
再次介绍检测对象的任务。 优先级-速度可接受的精度。 您将采用YOLOv3的体系结构并进行培训。 精度(mAp75)大于0.95。 但是运行速度仍然很低。 地狱
今天,我们将绕过量化。 在削减的范围内,考虑进行模型修剪 -修剪冗余网络部分以加快推理速度而又不损失准确性。 从视觉上看-在哪里切割多少。 让我们弄清楚如何手动执行操作以及在何处可以实现自动化。 最后是在keras上的存储库。
引言
在工作的最后一个地方,Perm Macroscop,我养成了一个习惯-总是监视算法的执行时间。 网络运行时间应始终通过适当性过滤器进行检查。 通常,产品中的最新技术不会通过此过滤器,这导致我无法进行修剪。
修剪是一个古老的主题,在2017年的斯坦福演讲中曾谈到过 。 主要思想是通过删除各种节点来减少训练网络的大小而不会损失准确性。 听起来很酷,但是我很少听说它的用法。 可能没有足够的实现,没有俄语文章,或者只是每个人都认为修剪专有技术和保持沉默。
但是请分开
生物学研究
我喜欢深度学习中的想法来自生物学。 它们像进化一样可以被信任(您知道ReLU与激活大脑神经元的功能非常相似吗?)
模型修剪过程也接近生物学。 此处的网络响应可以与大脑的可塑性进行比较。 Norman Dodge的书中有几个有趣的例子:
- 一个刚出生时只有一半的女人的大脑重新编程以执行缺失的一半的功能
- 这个家伙向自己射击了负责视觉的大脑部分。 随着时间的流逝,大脑的其他部分将接管这些功能。 (请勿重试)
因此,您可以从模型中切除一些弱束。 在极端情况下,剩余的捆束将有助于更换切好的捆束。
您喜欢转学还是从头学习?
选项一。 您正在Yolov3上使用转移学习。 视网膜,Mask-RCNN或U-Net。 但是通常,我们不需要像COCO中那样识别80类对象。 在我的实践中,所有课程仅限于1-2节课。 可以假定这里有80个类的体系结构是多余的。 让人想到需要减少体系结构。 此外,我希望做到这一点而又不会失去现有的预先训练的体重。
