新年越来越近,2010年代即将结束,这给世界带来了神经网络的轰动性复兴。 我被
一个简单的想法困扰
和剥夺了睡眠 :“一个人怎么可以回顾性地估计神经网络的发展速度?”对于“了解过去的人知道未来”。 不同算法的起飞速度有多快? 如何评估这一领域的进展速度并估计下一个十年的进展速度?

显然,您可以粗略计算出不同区域中的文章数。 该方法并不理想,您需要考虑子网域,但通常可以尝试。 我有个主意,在
Google Scholar(BatchNorm)上是很真实的! 您可以考虑新的数据集,也可以开设新的课程。 您的谦卑的仆人
经过各种选择后,选择了
Google趋势(BatchNorm) 。
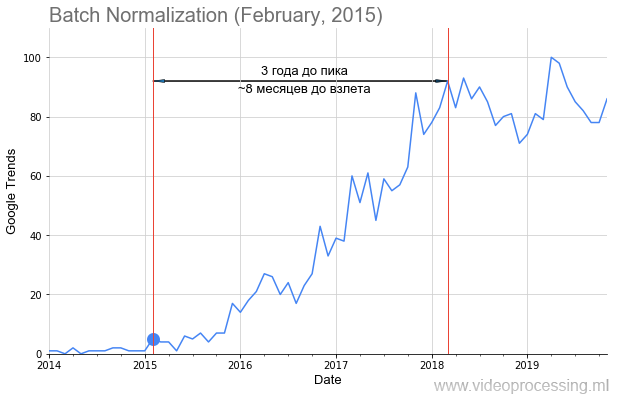
我和我的同事从主要的ML / DL技术中获取了请求,例如上图所示的
Batch Normalization ,在文章的发布日期上加上了一个点,并确定了该主题的受欢迎程度。 但是,并非所有这些都一样,小
路上散布着玫瑰,起飞像蝙蝠一样如此明显和美丽。 由于数据噪声,根本无法构建某些术语,例如正则化或跳过连接。 但总的来说,我们设法收集了趋势。
谁在乎发生了什么-欢迎切入!
而不是介绍或关于图像识别
这样啊 最初的数据非常嘈杂,有时会出现尖峰。
 资料来源: Andrei Karpaty twitter-学生站在庞大观众的过道中,听有关卷积神经网络的讲座
资料来源: Andrei Karpaty twitter-学生站在庞大观众的过道中,听有关卷积神经网络的讲座按照惯例,随着锐利峰的发展趋势的普及,
Andrey Karpaty可以为750人做一次具有传奇色彩的
CS231n:用于视觉识别的卷积神经网络演讲。 因此,使用简单的
框过滤器对数据进行了平滑处理(所有平滑处理在轴上都标记为“平滑处理”)。 由于我们有兴趣比较人气的增长速度-进行平滑处理后,所有数据均已归一化。 原来很有趣。 这是ImageNet上竞争的主要体系结构图:
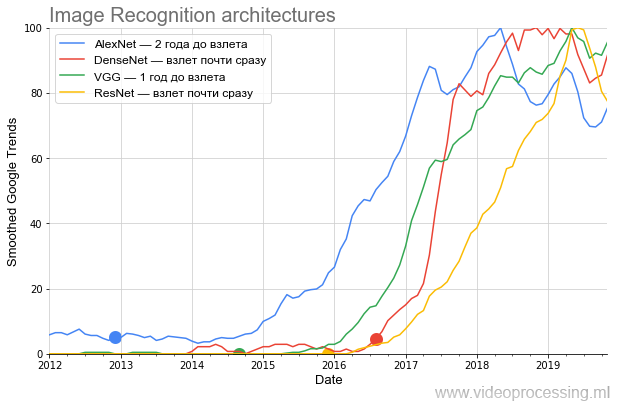 资料来源:下文-作者根据Google趋势得出的计算结果
资料来源:下文-作者根据Google趋势得出的计算结果该图非常清楚地显示,在
AlexNet轰动一时的出版物于2012年底酿造了当前神经网络炒作的稀饭之后,
尽管堆的断言只涉及相对狭窄的专家圈子,
但近两年来一直是沸腾
