任何光栅
图像都可以表示为
二维矩阵 。 当涉及到颜色时,可以通过以
三维矩阵的形式查看图像来提出想法,在该
矩阵中 ,可以使用附加的测量值来存储每种颜色的数据。
如果我们将最终颜色视为所谓的组合 原色(红色,绿色和蓝色),在三维矩阵中,我们确定了三个平面:第一个平面用于红色,第二个平面用于绿色,最后一个平面用于蓝色。
我们将矩阵中的每个点称为像素(图像元素)。 每个像素包含每种颜色的强度信息(通常以数值形式)。 例如,
红色像素表示它具有0个绿色,0个蓝色和最大红色。 可以使用三种颜色的组合来形成
粉红色像素 。 使用0到255之间的数值范围,将粉红色像素定义为
Red = 255 ,
Green = 192和
Blue = 203 。

本文是在EDISON的支持下发布的。
我们开发用于视频监控,流视频以及在手术室中进行视频录制的 应用程序 。
替代颜色编码技术
为了表示构成图像的颜色,还有许多其他模型。 例如,您可以使用索引调色板,其中仅需要一个字节来表示每个像素,而不是使用RGB模型时需要的三个字节。 在这样的模型中,可以使用2D矩阵代替3D矩阵来表示每种颜色。 这样可以节省内存,但颜色较少。

RGB
例如,在下面看这张照片。 第一张脸已完全粉刷。 其他的是红色,绿色和蓝色的平面(相应颜色的强度以灰度显示)。

我们看到原稿中的红色阴影将出现在观察到第二人称最亮部分的相同位置。 蓝色的贡献主要只能在马里奥(最后一张脸)的眼睛和他的衣服元素中看到。 请注意,所有三个彩色平面的贡献最小(图像的最暗部分)-这是Mario的胡子。
为了存储每种颜色的强度,需要一定数量的位-该值称为
位深 。 假设8个位(基于0到255的值)花费在一个彩色平面上。 然后,我们的色深为24位(8位* 3 R / G / B平面)。
图像的另一个属性是
分辨率 ,它是一维像素的数量。 通常将其称为
width×height ,如下面的示例图像4 x 4所示。

当处理图像/视频时,我们要处理的另一个属性是
纵横比 ,它描述图像或像素的宽度和高度之间通常的比例关系。
当他们说电影或图片为16 x 9时,通常指
的是显示器的
纵横比 (
DAR-来自
Display Aspect Ratio )。 但是,有时各个像素的形状可能有所不同-在这种情况下,我们谈论的
是像素的
比例 (
PAR-来自
像素长宽比 )。


给女主人的提示: DVD对应DAR 4 x 3
尽管DVD的实际分辨率为704x480,但由于PAR设置为10:11(704x10 / 480x11),因此它仍保留4:3的宽高比。
最后,我们可以将
视频定义为一段
时间内
n帧的序列,可以将其视为附加维度。 然后,
n是帧速率或每秒的帧数(
FPS- 每秒的帧数 )。

显示视频所需的每秒位数是其
比特率 。
比特率=宽度*高度*位深度*每秒帧数
例如,对于每秒30帧,每像素24位,480x240分辨率,每秒82,944,000位或82,944 Mbps(30x480x240x24)的视频,将需要-但这是您不使用任何压缩方法的情况。
如果比特率
几乎恒定 ,则称为
恒定比特率 (
CBR- 恒定比特率 )。 但是它也可以变化,在这种情况下,它被称为
可变比特率 (
VBR- 可变比特率 )。
该图显示了在完全暗帧的情况下,如果花费的位数不太多,则VBR受到限制。

最初,工程师开发了一种在不使用额外带宽的情况下使视频显示的感知帧速率加倍的方法。 这种方法被称为
隔行视频 ; 基本上,它在第一个“帧”中发送一半屏幕,在下一个“帧”中发送另一半屏幕。
当前,场景可视化主要使用
渐进扫描技术来执行。 这是一种显示,存储或传输运动图像的方法,其中顺序绘制每帧的所有线条。

