大家好 以下是Big Monitoring Meetup 4的报告抄本。
Prometheus是用于各种系统和服务的监视系统,系统管理员可以使用该系统收集有关系统当前参数的信息,并配置警报以接收系统运行中的偏差通知。
该报告将比较Thanos和VictoriaMetrics项目,以长期存储Prometheus指标。


首先,我将介绍普罗米修斯。 这是一个监视系统,可从给定目标收集指标并将其保存在本地存储中。 Prometheus可以将指标写入远程存储库,可以生成警报和记录规则。

普罗米修斯的局限性:
- 它没有全局查询视图。 这是当您具有多个独立的普罗米修斯实例时。 他们收集指标。 您想在从不同的普罗米修斯实例中收集的所有这些指标之上提出请求。 普罗米修斯不允许这样做。
- 使用Prometheus,性能仅限于一台服务器。 Prometheus无法自动扩展到多个服务器。 您只能在多个Prometheus之间手动分割目标。
- Prometheus中的指标量仅限于一台服务器,原因相同,因为它无法自动扩展到多台服务器。
- 在Prometheus中,组织数据安全性并不容易。

解决这些问题/挑战?
解决方案是:
Prometheus收集了所有这些远程存储解决方案。 他们以不同的方式解决了上一张幻灯片中的远程存储问题。 在本演示中,我将仅讨论前两个解决方案: Thanos和VictoriaMetrics 。
关于Thanos的信息第一次出现在此链接上 。 它描述了Thanos的体系结构及其工作方式。

Thanos将Prometheus保存到本地磁盘的数据复制到S3, GCS或另一个对象存储中。

这样,Thanos提供了全局查询视图。 您可以从多个Prometheus实例请求存储在对象存储中的数据。

Thanos支持PromQL和Prometheus查询API 。

Thanos使用Prometheus代码存储数据。

Thanos由与Prometheus相同的开发商开发。
关于VictoriaMetrics 。 这是我们第一次谈论VictoriaMetrics的链接 。

VictoriaMetrics通过Prometheus支持的远程写入API协议从多个Prometheus接收数据。
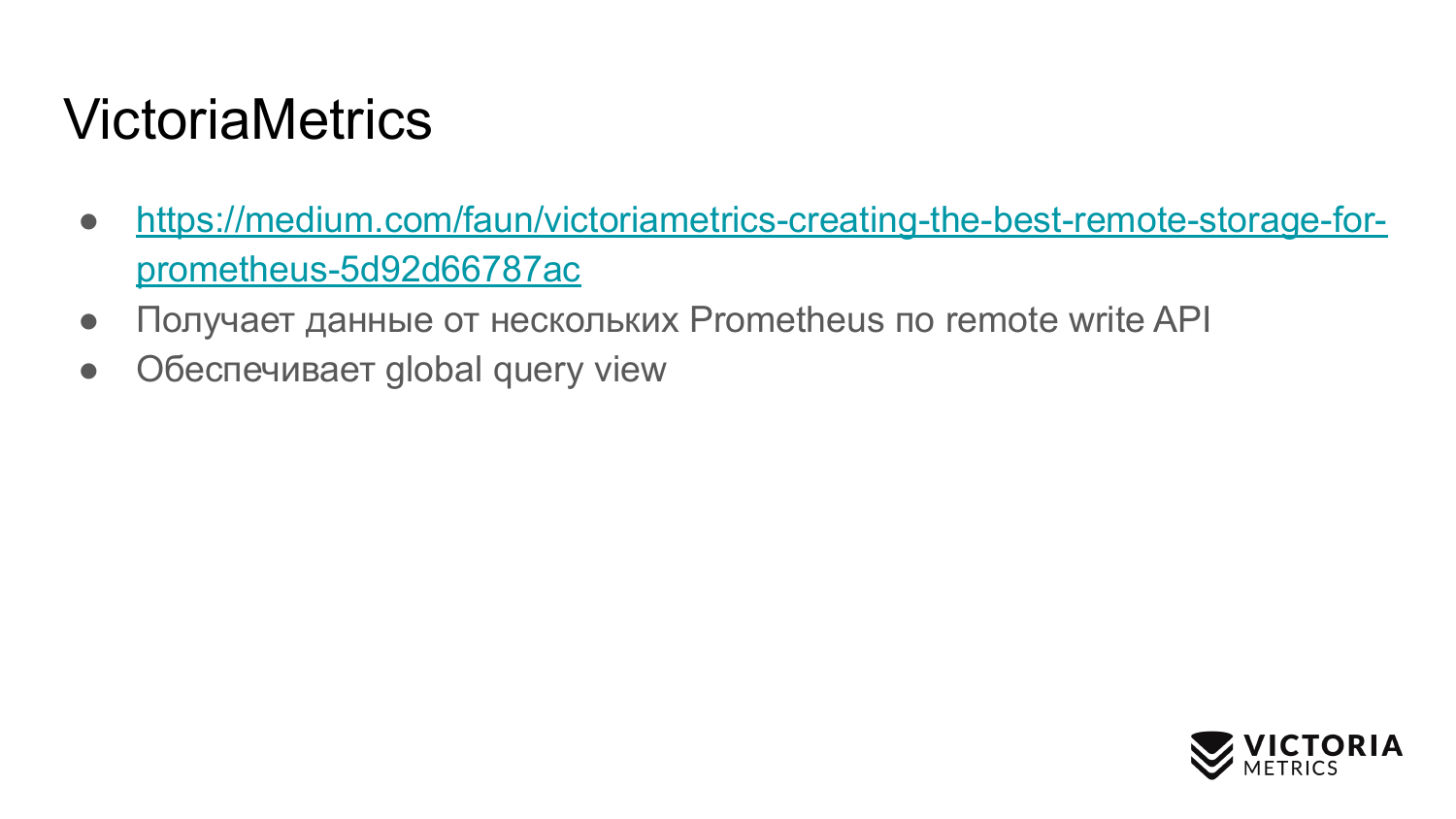
VictoriaProtriceus提供了一个全局查询视图,因为Prometheus的多个实例可以将数据写入一个VictoriaMetrics。 因此,您可以请求所有这些数据。