的 。 该主题仅在2014-2015年冬季才向公众发布。 请注意时间表从2017年开始的定期性:每年春季都达到顶峰。
在精神病学中,这被称为春季加重期。这是一个肯定的信号,表明该术语现在主要由学生使用,并且与受欢迎程度的峰值相比,平均而言,对AlexNet的兴趣下降。
此外,在2014年下半年,
VGG出现了。 顺便说一句,
VGG与
研究主管合着了我以前的学生
Karen Simonyan ,他现在在Google DeepMind(
AlphaGo ,
AlphaZero等)工作。 在第三年在莫斯科国立大学学习时,卡伦(Karen)实施了一种很好的
运动估计算法 ,该
算法已为2年制学生提供了12年的参考。 而且,那里的任务有些难以捉摸。 比较:
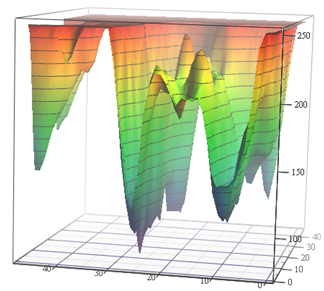
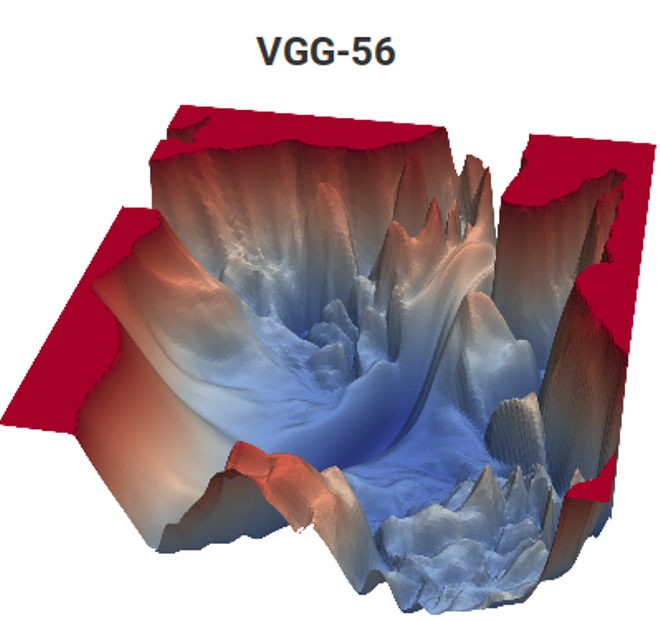 资料来源:运动估计任务的损失函数(作者材料)和VGG-56
资料来源:运动估计任务的损失函数(作者材料)和VGG-56在左侧,您需要根据输入数据在最小平凡的表面上找到最深的点,以进行最少的测量(可能有很多局部最小值),在右侧,您需要通过最少的计算找到一个较低的点(还有一堆局部最小值,并且该表面也取决于数据) 。 在左侧,我们获得了预测的运动矢量,而在右侧,则获得了经过训练的网络。 所不同的是,左侧仅是色彩空间的隐式度量,而右侧则是数以亿计的一对度量。 好吧,右边的计算复杂度大约高12个数量级(!)。 有点像……但是第二年,即使完成一个简单的任务,也像……[被审查制度淘汰]。 过去15年中,由于未知原因,昨天在校学生的编程水平显着下降。 他们必须说:“您会做得很好,他们会将您带到DeepMind!” 人们可能会说“发明VGG”,但出于某种原因“他们会进入DeepMind”的动机更好。 显然,这是经典的“您将吃粗面粉,您将成为一名宇航员!”的现代高级类似物。 但是,在我们的案例中,如果我们算出该国的儿童人数和宇航员的人数,则机会要高出数百万倍,因为我们中的两个人已经在我们实验室的DeepMind工作。
接下来是
ResNet ,打破了层数限制,六个月后开始起飞。 最后,DenseNet出现在炒作的开始,它几乎立即起飞,甚至比ResNet还酷。
如果我们要谈论流行度,我想在网络流行度还取决于网络的特性和性能方面加几句话。 如果您看一下如何根据网络上的操作数来预测
ImageNet类,布局将是这样的(
从高到低 -更好):
