哈Ha!
在今年年底,我们设法与您分享新闻,我们将开始由No Starch Press进行贝叶斯统计的有趣方式。 我们提供了本书作者的详细访谈的译文; 文字既涉及书籍本身,也涉及相关主题,甚至涉及其他阅读内容。

我和大多数开发人员一样,立即对很多事情感兴趣:功能编程,操作系统,类型系统,分布式系统和数据科学。 这就是为什么我如此受启发的原因,以至于得知
与Haskell一起编程的作者
Will Kurt在No Starch Press上写了一本关于贝叶斯统计的书。 撰写各种主题书籍的人并不多。 我相信Will会在他的新书中与读者分享一些内容,并且不会对此感到失望。 这本书是很好的入门材料,特别是对于那些不太擅长硬数学但仍希望在数据科学领域有所成就的人。 我建议在Think Stats之后但在概率Python编程之前阅读Kurt的新书:贝叶斯推理和算法,使用Python进行贝叶斯分析和进行贝叶斯数据分析。
1.为什么我们需要另一本关于统计的书?当前关于贝叶斯统计的许多现有书籍中几乎所有都表明,读者已经对统计有一个总体的了解,并且在编程方面有扎实的基础。 因此,目前,贝叶斯统计通常被认为是经典(即频率)统计的高级替代。 因此,尽管贝叶斯统计越来越流行,但其中的材料主要是为已经接受过良好定量培训的人们设计的。
当一个人决定简单地“研究统计数据”时,他会拿一本入门书,从频率的角度介绍统计数据,将其读出来,一半弄清楚了一系列的测试和规则,并且觉得整个话题非常混乱。 我想写一本关于贝叶斯统计的书,任何人都可以阅读,阅读后再直观地了解统计学的思想以及如何借助统计学解决实际问题。 对于绝对的初学者,我认为没有任何原因可以使贝叶斯统计不能成为该主题的第一门入门课程。
如果总有一天人们用“统计”一词开始表示贝叶斯统计,而频率统计只是学术界的利基之一,我将感到非常高兴。 为此,需要更多的书籍,其中将使用贝叶斯方法提出对广泛读者的统计知识,此外,作者考虑到这可能是读者对统计知识的首次了解。
我立即想到将这本书称为“统计学有趣的方式”,但我想我可能会从那些购买了这本书以准备统计学入学考试的人那里收到一堆愤怒的信,并且发现了那里完全不同! 我希望我的书可以在入学考试时要求贝叶斯统计数据的时候迈出一小步,并且即使对于那些刚刚准备考试的人,也应该阅读这样的书。
2.这本书的目标读者是什么? 一个人可以在没有任何数学背景的情况下阅读它吗?在研究“贝叶斯统计学很棒”的过程中,我试图编写一本原则上可以让任何在高中课程范围内学习过数学的人都可以理解的书。 即使您只是隐约地回忆起代数,书中的表述步伐也是如此,您可以跟上它。 贝叶斯统计量需要很少的数学分析,并且通过一点软件代码支持就可以更加简化,因此我在书中添加了两个应用程序,它们提供了R语言的基础知识,这些材料足以使R充当高级计算器,并且在其中介绍了数学分析的基本思想。因此,您可以从本书中找到所有涉及积分的示例。 但是,我保证阅读该书后,您无需解决数学分析领域的任何问题。