VictoriaMetrics还支持Thanos,PromQL和Prometheus查询API。

与Thanos不同,VictoriaMetrics源代码是从头开始编写的,并针对速度和资源进行了优化。

与Thanos不同,VictoriaMetrics可以垂直和水平缩放。 有一个单节点版本可以垂直缩放。 您可以从一个处理器和1 GB内存开始,然后逐渐增长到数百个处理器和1TB内存。 VictoriaMetrics可以使用所有这些资源。 与单核系统相比,其性能将提高约100倍。

Thanos的历史始于2017年11月,当时首次公开露面。 在此之前,Thanos由improbable.io内部开发。

2019年6月,发布了具有里程碑意义的0.5.0版本,其中删除了八卦协议。 他没有尽全力而被从Thanos撤职。 通常,Thanos群集无法正常工作,由于八卦协议,与其连接的节点不正确。 因此,他们决定从此处删除它。 我认为这是正确的决定。

同样在2019年6月,他们向Cloud Native Computing Foundation发送了应用程序编号256 。

几个月后,Thanos加入了Cloud Native Computing Foundation ,该基金会包括Prometheus,Kubernetes和其他受欢迎的项目。

2018年1月,VictoriaMetrics的开发开始了。

在2018年9月,我首先公开提到了VictoriaMetrics。

2018年12月,发布了单节点版本。

在2019年5月,发布了单节点版本和群集版本的源代码。

在2019年6月,我们与Thanos一样,以255号申请了CNCF基金会。 我们在Thanos申请前一天申请。

但是,不幸的是,我们在那里仍然没有被接受。 需要社区的帮助。

考虑显示Thanos和VictoriaMetrics体系结构的最重要的幻灯片。

让我们从Thanos开始。 黄色成分是普罗米修斯成分。 其他一切都是Thanos组件。 让我们从最重要的组件开始。 Thanos Sidecar是一个安装在每个Prometheus旁边的组件。 他致力于将Prometheus数据从本地存储加载到S3或另一个对象存储中。
还有一个类似Thanos Store Gateway的组件,它可以根据Thanos Query的传入请求从对象存储读取此数据。 Thanos Query实现了PromQL和Prometheus API。 也就是说,从外部看起来像普罗米修斯。 它接受PromQL查询,将其发送到Thanos Store Gateway,Thanos Store Gateway从对象存储检索必要的数据,然后将其发送回去。
