背景知识
有一次,与同事开始讨论如何改进C ++枚举中使用位标志的工具。 那时,我们已经有了IsEnumFlagSet函数,该函数将被测试的变量作为第一个参数,并检查第二组标志。 为什么它比旧的按位好呢?
if (IsEnumFlagSet(state, flag)) { }
我认为-可读性。 通常,我很少使用位标志和位操作,因此,在查看别人的代码时,比起立即调用内部window.alert()并带有标题“注意! 可能正在发生某种魔术。”
有点悲伤不幸的是,C ++仍然不支持扩展方法(尽管已经有一个
类似的提议 )-否则,例如,la std :: bitset方法将是一个理想的选择:
if (state.Test(particularFlags)) {}
在设置或删除标志的操作期间,特别是可读性恶化。 比较:
state |= flag;
在讨论过程中,还表达了创建
SetEnumFlag(state, flag, isSet) :根据第三个参数,
state会引发标志或清除标志。
显然,由于假定此参数是在
RaiseEnumFlag/ClearEnumFlag传递的,因此与
RaiseEnumFlag/ClearEnumFlag对相比,您不能没有开销。 但是出于学术兴趣,我想通过探究微优化
的魔鬼进入
矿井,以将其最小化。
实作
1.天真的实现
首先,我们介绍枚举(我们将不使用enum类来简化):
#include <limits> #include <random> enum Flags : uint32_t { One = 1u << 1, Two = 1u << 2, Three = 1u << 3, OneOrThree = One | Three, Max = 1u << 31, All = std::numeric_limits<uint32_t>::max() };
和实现本身:
void SetFlagBranched(Flags& x, Flags y, bool cond) { if (cond) { x = Flags(x | y); } else { x = Flags(x & (~y)); } }
2.微优化
天真的实现有一个明显的分支,我非常想将其转移到算术上,这是我们现在要尝试的。
首先,我们需要选择一些表达式,使我们可以根据参数从一个结果切换到另一个结果。 举个例子
(x | y) & ¬p
- 当
p = 0升旗:
(x | y) & ¬0 ≡ (x | y) & 1 ≡ x | y
- 当
p = y删除p = y标志:
(x | y) & ¬y ≡ (x & ¬y) | (y & ¬y) ≡ (x & ¬y) | 0 ≡ x & ¬y
现在,我们需要以某种方式将取决于变量
cond的参数值更改“打包”到算术中(请记住-禁止分支)。
最初让
p = y ,如果
cond true,则尝试重置
p ,如果不是,则保留所有内容。
我们将无法直接使用
cond变量:转换为算术类型时,如果为true,则仅以低阶获得一个单位,理想情况下,我们需要以所有位来获得单位(UPD:
您仍然可以 )。 结果,没有比使用按位移位更好的主意了。
我们定义了移位量:由于标准要求移位量小于类型大小,因此无法立即移位所有位以使参数
p在一次操作中复位。
没有正当理由例如,asm文档中的左移算术(SAL)命令显示“计数范围限制为0到31(如果使用64位模式和REX.W,则限制为63)”
因此,我们计算最大移位量,写出初步表达式
constexpr auto shiftSize = sizeof(std::underlying_type_t<Flags>) * 8 - 1; (x | y) & ~ ( y >> shiftSize * cond);
并分别处理表达式
y >> shiftSize * cond的结果的
y >> shiftSize * cond :
(x | y) & ~ (( y >> shiftSize * cond) & ~cond);
分支
shiftSize * cond在
shiftSize * cond -根据
shiftSize * cond false或true,shift值将分别为0或31,并且我们的参数将等于
y或0。
当
shiftSize = 31时会发生什么:
- 当
cond = true我们将y位右移31位,其结果是y的最高有效位变为最低有效,其他所有位均被复位。 相反,在~cond最低有效位是0,所有其他有效位是1。 这些值的按位相乘将得到干净的0。 - 当
cond = false不发生移位,所有位中的~cond均为1,并且这些值的按位乘积将为y 。
我想指出这种方法的折衷方案,这种折衷方案并非立即显而易见:在不使用分支的情况下,我们可以计算
x | y x | y (也就是朴素版本的分支之一),无论如何,然后,由于“额外”算术运算,我们将其转换为所需的结果。 如果其他算术的开销小于分支的开销,那么所有这些都是有意义的。
因此,最终决定如下:
void SetFlagsBranchless(Flags& x, Flags y, bool cond) { constexpr auto shiftSize = sizeof(std::underlying_type_t<Flags>) * 8 - 1; x = Flags((x | y) & ~(( y >> shiftSize * cond) & ~cond)); }
(通过读取
std::numeric_limits::digits ,移位大小更正确,
请参见注释 )
3.比较
无需分支即可实施该解决方案,我去了
quick-bench.com以确保其优势。 对于开发,我们主要使用clang,因此我决定在其上运行基准测试(clang-9.0)。 但是后来惊喜来了...