此外,在我努力工作的过程中,尝试尽可能减少阅读一本书所需的数学知识,当您阅读本书时,您将逐渐开始学习数学思维方式。 如果您了解正确使用的数学原理,那么您会更好地理解它。 因此,我并不是想逃避实际的数学,而是逐步解释它,以便所有数学逐渐对您变得显而易见。 像许多人一样,我曾经认为数学是一门复杂的科学,很难与之合作。 随着时间的流逝,我深信使用正确的方法,数学几乎不会造成任何困难。 数学上的任何混淆通常仅是由于尝试过快地通过材料而引起的-因此,错过了进行正确推理所需的重要步骤。
3.程序员为什么要学习概率论和统计学?我真的相信每个人都应该在某种程度上研究概率论和统计学,因为这种知识将有助于判断生活中各个地方的不确定性。 对于程序员而言,他绝对必须处理一些对理解统计数据有用的典型任务。 在您职业生涯的某个时刻,您很有可能必须编写代码,其中代码是根据先验模糊因素做出的。 也许这将是对网页转换,游戏中一些随机奖励的产生,用户向组中的随机分布,甚至从某个模糊传感器中读取信息的度量。 在所有这些情况下,对概率论的扎实了解将对您有很大帮助。 我自己的实践表明,概率方法在调试许多难以重现或跟踪复杂问题的错误方面大有帮助。 如果事实证明该错误是由内存不足引起的,那么您可以确定如果更严格地削减内存,该错误会更频繁地发生吗? 如果可以用两种方式解释一个复杂的错误,那么首先探索的最佳机会是什么? 在所有这些情况下,概率论都可以提供帮助。 当然,机器学习和数据科学的鼎盛时期导致了这样一个事实,即工程师越来越必须处理编程提供具有可能性的直接工作的任务。
4.是否可以简要描述频率和贝叶斯概率论方法之间的区别?在频率解释中,概率被解释为有关事件在重复尝试期间应多久发生一次的陈述。 因此,抛硬币两次,应该期望它会被老鹰掉下1次,因为硬币有两个侧面,其中一个有一个鹰。 在贝叶斯解释中,原则上将概率解释为我们知识的某些特征,这是逻辑的延续。 用鹰扔硬币的概率为0.5,因为我认为没有理由使鹰比尾巴掉落更多。 因此,在抛硬币的情况下,两种方法都可以正常使用。 但是,当涉及到喜欢的球队赢得世界杯的赔率时,置信度就变得更加重要。 顺便说一句,这也意味着贝叶斯统计数据不是关于世界的陈述,而是关于我们对世界的理解的陈述。 由于每个人对世界的理解有所不同,因此贝叶斯统计数据有助于我们在分析中考虑这些差异。 在许多方面,贝叶斯分析是观点演变的科学。
5.为什么书的重点放在贝叶斯方法上?关注贝叶斯统计有很多非常好的哲学原因,但是我受到一个完全实际原因的指导:使用贝叶斯方法,一切变得合乎逻辑。 基于相对较少的直观规则集,您可以为几乎遇到的任何问题开发解决方案。 这就是贝叶斯统计数据如此强大和灵活的原因,以及它们如此易于学习的原因。 我认为贝叶斯推理方式完全适合程序员。 您不必尝试通过即席测试来解决问题,而是要对此进行推理,并逐步寻求真正合理的解决方案。 原则上,贝叶斯统计-这就是推理。 仅当静态分析确实合乎逻辑且令人信服时,您才同意静态分析,而不是因为看起来随意的测试为您提供了同样未经证实的价值。 此外,从定性的观点来看,贝叶斯统计方法可以使结果令人怀疑。 在日常实践中,经常会出现两个人具有相同的事实,但他们的结论不同的情况。 贝叶斯统计方法使我们可以对这种意见分歧进行正式建模,以便我们可以自己检查将需要哪些事实,以便改变观点。 您不必因为某些p值而相信纸上陈述的结果,而是相信它们,因为它们在您看来确实令人信服。