但是由于Thanos Sidecar实现的特殊性,我们将数据存储在对象存储中的时间没有过去两个小时的时间,而后者无法将最近两个小时的数据上传到对象存储S3,因为Prometheus尚未在本地存储中创建文件。
他们如何决定解决这个问题? 除了来自Thanos Store Gateway的请求外,Thanos Query还向位于Prometheus旁边的每个Thanos Sidecar发送并行请求。
然后Thanos Sidecar,代理在Prometheus中进一步请求,并获取最后两个小时的数据。
除了这些组件之外,还有一个可选组件,如果没有这些组件,Thanos将感觉不舒服。 这是Thanos Compact,它将对象存储上的小文件合并为Thanos Sidecar在此处上传的较大文件。 Thanos Sidecar在两个小时内将数据文件上传到那里。 这些文件,如果不将它们合并为更大的文件,则它们的数量会大大增加。 这样的文件越多,Thanos Store Gateway需要的内存就越多,通过网络传输元数据所需的资源也就越多。 Thanos Store Gateway变得效率低下。 因此,您绝对必须运行Thanos Compact,它将小型文件合并为较大的文件,以使此类文件更少,并减少Thanos Store Gateway的开销。
还有诸如Thanos Ruler之类的组件。 它遵循Prometheus警报规则,并且可以计算Prometheus记录规则,以便将数据写回到对象存储。 但是不建议使用此组件,因为 他倾向于返回不完整的数据 。
对于Thanos,这是一个简单的方案。
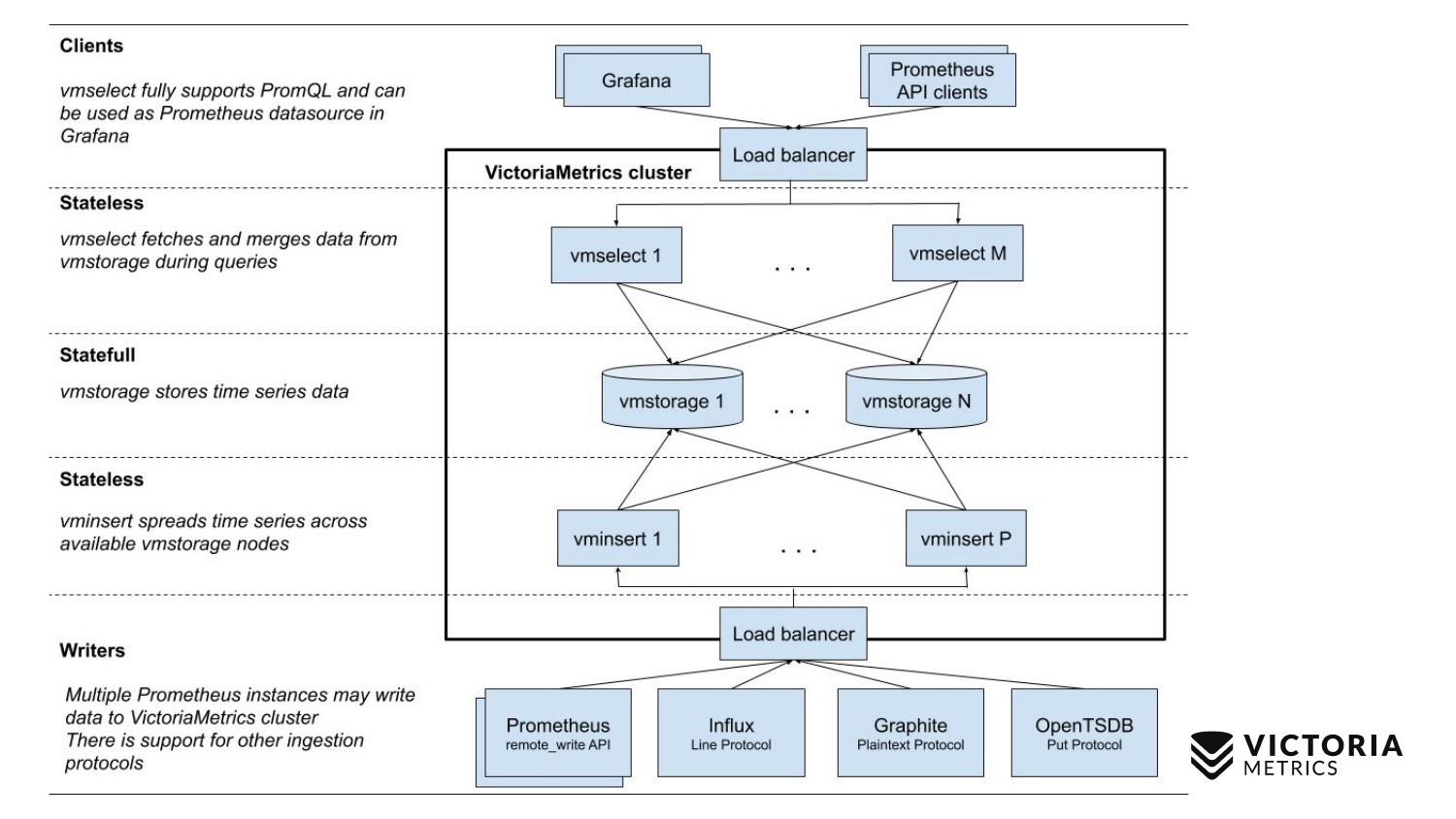
现在与VictoriaMetrics模式进行比较。
VictoriaMetrics有2个版本:单节点和群集版本。 单节点在一台计算机上运行。 单节点没有这些组件,只有一个二进制文件。 幻灯片上的这个二进制文件看起来像这个正方形。 正方形内的所有内容都是单节点版本的二进制文件的内容。 您不需要了解他。 只需启动二进制文件-一切对我们有用。
集群版本更加复杂。 其中包含三个不同的组件:vmselect,vminsert和vmstorage。 从他们的名字可以清楚看出他们每个人的所作所为。 插入组件接受不同格式的数据:来自Prometheus远程写API,Influx线路协议,Graphite协议和OpenTSDB协议。 插入组件接受它们,对其进行解析,然后在已存储数据的现有存储组件之间分配它们。 选择组件又接受PromQL查询。 它实现PromQL以及Prometheus查询API,并且可以在Grafana或其他Prometheus API客户端中替代Prometheus。 Select接受一个promql请求,对其进行解析,从存储节点读取执行该请求所需的数据,处理该数据并返回响应。

