哈勃! 大数据和机器学习的数据集呈指数增长,需要进行处理。 我们关于高性能计算(HPC)的另一项创新技术的文章在金士顿(Superston)
2019年超级计算机展位上展出。 这是在具有图形处理器(GPU)和GPUDirect Storage总线技术的服务器中使用高端存储系统(SHD)。 由于存储器和GPU之间直接进行数据交换,绕过CPU,因此将数据加载到GPU加速器中的速度提高了一个数量级,因此大数据应用程序以GPU提供的最高性能运行。 反过来,HPC系统的开发人员对具有最高I / O速度的存储方面的进步感兴趣,例如金士顿(Kingston)版本。

数据加载前的GPU性能
自从CUDA(一种用于开发通用应用程序的基于GPU的硬件和软件并行计算架构)创建以来,在2007年,GPU本身的硬件功能得到了惊人的增长。 如今,GPU越来越多地用于HPC应用程序领域,例如大数据,机器学习和深度学习。
请注意,尽管术语相似,但最后两个算法在算法上是不同的。 ML讲授基于结构化数据的计算机,而DL讲授基于神经网络响应的计算机。 一个有助于理解差异的示例非常简单。 假设计算机应区分存储中加载的猫和狗的照片。 对于ML,您应该提交一组带有许多标签的图像,每个标签都定义动物的一个特定特征。 对于DL,上传大量图像就足够了,但是只需一个标签“这是猫”或“这是狗”即可。 DL与幼儿的教学方式非常相似-它们只是在书本和生活中被简单地显示为狗和猫的图像(大多数情况下甚至没有解释详细的区别),并且在经过一定数量的图片进行比较后,孩子的大脑本身开始确定动物的类型(据估计,我们谈论的是整个童年时期的一百或两次印象)。 DL算法还不是很完美:为了成功处理神经网络的图像定义,必须在GPU中提交和处理数百万个图像。
引入的结果是:基于GPU,您可以在大数据,ML和DL领域构建HPC应用程序,但是存在一个问题-数据集太大,以至于将数据从存储系统下载到GPU的时间开始降低应用程序的整体性能。 换句话说,由于来自其他子系统的数据输入/输出速度较慢,因此快速GPU仍保持欠载状态。 GPU和到CPU / SHD的总线的输入/输出速度的差异可能是一个数量级。
GPUDirect存储技术如何工作?
输入/输出过程由CPU控制,以及将数据从存储设备加载到GPU进行后续处理的过程。 这促使人们要求提供一种技术,该技术可以在GPU和NVMe驱动器之间提供直接访问,以实现彼此之间的快速交互。 NVIDIA提出了第一个此类技术,并将其称为GPUDirect Storage。 实际上,这是他们先前开发的GPUDirect RDMA(远程直接内存地址)技术的变体。
 NVIDIA首席执行官黄仁勋(Jensen Huang)在SC-19大会上介绍了GPUDirect存储,作为GPUDirect RDMA的变体。 资料来源:NVIDIA
NVIDIA首席执行官黄仁勋(Jensen Huang)在SC-19大会上介绍了GPUDirect存储,作为GPUDirect RDMA的变体。 资料来源:NVIDIAGPUDirect RDMA和GPUDirect存储之间的区别在于执行寻址的设备之间。 重新分配了GPUDirect RDMA技术以在网络接口输入卡(NIC)和GPU内存之间直接移动数据,GPUDirect Storage提供了本地或远程存储之间的直接数据传输路径,例如通过Fabric(NVMe-oF)的NVMe或NVMe和GPU内存。
