
最近,在Yandex.Money运营部发生了一次重大事件。 我们的公司发展迅速,事实证明,不仅我们的心,而且数据中心的需求也在变化。 更准确地说,所需的位置发生了变化。 现在三个月以来,其中一个数据中心生活在一个新地方。
关于Yandex.Money如何迁移到新的数据中心,我将告诉您运营部门主管和IT基础架构和内部系统部门主管Ivan。
在切入点下-事件的时间顺序,举动的重要里程碑,意外的转折和汇报。 我们分享我们如何生存下来。
搬迁的先决条件
以前,Yandex.Money数据中心之一位于莫斯科郊区。 现实是,在城市以外,并非所有的光通信通道提供商都具有独立铺设电缆路线的能力-这很昂贵。 我们之所以决定采取此决定的第一个原因是,在旧的数据中心中,通信通道沿相同的路径通过,这带来了额外的风险。
莫斯科环路内有许多提供商,并且电缆系统非常发达。 您可以从不同的提供商那里购买渠道,这些渠道以不同的方式出现并且不会重叠。 该地区的风险有所增加-例如,一台挖掘机将同时挖掘所有的履带。
其次,以前的数据中心存在技术限制,包括周期性地遇到电源问题。
但是主要原因(=痛苦)是无法扩展。 这意味着该建筑物没有足够的空间来放置其他机架,因此可以在其中放置新设备。 这与我们的生产环境直接相关,因为Yandex.Money有两个数据中心,并且它们的容量必须对称。
规划中
此举的准备工作分为以下几个阶段:
- 比赛:DC,通道,网络,机架,PDU,电缆;
- 将应用程序和数据库转移到第二个DC;
- 教--禁用DC;
- 核心网的新架构,IX;
- 在DC中设置新的网络核心。
供应商选择
第一个Yandex.Money数据中心位于莫斯科。 为了避免较大的网络延迟,我们决定将第二个数据中心放置在第一个附近。
在MKAD内以最大程度地减少网络延迟,并且距第一个设施的距离不超过20公里,以确保两个数据中心不受同一城市基础设施以及可能的技术或自然灾害的影响。
在分析市场时,我们以诸如可用性和可靠性方面的数据中心认证之类的重要标准为指导。 在俄罗斯和世界上最常见的标准是Uptime Institute开发的标准,该标准对全世界的数据中心进行审核。 值得注意的是,有许多数据中心仅对项目文档进行了认证,但这并不意味着数据中心本身是根据标准构建,测试和操作的。
从我们的实践中得到一个案例:莫斯科的一个数据中心服务提供商向我们宣布该数据中心项目符合Tier III标准,并提出达成一项协议,承诺100%的可用性,即每年停机时间为0分钟! 亲自访问该站点后,我们意识到没有任何官方认证可以保证质量水平,并且基础架构显然没有使用Tier III。 数据中心位于一栋居民楼的底楼,唯一的发电机拖车站在街道上,没有任何人身保护。
因此,在竞争要求中,我们不仅包括项目认证,还包括实施和管理过程的认证。
此外,我们与供应商确定了DC之间的光通信通道以及到流量交换点(IX)的通道,在此处我们与供应商或合作伙伴安排了接口。 主要标准是光通信通道应该是独立的,并走不同的路线。
当然,还有其他购买–主要是网络设备,机架(用于安装服务器的专用机柜),配电单元(智能配电单元)以及电缆和跳线。
值得注意的是,我们特别仔细地选择了将运输设备的供应商。 公司拥有运输服务器的经验非常重要,搬家工人知道这不是家具和货物,因此在驾驶时也应格外小心。 另外,在运输过程中发生损坏时,我们对运输的设备进行了保险。
网络基础架构升级
关于网络基础架构,我们有两个选择。 首先是“按原样”运输旧的网络设备。 第二是首先在新的数据中心中构建新的网络基础结构,然后再传输服务器设备。
由于我们了解到我们已经“碰上”了旧数据中心的网络带宽,并且我们至少需要在未来3-5年内保留和扩展能力,因此决定从头开始在新数据中心中构建网络基础架构并升级到新一代设备。
在新数据中心中构建网络时,我们遵循经典模型。 在每个机架中,服务器连接到两个访问交换机,然后又连接到中央聚合交换机(它们也是网络的核心)。
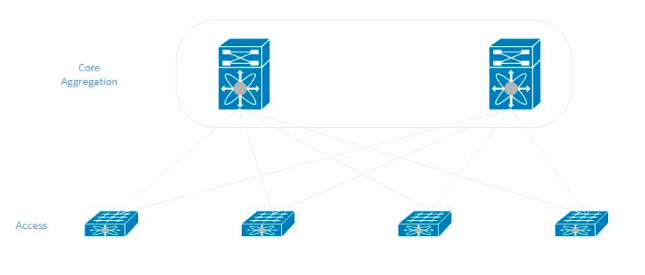
教s
移动时,我们决定完全关闭数据中心,一次将所有内容运输并在新的地方打开它。 为此,该公司必须学习如何在没有两个数据中心之一的情况下进行操作。 它需要几乎所有管理员的参与,才能使信息平台在不同平台,不同操作系统,不同数据库上不间断地在其余站点上工作。
对于最关键的服务,提供了备用资源,即使关闭了一个数据中心,该备用资源仍然可用。
进行预订工作后,开始练习。 首先,我们断开各个网络,网段的连接,然后才断开数据中心的连接。 在2019年,我们对数据中心进行了10次测试关闭-我们观察了300个信息系统的运行情况。 反复检查自治权,我们坚信我们可以轻松断开连接。
然后...
第十周
计划在星期五中的一个星期五关闭数据中心的所有设备-最新版本在早上推出,然后宣布暂停。
Yandex.Money每天可以发布60个或更多版本,并且所有版本均同时发布到两个数据中心。
我们停止了发行,确保系统稳定运行,并且无需修复组件。 从15:00开始,他们开始逐步淘汰所有应用程序,数据库和服务器。 在周五至周六的夜晚,我们等待时间,我们确信没有发生任何不良情况,这意味着我们可以出发。 在周六早上,由15人组成的团队开始拆卸设备,并将其运输到新的数据中心。

