如今,已有用于监视IP(TS)流的现成(专有)解决方案,例如VB和iQ ,它们具有相当丰富的功能集,通常,此类解决方案可供处理电视服务的大型运营商使用。 本文介绍了一种基于开源项目TSDuck的解决方案,该解决方案旨在通过计数器CC(连续性计数器)和比特率对IP(TS)流进行最小控制。 一种可能的应用是通过租用的L2通道(无法正常监视,例如,通过读取队列中的丢失计数器)来控制数据包或整个流的丢失。
关于TSDuck的非常简短
TSDuck是用于处理TS流的开源软件(两条款BSD许可)(一组控制台实用程序以及用于开发其实用程序或插件的库)。 作为输入,它可以与IP(多播/单播),http,hls,dvb调谐器,dektec dvb-asi解调器一起使用,具有内部TS流生成器并可以从文件中读取。 输出可以是文件,IP(多播/单播),hls,dektec dvb-asi和HiDes调制器,播放器(mplayer,vlc,xine)和放置。 在输入和输出之间,您可以打开各种流量处理器,例如PID重新映射,加扰/解扰,CC计数器分析,比特率计算以及TS流的其他典型操作。
在本文中,将使用IP流(多播)作为输入,使用bitrate_monitor处理器(从名字上清楚地知道它是什么)和连续性(CC计数器的分析)。 没问题,您可以用TSDuck支持的另一种输入类型替换IP多播。
TSDuck的官方版本/软件包适用于大多数当前的OS。 对于Debian而言,它们不是,但在debian 8和debian 10下可以毫无问题地进行组装。
然后使用TSDuck版本3.19-1520,使用Linux作为OS(使用Debian 10编写解决方案,使用CentOS 7进行实际使用)
准备TSDuck和操作系统
在监视实际流量之前,您需要确保TSDuck工作正常,并且在网卡或OS(插槽)级别没有掉线。 这是必需的,以便以后不猜测丢失的位置-在网络上还是在“服务器内部”。 您可以使用ethtool -S ethX命令在网卡级别检查丢弃,使用相同的ethtool进行调整(通常,您需要增加RX缓冲区(-G)并有时禁用某些卸载(-K))。 作为一般建议,建议使用单独的端口来接收分析的流量,如果可能的话,这可以最大程度地减少与由于其他流量的存在导致丢弃在分析器端口上连贯发生这一事实相关的误报。 如果无法做到这一点(使用具有单个端口的小型计算机/ NUC),则相对于连接分析仪的设备上的其余流量,优先考虑已分析流量的优先级。 关于虚拟环境,在这里您需要小心并能够找到从物理端口开始到虚拟机内部的应用程序结束的程序包删除。
主机内部流的生成和接收
作为准备TSDuck的第一步,我们将使用netns在同一主机内生成和接收流量。
烹饪环境:
ip netns add P
环境已准备就绪。 我们启动流量分析器:
ip netns exec P tsp --realtime -t \ -I ip 239.0.0.1:1234 \ -P continuity \ -P bitrate_monitor -p 1 -t 1 \ -O drop
其中“ -p 1 -t 1”表示您需要每秒计算比特率并每秒显示一次有关该比特率的信息
我们以10 Mbps的速度启动流量生成器:
tsp -I craft \ -P regulate -b 10000000 \ -O ip -p 7 -e --local-port 6000 239.0.0.1:1234
其中“ -p 7 -e”表示您需要将7个TS数据包打包到1个IP数据包中并进行艰苦的处理(-e),即 发送IP数据包之前,请始终等待来自最后一个处理器的7个TS数据包。
分析器开始显示预期的消息:
* 2020/01/03 14:55:44 - bitrate_monitor: 2020/01/03 14:55:44, TS bitrate: 9,970,016 bits/s * 2020/01/03 14:55:45 - bitrate_monitor: 2020/01/03 14:55:45, TS bitrate: 10,022,656 bits/s * 2020/01/03 14:55:46 - bitrate_monitor: 2020/01/03 14:55:46, TS bitrate: 9,980,544 bits/s
现在添加一些滴:
ip netns exec P iptables -I INPUT -d 239.0.0.1 -m statistic --mode random --probability 0.001 -j DROP
并显示以下消息:
* 2020/01/03 14:57:11 - continuity: packet index: 80,745, PID: 0x0000, missing 7 packets * 2020/01/03 14:57:11 - continuity: packet index: 83,342, PID: 0x0000, missing 7 packets
期望什么。 禁用数据包丢失(ip netns exec P iptables -F),并尝试将生成器的比特率提高到100 Mbps。 分析仪报告一堆CC错误,大约是75 Mbit / s(而不是100)。我们试图找出是谁应该负责-生成器没有时间或问题不在其中,因此,我们开始生成固定数量的数据包(700,000 TS数据包= 100,000 IP数据包):
# ifconfig veth0 | grep TX TX packets 151825460 bytes 205725459268 (191.5 GiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 # tsp -I craft -c 700000 -P regulate -b 100000000 -P count -O ip -p 7 -e --local-port 6000 239.0.0.1:1234 * count: PID 0 (0x0000): 700,000 packets # ifconfig veth0 | grep TX TX packets 151925460 bytes 205861259268 (191.7 GiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
如您所见,恰好生成了100,000个IP数据包(151925460-151825460)。 因此,我们了解了分析器会发生什么情况,为此,我们使用veth1上的RX计数器进行检查,它严格等于veth0上的TX计数器,然后我们看看套接字级别发生了什么:
# ip netns exec P cat /proc/net/udp sl local_address rem_address st tx_queue rx_queue tr tm->when retrnsmt uid timeout inode ref pointer drops 133: 010000EF:04D2 00000000:0000 07 00000000:00000000 00:00000000 00000000 0 0 72338 2 00000000e0a441df 24355
在这里,您可以看到丢弃的数量=24355。在TS数据包中,这是170485或700000的24.36%,因此我们看到丢失的比特率的25%是udp套接字中的丢弃。 UDP套接字丢失通常是由于缺少缓冲区而引起的,请查看默认套接字缓冲区的大小和套接字缓冲区的最大大小:
# sysctl net.core.rmem_default net.core.rmem_default = 212992 # sysctl net.core.rmem_max net.core.rmem_max = 212992
因此,如果应用程序未明确请求缓冲区的大小,则会使用208 KB的缓冲区创建套接字,但是如果它们请求更多的套接字,它们仍将不会收到请求的内容。 由于您可以在tsp中为IP输入设置缓冲区大小(--buffer-size),因此默认情况下我们不会触摸套接字大小,我们只需设置套接字缓冲区的最大大小并通过tsp参数显式指定缓冲区大小:
sysctl net.core.rmem_max=8388608 ip netns exec P tsp --realtime -t -I ip 239.0.0.1:1234 -b 8388608 -P continuity -P bitrate_monitor -p 1 -t 1 -O drop
通过套接字缓冲区的这种调整,现在报告的比特率约为100 Mbit / s,没有CC错误。
由tsp应用程序本身占用的CPU。 相对于i5-4260U CPU @ 1.40GHz的一个内核,分析10Mbit / s数据流需要3-4%的CPU,100Mbit / s-25%,200Mbit / s-46%。 设置丢包百分比时,CPU的负载实际上不会增加(但可以减少)。
在生产率更高的硬件上,可以毫无问题地生成和分析超过1 Gb / s的流量。
在真实的网卡上测试
在第ve对上进行测试后,您需要获取两台主机或一台主机的两个端口,将端口彼此连接,在其中一台上运行生成器,在第二台上运行分析器。 毫无意外,但实际上,一切都取决于铁,越弱越有趣。
