
当我们停止控制表的大小时,维护和使数据可用变得不容易。 我在生产中已经遇到过这样的问题,每天有更多的数据,表不适合内存,服务器响应了很长时间,但是找到了解决方案。
哈Ha! 我叫Diamond,现在我想分享一种方法来帮助我实现分区。
在PostgreSQL中分区
分区 (或称分区)是将一个大型逻辑表拆分为几个较小的物理部分的过程。 这就是帮助我们管理数据的原因。
例如:我们有一个“销售”表,该表以一个月为间隔进行划分,并且这些区域可以按区域划分为更小的子区域。
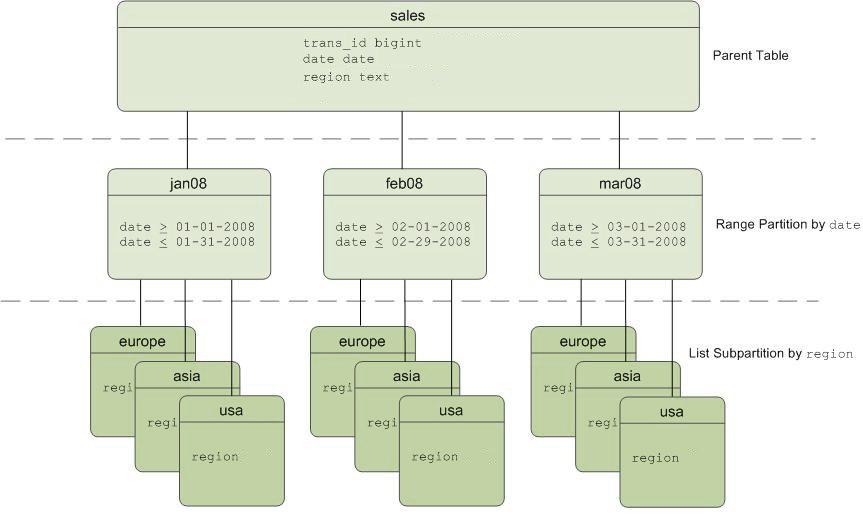 分区表“销售”模式
分区表“销售”模式这种方法的缺点:
-复杂的数据库结构。 数据库定义中的每个部分都是一个表,尽管它是一个逻辑实体的一部分。
-您不能将现有表转换为分区表,反之亦然。
-Postgres版本11中没有完全支持。
优点:
+性能。 在某些情况下,我们可以使用一组有限的节而无需遍历整个表,即使大型表的索引搜索也将变慢。 提高数据可用性。
+使用ATTACH / DETACH命令批量上传和删除数据。 这样可以节省我们VACUUM形式的开销。 这使您可以更有效地维护数据库。
+能够为该部分指定TABLESPACE。 这给了我们将数据传输到其他部分的机会,但是我们仍然在同一个实例中工作,并且主目录的元数据将包含有关部分的信息(不要与分片相混淆)
在PostgreSql中实现分区的2种方法:
1.表的继承(INHERITS)创建表时,我们说“从另一个(父)表继承”。 同时,我们在表中添加了数据管理限制。 通过这种方式,我们支持数据拆分的逻辑,但是这些逻辑上是不同的表。
在这里应该注意由Postgres Professional pg_pathman开发的扩展,它也通过表继承来实现分区。
CREATE TABLE orders_y2010 ( CHECK (log_date >= DATE '2010-01-01) ) INHERITS (orders);
2.声明式方法(PARTITION)表定义为声明性分区。 此解决方案出现在PostgreSql的版本10中。
CREATE TABLE orders (log_date date not null, …) PARTITION BY RANGE(log_date);
我选择了一种声明式方法。 这具有很大的优势-本机性,内核支持更多功能。 考虑在这个方向上的PostgreSQL开发:
 来源
来源但是PostgreSql继续发展,版本12支持链接到分区表。 这是一个重大突破。
我的方式
鉴于以上所述,一个
脚本是用PL / pgSQL编写的,该
脚本基于现有的
脚本创建了一个分区表,并将所有链接“抛出”到新表。 因此,我们基于现有的表获得了分区表,并像常规表一样继续使用该表。
该脚本不需要其他依赖关系,并且可以在它自己创建的单独电路中运行。 还记录重做和撤消操作。 该脚本解决了两个主要任务:创建一个分区表,并通过触发器触发器实现对其的外部链接。
脚本要求:PostgreSql v.:11及更高版本。
现在,让我们更详细地了解脚本。 界面非常简单:
有两个过程可以完成所有工作。
1.主要挑战-在此阶段,我们不会更改主表,但将在单独的方案中创建分段所需的所有内容:
call partition_run();
2.调用在主要工作中计划的延期任务:
call partition_run_jobs();
可以在多个线程中启动工作。 最佳线程数量接近分区表的数量。
脚本的输入参数 (_pt记录)

从内部脚本来看,主要动作:
-创建分区表
perform _partition_create_parent_table(_pt);
-创建部分
perform _partition_create_child_tables(_pt);
-复制该部分中的数据
perform _partition_copy_data(_pt);
-添加限制(工作)
perform _partition_add_constraints(_pt);
-恢复到外部表的链接
perform _partition_restore_referrences(_pt);
-恢复触发器
perform _partition_restore_triggers(_pt);
-创建事件触发器
perform _partition_def_tr_on_delete(_pt);
-创建索引(工作)
perform _partition_create_index(_pt);
-替换视图,版块链接(工作)
perform _partition_replace_view(_pt);
脚本的运行时间取决于许多因素,但主要因素是目标表的大小,关系数,索引和服务器特征。 就我而言,一个300Gb的表在不到一个小时的时间内就被分区了。
结果
我们得到了什么? 让我们看一下查询计划:
EXPLAIN ANALYZE select * from “sales” where dt BETWEEN '01.01.2019'::date and '14.01.2019'::date

与对常规表的查询相比,我们更快地从分区表中获得了结果,并使用了更少的服务器资源。
在此示例中,常规表和分区表位于同一基础上,并具有约200M记录。 鉴于我们无需重写应用程序代码即可获得加速,因此这是一个很好的结果。 对其他索引的查询也可以很好地工作,但是请记住:每当我们确定一个节时,结果就会快几倍,因为 PostgreSql可以在请求计划阶段丢弃多余的部分(
将enable_partition_pruning设置为on )。
总结
我设法在具有许多关系的表上实现分区并确保数据库完整性。 该脚本独立于特定的数据结构,可以重复使用。
PostgreSQL是世界上最先进的开源关系数据库!谢谢大家!
链接到源