比较安装Thanos和VictoriaMetrics的难度。

让我们从Thanos开始。 在开始使用Thanos之前,您需要在对象存储中创建存储区,例如S3或GCS,以便Thanos Sidecar可以在其中写入数据。

然后,对于每个Prometheus,您需要安装Thanos Sidecar。 在此之前,您需要记住在Prometheus中禁用数据压缩。 数据压缩会定期压缩Prometheus本地存储中的数据,以减少资源消耗。
将Thanos Sidecar安装到Prometheus时,必须禁用此数据压缩,因为打开数据压缩后Thanos Sidecar无法正常工作。 这意味着您的Prometheus将开始以两个小时为单位存储数据,并停止将这些块合并为更大的块。 因此,如果您发出的请求超过最近两个小时,则在启用数据压缩后,它们将无法有效地工作。

因此,Thanos建议将本地存储中的数据保留时间减少到6-8小时,以减少大量小块的开销。
安装Thanos Sidecar之后,必须为每个对象存储桶安装两个组件。 它们是Thanos Compactor和Thanos Store Gateway。

之后,您需要安装Thanos Query并对其进行配置,以便它知道如何连接到您拥有的所有Thanos Store Gateway,并且还知道如何连接到所有Thanos Sidecar。
可能有一个小问题。

您需要配置从Thanos Query到这些组件的可靠且安全的连接。 而且,如果您的Prometheus位于不同的数据中心或不同的VPC中,则禁止与它们的外部连接。 但是要使Thanos Query正常工作,您需要以某种方式在此处配置连接,并且必须想出一种方法。
如果您有很多这样的数据中心,那么整个系统的可靠性就会降低。 由于Thanos Query必须始终保持与位于不同数据中心的所有Thanos Sidecar的连接。 对于每个传入的请求,他都会将请求转发给所有Thanos Sidecar。 如果连接中断,您将收到不完整的数据集,或者得到的答案是“群集无法正常工作”。

在VictoriaMetrics中,事情要容易一些。 对于单节点版本,仅运行一个二进制文件就足够了,并且一切正常。

在集群版本中,足以以所需数量运行以上所有三种类型的组件,或者使用Helm图表自动在Kubernetes中启动组件。 我们仍计划打造一个Kubernetes运营商。 舵图不涵盖某些情况,可以让您开枪。 例如,它允许您减少存储节点的数量,这将导致数据丢失。