周六我们花了一整天的时间来拆卸和运输设备。 接下来,开始进行设备安装,切换,将其连接到电源的过程。

在星期六晚上,我们安装并连接了第一批服务器。 主要工作开始于周日-到周末晚上,几乎所有设备都已安装。 我们只在星期一晚上完成了换乘。

在星期二早上,我们对网络,通讯渠道进行了最终测试,并准备提高我们的系统。 他们开始筹集第一批服务器,但是出了点问题...
我们开始收到来自管理员的大量投诉,指网络无法完全在服务器中运行,或者完全无法运行,或者是两个接口之一。 他们开始在网络设备方面,操作系统中,操作系统设置中寻找问题。
症状相似-他们开始查看可能是什么原因。 我们注意到,有必要将跳线移到交换机端口旁边,并且一些工作链接会断开。

发现这一点后,我们意识到这些跳线中有很大一部分(约2000条的40%)有缺陷。 我们将另一家值得信赖的制造商的所有可用跳线移动到了新的数据中心,并紧急开始重新连接最关键的服务器。 又过了一天。
从星期三晚上到星期四早上,团队开始提升信息系统的主要组成部分。
在我们提高了关键服务并启动了支付系统的储备之后,我们包括了新数据中心的部分测试台和后台办公系统的储备,以便我们所有的内部系统都可以与两个数据中心一起工作。 到本周末,已传输的数据中心的几乎所有IT基础架构都已启动。
最初有一个为期5天的计划,但由于与跳线故障有关的应急情况,结果证明是一周。 下面我们清楚地描绘了我们行动的时间表。
搬迁计划-待定:- 星期五-我们熄灭网络和应用程序;
- 星期六-我们随身携带并开始集会;
- 星期日-安装服务器,启动网络;
- 星期一-我们完成了网络,启动了应用程序;
- 星期二-打开所有内容。
现实情况:- 星期五-我们熄灭网络和应用程序;
- 星期六-我们随身携带并开始集会;
- 星期日-安装服务器,启动网络;
- 星期一-布线,网络启动;
- 星期二-打开服务器, 超过100个无法使用;
- 星期三- 联姻,更换 ,启动App和DB;
- 星期四-完成了PS的替换,启动了App。
搬家后的生活
我们从搬家中学到了什么?首先,我们两个数据中心现在都属于Tier III Uptime Institute级别。 数据中心的供应商向我们保证了正常运行时间的可用性为99.982%,这相当于每年停机1.6小时。 我们对站点之间通信渠道的可靠性充满信心。 现在,扩展我们的IT基础架构也没有任何限制。
移动的想法为我们提供了一个在带宽方面升级网络设备的绝好机会。 我们还重构了机架中的电源-已安装“智能PDU”,备用电源服务器。
当我们移动时,我们能够“梳理”开关,现在看起来更整洁了。

因此,总的来说,系统开始更稳定地工作,并且我们的客户获得了更好的服务。
您为自己得出了什么结论?在执行大型项目时,您需要考虑风险,想象可能会遇到的陷阱。 我们的以太网电缆示例表明,仅购买测试产品并测试所选制造商的电缆产品还不够。 为了降低风险,有必要对2000条电缆进行随机测试。
还值得考虑的是,某些服务器可能无法幸免,并且由于各种原因而无法打开。 一种或另一种方式是晃动和机械应力。 在600辆运输设备中,有6块被打破。 在足够多的服务器中,只有1%遭受了损坏,没有一个磁盘崩溃了-我们相信这是一个很好的结果。
这就是Yandex.Money数据中心搬到新地方的方式。 我们希望我们的经验可以帮助您避免可能的错误,并且也许会带您获得其他有趣的解决方案。