解释地震数据的复杂性是由于以下事实:对于每项任务,都必须寻找单独的方法,因为每组此类数据都是唯一的。 手工处理需要大量的人工成本,并且结果通常包含与人为因素有关的错误。 使用神经网络进行解释可以大大减少体力劳动,但是数据的唯一性对这项工作的自动化施加了限制。
本文介绍了一个实验,该实验以来自北海的全标记数据为例,分析了神经网络在2D图像中自动分配地质层的适用性。
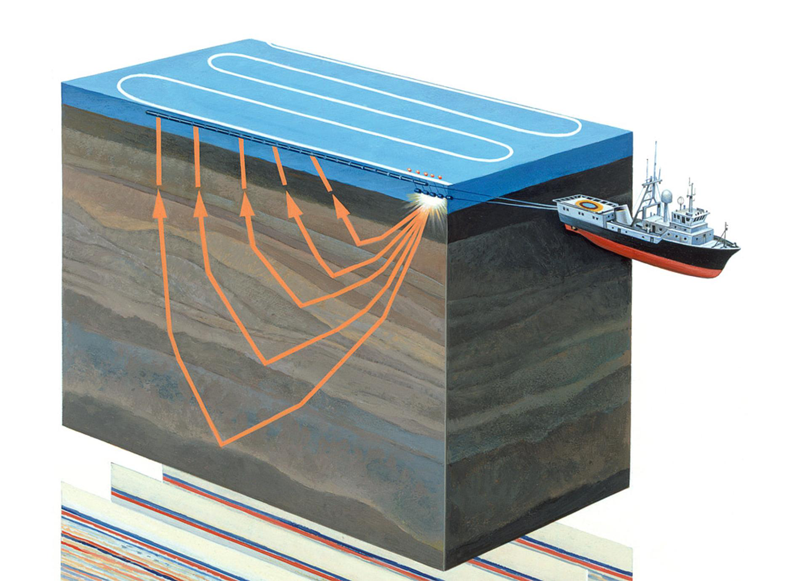
图1.海洋地震勘测(
来源 )
关于主题领域的一点
地震勘探是一种利用弹性振动(地震波)研究地质对象的地球物理方法。 该方法基于以下事实:地震波的传播速度取决于地震波在其中传播的地质环境的性质(岩石成分,孔隙率,裂缝,水分饱和度等)。穿过具有不同性质的地质层,地震波从不同的对象并返回给接收者(参见图1)。 记录它们的性质,经过处理后,您可以形成二维图像-地震剖面或三维数据数组-地震立方体。
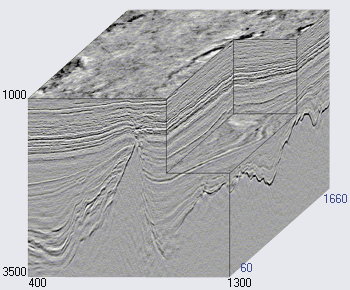
图2.地震立方体的一个示例(
来源 )
地震立方体的水平轴沿地球表面定位,垂直轴表示深度或时间(见图2)。 在某些情况下,立方体沿地震检波器的轴线(所谓的内联线,内联线)或跨过(交叉线,交叉线,x线)分为垂直部分。 每个立方体垂直(和切片)都是独立的地震迹线。
因此,内联线和交叉线由相同的地震轨迹组成,只是顺序不同。 相邻的地震道非常相似。 在故障点上发生了更为戏剧性的变化,但是仍然存在相似之处。 这意味着相邻切片彼此非常相似。
在计划实验时,所有这些知识将对我们有用。
解释任务及其在解决方案中的作用
解释员手动处理获得的数据,他们直接在立方体或每个切片上识别出其单独的地质岩石层及其边界(地平线,地平线),盐矿,断层和研究区域地质结构的其他特征。 解释器使用多维数据集或切片,开始进行艰苦的手动选择地质层和地层的工作。 必须通过指向光标并单击鼠标来手动刺入每个地平线(来自英语“ picking”(收藏))。
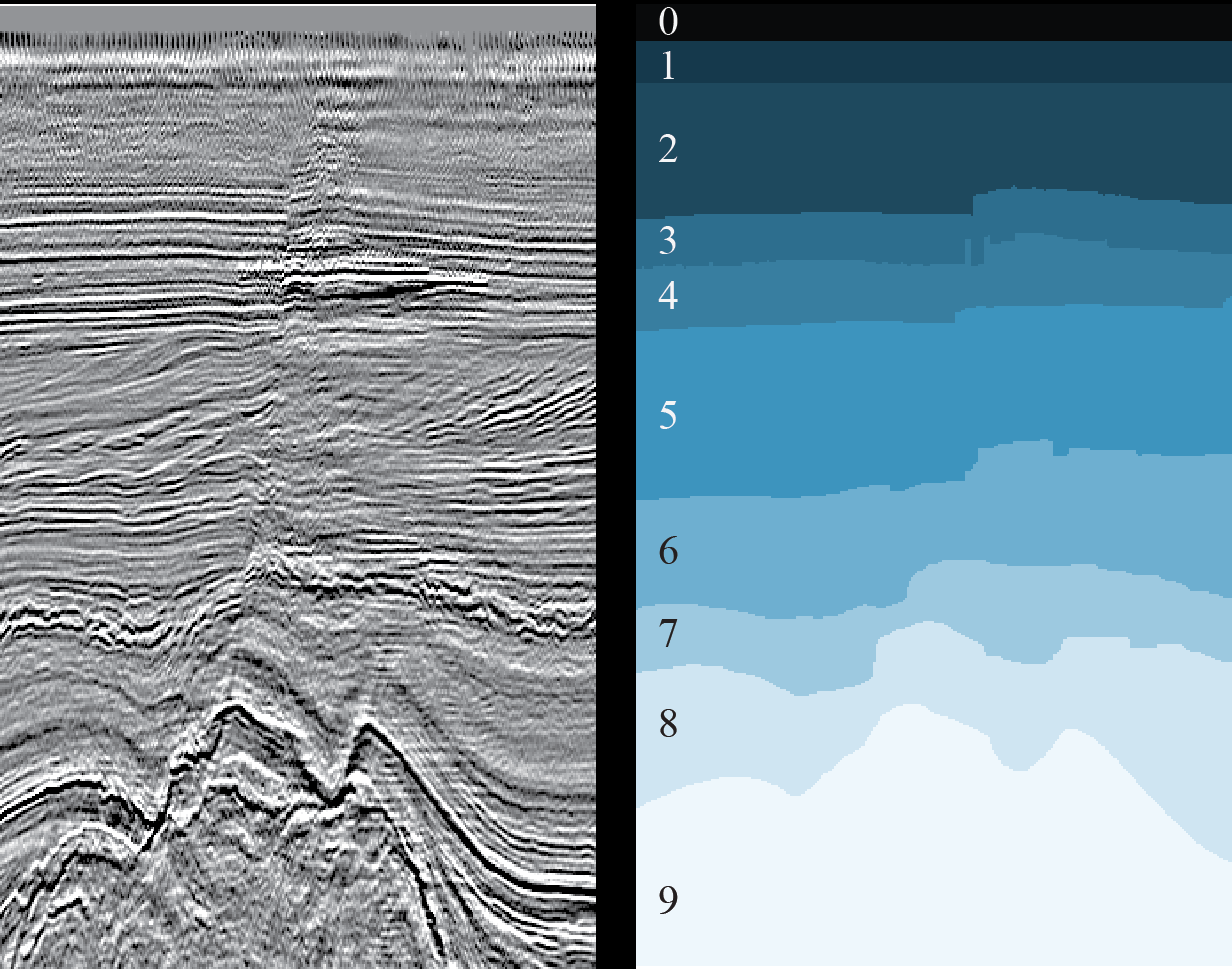
图3. 2D切片的示例(左)和相应的地质层标记的结果(右)(
源 )
主要问题与在日益复杂的地质条件下(例如,海深的水下部分)每年获取的地震数据不断增加以及这些数据的解释含糊不清有关。 另外,在时间紧迫和/或交易量大的情况下,口译员不可避免地会犯错误,例如错过了地质部分的各种特征。