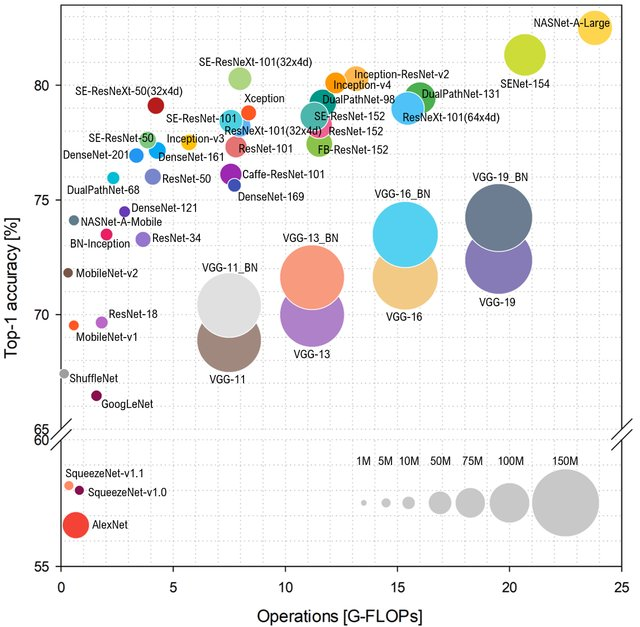 资料来源: 代表性深度神经网络架构的基准分析
资料来源: 代表性深度神经网络架构的基准分析类型AlexNet不再是蛋糕,它们统治基于ResNet的网络。 但是,如果您对
FPS的实际评估离我的心脏较近,则可以清楚地看到VGG在此处更接近最佳值,并且通常,对齐方式会发生明显变化。 在帕累托最优包络上意外地包含AlexNet(水平标度是对数的,在上方和右侧更好):
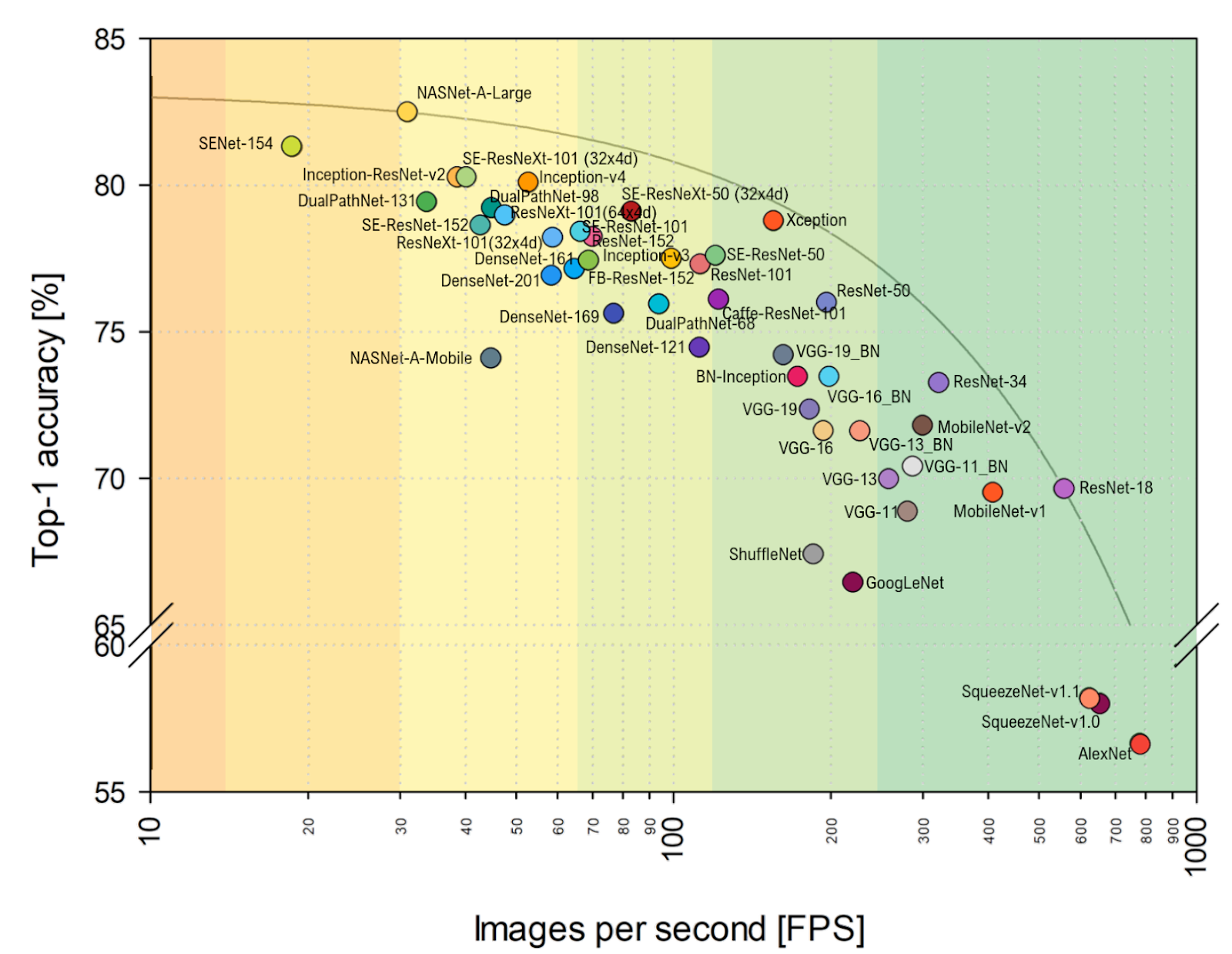 资料来源: 代表性深度神经网络架构的基准分析总计:
资料来源: 代表性深度神经网络架构的基准分析总计:
- 在未来的几年中,由于神经网络加速器的进步 ,当某些架构搁浅而有些突然起飞时,仅由于最好放下新硬件,架构的对齐方式将发生非常显着的变化。 例如, 在上述文章中 ,在NVIDIA Titan X Pascal和NVIDIA Jetson TX1板上进行了比较,并且布局发生了明显变化。 同时,TPU,NPU等的发展才刚刚开始。
- 作为一名从业者,我不禁会注意到,默认情况下,在ImageNet上进行的比较是在ImageNet-1k上进行的,而不是在ImageNet-22k上进行的,这仅仅是因为大多数人都在ImageNet-1k上训练了他们的网络,而该网络上的班级少了22倍(既方便又快捷)。 切换到与许多实际应用更相关的ImageNet-22k,也会改变对齐方式(对于那些锐化了1k的用户)。
更深入的技术和架构
但是,回到技术上。
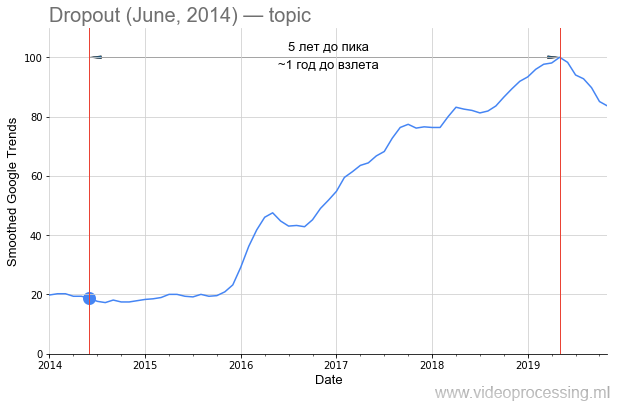
辍学一词作为搜索词非常嘈杂,但5倍增长显然与神经网络有关。 随着
Google专利和新方法的出现,对它的兴趣下降的可能性最大。 请注意,从
原始文章的发布到对该方法的兴趣激增已经过去了一年半的时间:
但是,如果我们谈论流行度上升之前的时期,那么在DL中,
循环网络和
LSTM显然是第一位:
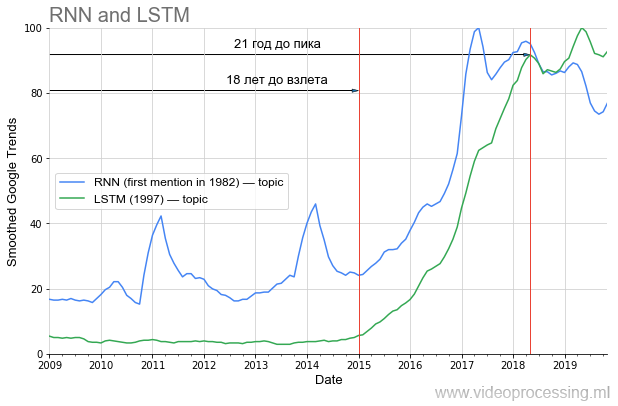
距离目前的流行高峰已经过去了20年,如今,机器翻译和基因组分析的使用已经大大改善,并且在不久的将来(如果从我所在的地区带走),具有相同视觉质量的YouTube,Netflix流量将下降两倍。 如果您正确地学习了历史教训,很显然,当前文章中的部分思想只有在20年后才会“腾飞”。 过上健康的生活方式,多保重自己,您会亲身经历!