选项二。 也许您拥有大量的数据和计算资源,或者您只需要一个超级定制的体系结构。 没关系 但是您从头开始学习网络。 通常的顺序是查看数据结构,选择一种功耗降低的架构,并从重新训练中减少辍学。 我看到辍学0.6,卡尔。
在两种情况下,都可以减少网络。 晋升。 现在让我们找出哪种 包皮环切术 修剪
通用算法
我们决定可以消除卷积。 看起来很简单:
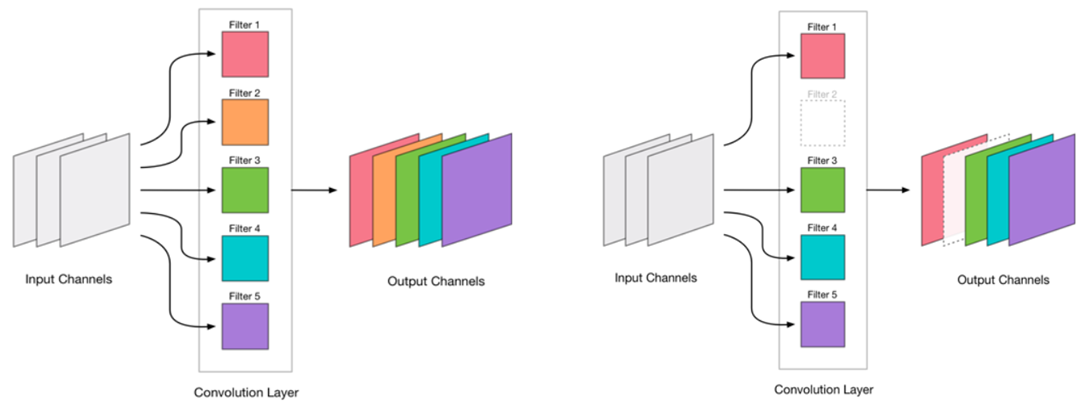
消除任何卷积是网络的压力,通常会导致误差增加。 一方面,这种错误增长表明我们如何正确消除卷积(例如,大的增长表明我们做错了什么)。 但是小的增长是完全可以接受的,并且通常通过随后使用小LR进行简单的进一步培训来消除。 我们添加了重新训练的步骤:
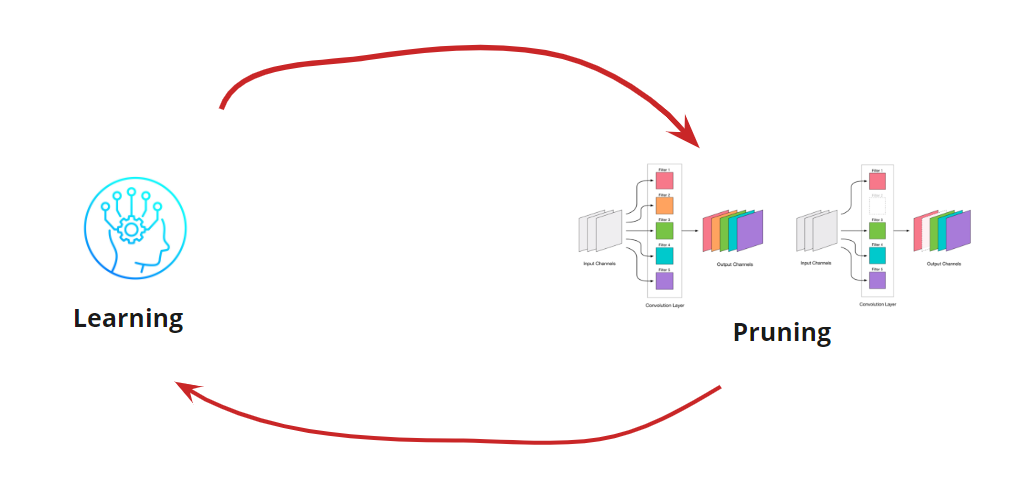
现在我们需要了解何时停止学习<->修剪周期。 当我们需要将网络缩小到一定规模和运行速度时(例如,对于移动设备),可能会有一些特殊的选择。 但是,最常见的选择是继续循环,直到误差变得大于允许的误差为止。 添加条件:
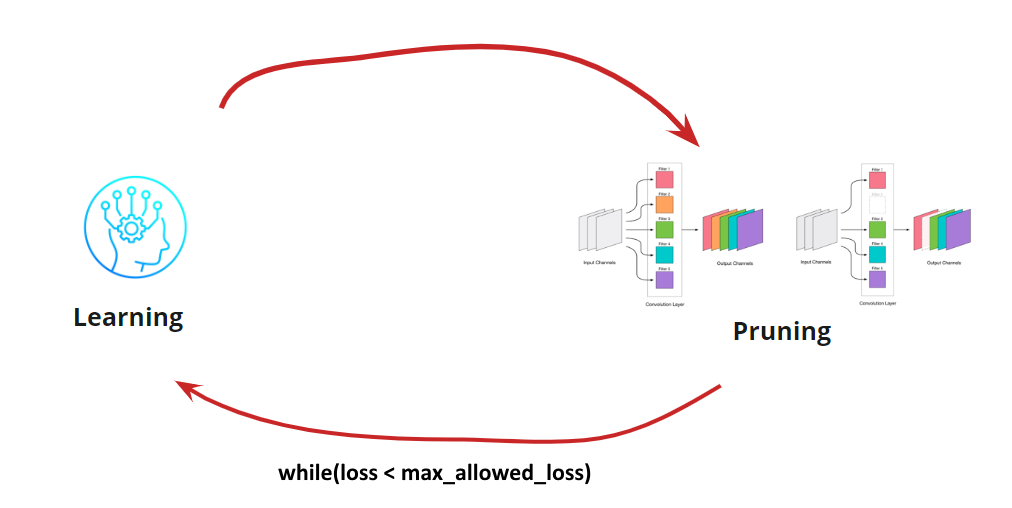
因此,算法变得清晰。 如何确定删除的卷积还有待分解。
搜索要删除的卷积
我们需要消除一些卷积。 尽管它会起作用,但先撕掉并“击退”是一个坏主意。 但是,如果您有头脑,您可以考虑并尝试选择“弱”卷积进行去除。 有几种选择:
- 最小的L1度量或low_magnitude_pruning 。 小权重的卷积对最终决策的贡献很小
- 考虑到平均值和标准偏差的最小L1度量。 我们补充对分布性质的评估。
- 掩盖卷积并消除影响最小的结果精度 。 微不足道的卷积的更准确定义,但非常耗时且占用大量资源。
- 其他
每个选项都具有生命权及其自己的实现功能。 在这里,我们考虑L1度量最小的变量
YOLOv3的手动处理
原始体系结构包含残留块。 但是,无论深度网络多么酷,它们都会在一定程度上阻碍我们的发展。 困难在于您无法在这些图层中删除具有不同索引的对帐:

因此,我们选择可以自由删除对帐的图层:
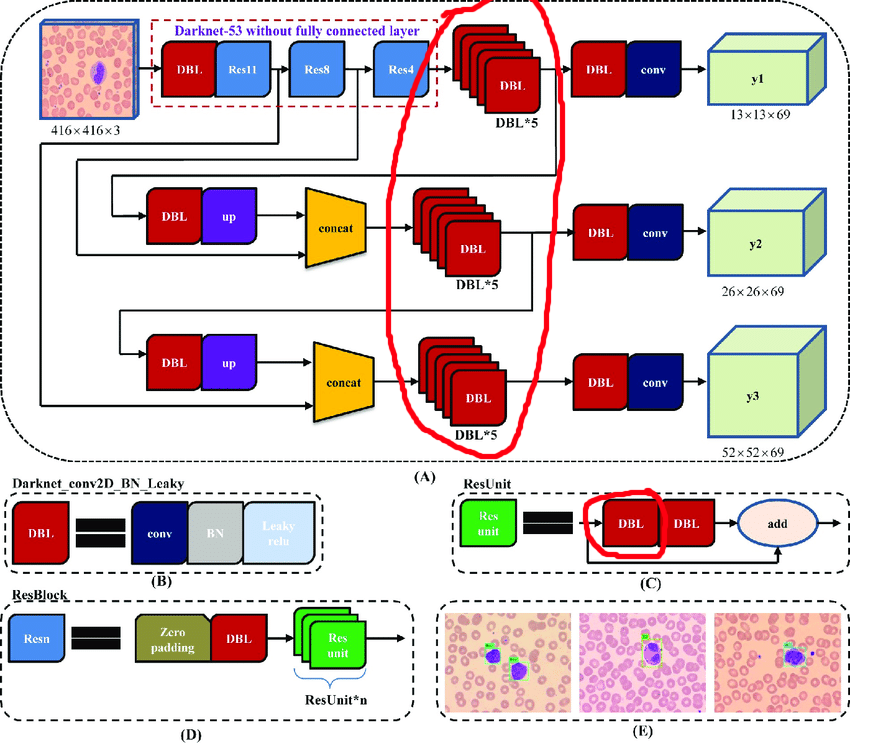
现在让我们建立一个工作周期:
- 卸载激活
- 我们想知道削减多少
- 切出
- 通过LR = 1e-4学习10个时代
- 测试中
卸载卷积对于评估我们可以在特定步骤中删除的部分很有用。 卸载示例:

我们发现几乎到处都有5%的卷积具有非常低的L1范数,我们可以将其删除。 在每个步骤中,都要重复进行这样的卸载,并评估哪些层以及可以切割多少层。
整个过程分4个步骤完成(此处和所有RTX 2060 Super的编号):
在第2步中,添加了一个积极的效果-补丁大小4进入了内存,大大加快了重新训练的过程。
在第4步,该过程已停止,因为 甚至长时间的继续教育也无法将mAp75提高到旧值。
结果,我们设法将推理速度提高了15% ,将尺寸减小了35%,并且没有损失准确性。
自动化实现更简单的架构
对于更简单的网络体系结构(无条件添加,合并和残差块),完全有可能专注于处理所有卷积层并使切割卷积的过程自动化。
我在这里实现了这个选项。
很简单:您只有损失函数,优化器和批处理生成器:
import pruning from keras.optimizers import Adam from keras.utils import Sequence train_batch_generator = BatchGenerator... score_batch_generator = BatchGenerator... opt = Adam(lr=1e-4) pruner = pruning.Pruner("config.json", "categorical_crossentropy", opt) pruner.prune(train_batch, valid_batch)
如有必要,您可以更改配置参数:
{ "input_model_path": "model.h5", "output_model_path": "model_pruned.h5", "finetuning_epochs": 10, # the number of epochs for train between pruning steps "stop_loss": 0.1, # loss for stopping process "pruning_percent_step": 0.05, # part of convs for delete on every pruning step "pruning_standart_deviation_part": 0.2 # shift for limit pruning part }
另外,实施基于标准偏差的限制。 目标是限制一部分已删除的卷,不包括具有“足够” L1量度的卷积:
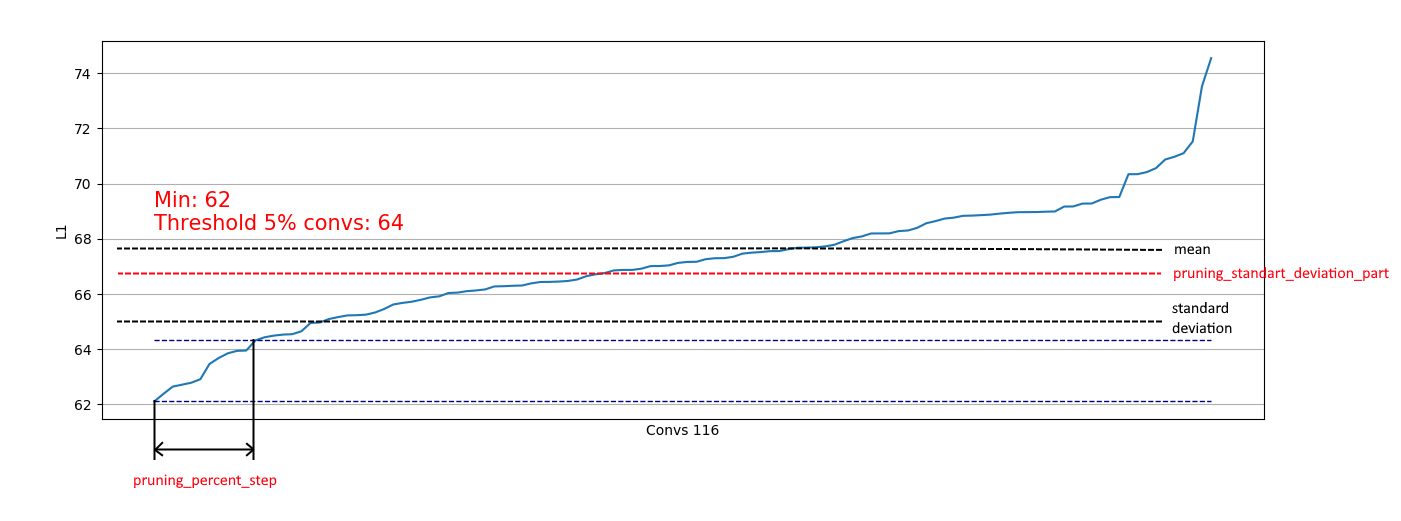
因此,我们只能从类似于右侧的分布中删除弱卷积,而不会影响从类似于左侧的分布中删除:

当分布接近正态时,可以从以下中选择系数pruning_standart_deviation_part:

我建议使用2 sigma的假设。 否则您将无法专注于此功能,而将值保留为<1.0。
输出是整个测试的网络大小,损耗和网络运行时间的图形,标准化为1.0。 例如,这里的网络大小几乎减少了2倍,而没有质量损失(小型卷积网络,权重为10万):
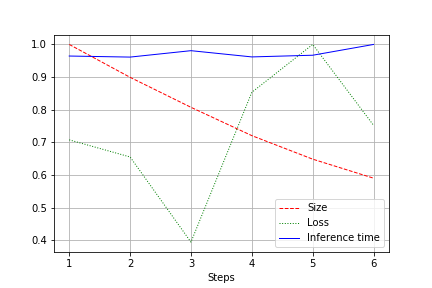
运行速度受正常波动的影响,并没有太大变化。 对此有一个解释:
- 卷积的数量从方便(32、64、128)变为不是最方便的视频卡-27、51等。 在这里,我可能会误会,但很可能会造成影响。
- 该体系结构不是广泛的,而是一致的。 减小宽度,我们不触摸深度。 因此,我们减少了负载,但不改变速度。
因此,改进表示为运行期间CUDA的负载减少了20-30%,而不是运行时间的减少
总结
反映。 我们考虑了2种修剪选项-YOLOv3(需要手动操作时)和架构更简单的网络。 可以看出,在两种情况下都可以在不损失准确性的情况下实现网络规模的减小和加速。 结果:
附录