借助神经网络可以部分解决此问题,从而大大减少了体力劳动,从而加快了解释过程并减少了错误数量。 对于神经网络的操作,需要一定数量的现成的,带有标签的部分(立方体的部分),因此将获得所有部分(或整个立方体)的完整标记,理想情况下,仅需人工进行一点细微的调整即可调整地平线的某些部分或重新标记小区域,网络无法正确识别。
对于使用神经网络进行解释的问题,有很多解决方案,这里仅举几个例子:
一 ,
二 ,
三 。 困难在于每个数据集都是唯一的-由于研究区域的地质岩石的特殊性,由于地震勘探的各种技术手段和方法,以及用于将原始数据转换为现成数据的各种方法。 即使由于外部噪声(例如,狗叫声和其他大声声音),也无法始终将其完全消除。 因此,每个任务必须单独解决。
但是,尽管如此,许多著作仍使我们有可能寻求解决各种解释问题的单独的一般方法。
我们在
MaritimeAI (一个由社交产品机器学习
ODS社区开发的项目,
有关我们的文章 )上对我们感兴趣的领域(海洋研究)研究的每个区域已经发表的作品并进行了自己的实验,从而使我们能够阐明某些应用的边界和特征解决方案,有时会找到自己的方法。
我们在本文中描述的一个实验的结果。
商业研究目标
数据科学专家只要放轻松一下就可以看一下图3,这是语义图像分割的一项常见任务,为此发明了许多神经网络体系结构和教学方法。 您只需要选择合适的培训网络即可。
但不是那么简单。
为了在神经网络的帮助下获得良好的结果,您需要尽可能多的已标记数据,以供其学习。 但是,我们的任务恰恰是减少手工工作量。 而且,由于它们在地质结构上的巨大差异,很少使用来自其他地区的标记数据。
我们将以上内容翻译成商务语言。
为了在经济上合理地使用神经网络,有必要将主要的人工解释和获得的结果的精简数量减至最少。 但是减少用于训练网络的数据将负面影响其结果的质量。 那么,神经网络能否加快和促进口译员的工作并提高标记图像的质量? 还是只是使通常的过程变得复杂?
这项研究的目的是尝试确定神经网络标记的地震立方数据的最小足够量,并评估所获得的结果。 我们试图找到以下问题的答案,这将有助于地震勘测结果的“所有者”决定手动或部分自动解释:
- 专家需要多少数据来标记训练神经网络? 而应该为此选择什么数据?
- 这样的输出会发生什么? 是否需要人工完善神经网络预测? 如果是这样,那么复杂和庞大?