现在更接近承诺的炒作。
GAN像这样起飞:
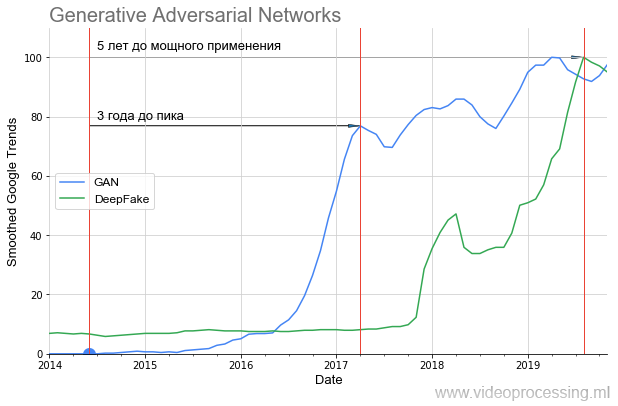
可以清楚地看到,近一年来一直保持沉默,直到2016年,两年后才开始急剧上升(结果明显改善了)。 一年后的这次起飞带来了轰动的DeepFake,但它也起飞了1.5年。 就是说,即使是非常有前途的技术,也需要大量的时间才能从构思到每个人都可以使用的应用程序。
如果您查看
原始文章中 GAN生成的图片以及使用
StyleGAN可以生成的图片,那么很明显为什么会出现这种沉默。 在2014年,只有专家才能评估其凉爽程度-从本质上讲,将另一个网络作为损失函数来进行训练。 在2019年,每个小学生都可以体会到这有多酷(没有完全了解这是如何做到的):

如今,神经网络成功解决
了许多不同的问题,您可以采用最佳网络并为每个方向建立流行度图表,处理噪声和搜索查询的峰值等。 为了避免在树上散布我的思想,我们将以分割算法为主题来结束本次选择,在过去的一年半中,
无休止的/膨胀的卷积和
ASPP的思想
在算法基准测试中颇为
火爆 :
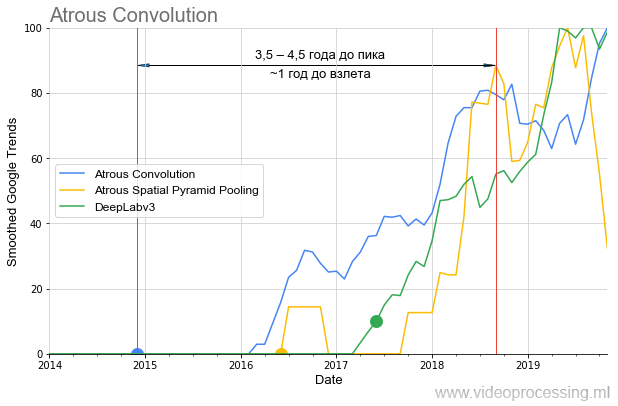
还应该注意的是,如果
DeepLabv1超过一年才“等待”普及,那么
DeepLabv2会在一年后起飞,而
DeepLabv3几乎会立即
起飞 。 即 总的来说,我们可以谈论随着时间的推移促进兴趣的增长(或者,加速对著名作者的技术的兴趣的增长)。
所有这些共同导致了以下全球问题的产生-有关该主题的出版物数量激增:
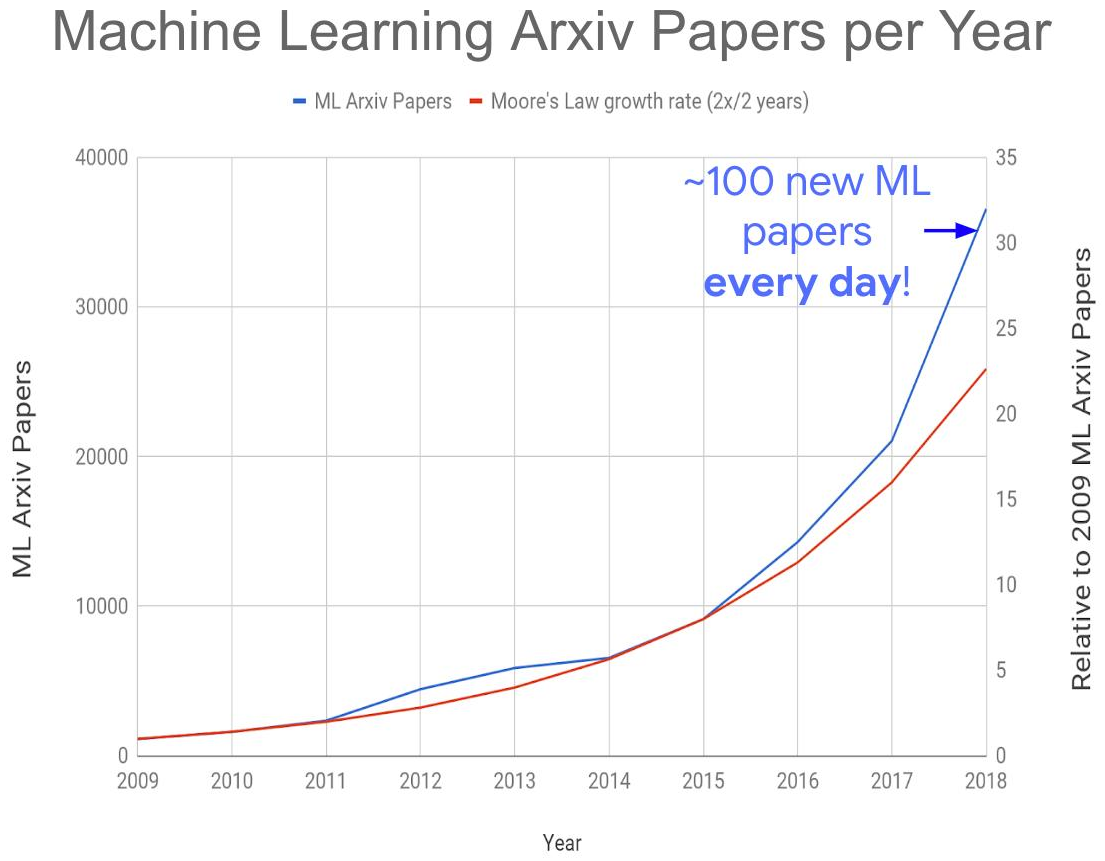 资料来源: 机器学习论文太多?