好吧! 现在我们知道,如果传输速度是恒定(CBR)或可变(VBR),则如何以数字形式表示图像,如何排列颜色,每秒花费多少位来显示视频。 我们知道使用给定帧速率的给定分辨率,并熟悉许多其他术语,例如隔行视频,PAR和其他一些术语。
裁员
众所周知,没有压缩的视频不能正常使用。 分辨率为720p且频率为每秒30帧的每小时视频将占用278 GB。 我们将1280 x 720 x 24 x 30 x 3600(宽度,高度,每像素位数,FPS和以秒为单位的时间)相乘得出该值。
使用DEFLATE之类的
无损压缩算法 (用于PKZIP,Gzip和PNG)将不会充分减少所需的带宽。 您必须寻找其他压缩视频的方法。
为此,您可以使用我们愿景的功能。 我们区分出比颜色更好的亮度。 视频是随时间重复的一组连续图像。 同一场景的相邻帧之间存在很小的差异。 此外,每个框架都包含许多使用相同(或相似)颜色的区域。
颜色,亮度和我们的眼睛
我们的眼睛对亮度比对颜色更敏感。 您可以通过看这张图片自己看到。
如果您没有在图像的左半部分看到正方形
A和
B的颜色实际上是相同的,那么这是正常的。 我们的大脑使我们更加注重明暗对比而不是颜色。 在标记的正方形之间的右侧,有一个相同颜色的跳线-因此我们(即我们的大脑)可以轻松地确定实际上存在相同的颜色。
让我们看看(简化)我们的眼睛如何工作。 眼睛是由许多部分组成的复杂器官。 但是,我们对锥和棍棒最感兴趣。 眼睛包含约1.2亿个杆和600万个视锥。
将对颜色和亮度的感知视为眼睛某些部分的独立功能(实际上,一切都有些复杂,但是我们会简化)。 杆状细胞主要负责亮度,而锥状细胞负责颜色。 根据所含颜料的不同,视锥分为三种:S视锥(蓝色),M视锥(绿色)和L视锥(红色)。
由于杆(亮度)比圆锥(颜色)多得多,因此可以得出结论,与颜色相比,我们更能区分黑暗和明亮之间的过渡。

对比灵敏度功能
实验心理学和许多其他领域的研究人员开发了许多人类视觉理论。 其中之一称为对比敏感度函数 。 它们与空间和时间照明相关联。 简而言之,它是关于观察者看到它们之前需要进行多少更改。 注意单词“功能”的复数形式。 这是由于这样一个事实,我们可以测量灵敏度函数,以便不仅与黑白图像形成对比,而且与彩色形成对比。 这些实验的结果表明,在大多数情况下,我们的眼睛对亮度比对颜色更敏感。
由于已知我们对图像亮度更敏感,因此您可以尝试使用此事实。
颜色模型
我们弄清楚了如何使用RGB方案处理彩色图像。 还有其他型号。 有一种将亮度与颜色分开的模型,称为
YCbCr 。 顺便说一下,还有其他模型也进行了类似的分离,但我们仅考虑这一模型。
在此颜色模型中,
Y代表亮度,并且使用了两个颜色通道:
Cb (饱和蓝色)和
Cr (饱和红色)。 YCbCr可以从RGB获得,也可以进行逆变换。 使用此模型,我们可以创建全彩色图像,如下所示:

在YCbCr和RGB之间转换
有人会反对:如果不使用绿色,如何获得所有颜色?
要回答此问题,请将RGB转换为YCbCr。 我们使用
ITU-R单位推荐的
BT.601标准中采用的系数。 本单元定义了数字视频标准。 例如:什么是4K? 帧速率,分辨率,颜色模型应该是什么?
首先,我们计算亮度。 我们使用ITU提出的常数并替换RGB值。
Y = 0.299
R + 0.587
G + 0.114
B获得亮度后,我们将蓝色和红色分开:
Cb = 0.564(
B -
Y )
铬 = 0.713(
R -
Y )
我们还可以转换回YCbCr,甚至获得绿色:
R =
Y + 1.402
铬B =
Y + 1.772
立方英尺G =
Y -0.344
Cb -0.714
Cr通常,显示器(监视器,电视,屏幕等)仅使用RGB模型。 但是可以用不同的方式来组织此模型:

颜色下采样
通过将图像显示为亮度和颜色的组合,如果我们有选择地删除信息,我们可以使用人类视觉系统对亮度的敏感性高于对颜色的敏感性。 颜色下采样是一种使用比色彩亮度低的分辨率对图像进行编码的方法。
降低色彩分辨率的接受程度如何? 事实证明,已经有一些描述如何处理分辨率和合并的方案
(最终颜色= Y + Cb + Cr)。这些方案被称为
子采样系统 ,并以3倍比率-a
: x : y的形式表示,该比率确定亮度和色差信号的样本数。
a-标准水平采样(通常等于4)
x-第一像素行中的颜色样本数(相对于
a的水平分辨率)
y是像素的第一行和第二行之间的颜色样本的更改次数。
4 : 1 : 0是例外,它在每个4 x 4亮度分辨率块中提供一种颜色样本。
现代编解码器中使用的常见方案:
- 4 : 4 : 4 (不进行下采样)
- 4 : 2 : 2
- 4 : 1 : 1
- 4 : 2 : 0
- 4 : 1 : 0
- 3 : 1 : 1
YCbCr 4:2:0-合并示例
这是使用YCbCr 4:2:0的组合图像片段。 请注意,我们每个像素仅花费12位。
这是由主要类型的颜色子采样编码的相同图像的外观。 第一行是最终的YCbCr,下一行显示颜色分辨率。 鉴于质量损失很小,结果非常不错。

还记得我们为一个小时的视频文件(计数为720p和每秒30帧)计算了278 GB的存储空间吗? 如果我们使用YCbCr 4:2:0,则此大小将减少一半-139 GB。 到目前为止,距离可接受的结果还很远。
您可以使用FFmpeg自己获取YCbCr直方图。 在此图像中,蓝色胜过红色,这在直方图本身上清晰可见。

颜色,亮度,色域-视频评论
建议观看此精彩视频。 这就解释了什么是亮度,实际上,所有关于亮度和颜色的点都放置在其上 。
镜框类型
我们继续前进。 让我们尝试及时消除冗余。 但首先,让我们定义一些基本术语。 假设我们有一部每秒30帧的电影,这是它的前4帧:




我们可以在帧中看到许多重复:例如,蓝色背景在帧之间不会改变。 为了解决这个问题,我们可以将它们抽象地分为三种类型的框架。
I型框架( I ntro框架)
I帧(参考帧,关键帧,内部帧)是独立的。 无论需要可视化什么,I框架实际上都是静态照片。 第一帧通常是I帧,但是我们会定期观察远离第一帧的I帧。
P帧( P保留帧)
P帧(预测帧)利用了以下事实:几乎可以始终使用前一帧播放当前图像。 例如,在第二帧中,唯一的变化是前进球。 我们可以仅通过略微修改帧1来获得帧2,仅使用这些帧之间的差异即可。 要构建框架2,请参考框架1之前的框架。
←

B帧( B i预测帧)
不仅链接到过去,而且链接到将来的框架,以提供更好的压缩效果怎么样? 这基本上是一个B帧(双向帧)。
←
→
中级提款
这些帧类型用于提供最佳压缩。 我们将在下一节讨论这种情况。 同时,我们注意到,就内存而言,I帧是最“昂贵”的,P帧便宜得多,但B帧是视频最赚钱的选择。

时间冗余(帧间预测)
让我们看看我们有什么机会可以减少时间重复。 这种类型的冗余可以使用相互预测的方法来解决。
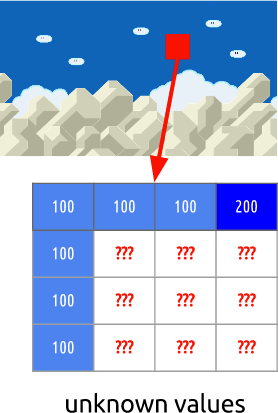
我们将尝试花费尽可能少的比特来编码帧0和1的序列。