实验的一般说明和使用的数据
对于实验,我们选择了一种解释性问题,即隔离地震立方体的2D截面上的地质层的任务(请参见图3)。 我们已经尝试解决此问题(请参阅
此处 ),并且据作者所述,对于1%的随机选择的切片,其效果很好。 给定立方体的体积,这些是16张图像。 但是,本文没有提供用于比较的指标,也没有描述训练方法(损失函数,优化器,用于更改学习速度的方案等),这使得实验无法重现。
此外,我们认为,此处提出的结果不足以完全解决所提出的问题。 这个值是否最佳为1%? 或者,对于另一个切片样本,它会有所不同吗? 我可以选择更少的数据吗? 值得多吃点吗? 结果将如何变化? 等等
对于实验,我们从北海的荷兰地区获取了相同的一组完全标记的数据。 原始地震数据可在Open Seismic Repository:
Project Netherlands Offshore F3 Block网站上找到。 简短的描述可以在
Silva等人的文章中找到
。 “荷兰数据集:地震解释中机器学习的新公共数据集 。
”由于在我们的案例中,我们是在谈论2D切片,因此我们没有使用原始的3D立方体,而是使用了已经提供的“切片”,可在此处找到:
荷兰F3解释数据集 。
在实验过程中,我们解决了以下任务:
- 我们查看了源数据并选择了质量与手动标记最接近的切片。
- 我们记录了神经网络的体系结构,训练的方法和参数,以及选择用于训练和验证的切片的原理。
- 我们在相同类型的切片的不同数据量上训练了20个相同的神经网络,以比较结果。
- 我们在不同类型的切片的不同数据量上训练了另外20个神经网络,以比较结果。
- 估计了预测结果所需的手动优化量。
实验结果以估计量度的形式显示,并由切片蒙版的网络预测。
任务1.数据选择
因此,作为初始数据,我们使用了来自北海荷兰地区的地震立方体的现成内嵌线和交叉线。 进行了详细的分析后,发现那里并不是所有的事物都是平滑的-有很多图像和遮罩以及伪影,甚至还有严重失真的图像和遮罩(见图4和5)。

图4.带有伪影的示例蒙版
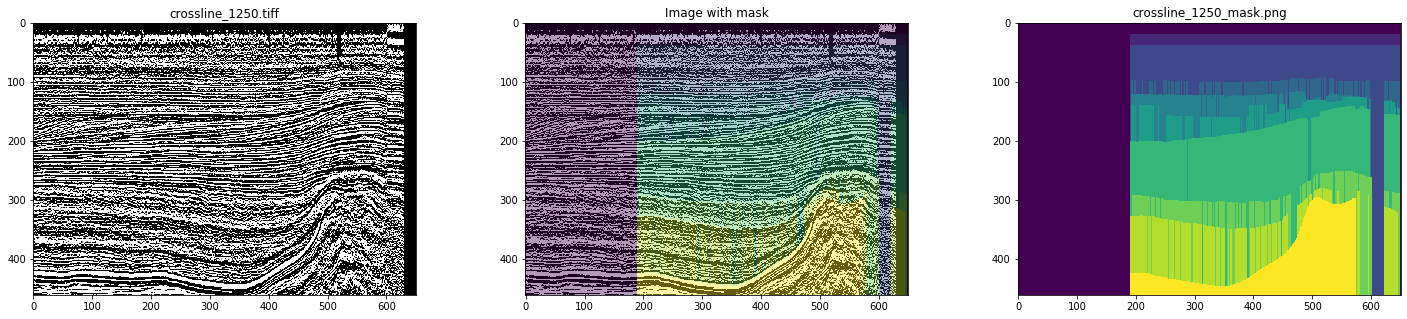
图5.变形的蒙版示例
使用手动标记,将不会观察到任何东西。 因此,在模拟口译员的工作,训练网络时,我们只看了所有切片就只选择了干净的口罩。 结果,选择了700个交叉线和400个内联线。
任务2.固定实验参数
首先,对于数据科学领域的专家而言,本节很有趣,因此,将使用适当的术语。
由于内线和交叉线包含相同的地震迹线,因此可以提出两个互斥的假设:
- 使用另一种类型的图像作为延迟选择,只能对一种类型的切片(例如,内联)进行训练。 这将对结果进行更充分的评估,因为 训练中使用的相同类型的其余切片仍将类似于训练的切片。