资料来源: 机器学习论文太多?考虑到不是所有的文章都在arXiv-e上发表,今年我们每天都会收到150-200篇文章。 今天即使在自己的子区域中阅读文章也是完全不可能的。 结果,许多有趣的想法肯定会被埋在新出版物的废墟下,这将影响它们“起飞”的时间。 但是,该地区雇用的合格专家人数的
爆炸性增长也使得解决该问题的希望渺茫。
总计:
- 除了ImageNet和DeepMind游戏成功的幕后故事外,GAN还引发了神经网络普及的新浪潮。 有了他们,确实有可能在不使用相机的情况下“拍摄”演员 。 以及是否还会有更多! 在这种信息噪音的情况下,将减少声音的减少,但将提供相当有效的处理和识别技术。
- 由于出版物太多,我们期待出现新的神经网络方法来快速分析文章,因为只有它们才能为我们省钱(一个笑话,只有一个笑话!)。
工作机器人,快乐的人
两年来,AutoML
在报纸上越来越受欢迎。 从传统上来说,这一切都始于ImageNet,在ImageNet中,他以Top-1 Accuracy稳固地获得了第一名:
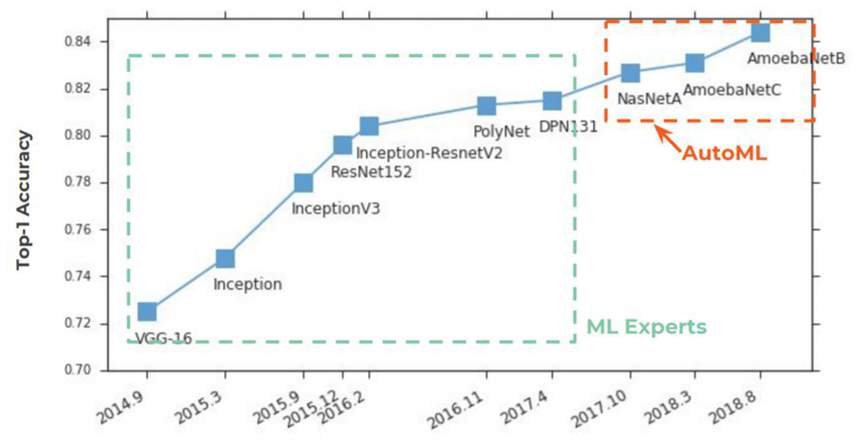
AutoML的本质非常简单,其中一个实现了一个世纪的数据科学家的梦想就已经实现了-神经网络选择超参数。 这个想法引起了轰动:
在图表的下方,我们看到了一种非常罕见的情况,即在
NASNet和
AmoebaNet上的初始文章发表后,它们几乎立即以以前的想法为标准开始受到欢迎(对该主题的巨大兴趣受到影响):
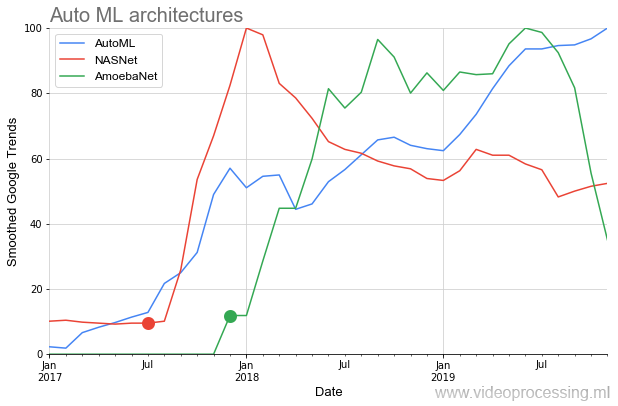
田园诗般的风景被两点宠坏了。 首先,有关AutoML的任何讨论都以以下短语开头:“如果您有GPU dofigalion ...”。 这就是问题所在。 Google当然声称使用
Cloud AutoML可以轻松解决这一问题,
主要是您有足够的资金 ,但并非所有人都同意这种方法。 其次,到目前为止,它还不
完美 。 另一方面,回顾GAN,五年还没有过去,这个想法本身看起来非常有前途。
无论如何,AutoML的主要发展将始于下一代用于神经网络的硬件加速器,实际上是改进的算法。
 资料来源:Dmitry Konovalchuk的图片,作者的资料总计:实际上,数据科学家当然不会度过一个永恒的假期,因为在很长的一段时间内,数据仍然会令人头疼。 但是在新年和2020年代初之前,为什么不做梦呢?