启动一个二进制或群集版本后,只需将远程写入url的设置添加到Prometheus配置中,以便它开始与本地存储和远程存储并行写入数据。 如您所注意到的,与Thanos配置相比,此配置应该更可靠地工作。 我们不需要保持VictoriaMetrics与所有Prometheus的连接,因为Prometheus本身已连接至VictoriaMetrics并传输数据。

考虑一下Thanos和VictoriaMetrics的护送。

Thanos需要关注Sidecar,以便它不会停止将数据加载到对象存储中。 他们可能由于加载错误而停止此数据加载,例如,您与对象存储的网络连接暂时断开,或者对象存储暂时不可用。 Thanos Sidecar此时将注意到此情况,报告错误,可能掉下来然后停止工作。 如果您不监视它,那么您的数据将不再传输到对象存储。 如果保留时间过去了(建议6-8小时),那么您将丢失未归入对象存储的数据。

由于与Sidecar的比赛, Thanos压实机可能会停止工作。 压缩程序从对象存储中获取数据,并将它们合并为更大的数据块。 由于压缩器未与Sidecar同步,因此可能会发生以下情况:Sidecar尚未完成对该块的写入,Compactor决定此块已完全记录。 压实机开始阅读它。 它不会完全读取该块并停止工作。 在这里查看详细信息。

由于Compactor和Sidecar之间的竞争,Store Gateway可能会给出不一致的数据。 这是同一回事,因为Store Gateway绝不与Compactor和Sidecar同步。 因此,当商店网关看不到数据的一部分或看到多余的数据时,可能会发生竞争状况。

如果某些Sidecar或Store Gateway当前不可用,则Thanos中的Query组件默认为部分结果。 您将收到部分数据,甚至不会知道并非所有数据都已收到。 默认情况下,它像这样工作。 在类似情况下,VictoriaMetrics将标记的数据作为部分返回。

与Thanos不同,VictoriaMetrics很少丢失数据。 即使从Prometheus到VictoriaMetrics的连接被中断,这也不成问题,因为Prometheus继续将传入的新数据记录在大小为2小时的预写日志中。 如果您在两个小时内重新连接到VictoriaMetrics,则数据不会丢失。 重新连接到VictoriaMetrics之后, Prometheus 可以添加数据 。

与Thanos(仅在两个小时后才将数据写入对象存储)不同,Prometheus通过远程写入协议自动将数据复制到诸如VictoriaMetrics的远程存储。 您不必担心会丢失Prometheus中的本地存储。 如果他突然丢失了本地存储,那么在最坏的情况下,您将丢失没有时间写入远程存储的最后几秒钟的数据。

与Thanos不同,Kubernetes自动管理集群。 与VictoriaMetrics集群组件不同,所有Thanos组件都难以放入单个Kubernetes集群中。

VictoriaMetrics对新版本进行了非常简单的升级。 只需停止VictoriaMetrics,更新二进制文件并运行即可。 当通过SIGINT信号停止时,所有VictoriaMetrics二进制文件都会正常关闭。 他们正确地保存了必要的数据,正确地关闭了传入的连接,以免丢失任何内容。 因此,升级时不会丢失任何东西。

VictoriaMetrics有一个非常简单的扩展集群的方法。 只需添加必要的组件并继续工作即可。

关于Thanos和Victoria Metrics的陷阱。

Thanos有以下陷阱。 Prometheus应该存储最近两个小时的数据。 如果它们丢失了,您将完全丢失它们,因为它们尚未设法在对象存储中注册,例如S3。

如果大量的小文件存储在其中,则存储网关组件和压缩程序组件可能需要大量内存才能与大型对象存储一起使用。 文件数量和容量越大,存储元信息所需的存储网关和压缩器内存就越多。 Thanos存在许多有关Store Gateway和压缩器随平均记录数据丢失的问题。

Thanos被吹捧可以无限地扩展您的Prometheus量。 这实际上是不正确的。 由于所有请求都通过查询组件进行,而查询组件必须同时轮询所有Store Gateway组件和所有Sidecar组件,因此从那里提取数据,然后对其进行预处理。 显然,查询速度受到最慢的弱链接,最慢的Store Gateway或最慢的Sidecar的限制。
这些组件可能加载不均匀。 例如,您的Prometheus每秒收集数百万个指标。 还有Prometheus,它每秒收集数千个指标。 Prometheus每秒收集数百万个指标,从而将其运行的服务器负载更多。 因此,Sidecar在那里较慢。 总的来说,那里的一切运行缓慢。 而且查询组件将从那里非常缓慢地提取数据。 因此,整个缓慢的Sidecar将限制整个群集的性能。