- 对于训练,最好混合使用不同类型的切片,因为这是现成的增强方法。
看看吧。
另外,相同类型的相邻切片的相似性以及获得可再现结果的愿望使我们找到了一种选择切片进行训练和验证的策略,而不是通过任意原理,而是在整个立方体(即整个立方体)中进行统一选择。 因此,切片之间的距离越远越好,因此覆盖了最大数量的数据。
为了验证,使用了2个切片,它们也均匀分布在训练样本的相邻图像之间。 例如,对于训练样本为3个内联的情况,验证样本由4个内联组成,其中3个内联和3个交叉线分别为8个切片。
因此,我们进行了2期培训:
- 对3到20个切片的内联样本进行训练,均匀地分布在多维数据集上,并验证其余内联和所有交叉线上的网络预测结果。 此外,还对80和160个部分进行了培训。
- 来自每个类型的3-10个部分的内联线和交叉线的组合样本中的训练均匀地分布在一个多维数据集上,并验证其余图像中网络预测的结果。 此外,还对40 + 40和80 + 80的部分进行了培训。
使用这种方法时,应考虑到训练样本和验证样本的大小差异很大,这使比较变得复杂,但是剩余图像的体积并没有减少太多,因此无法用于评估结果的变化。
为了减少训练样本的再训练,对任意作物尺寸448x64进行了增强,并沿垂直轴使用镜像图像,概率为0.5。
由于我们只对结果质量的依赖依赖于训练样本中的切片数感兴趣,因此可以忽略图像的预处理。 我们使用了一层PNG图片,没有任何更改。
出于同样的原因,在本实验的框架内,无需寻找最佳的网络体系结构-主要是每个步骤都相同。 我们为这些任务选择了一个简单但完善的UNet:

图6.网络架构
损失函数由提花系数和二进制交叉熵组成:
def jaccard_loss(y_true, y_pred): smoothing = 1. intersection = tf.reduce_sum(y_true * y_pred, axis = (1, 2)) union = tf.reduce_sum(y_true + y_pred, axis = (1, 2)) jaccard = (intersection + smoothing) / (union - intersection + smoothing) return 1. - tf.reduce_mean(jaccard) def loss(y_true, y_pred): return 0.75 * jaccard_loss(y_true, y_pred) + 0.25 * keras.losses.binary_crossentropy(y_true, y_pred)
其他学习选择:
keras.optimizers.SGD(lr = 0.01, momentum = 0.9, nesterov = True) keras.callbacks.EarlyStopping(monitor = 'val_loss', patience = 10), keras.callbacks.ReduceLROnPlateau(monitor = 'val_loss', patience = 5)
为了减少初始权重选择的随机性对结果的影响,该网络在1个时代的3个内联线上进行了训练。 所有其他培训都从获得这些权重开始。
每个网络都在GeForce GTX 1060 6Gb上进行了30-60个时期的培训。 每个时代的训练需要10到30秒,具体取决于样本大小。
任务3.对一种类型的切片进行训练(内联)
第一个系列包括3至20个内联的18个独立网络培训。 而且,尽管我们仅对估计未用于训练和验证的切片上的提花系数感兴趣,但考虑所有图很有意思。
回想一下,每个切片的解释结果为10类(地质层),在图中用0到9的数字进一步标记。

图7.训练集的提花系数

图8.验证样本的提花系数
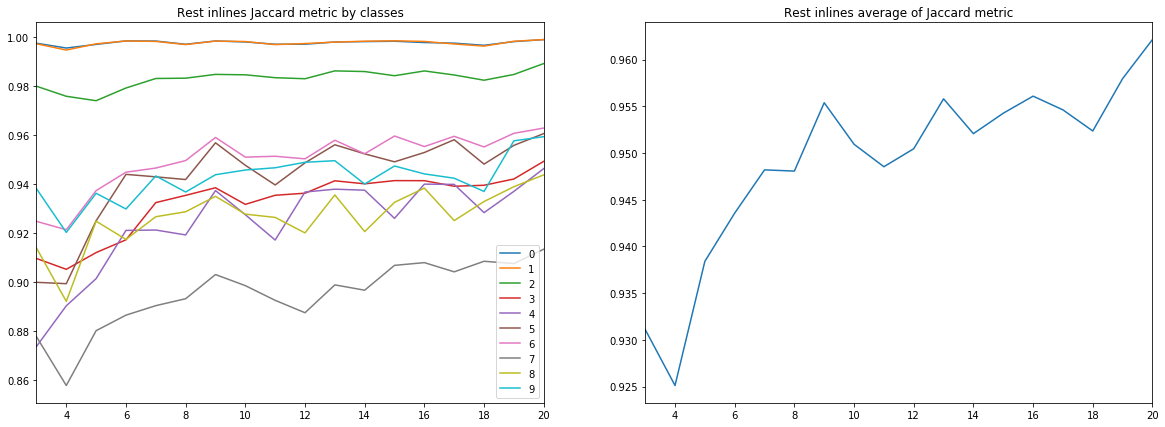
图9.其余内联的提花系数
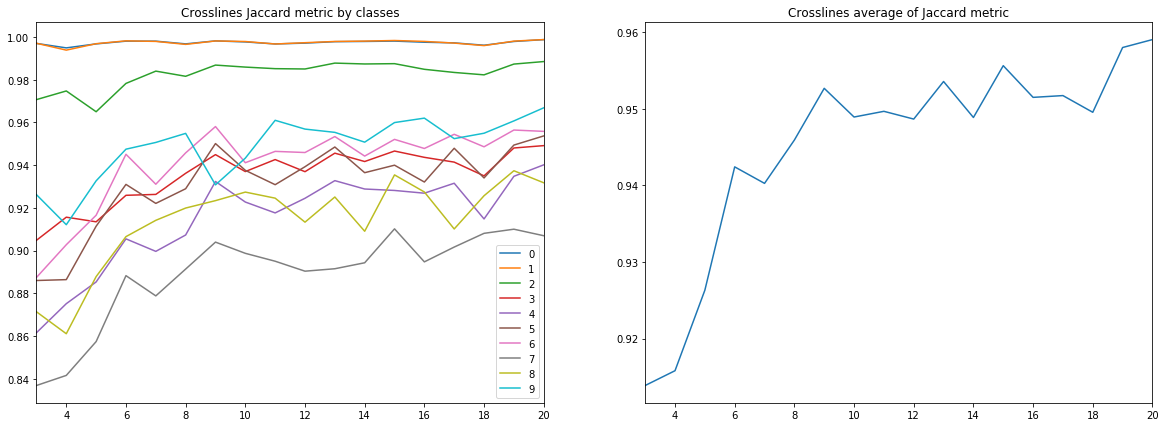
图10.交叉线的提花系数
从以上图表可以得出许多结论。
首先,通过提花系数测得的预测质量已经达到9根线,达到了很高的值,此后它继续增长,但没有那么集中。 即 证实了用于训练神经网络的少量标记图像足够的假设。
其次,尽管仅使用内联进行训练和验证,但交叉线却获得了非常高的结果-也证实了仅一种类型的切片足够的假设。 但是,要得出最终结论,您需要将结果与内联线和交叉线混合训练的结果进行比较。
第三,不同层的指标,即 他们认可的质量大不相同。 这导致了选择不同学习策略的想法,例如,对弱势群体使用权重或其他网络,或者采用成熟的“一对多”方案。
最后,应该指出的是,提花系数不能完整描述结果的质量。 为了在这种情况下评估网络预测,最好查看掩码本身,以评估其是否适合口译员进行修订。
下图显示了经过10个内联训练的网络的标记。 第二列标记为“ GT蒙版”(Ground Truth蒙版),表示目标解释,第三列是神经网络的预测。


图11.内联的网络预测示例
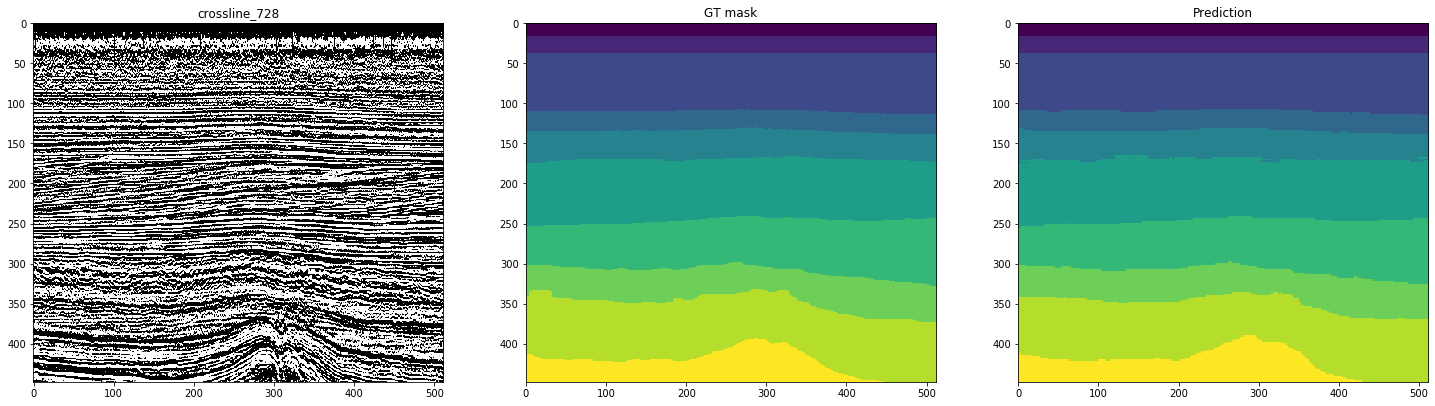

图12.交叉线的网络预测示例
从图中可以看出,连同相当干净的掩码,即使是在线上也很难识别复杂的案例。 因此,尽管有足够高的度量标准可用于10个切片,但部分结果仍需要大量改进。
我们考虑的样本量在总数据量的1%左右波动-这已经使得可以很好地标记出其余切片的一部分。 我应该增加最初标记的部分的数量吗? 这样会提高质量吗?