6.贝叶斯统计如何与机器学习相关我想到的机器学习(尤其是神经网络)与贝叶斯统计之间的相似之处如下:在这两个学科中,数学分析可能非常复杂。 原则上,机器学习是对非常重要的导数的理解和解决方案。 您得到一个函数,并为此得到一个损失函数,然后(自动)计算导数并尝试遵循它,直到将其引向最佳参数为止。 许多恶意地指出,向后传播只是“链条规则”,但是在几乎所有与机器学习相关的复杂任务中,它都非常成功地使用了。
贝叶斯统计是数学分析的另一个方面,它与求解真正复杂的积分有关。 Stan的作者Michael Betancourt完美地指出,几乎所有贝叶斯分析都与期望的计算(即积分的计算)有关。 作为贝叶斯分析的结果,您仍然具有后验分布,但是如果不对其进行积分就无法以任何方式使用它,因此无法获得具体的答案。 幸运的是,没有人对积分发表过恶性评论,因为每个人都知道,即使最琐碎的积分也相当复杂。 以下是xkcd漫画之一中的格言形式:
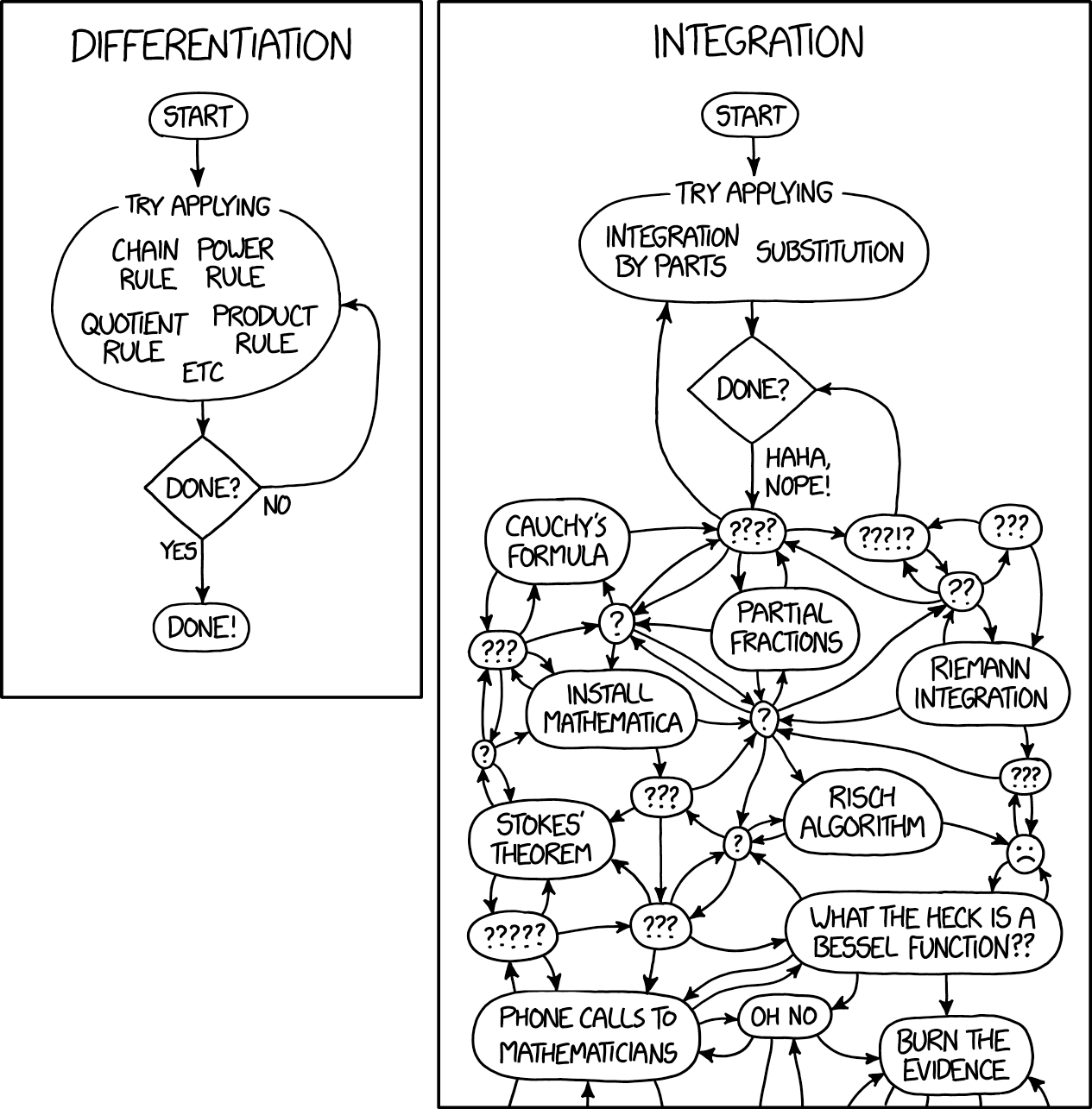
如今,机器学习和贝叶斯统计正处于一种奇怪的状态:我们将最简单的数学分析思想发展到一定程度的复杂性,以至于只能用于计算。
这种关系也突出了一个关键点。 当我们讨论导数时,我们正在寻找与函数有关的特定点。 因此,如果您知道位置和时间,那么速度就是确定您何时最快移动的导数。 迈向MO进步的一个小步骤是,当您发现一个指标比其他指标都更好时。 集成是整个过程的总和。 同样,如果您知道地点和时间,那么积分就是距离,它可以让您找出到达的距离。 贝叶斯统计信息是您对问题了解的所有信息的总和,但它不仅使您可以进行单独的预测,而且可以表征对我们的预测的信心程度,这些预测有多种选择。 贝叶斯统计的进步是对日益复杂的信息系统的理解。
7.如果读者想更深入地了解本书的主题,您会建议他们使用哪些材料(书籍,课程,博客)?我从I. T. Jane的书“概率论:科学的逻辑”中获得了最大的启发。 秘密地,我希望我的书《贝叶斯统计是伟大的》可以成为他的书的类似物,但针对的读者广泛。 使用Janes的书并非易事,它提出了贝叶斯统计的非常激进的结果。 奥布里·克莱顿(Aubrey Clayton)通过在本书的各个章节上进行了
一系列的演讲 ,为他的读者提供了大量的服务。
当然,如果您喜欢这本书,那么您可能会喜欢我的博客。 最近,我在那里写的东西不多,就像我写的《贝叶斯统计学很棒》一书以及在那之前的《用Haskell编程》一样,但是现在我脑子里充满了想法,并不是所有的想法都专门用于贝叶斯。主题。 通常,我会从统计/概率领域来思考一个主题,根据这个想法,我会为博客仔细选择一篇新文章。