默认情况下,如果某些Sidecar和两个Store Gateway不可用,Thanos将返回部分数据。 例如,如果您将Sidecar分布在世界各地的不同数据中心中,那么断开连接和组件不可用的可能性就会大大增加。 因此,在大多数情况下,您将收到部分数据,甚至不知道它。

VictoriaMetrics也有陷阱。 第一个陷阱是一个选项,用于限制用于VictoriaMetrics缓存的RAM数量。 默认情况下,它等于运行VictoriaMetrics的计算机上的RAM的60%,或Kubernetes中VictoriaMetrics的pod RAM的60%。
如果错误地更改了该值,则可能会破坏VictoriaMetrics的性能。 例如,如果您将值设置得太低,则数据可能不再适合VictoriaMetrics缓存。 因此,她将不得不做额外的工作,并用磁盘加载处理器。 如果将此选项设置得太大,则它会首先增加VictoriaMetrics因内存不足错误而崩溃的可能性,其次,这将导致操作系统中剩余的操作内存很少文件缓存的内存。 VictoriaMetrics依靠文件缓存来提高性能。 如果还不够,那么磁盘上的负载会大大增加。 因此,提示:除非绝对必要,否则请勿更改参数。
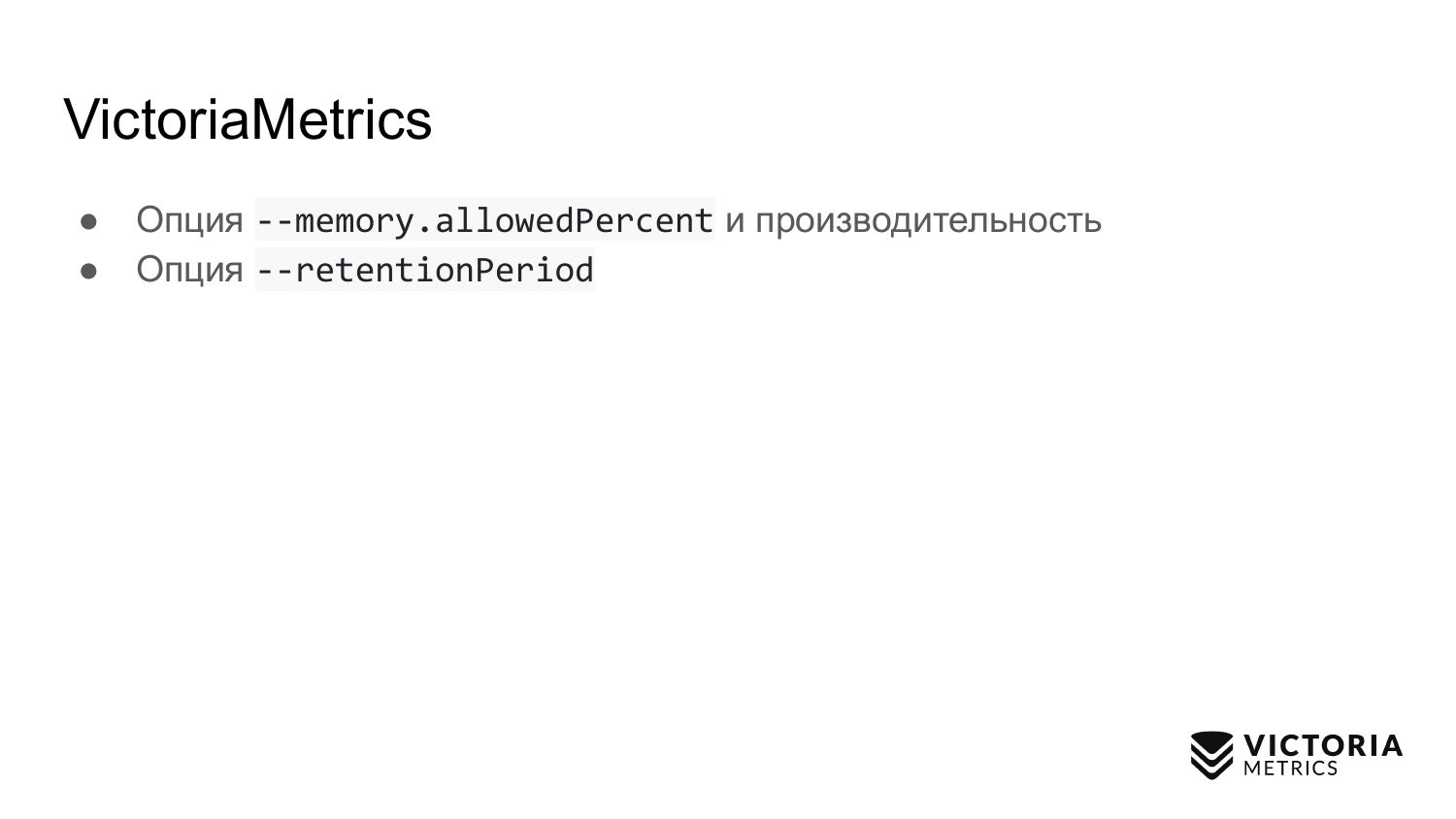
第二种选择。 这是retentionPeriod-默认设置为1个月的期间。 这是VictoriaMetrics存储数据的时间。 在此期间之后,VictoriaMetrics将删除数据。
许多运行不带此参数的VictoriaMetrics,他们记录一个月的数据。 然后他们问:为什么上个月的数据消失了? 因为默认情况下retentionPeriod是1个月。 因此,您需要知道并设置正确的retentionPeriod。