让我们考虑以相同的部分为例,对在5、10、15、20、80(占总立方体体积的5%)和160(10%)的内联线上训练的网络进行预测结果变化的动态。
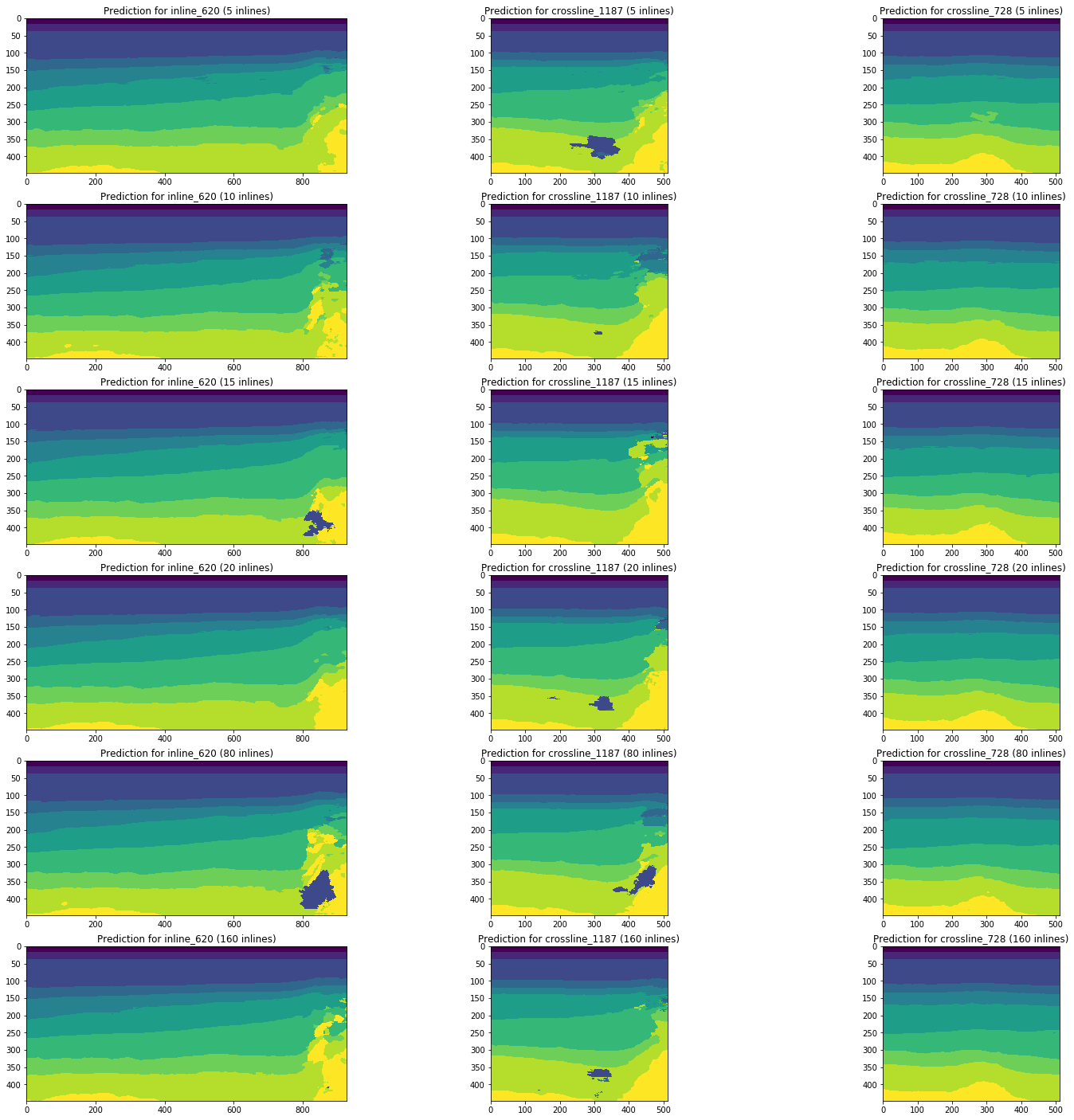
图13.在不同数量的培训样本上接受培训的网络的预测示例
图13显示,训练样本的体积增加5倍甚至10倍不会导致显着改善。 在10个训练图像中已经被很好地识别的切片不会变差。
因此,即使是没有图像调整和预处理的简单网络也能够以少量的手动标记图像来以足够高的质量来解释部分切片。 我们将考虑这样的解释所占份额以及最终确定识别不佳的切片的复杂性问题。
仔细选择架构,网络参数和训练,图像预处理可以在相同数量的标记数据上改善这些结果。 但这已经超出了当前实验的范围。
任务4.训练不同类型的切片(内联线和交叉线)
现在,让我们将该系列的结果与通过对内联线和交叉线进行混合训练而获得的预测进行比较。
下图显示了不同样品的提花系数估算值,包括与先前系列结果的比较。 为了进行比较(请参见图中的右图),仅采集了相同体积的样品,即 10行与5行+ 5条交叉线等

图14.训练集的提花系数

图15.验证样本的提花系数

图16.其余内联的提花系数

图17.其余交叉线的提花系数
这些图清楚地说明,添加不同类型的切片不会改善结果。 即使在分类的情况下(参见图18),对于任何考虑的样本量,也没有观察到交叉线的影响。

图18.不同类别(沿X轴)以及训练样本的不同大小和组成的提花系数
为了使图片更完整,我们在相同的切片上比较了网络预测的结果:
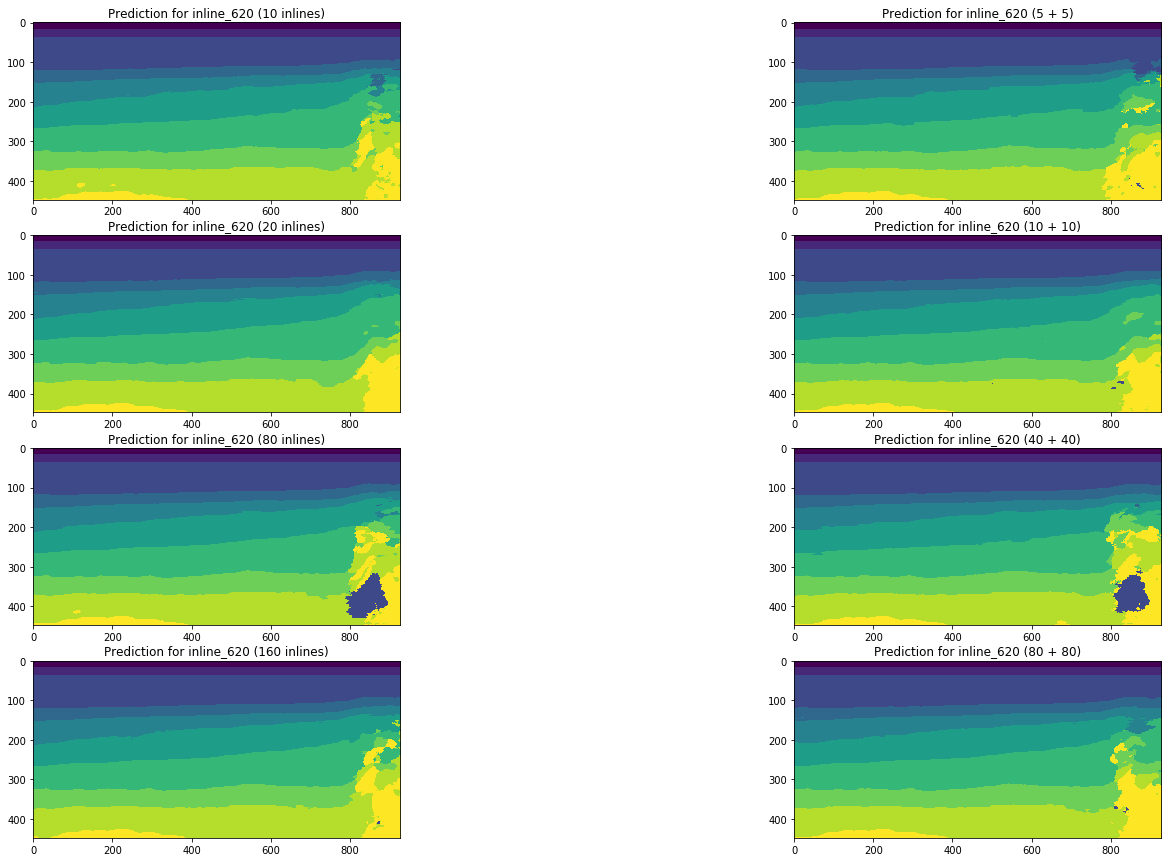
图19.内联的网络预测比较
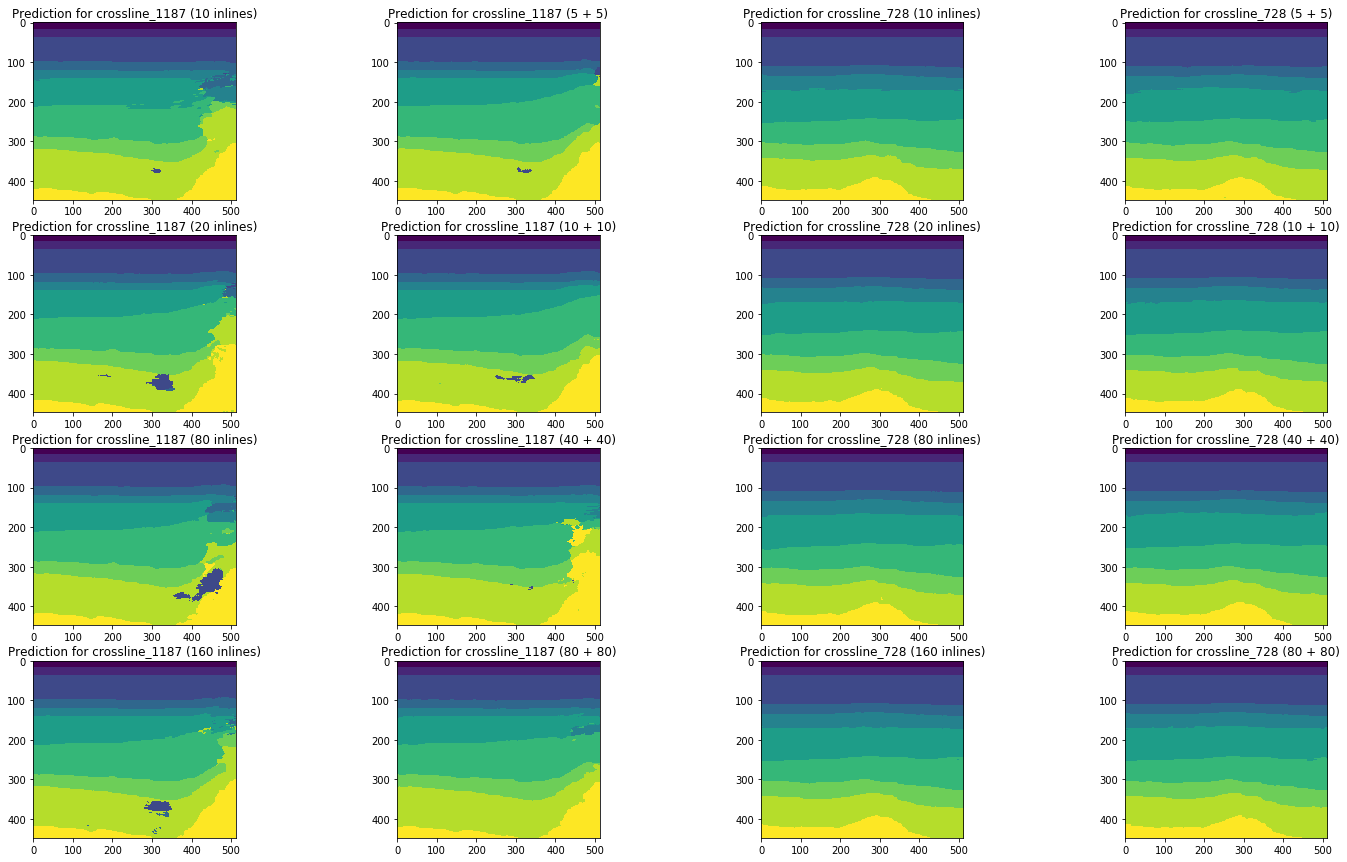
图20.交叉线的网络预测比较
视觉比较证实了这样的假设,即向训练中添加不同类型的切片不会从根本上改变情况。 只能从左侧交叉线观察到一些改进,但是它们是全局的吗? 我们将尝试进一步回答这个问题。