资料来源:Dmitry Konovalchuk的图片,作者的资料总计:实际上,数据科学家当然不会度过一个永恒的假期,因为在很长的一段时间内,数据仍然会令人头疼。 但是在新年和2020年代初之前,为什么不做梦呢?关于工具的几句话
研究的有效性在很大程度上取决于工具。 如果要对AlexNet进行编程,而您又需要不平凡的编程,那么今天,可以在新框架的多行中收集这样的网络。
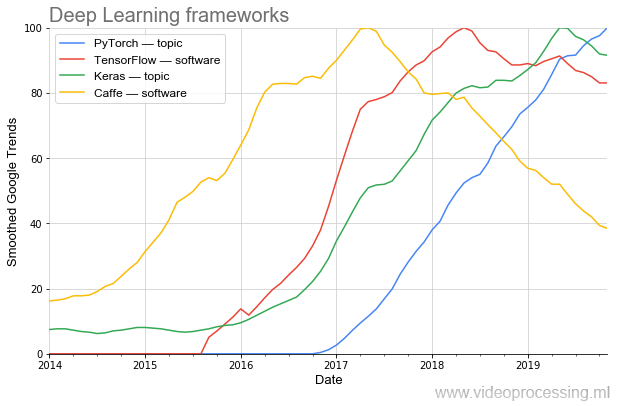
可以清楚地看到,流行程度是如何变化的。 如今,最受欢迎的(包括
根据PapersWithCode得出的 )是
PyTorch 。 而且一旦流行的
Caffe精美漂亮地离开了。 (注意:主题和软件意味着在进行绘制时使用了Google的主题过滤功能。)
好吧,由于我们接触了开发工具,因此值得一提的是用于加速网络执行的库:
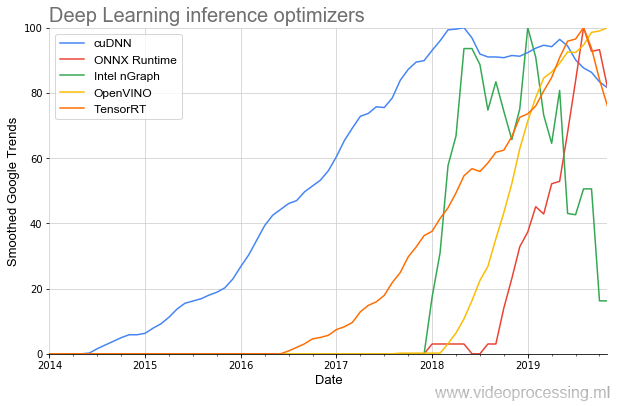
该主题中最早的是(尊重NVIDIA)
cuDNN ,对于开发人员而言,幸运的是,在过去的几年中,库的数量已增长了数倍,并且它们的流行开始变得越来越陡峭。 看来这一切仅仅是个开始。
总计:即使在过去三年中,工具也已经发生了重大变化,使情况变得更好。 3年前,按照今天的标准,它们根本不存在。 进度很好!预期的神经网络前景
但是,乐趣会在以后开始。 今年夏天,我在
另一篇大文章中详细描述了为什么CPU甚至GPU效率不足以与神经网络一起工作,为什么数十亿美元投入到新芯片的开发中以及前景如何。 我不会重复自己。 以下是上一章的概括和补充。
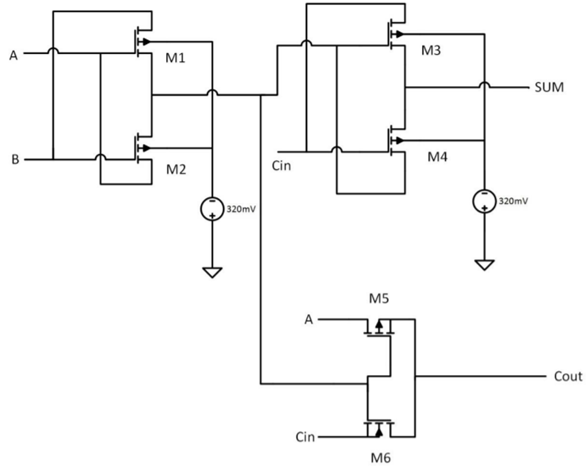
首先,您需要了解神经网络计算与熟悉的von Neumann架构中的计算之间的差异(当然可以在其中进行计算,但效率较低):
 资料来源:Dmitry Konovalchuk的图片,作者的资料
资料来源:Dmitry Konovalchuk的图片,作者的资料上一次,主要讨论围绕FPGA / ASIC,并且不准确的计算几乎没有引起注意,因此让我们更详细地讨论它们。 减少下一代芯片的巨大前景正好是不准确读取(以及在本地存储系数数据)的能力。 实际上,当将网络权重转换为整数并进行量化(但以新的级别)时,粗化实际上也用于精确算术中。 举个例子,考虑一下一位加法器(这个例子很抽象):
 资料来源: 采用新型两个晶体管(2T)XOR门的高速和低功耗8位x 8位乘法器设计
资料来源: 采用新型两个晶体管(2T)XOR门的高速和低功耗8位x 8位乘法器设计他需要6个晶体管(有不同的方法,所需的晶体管数量可能越来越少,但总的来说是这样的)。 对于8位,大约需要
48个晶体管 。 在这种情况下,模拟加法器仅需要2个(两个!)晶体管,即 少24倍:
 资料来源: 模拟乘法器(模拟集成电路的分析和设计)
资料来源: 模拟乘法器(模拟集成电路的分析和设计)如果精度更高(例如,等同于数字10或16位),则差异将更大。 更有趣的是乘法的情况! 如果一个数字8位多路复用器需要大约
