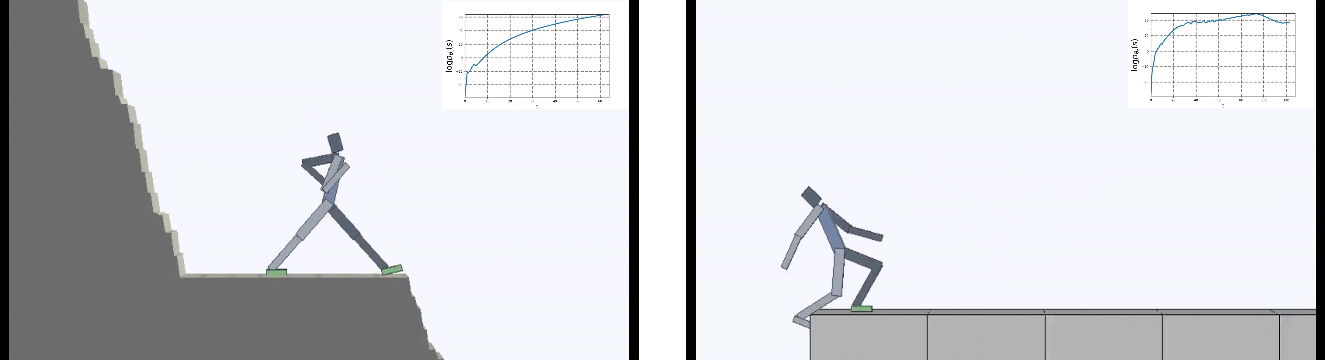
强化学习通常将好奇心作为AI的动机。 迫使他寻求新的感觉并探索世界。 但是生活充满了不愉快的惊喜。 您可以掉下悬崖,从好奇心的角度来看,它将永远是非常新的和有趣的感觉。 但显然不是要争取什么。
伯克利的开发人员将虚拟代理的任务颠倒了:不是主要动机是好奇心,而是希望通过各种方式避免任何新颖性。 但是“无所作为”比听起来要难。 置于不断变化的环境中,人工智能必须学习复杂的行为,以避免产生新的感觉。
强化学习采取了怯tim的步骤来构建强大的AI。 尽管所有内容都限制在很小的范围内,但实际上是虚拟代理必须采取行动的单位(最好是合理的),但不时出现新的想法来改善人工智能的培训。
但是不仅学习算法很复杂。 环境也越来越难。 大多数强化学习环境非常简单,并且会激发探员探索世界的动力。 可能是必须完全规避迷宫才能找到出路的迷宫,或者可能是必须完成的迷宫游戏。
但是从长远来看,生物(合理而并非如此)不仅努力探索周围的世界。 但同时也要保留他们短暂(或并非如此)生命中的一切美好。
这称为动态平衡-身体维持恒定状态的愿望。 以一种或另一种形式,这对于所有生物都是普遍的。 伯克利的开发人员举了一个奇怪的例子:人类的所有成就大体上都是为了防止令人不愉快的意外。 防止环境熵不断增加。 我们建造的房屋保持恒温,不受天气变化的影响。 我们使用药物来保持健康等。
可以对此进行争论,但是在这个类比中确实存在某些东西。
你们问了一个问题-如果AI的主要动机是试图避免任何新颖性,将会发生什么? 换句话说,将混乱最小化是一种客观的学习功能。
他们将特工置于一个不断变化的危险世界中。
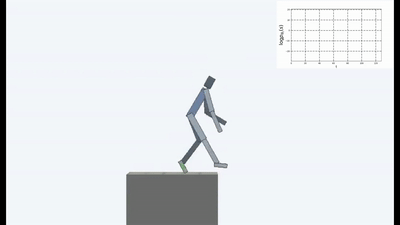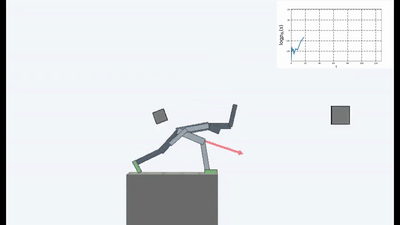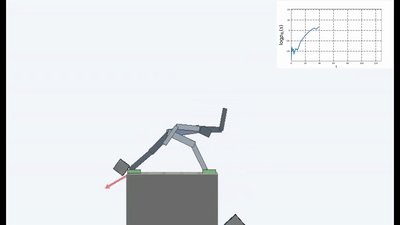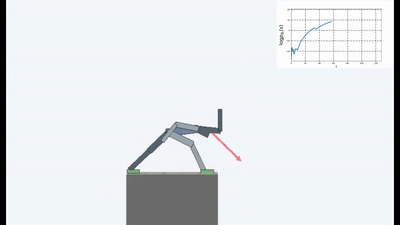
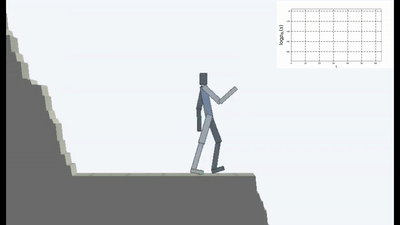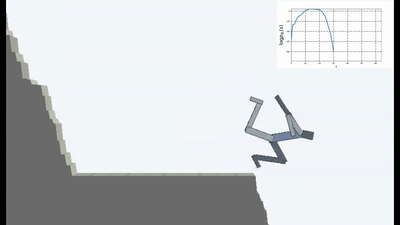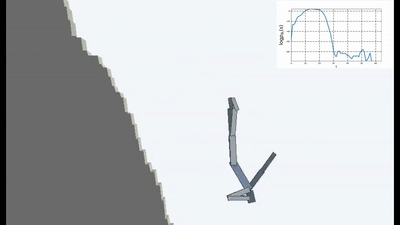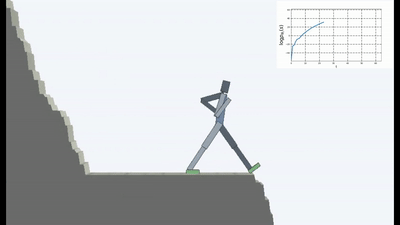