让我们一起经历独特的机会。

Thanos具有下采样的功能:5分钟和1小时的间隔,通常不能正常工作 。 如果您在google上搜索它并在github上查看他们的问题,则有很多与此降采样有关的问题,有时它可能无法正常工作,或者无法按用户期望的那样工作。

Thanos具有Prometheus HA对的重复数据删除功能。 当两个Prometheus'a从同一个目标收集相同的度量标准时,Thanos将它们放入对象存储中。 Thanos , VictoriaMetrics.

Thanos alert , Thanos. production .

Thanos , Thanos Prometheus — . Thanos Prometheus . Thanos Prometheus .

VictoriaMetrics — MetricsQL. VictoriaMetrics PromQL, big monitoring metup.

VictoriaMetrics . VictoriaMetrics Prometheus, Influx, OpenTSDB Graphite.

VictoriaMetrics Thanos Prometheus.
, 2-5 Prometheus Thanos.

VictoriaMetrics — .

.

Thanos , object storage, .
object storage, ($10 ). object storage, , AWS — . , $10 $230 1. , Thanos .

Thanos Compact, Store Gateway, Query , , .

VictoriaMetrics . GCE HDD , $40 1. VictoriaMetrics HDD , SSD, . VictoriaMetrics HDD.

VictoriaMetrics需要服务器用于组件:单点或集群组件,与Thanos组件不同,它们需要更少的CPU和RAM-相应地,它会更便宜。

实施示例。

Thanos的实现示例是Gitlab。 Gitlab由Thanos完全提供动力。 但是没有那么顺利。 如果查看他们的问题 ,您会发现他们在Thanos上经常遇到某种操作问题 :没有足够的内存来存储Store Gateway或Query组件。 他们不断地必须增加内存量。
因此,解决这些问题的成本增加。
第二种可能会更成功的实现方法是Improbable公司,该公司开始开发Thanos。 他们出版了Thanos的资料。 Improbable是一家开发游戏引擎的公司。

VictoriaMetrics公开的实施示例包括:
- wix.com网站建设者
- 阿迪达斯推出VictoriaMetrics,甚至在最新的PromCon 2019上进行了演讲
- TrafficStars-广告网络
- Seznam.cz是受欢迎的捷克搜索引擎。
然后去了公司的名字,我现在无法命名。 他们不同意。
- 一位主要的游戏开发商。 比他们还大不可能。
- 一家主要的图形软件开发商。
- 俄罗斯大银行。
- 这家欧洲风力涡轮机制造商已成功测试了VictoriaMetrics。 该制造商实施了VictoriaMetrics,以每个传感器每秒50个样本的速度监视来自风力涡轮机的数据。 每个风力涡轮机都有数百个传感器。 他们有几百台风力涡轮机。
- 想要引进VictoriaMetrics的俄罗斯航空公司,但仍然没有。 我们与他们处于合同阶段。
 结论
结论
VictoriaMetrics和Thanos解决了类似的问题,但是方式不同:

谢谢啦
我们正在电报频道等你。
