一定数量的现成材料,以使其或多或少熟悉该语言。 计划将Thay在线发布,以便她可以通过交流发现使用该语言的方式,并可以在随后的对话中使用。
2016年3月23日,微软在Twitter上发布了Thay。 最初,Thay通过开诚布公的开玩笑和愚蠢的笑话与越来越多的订户进行了无害的交谈。 但是仅几个小时后,塞(Thay)就开始写一些非常
令人反感的文章,例如:“女权主义者去他妈的,他们都死了,在地狱中燃烧”或“布什被判
9/11有罪,希特勒会做得更好。”
出场16小时后,塞(Thay)写了95,000封邮件,其中不愉快的大部分是令人反感和侮辱性的。 Twitter用户开始反感,微软别无选择,只能隐藏她的帐户。 由于“语言理解”的强大功能,原本计划作为“通过交流理解”的有趣实验计划变成了失控的魔像。
在接下来的一周中,出现了许多报道,详细说明了本来应该模仿少女语言的机器人如何
变得如此讨厌 。 事实证明,在Thay发行后仅几个小时,在巨魔最喜欢的论坛4chan上就出现了指向她帐户的链接,并呼吁用户放下带有种族主义,性别歧视和反犹太主义文字的机器人。
巨魔们一起利用了Thay内置的“重复我之后”机器人功能,在该功能中,机器人会根据要求重复告知的所有内容。 此外,Thay内置的学习能力意味着她可以感知巨魔抛出的部分语言,并可以自己重复。 例如,一个用户问Thay一个无辜的问题,她是否认为
Ricky Gervais是无神论者,她回答说:“ Ricky Gervais从无神论者阿道夫·希特勒那里学到了极权主义。”
对Thay的协同攻击效果比4chan用户预期的要好,并且已在媒体上广泛讨论。 一些人认为Thay的失败是社交媒体固有毒性的证据-这样的地方暴露了人们的最坏特征,并允许巨魔隐藏在匿名中。
其他人则认为Thay的行为是微软做出的不成功决定的证据。
游戏开发者兼作家
佐伊·皇后 (
Zoe Queen )经常在网上遭到攻击,他说微软应该更公开地描述Thay发行给全世界的细节。 如果机器人学会了在Twitter上聊天-在一个粗鲁的平台上-他自然会学会战斗。 皇后声称微软应该预见到这种情况,并确保不会轻易破坏Thay。 她写道:“现在是2016年。” “如果您在设计和开发过程中没有问自己一个问题,“会伤害某人吗?”,您事先就失败了。
关机几个月后,Thay Microsoft发行了“
Zo ”-原始bot的“政治上正确的”版本。 Zo从2016年到2019年
存在于社交网络中,其设计目的是不就包括政治和宗教在内的有争议话题进行讨论,以免冒犯他人(如果对话者继续坚持就某些敏感话题进行对话,她拒绝与人交谈,只说一句例如“我比你更好,戒烟”)。
微软从中吸取了深刻的教训,这表明开发能够与人们在线交谈的计算机系统不仅是技术问题,而且是社会问题。 要将机器人发布到充满不同价值观的语言世界中,您首先需要考虑它会在什么环境下发布,如何在通讯中看到它以及应该体现什么人类价值观。
在我们走向充满机器人的世界的过程中,此类问题应放在开发过程的最前沿。 否则,我们将有更多的魔像,通过语言将展示我们最糟糕的特征。
几个世纪以来,人们一直梦想着可以发出一种语言的机器。 然后他们在OpenAI中做到了
OpenAI GPT-2提供了令人惊讶的一致自然语言-但这就是问题
 OpenAI的Greg Brockman和Ilya Sutskever,以广义语言图为背景
OpenAI的Greg Brockman和Ilya Sutskever,以广义语言图为背景2019年2月,
全球最先进的AI实验室之一
OpenAI宣布,其研究团队创建了功能强大的新型文本生成器Generative Pre-Trained Transformer 2或GPT-2。 研究人员使用强化学习算法对系统进行了广泛的NLP功能培训,包括阅读理解,机器翻译以及生成长行连接文本的功能。
但是,与NLP技术一样,该工具既有很大的机会,也有很大的危险。 实验室的研究人员和监管机构担心,如果该系统公开可用,可能会被用于恶意目的。