任务5.评估手动优化的数量
对于结果的最终结论,有必要估计获得的网络预测的人工改进量。 为此,我们在获得的每个预测中确定了连接的组件(即相同颜色的实心斑点)的数量。 如果该值为10,则正确选择了图层,我们正在谈论的是次地平线校正的最大值。 如果没有更多,则只需要“清洁”图像的小区域。 如果有更多的话,那么一切都不好,甚至可能需要重新布局。
为了进行测试,我们选择了110条内联线和360条交叉线,这些线在训练任何考虑的网络中都没有使用。
表1.两种切片的平均统计量
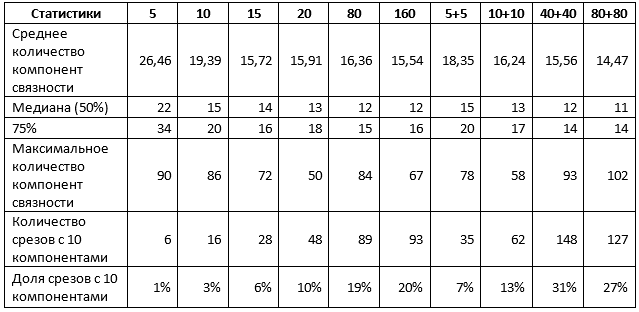
表1证实了一些先前的结果。 特别是,使用1%的切片进行训练时,没有区别,可以使用一种类型的切片,也可以同时使用两种切片,其结果可以表征为:
- 大约10%的预测接近理想水平,即 仅需对地平线的各个部分进行调整;
- 50%的预测包含不超过15个斑点,即 最多不超过5个;
- 75%的预测包含不超过20个斑点,即 最多不超过10个;
- 剩下的25%的预测需要进行更大幅度的细化,包括可能对单个切片进行完全重新设计。
样本量最多增加5%会改变这种情况。 特别是,在各部分混合训练的网络中,指标的显示明显更高,尽管组件的最大值也有所增加,这表明出现了质量很差的单独解释。 但是,如果将样本增加5倍并混合使用切片:
- 大约30%的预测接近理想水平,即 仅需对地平线的各个部分进行调整;
- 50%的预测包含不超过12个斑点,即 最多不超过2个;
- 75%的预测包含不超过14个斑点,即 最多不超过4个;
- 剩下的25%的预测需要进行更大幅度的细化,包括可能对单个切片进行完全重新设计。
样本量的进一步增加不会导致结果改善。
通常,对于我们检查的数据立方体,我们可以得出有关总数据量的1-5%足够的结论,以便从神经网络中获得良好的结果。
根据这些数据,结合上述度量和说明,已经有可能得出关于使用神经网络来帮助口译员的建议以及专家将要处理的结果的结论。