GPUDirect RDMA和GPUDirect Storage这两个选项都可以避免不必要的数据通过CPU内存中的缓冲区移动,并允许直接内存访问(DMA)机制将数据从网卡或存储直接传输到GPU内存或从GPU内存直接传输-所有这些都无需在中央处理器上加载处理器 对于GPUDirect Storage,存储位置无关紧要:它可以是GPU单元内部,机架内部的NVME磁盘,也可以通过网络连接为NVMe-oF。
 GPUDirect Storage操作方案。 资料来源:NVIDIA
GPUDirect Storage操作方案。 资料来源:NVIDIAHPC应用程序市场所需的NVMe高端存储
了解到随着GPUDirect Storage的到来,大客户的兴趣将转向提供具有与GPU带宽相对应的输入/输出速度的存储系统,金士顿在SC-19上展示了一个演示系统,该系统由基于NVMe磁盘的存储系统和带有GPU的单元组成每秒分析数千个卫星图像。
在超级计算机展览会的报告中,我们已经基于10个驱动器DC1000M U.2 NVMe编写了有关这种存储的文章。
 基于10个驱动器的存储DC1000M U.2 NVMe通过图形加速器充分补充了服务器。 资料来源:金斯敦
基于10个驱动器的存储DC1000M U.2 NVMe通过图形加速器充分补充了服务器。 资料来源:金斯敦这样的存储以机架单元1U或更大的形式执行,并且可以根据DC1000M U.2 NVMe驱动器的数量进行扩展,每个驱动器的容量为3.84-7.68 TB。 DC1000M是用于数据中心的金士顿驱动器系列中U.2尺寸规格中的第一款NVMe SSD型号。 它具有耐用性等级(DWPD,每天写入驱动器),可让您每天一次以最大容量覆盖数据,以保证驱动器寿命。
在Ubuntu操作系统18.04.3 LTS,Linux内核5.0.0-31-generic的fio v3.13测试中,展览存储模型显示580万IOPS的持续读取速度和23.8 Gb / s的持续带宽。
金士顿SSD业务经理Ariel Perez对新存储系统的描述如下:“我们准备为下一代服务器提供U.2 NVMe SSD,以解决传统上与存储相关的许多数据传输瓶颈。 NVMe SSD和我们的高级Server Premier DRAM的结合使金士顿成为业界最全面的端到端数据处理器提供商之一。”
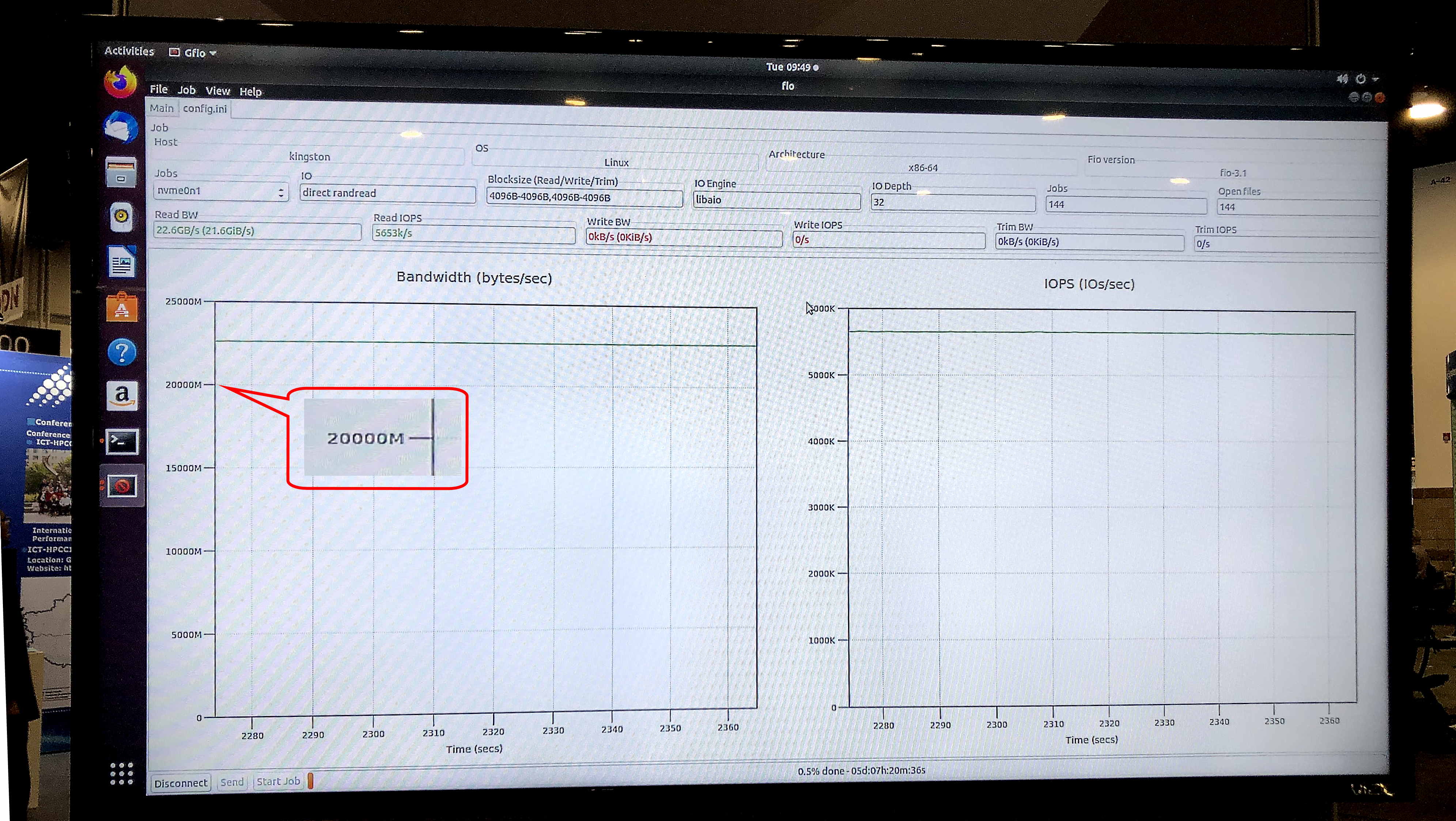 gfio v3.13测试显示,DC1000M U.2 NVMe驱动器上的演示存储带宽为23.8 Gb / s。 资料来源:金斯敦
gfio v3.13测试显示,DC1000M U.2 NVMe驱动器上的演示存储带宽为23.8 Gb / s。 资料来源:金斯敦对于使用GPUDirect Storage技术或类似技术的HPC应用程序,典型的系统会是什么样? 这是一种将机架中功能块物理分离的体系结构:一个或两个单元用于RAM,另外一些用于GPU和CPU计算节点,一个或多个用于存储。
随着GPUDirect Storage的发布以及其他GPU供应商中类似技术的可能出现,金士顿扩大了对设计用于高性能计算的存储系统的需求。 标记将是从存储系统读取数据的速度,与具有GPU的计算单元入口处的40或100 Gbit网卡的带宽相当。 因此,来自外来的超快速存储系统,包括外部NVMe到Fabric,将成为HPC应用程序的主流。 除了科学和财务计算之外,它们还将在许多其他实际领域中得到应用,例如特大城市安全城市级别的安全系统或交通监控中心,在这些领域中,识别和识别速度需要达到每秒数百万高清图像的水平,“ SHD
有关金士顿产品的更多信息,请
访问公司的
官方网站 。