监视系统对接收到的数据的使用(Zabbix)
Tsp没有像SNMP之类的任何机器可读API。 CC消息至少需要聚合1秒钟(丢包率很高,每秒可能有数百/数千/数万,具体取决于比特率)。
因此,为了保存信息并绘制CC错误和比特率的图表并造成某种事故,可能还需要以下选择:
- 解析并汇总(根据CC)tsp的输出,即 将其转换为所需的形状。
- 添加tsp和/或处理器插件bitrate_monitor和自身的连续性,以便以适合于监视系统的机器可读形式显示结果。
- 在tsduck库的顶部编写应用程序。
显然,从人工成本的角度来看,选项1是最简单的,尤其是考虑到tsduck本身是用低级(按现代标准)语言(C ++)编写的
一个简单的bash解析器+聚合器原型显示,在10Mbit / s的流和50%的数据包丢失(最坏的情况)下,bash进程消耗的CPU比tsp进程本身多3-4倍。 这种情况是不可接受的。 实际上是下面这个原型的一部分
除了它运行缓慢的事实之外,bash中没有正常的线程,bash作业是独立的进程,我不得不每秒记录一次副作用的missingPackets值(当我收到每秒发来的比特率消息时)。 结果,bash被搁置了,因此决定在golang中编写包装器(解析器+聚合器)。 类似golang代码的CPU消耗比tsp进程本身少4-5倍。 通过用golang替换bash来加快包装速度,大约达到了16倍,总体结果是可以接受的(在最坏的情况下,CPU的开销增加了25%)。 golang上的源文件在这里 。
包装推出
为了运行包装器,为systemd创建了最简单的服务模板( 此处 )。 假定包装器本身已编译为位于/ opt / tsduck-stat /中的二进制文件(进行构建tsduck-stat.go)。 假定golang用于支持单调时钟(> = 1.9)。
要创建服务实例,您需要运行systemctl enable tsduck-stat@239.0.0.1:1234命令,然后开始使用systemctl start tsduck-stat@239.0.0.1:1234。
Zabbix的发现
为了让zabbix能够发现正在运行的服务,以发现Zabbix所必需的格式制作了一个组列表生成器 (discovery.sh),假定它位于/ opt / tsduck-stat中。 要通过zabbix-agent开始发现,您需要将.conf文件添加到具有zabbix-agent配置的目录中,以添加用户参数。
Zabbix模板
创建的模板 (tsduck_stat_template.xml)包含自动发现规则,数据元素的原型,图形和触发器。
简短的清单(嗯,如果有人决定使用清单)
- 确保tsp不会在“理想”状态下丢弃数据包(发生器和分析仪直接连接),如果有数据包丢失,请参阅第2节或关于此主题的文章文字。
- 调整最大套接字缓冲区(net.core.rmem_max = 8388608)。
- 编译tsduck-stat.go(开始构建tsduck-stat.go)。
- 将服务模板放在/ lib / systemd / system中。
- 使用systemctl启动服务,检查计数器是否开始出现(grep“” / dev / shm / tsduck-stat / *)。 服务数量乘多播流的数量。 在这里,您可能需要创建到多播组的路由,或者关闭rp_filter或创建到源ip的路由。
- 运行discovery.sh,确保它生成json。
- 附加zabbix代理的配置,然后重新启动zabbix代理。
- 将模板下载到zabbix,将其应用于监视和安装zabbix-agent的主机,等待大约5分钟,看看是否出现了新的数据元素,图形和触发器。
结果
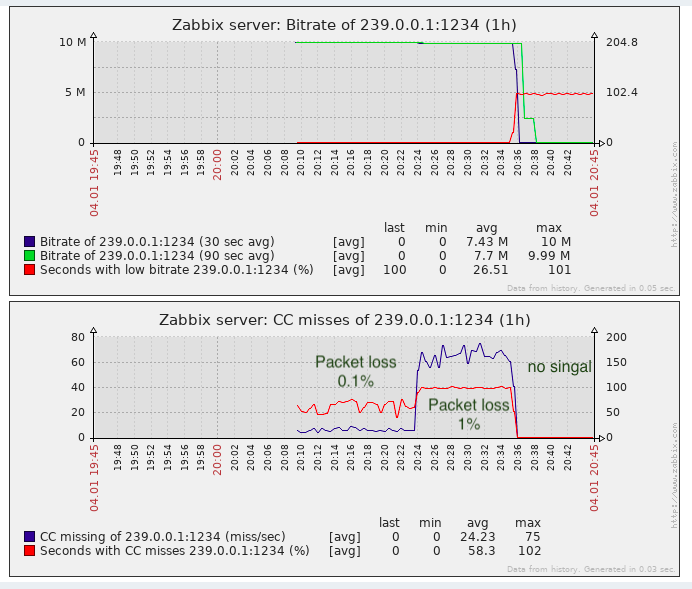
对于检测数据包丢失的任务几乎足够,至少它比缺少监视要好。
实际上,粘贴视频片段时可能会发生CC-“丢失”(据我所知,插入是在俄罗斯联邦的本地电信中心完成的,也就是说,无需计算CC计数器),这一点必须牢记。 在专有解决方案中,通过检测SCTE-35标签标签(如果它们是由流生成器添加的)可以部分绕过此问题。
UPD:在包装器和zabbix模板中增加了对SCTE-35标签的支持
从监视传输质量的角度来看,没有足够的监视抖动(IAT),因为 电视设备(无论是调制器还是终端设备)都有此参数的要求,并且并不总是能够将jitbuffer膨胀到无穷大。 当在传输过程中使用具有大缓冲区的设备并且未配置QoS或未将QoS正确配置为传输此类实时流量时,抖动可能会浮动。