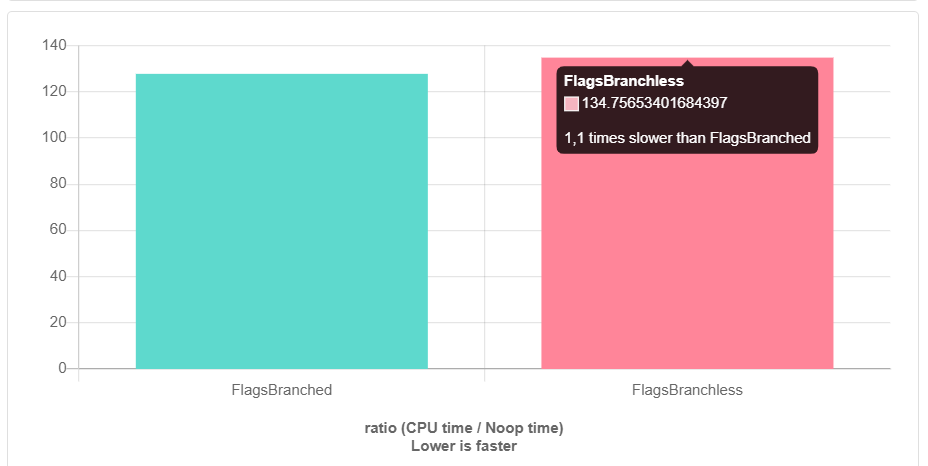
这是-O3。 没有优化,情况更糟。 怎么发生的? 谁该怪谁该怎么办?
我们命令“搁置恐慌!”并去了解
godbolt.org (quick-bench还提供了asm列表,但是godbolt在这方面看起来更方便)。
接下来,我们仅讨论优化级别-O3。 那么,clang为我们的幼稚实现生成了什么代码?
SetFlagBranched(Flags&, Flags, bool): # @SetFlagBranched(Flags&, Flags, bool) mov eax, dword ptr [rdi] mov ecx, esi not ecx and ecx, eax or eax, esi test edx, edx cmove eax, ecx mov dword ptr [rdi], eax ret
还不错吧? Clang还知道如何进行权衡,并且了解使用条件跳转命令来计算
两个分支并使用条件移动命令会更快,这
不涉及分支预测器。
无分支的实现代码:
SetFlag(Flags&, Flags, bool): # @SetFlag(Flags&, Flags, bool) mov eax, dword ptr [rdi] or eax, esi test edx, edx mov ecx, 31 cmove ecx, edx shr esi, cl not esi or esi, edx and esi, eax mov dword ptr [rdi], esi ret
几乎是“无分支的”-实际上,我在这里命令进行通常的乘法运算,而您,我的朋友,提出了有条件的举动。 也许编译器是正确的,在这种情况下,test + cmove会比imul快,但是我不太擅长汇编器(有知识的人,请在注释中告诉我)。
另一件事很有趣-实际上,对于优化之后的两个实现,编译器都没有完全生成我们所要求的结果,结果我们介于两者之间:在两个变体中都使用了cmove,在无分支实现中我们只有很多其他算法,这使基准不堪重负。
第八版及更早版本的Clang通常使用实际的条件转换,“无分支”版本的“慢速翻译”因此而变得几乎慢了一半半:
SetFlag(Flags&, Flags, bool): # @SetFlag(Flags&, Flags, bool) mov eax, dword ptr [rdi] or eax, esi mov cl, 31 test edx, edx jne .LBB0_2 xor ecx, ecx .LBB0_2: shr esi, cl not esi or esi, edx and eax, esi mov dword ptr [rdi], eax ret
可以得出什么结论? 除了明显的“不要进行不必要的微优化”之外,除非您可以建议您始终检查使用机器代码的结果,否则可能会证明编译器已经对初始版本进行了充分的优化,而“精明的”优化将无法理解它,尽管如此,您仍将考虑条件过渡而不是乘法。
此时,即使不是一个“ but”,也有可能完成。 天真的实现的gcc代码与clang代码相同,但是无分支版本是..:
SetFlag(Flags&, Flags, bool): movzx edx, dl mov eax, esi or eax, DWORD PTR [rdi] mov ecx, edx sal ecx, 5 sub ecx, edx shr esi, cl not esi or esi, edx and esi, eax mov DWORD PTR [rdi], esi ret
我尊重开发人员以一种优雅的方式优化我们的表达而无需使用
imul或
cmove 。 此处发生的情况是:bool变量cond左移5个字符(因为我们的枚举类型为uint32_t,其大小为32位,即100000
2 ),然后从结果中减去它。 因此,在cond = true的情况下,我们得到11111
2 = 31
10,在其他情况下,我们得到0。 不用说,即使考虑到条件移动优化,这样的选择也比幼稚的选择要快。

好吧,结果是非常奇怪的-根据编译器的不同,不带分支的选项可能比带分支的实现更快或更慢。 让我们尝试使用gcc方法帮助clang并转换我们的表达式(同时根据de Morgan简化
~((y >> shiftSize * cond) & ~cond)的部分-这是clang和gcc共同完成的):
void SetFlagVerbose(Flags& x, Flags y, bool b) { constexpr auto shiftSize = sizeof(std::underlying_type_t<Flags>) + 1; x = Flags( (x | y) & ( ~(y >> ((b << shiftSize) - b)) | b) ); }
这样的提示只对clang的主干版本有效,它实际上会生成类似于gcc的代码(尽管在原始的“ branchless”中,它是相同的测试+ cmove)
MSVC呢? 在这两个版本中,没有分支,使用的是诚实的imul(我不知道比clang / gcc选项快/慢多少-quick-bench不支持此编译器),并且在朴素的版本中出现了条件跳转。 悲伤但真实。
总结
也许可以得出主要结论,即程序员在高级代码中的意图远未总是反映在机器代码中,这使微优化没有基准和查看清单就变得毫无意义。 此外,微优化的结果可能比普通版本更好或更差-一切都取决于编译器,如果项目是跨平台的,这可能是一个严重的问题。