结论
因此,现在我们可以使用在北海一个地震立方体的示例中获得的结果来回答本文开头提出的问题:
专家需要多少数据来标记训练神经网络? 我应该选择什么数据?要获得对网络的良好预测,预标记片总数的1%至5%就足够了。 与先前标记的数据数量的增加相比,体积的进一步增加不会导致结果的改善。 为了使用神经网络在如此小的体积上获得更好的标记,有必要尝试其他方法,例如,微调体系结构和学习策略,图像预处理等。
对于初步标记,值得选择两种类型的切片-内联线和交叉线。
这样的输出会发生什么? 是否需要人工完善神经网络预测? 如果是这样,那么复杂和庞大?
结果,由这样的神经网络标记的图像的很大一部分将不需要最重要的改进,包括对各个不良识别区域的校正。 其中将有不需要任何更正的解释。 并且仅对于单个图像,您可能需要新的手动布局。
当然,当优化学习算法和网络参数时,可以提高其预测能力。 在我们的实验中,不包括解决此类问题的方法。
此外,对一个地震立方体的一项研究结果不应该被深思熟虑地归纳-正是由于每个数据集的唯一性。 但是这些结果是对其他作者进行的实验的证实,也是与我们以后的研究进行比较的基础,我们将在稍后对此进行介绍。
致谢
最后,我要感谢
MaritimeAI的同事(特别是Andrey Kokhan)和
ODS的宝贵意见和帮助!
使用的来源清单:
- 巴斯·彼得斯,埃尔达·哈伯,贾斯汀·格兰尼克。 用于地球物理学家的神经网络及其在地震数据解释中的应用
- 吴浩,张波。 深度卷积编解码器神经网络辅助地震视线跟踪
- Thilo Wrona,Indranil Pan,Robert L.Gawthorpe和Haakon Fossen。 利用机器学习进行地震相分析
- Reinaldo Mozart Silva,Lais Baroni,Rodrigo S.Ferreira,Daniel Civitarese,Daniela Szwarcman,Emilio Vital巴西。 荷兰数据集:用于地震解释中机器学习的新公共数据集