结果很有趣。 在许多情况下,这样的学习已经超越了基于课程的学习,而且就质量而言,往往比与老师学习更接近。 也就是说,要进行专门的培训才能达到特定的目标-赢得比赛,经历迷宫。
这当然是合乎逻辑的,因为如果您站在倒塌的桥上,然后继续站在桥上(以保持恒定并避免新的感觉落下),则需要不断远离边缘。 就像爱丽丝所说的那样,她全力以赴,保持静止不动。

实际上,在任何强化学习算法中,都有这样的时刻。 因为游戏中的死亡和剧集的结尾将受到负面奖励的惩罚。 或者,根据算法,通过降低代理商未从悬崖上连续掉下时可得到的最大报酬。
但这就是这种表达方式,当AI除了避免新颖性的愿望之外没有其他目标时,似乎它是第一次在强化学习中使用。
有趣的是,在这种动机下,虚拟代理学会了玩很多旨在取胜的游戏。 例如,俄罗斯方块。

或者是《毁灭战士》中的环境,您需要躲避飞行的火球并向接近的对手射击。 因为许多任务可以表述为保持稳定性的任务。 对于俄罗斯方块来说,这是保持领域空白的愿望。 屏幕是否一直充满? 哦,亲爱的,当它充满到最后会发生什么? 不,不,我们不需要这种幸福。 太震惊了。
从技术方面来说,它的安排非常简单。 当代理收到新状态时,他会评估此状态的熟悉程度。 也就是说,新状态包含在他先前访问的状态分布中。 代理人进入更熟悉的状态,获得的奖励越大。 学习策略的任务(如果有人不知道,这些都是强化学习的全部用语)是选择将导致过渡到最熟悉状态的操作。 另外,获得的每个新状态都用于更新与新状态进行比较的熟悉状态的统计信息。
有趣的是,在AI的过程中,我自发地了解了新的状态会影响被认为是新颖性的事物。 并且您可以通过两种方式实现熟悉的状态:进入已知状态。 或者进入一种状态,该状态将更新环境的持久性/熟悉性的概念,并且代理将处于一种新的状态,这种状态是由其行为所形成的,熟悉的状态。
这迫使行动者采取复杂的协调行动,即使生活中什么也不做。
矛盾的是,这导致了普通学习中的好奇心,并迫使特工探索他周围的世界。 突然某个地方有比现在和现在更安全的地方? 在这里,您可以完全沉迷于懒惰,什么也不做,从而避免出现任何问题和新感觉。 毫不夸张地说,这样的想法可能发生在我们当中。 对于许多人来说,这是生活中真正的动力。 尽管在现实生活中,我们当然都不需要处理俄罗斯方块。