400个晶体管 ,则模拟6,即5。 少67倍(!)。 当然,从电路的角度来看,“模拟”和“数字”晶体管有很大的不同,但是这个想法很明确-如果我们设法提高模拟计算的精度,那么当我们需要少两个数量级的晶体管时,我们很容易就会遇到这种情况。 重点并不是减小尺寸(这对于“摩尔定律的放慢”很重要),而是减小功耗,这对移动平台至关重要。 对于数据中心来说,这不是多余的。
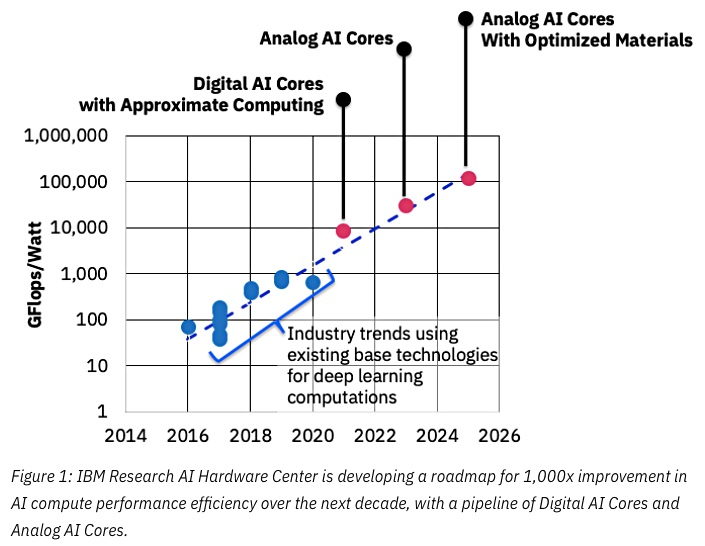 资料来源: IBM认为模拟芯片可以加速机器学习
资料来源: IBM认为模拟芯片可以加速机器学习成功的关键在于降低准确性,而IBM再次站在最前沿:
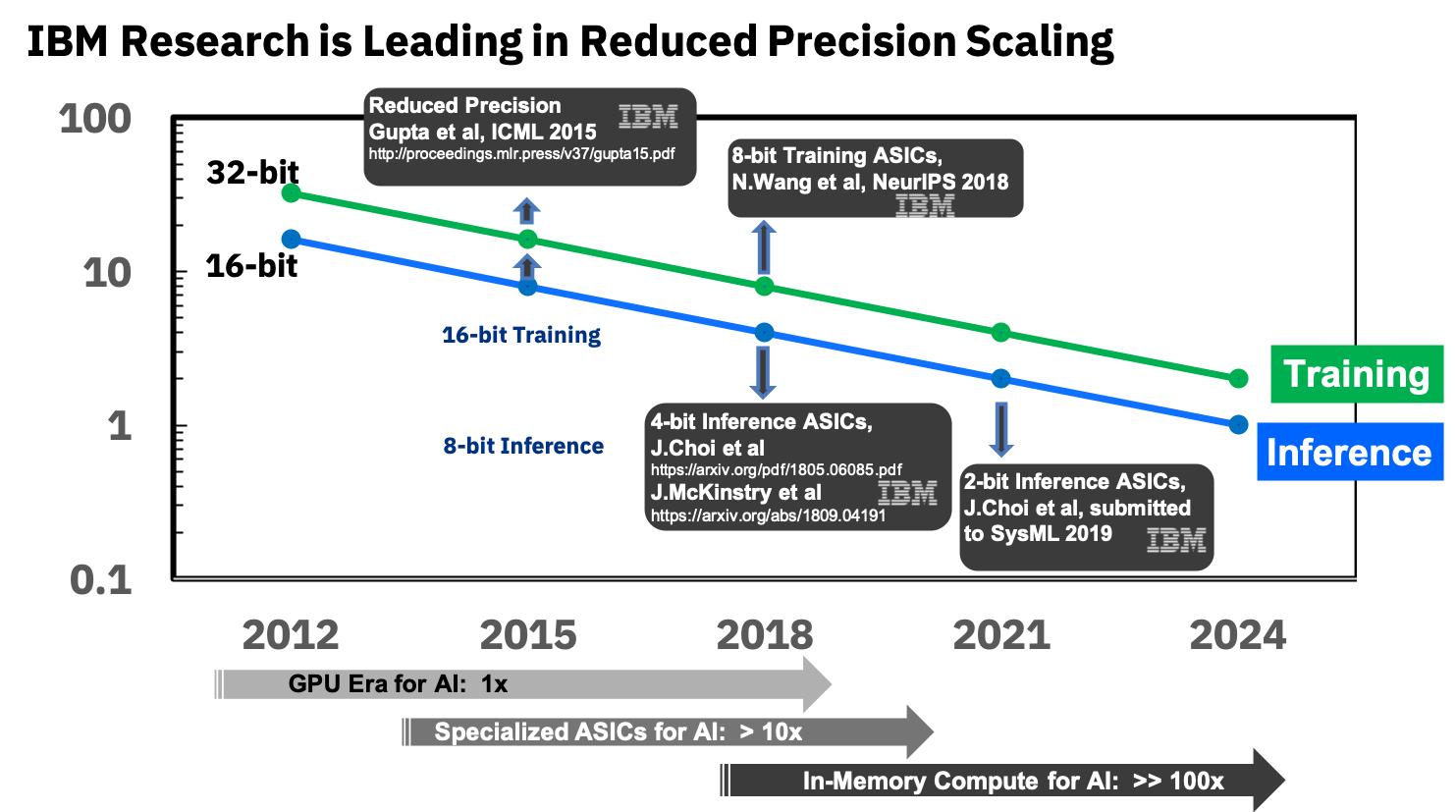 来源: IBM Research博客:用于训练深度学习系统的8位精度
来源: IBM Research博客:用于训练深度学习系统的8位精度他们已经从事用于神经网络的专用ASIC,与GPU相比,它们具有10倍以上的优势,并计划在未来几年内实现100倍的优势。 看起来非常令人鼓舞,我们真的很期待,因为我重申,这将是移动设备的突破。
同时,尽管取得了重大成功,但情况并非如此神奇。 这是对当前神经网络的移动硬件加速器的一个有趣的测试(图片是可点击的,再次以每秒的图片数显示了作者的灵魂):
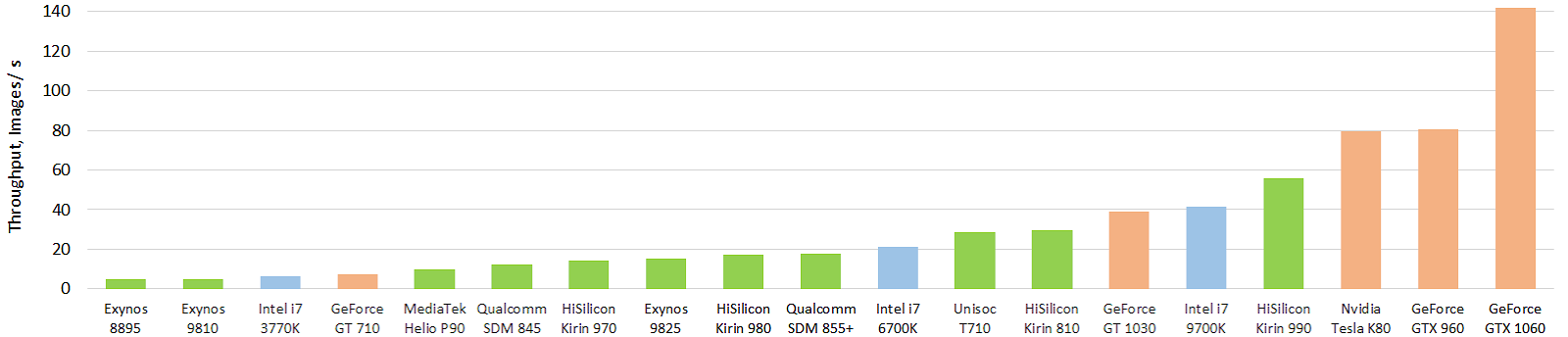 来源: 移动AI加速器的性能演变:浮动Inception-V3模型(使用TensorFlow Lite和NNAPI的FP16模型)的图像吞吐量
来源: 移动AI加速器的性能演变:浮动Inception-V3模型(使用TensorFlow Lite和NNAPI的FP16模型)的图像吞吐量绿色表示移动芯片,蓝色表示CPU,橙色表示GPU。 可以明显看出,当前的移动芯片,首先是华为的高端芯片,已经超过了CPU尺寸(和功耗)的数十倍。 而且很结实! 有了GPU,到目前为止,一切都不是那么神奇,但是还会有其他东西。 您可以在单独的网站
http://ai-benchmark.com/上更详细地查看结果,请注意此处的“测试”部分,他们选择了一套不错的算法进行比较。
总计:当今模拟加速器的进展很难评估。 有一场比赛。 但是产品尚未问世,因此出版物相对较少 。 您可以监视延迟出现的专利(例如, 来自IBM的大量销售 )或监视其他制造商的稀有专利 。 看来这将是一场非常严肃的革命,主要是在智能手机和服务器TPU中。而不是结论
当我们不编写程序而是插入一个块并对其进行训练时,今天的ML / DL被称为一种新的编程技术。 即 就像最初有一个汇编器,然后是C,然后是C ++,现在,经过30多年的等待,下一步是ML / DL:
那是有道理的。 最近,在先进的公司中,程序决策位置已被神经网络所取代。 即 « IF-» (!) , 3-5 . , , . ,
, , , , , . -!
, . , - , : « , !»
, , , , (, !) . : « , !» , . «» « !» ( ). . !
, ML/DL — , . :
- — ,
- — ,
- — ,
- 8K 2K — ,
- , — ,
- 10 ,