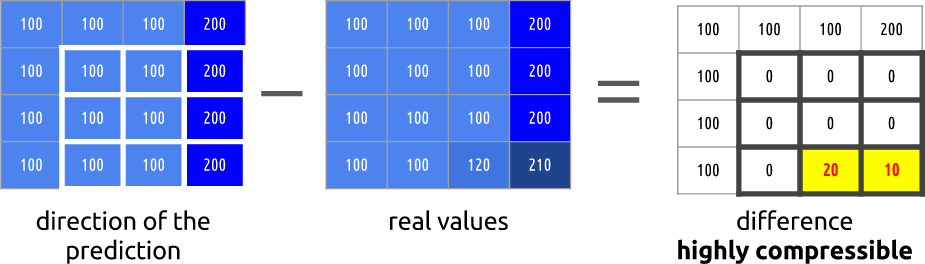
我们可以从第0帧减去第1帧,然后减去。得到第1帧,我们仅使用它与前一帧之间的差,实际上,我们仅对所得的余数进行编码。

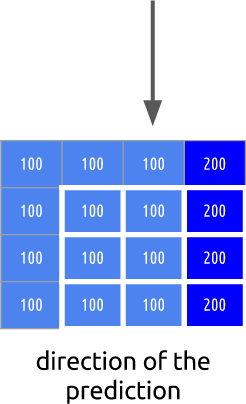
但是,如果我告诉您,还有一种使用更少位的更好方法呢? 首先,让我们将第0帧分成清晰的块网格。 然后,我们尝试比较帧0和帧1中的块。换句话说,我们评估帧之间的移动。
来自维基百科- 块运动补偿
块运动补偿将当前帧划分为不相交的块,运动补偿矢量报告了块的起源(一个常见的误解是前一帧被划分为不相交的块,而运动补偿矢量却指示了这些块的去向。但实际上,并未分析前一个块框架和下一个框架,结果不是方块移动的位置,而是方块的来源。 通常,源块在源帧中重叠。 一些视频压缩算法不仅从一个帧的一部分中收集当前帧,还从多个先前传输的帧中收集当前帧。

在评估过程中,我们看到球已从
( x = 0, y = 25)移动到
( x = 6, y = 26) ,
x和
y的值确定了运动矢量。 保存位的另一步骤是仅编码块的最后位置和预测位置之间的运动矢量之差,因此最终运动矢量将为
(x = 6-0 = 6,y = 26-25 = 1)。在实际情况下,该球将被分成
n个块,但这不会改变问题的本质。
框架中的对象在三个维度上移动,因此,当球移动时,它在视觉上会变小(如果朝观察者移动,则可能会变大)。 通常,块之间不会有完美的匹配。 这是我们的评估和真实情况的综合视图。

但是我们看到,当应用运动估计时,用于编码的数据明显少于使用计算帧之间增量的更简单方法时的数据。

真实的运动补偿将是什么样子
此技术立即应用于所有块。 通常,我们的条件移动球会一次被分成几个区块。

您可以使用
Jupyter亲自感受这些概念。
要查看运动矢量,可以使用
ffmpeg创建具有外部预测的视频。
")
您也可以使用
Intel Video Pro Analyzer (已付费,但有一个免费的试用版,仅受前十帧的限制)。

空间冗余(内部预测)
如果我们分析视频中的每一帧,就会发现许多相互联系的区域。

让我们来看这个例子。 该场景主要由蓝色和白色组成。

这是一个I形框架。 我们无法采用以前的帧进行预测,但是最终会对其进行压缩。 . , , - .
, . , .
. ( ), . , .
, ffmpeg. ffmpeg.
 ffmpeg") 或者,您也可以使用Intel Video Pro Analyzer(如上所述,在免费试用版中,前10帧有限制,但是一开始对您来说就足够了)。
或者,您也可以使用Intel Video Pro Analyzer(如上所述,在免费试用版中,前10帧有限制,但是一开始对您来说就足够了)。

另请阅读博客
EDISON公司:
20个图书馆
壮观的iOS应用程序