老实说,这是一个复杂的故事。 但是实践证明它是有效的。 研究人员将该算法与基于好奇心的最佳代表进行了比较: ICM和RND 。 第一个是好奇心的有效机制,在强化学习中已经成为经典。 代理人不只是努力争取新的陌生状态,因此要寻求有趣的状态。 此类算法对情况的不熟悉程度是通过代理是否可以预测的来估算的(在早期,字面量是访问状态的计数器,但现在一切都归结为神经网络提供的积分估计值)。 但是,在这种情况下,树木上动静的叶子或电视上的白噪声对于这种媒介来说将具有无穷的新颖性,并会引起无尽的好奇心。 因为他无法在完全随机的环境中预测所有可能的新状态。
因此,在ICM中,代理仅寻求可以影响其行为的新状态。 AI会影响电视上的白噪声吗? 不行 没意思 如果您移动球,会影响球吗? 是的 所以玩球很有趣。 为此,ICM在反向模型中使用了一个非常酷的想法,将其与正向模型进行了比较。 在原始工作中有更多细节。
RND是好奇心机制的最新发展。 在实践中已经超过了ICM。 简而言之,神经网络正试图预测另一个神经网络的输出,该输出由随机权重启动并且永远不会改变。 假设情况越熟悉(馈入当前和随机启动的两个神经网络的输入),当前神经网络将越有能力预测随机启动的输出。 我不知道是谁发明了这一切。 一方面,我想和这样的人握手,另一方面,为这样的扭曲提供帮助。
但是,在许多情况下,在实践中,以一种方式或另一种方式进行有关维持体内平衡和避免任何新颖性的思想的培训比基于ICN或RND的课程获得了更好的最终结果。 图中反映了什么。
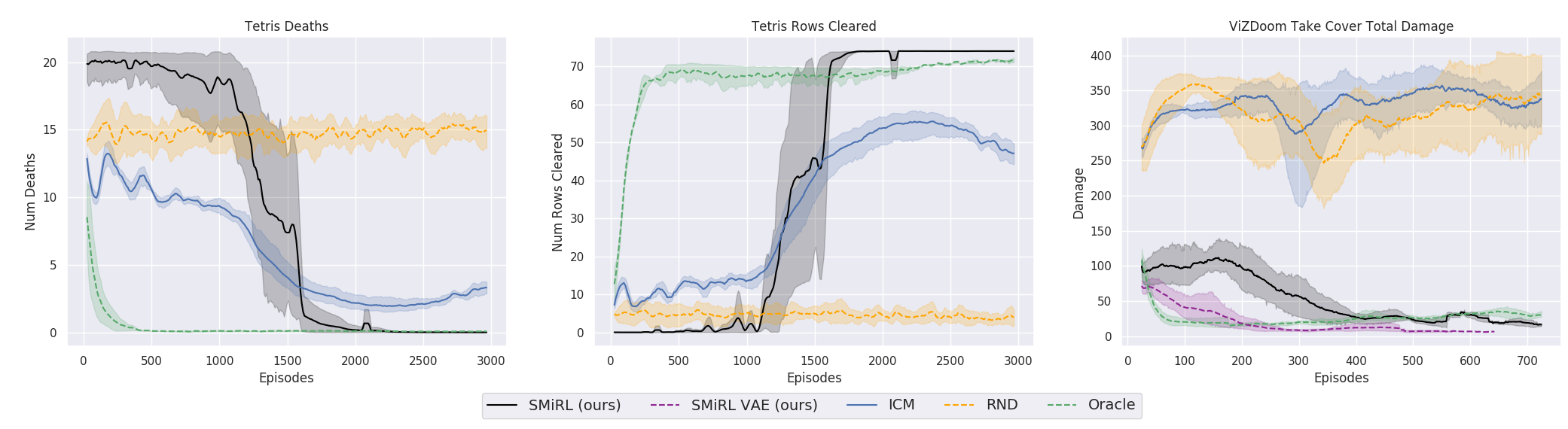
但是在这里有必要澄清一下,这仅适用于研究人员在工作中使用的环境。 它们是危险的,随机的,嘈杂的并且具有越来越大的熵。 在其中不执行任何操作确实会更有利可图。 当火球飞入您体内或您身后的桥开始坍塌时,它才偶尔主动移动。 但是,伯克利大学的研究人员显然从他们艰难的生活经历中坚持认为,这种环境比以前用于强化训练的环境更接近复杂的现实生活。 好吧,我不知道,我不知道。 在我的生活中,发现有来自怪物的火球飞向我和只有一个出口的无人迷宫,它们的发生频率大致相同。 但是不能否认的是,所提出的方法尽管非常简单,却显示出了惊人的效果。 也许将来应该将这两种方法合理地结合起来-长期保持稳态与保持正恒定性以及对当前环境研究的好奇心。
链接到原始作品