8.根据您的经验,概率理论/统计学领域中的哪个概念特别难以理解?老实说,最难的部分是概率的解释。 当人们预测希拉里·克林顿将以80%的概率赢得2016年大选时,人们实际上对许多贝叶斯分析家失去了信心,例如内特·西尔弗(Nate Silver)等。 人们以为有人欺骗了他们,每个人都错了,但是,实际上80%的可能性并不大。 如果医生告诉我我的生存机会是80%,那么我会非常紧张。
通常,此问题的解决方法如下:我们指出了这样的概率,并声明它们不太适合表示不确定性。 为了解决这种不便,必须使用系数或似然比或某种分贝式系统,例如Jane的“证据”概念。 但是,考虑了很长时间后,我得出的结论是,没有唯一合适的表达不确定性的方法。
问题的实质是我们每个人都深信世界上存在确定性。 即使是经验丰富的概率论专家也有这样的感觉,如果您进行正确的分析,找到必要的先验数据,再将新级别添加到层次模型中,您将会成功,并且您将摆脱不确定性或至少减少不确定性。 由于这两个因素的奇怪结合,概率在某种程度上对我具有吸引力:理解世界的渴望和认识到,无论您如何尝试,世界总会令您感到惊讶。
9.您如何看待p值作为统计显着性的度量? 您能否简要描述什么是P-hacking?对于p值,经常会误解两件事。 首先,有智慧的人不会尝试用p值回答问题。 想象下面的对话在工作中是什么样的:
经理:“您已修复此错误,如何分配给您?”
您:“嗯,我非常确定自己没有解决问题……”
管理员:“如果您已修复,请标记为已修复。”
您:“哦,不,我不能说我已解决问题……”
经理:“好吧,您要标记它'我不会修复'吗?”
您:“不,不,当然根本不是那样”
由于许多p值本质上是模糊的,因此它们很混乱。 贝叶斯统计告诉您后验概率,这是对您所希望提出的问题的肯定答案。 在上面的对话框中,贝叶斯表示:“我很确定该错误已修复。” 如果经理希望您更自信地做出响应,那么贝叶斯可以收集其他信息并说:“原则上,我相信它已经确定。”
第二个问题是根深蒂固的习惯,即选择0.05作为某种神奇的,据说有意义的含义。 回到关于理解概率的上一个问题,某个事件将发生5%的概率并不意味着该事件是罕见的。 投掷20面骰子时,您有5%的几率获得20分。 但是,任何玩过龙与地下城的人都知道,这绝非不可能。 除了角色扮演游戏,扔骨头不是区分真相和谎言的最佳工具。
在这里,我们来谈谈p-hacking。 想象一下,您与朋友一起玩龙与地下城,并一次掷出20个骰子。 然后,您指向下降了20点的那根,并声明:“这是我要扔的那根骨头,其余的都是经过测试的骨头。” 正式来说,您确实获得了20分,但这仍然是一个骗局。 这是p-hacking的本质。 您进行分析,直到找到“必要”的东西,然后声称这就是您从一开始就在寻找的东西。
10.关于您之后要读哪本书的最终建议?, , , , . «Bayesian Analysis with Python» (, Not Monad Tutorial). , PyMC3. , . , — “Statistical Rethinking” . , .
. « – ». , «Doing Bayesian Data Analysis» .