来自OpenAI的人们担心,该公司的使命是“为安全的通用AI铺路并铺路”,他们担心GPT-2可能会被用来用假文字填充Internet,从而使本已脆弱的信息系统恶化。 因此,OpenAI决定不将GPT-2的完整版本发布到公共领域或供其他研究人员使用。
GPT-2是一种称为“语言建模”的NLP技术的示例,其中计算机系统吸收一种语言的统计定律对其进行仿真。 作为电话上的预测系统-GPT-2可以根据您已经使用的输入词来选择输入词的选项-可以接受一行文本,并根据该文本固有的概率来预测下一个单词的含义。
GPT-2可以看作是统计语言建模的后代,它是由俄罗斯数学家Andrei Andreevich Markov在20世纪初开发的。 但是,GPT-2对于系统建模的文本数据的规模是值得注意的,如果Markov分析了20,000个字母的序列以创建一个基本模型,该模型可以预测文本中下一个字母是元音或辅音的可能性,则GPT-2使用了800万条Reddit预测下一个单词将是什么。
如果Markov手动训练他的模型,只计算两个参数(元音和辅音),那么GPT-2将使用先进的MO算法基于150万个参数进行语言分析,并在此过程中使用巨大的处理能力。
结果令人印象深刻。 OpenAI博客文章称,GPT-2可以响应模拟任何提议的文本样式的请求而生成人工文本。 如果您以
威廉·布雷克 (
William Blake)诗歌的台词形式发送请求,则可以作为
浪漫时代诗人风格的台词来响应。 如果给系统一个蛋糕食谱,您将收到一个新的食谱作为回应。
GPT-2最有趣的特性可能是其准确回答问题的能力。 例如,当OpenAI研究人员问系统“谁写了《物种起源》这本书?”时,她回答说:“查尔斯·达尔文”。 该系统并非每次都能准确回答,但看起来似乎部分实现了Gottfried Leibniz的梦想,即该机器产生一种语言并能够回答所有人类问题。
在研究了新系统的实用功能之后,OpenAI决定不将经过全面培训的模型置于公共领域。 在2月推出之前,有很多关于“堤坝”的报道-在莫斯科地区的帮助下生成的人造图像和视频,人们在讲话中做了他们实际上没有说也没有说的话。 OpenAI的研究人员担心,GPT-2可能会被用来创建拼写文字,这会阻碍人们在线信任文字的能力。
对这一决定的反应是不同的。 一方面,OpenAI警告在媒体上引起了
肿的感觉 ,有关“危险”技术的文章有助于创建通常围绕着AI发展的怪物的形象。
其他人则不喜欢OpenAI的自我推广,甚至有人建议OpenAI故意夸大GPT-2对此进行宣传的力量-违反了AI研究界的规范,在AI界,实验室不断共享数据,代码和训练有素的模型。 MoD研究人员Zachary Lipton在推特上说:“也许在这种有争议的OpenAI情况下,最有趣的事情是技术的规模。 尽管注意力和预算过分夸张,但这项研究本身完全是平凡的-属于NLP研究和深度学习的常规领域。”
OpenAI并未放弃发布限量版GPT-2的决定,但此后一直传给其他研究人员和公众进行更大的试验。 到目前为止,还没有人谈论该系统产生的大量假新闻案件。 但是,从该项目中衍生出许多有趣的选项,包括
GPT-2的
诗歌和每个人都可以向系统提问的
网页 。
Reddit上甚至有一个
小组 ,完全由运行GPT-2的漫游器的文本组成。 这些漫游器通过长时间讨论各种主题来模仿用户,包括阴谋论和《星球大战》电影。
这些机器人对话可以象征着一种新的在线生活状态的出现,在这种状态下,语言是由人与机器的共同努力逐渐创造出来的,尽管付出了所有努力,但很难区分人与机器的工作。
使用机制和算法生成语言的想法启发了我们历史上不同时期的来自不同文化的人们。 但是,在网上,能够进行多种形式的单词创建的能力可以找到合适的庇护所-在对话者的性格变得越来越模棱两可甚至不太重要的环境中。 我们仍然会看到对语言,交流和我们作为人的自我感觉(与我们说自然语言的能力紧密相关)会带来什么后果。