- — ,
- — - — ,
- — ! )

由于使用BatchNorm(2015)和skip connections(2015),人们在很多方面学会了训练真正的深度神经网络,仅过去了4年,而从他们“开始”开始已经过去了3年,我们真的在阅读他们的工作成果没有看到。 现在他们将到达产品。 某些事情告诉我们,在未来几年中,许多有趣的事情在等待着我们。 特别是当加速器“起飞”时...

从前,如果有人记得,普罗米修斯从奥林匹斯山偷走了火,并将其移交给了人们。 愤怒的宙斯与其他神灵共同创造了一个名叫潘多拉(Pandora)的女性男人的第一美,潘多拉拥有许多出色的女性特质
(我突然意识到,从政治上正确地重述古希腊的某些神话非常困难) 。 潘多拉被送往人们,但是怀疑有问题的普罗米修斯拒绝了她的咒语,而他的兄弟埃皮米修斯则没有。 作为婚礼的礼物,宙斯送了一个美丽的棺材给水星,一个善良的灵魂水星履行了命令-他把棺材交给了Epimetheus,但警告他无论如何都不要打开它。 好奇的潘多拉(Pandora)从丈夫那里偷了棺材,打开了棺材,但只有罪恶,疾病,战争和其他人类问题。 她试图关闭棺材,但为时已晚:
 资料来源: 艺术家弗雷德里克·斯图亚特·丘奇(Frederick Stuart Church),潘朵拉的盒子
资料来源: 艺术家弗雷德里克·斯图亚特·丘奇(Frederick Stuart Church),潘朵拉的盒子从那时起,“打开潘多拉魔盒”一词就消失了,也就是说,
出于好奇而进行
了不可逆的动作,其后果可能不如外部棺材上的装饰精美。
您知道,我越深入神经网络,就越觉得这是另一个潘多拉盒子。 但是,人类在打开这种盒子方面拥有最丰富的经验! 从最近最近-这是核能和互联网。 因此,我认为我们可以一起应对。 难怪揭幕
战中一群残酷的
大胡子男人。 好吧,棺材很漂亮,同意! 并非只有麻烦,已经获得了很多好处。 因此,他们走到了一起,……我们将进一步开放!
总计:
- 本文没有包含许多有趣的主题,例如经典的ML算法,转移学习,强化学习,数据集的流行性等。 (先生们,您可以继续这个话题!)
- 关于棺材的问题:我个人认为使Google 放弃与五角大楼的100亿美元合同 的Google程序员是伟大而英俊的。 他们尊重和尊重。 但是,请注意,有人赢得了这次大招标。
另请阅读:
总体而言,尤其是在2020年,尤其是在新年期间,所有大量新的有趣发现 !
致谢
我衷心感谢:
- 莫斯科国立大学计算机图形学与多媒体VMK实验室 MV 罗蒙诺索夫不仅对俄罗斯深度学习的发展做出了贡献
- 康斯坦丁(Konstantin Kozhemyakov)和德米特里(Dmitry Konovalchuk)做出了很多努力,以使本文变得更好,更直观,
- 最后,非常感谢Kirill Malyshev,Yegor Sklyarov,Nikolai Oplachko,Andrey Moskalenko,Ivan Molodetsky,Evgeny Lyapustin,Roman Kazantsev,Alexander Yakovenko和Dmitry Klepikov所做的许多有益的评论和更正,使本文更加完善!