本文包括两个部分:
- 简要介绍了一些用于检测图像中的对象和图像分割的网络体系结构,这些链接对我来说是对资源的最易理解的链接。 我尝试选择视频解释,最好选择俄语。
- 第二部分是尝试了解神经网络体系结构的发展方向。 以及基于它们的技术。

图1-了解神经网络的架构并不容易
一切始于他制作了两个演示应用程序来对Android手机上的对象进行分类和检测:
- 后端演示 ,在服务器上处理数据并传输到电话时。 三种类型的熊的图像分类:棕色,黑色和泰迪熊。
- 在手机上处理数据时的前端演示 。 三种类型的对象检测:榛子,无花果和枣。
在对图像进行分类,检测图像中的对象以及分割图像的任务之间存在区别。 因此,需要找出哪些神经网络架构可以检测图像中的对象以及哪些可以进行分割。 我找到了以下具有最易于理解的资源链接的体系结构示例:
- 基于R-CNN的一系列架构(具有C进化的N个区域的作品):R-CNN,Fast R-CNN, Faster R-CNN , Mask R-CNN 。 为了使用区域提议网络(RPN)机制检测图像中的对象,分配了边界框。 最初,使用较慢的“选择性搜索”机制代替了RPN。 然后,将所选的有限区域馈送到正常神经网络的输入以进行分类。 在R-CNN的体系结构中,在有限的区域内存在明确的“ for”枚举循环,通过内部AlexNet网络总共可以运行多达2000次。 由于显式的“ for”循环,图像处理速度会降低。 通过内部神经网络运行的显式循环数随着体系结构的每个新版本而减少,并且进行了许多其他更改以提高速度,并用Mask R-CNN中的对象分割来代替检测对象的任务。
- YOLO (your lyn ook Once)是第一个在移动设备上实时识别对象的神经网络。 特色:一次运行即可区分对象(只需查看一次)。 也就是说,YOLO体系结构中没有明确的“ for”循环,这就是网络速度快的原因。 例如,这是一个类比:在NumPy中,使用矩阵的操作中没有明确的“ for”循环,这些循环在NumPy中通过编程语言C在较低的体系结构中实现。YOLO使用预定义窗口的网格。 为了防止多次检测到同一对象,使用了窗口重叠系数(IoU,交叉口或并集)。 该体系结构可在广泛的范围内工作,并且具有很高的鲁棒性 :可以在照片中训练模型,但同时在绘画作品中也能很好地工作。
- SSD (Single S hot MultiBox Dector)-使用YOLO架构中最成功的“ hacks”(例如,非最大抑制),并添加了新的“ hacks”以使神经网络更快,更准确。 独特功能:使用图像金字塔上的给定窗口网格(默认框),一次运行即可区分对象。 在连续的卷积和合并操作期间,图像金字塔在卷积张量中进行编码(使用最大池操作时,空间尺寸会减小)。 通过这种方式,可以在单个网络运行中确定大型对象和小型对象。
- MobileSSD( 移动 NetV2 + SSD )是两种神经网络体系结构的组合。 第一个MobileNetV2网络速度很快,并提高了识别准确性。 使用MobileNetV2代替原始文章中最初使用的VGG-16。 第二个SSD网络确定图像中对象的位置。
- SqueezeNet是一个很小但准确的神经网络。 就其本身而言,它不能解决检测物体的问题。 但是,可以在组合各种体系结构时使用它。 并在移动设备上使用。 一个独特的功能是,首先将数据压缩到四个1×1卷积滤波器,然后扩展到四个1×1和四个3×3卷积滤波器。 数据压缩扩展的一种此类迭代称为“ Fire Module”。
- DeepLab (带有深度卷积网络的语义图像分割)-图像中对象的分割。 该体系结构的一个显着特征是稀释的卷积,可保留空间分辨率。 接下来是使用图形概率模型(条件随机字段)对结果进行后处理的阶段,该模型可让您去除分割中的细微噪声并提高分割图像的质量。 强大的名称“图形概率模型”的后面是通常的高斯滤波器,其近似值有5个点。
- 我试图了解RefineDet设备(用于对象检测的单发细化神经网络),但了解得很少。
- 我还研究了注意力技术的工作原理: video1 , video2 , video3 。 “注意力”架构的一个显着特征是使用称为注意力单元的神经网络自动分配对图像增加关注的区域(RoI,最有趣的区域)。 注意力增加的区域类似于有限区域(边界框),但与它们不同的是,它们并不固定在图像上,并且可能具有模糊的边框。 然后,从关注度更高的区域中,区分出“馈入”具有LSDM,GRU或Vanilla RNN体系结构的递归神经网络的特征(特征)。 递归神经网络能够分析序列中符号的关系。 递归神经网络最初用于将文本转换为其他语言,现在用于将图像转换为文本并将文本转换为图像 。
在研究这些架构时, 我意识到自己一无所知 。 关键不是我的神经网络的注意力机制有问题。 创建所有这些架构看起来像某种大型黑客马拉松,作者在其中参与竞争。 Hack是解决难题的快速解决方案。 也就是说,所有这些体系结构之间都没有可见的和可理解的逻辑连接。 使他们团结在一起的是彼此借鉴的一组最成功的hack,再加上带有反馈 (错误的反向传播,反向传播)的常见卷积操作 。 没有系统的思考 ! 尚不清楚要更改什么以及如何优化现有成就。
由于黑客之间缺乏逻辑联系,因此很难记住它们并将其付诸实践。 这是零散的知识。 在最好的情况下,会记住一些有趣和意外的时刻,但是大多数理解的和难以理解的时刻会在几天之内从记忆中消失。 如果我至少在一周内记得建筑的名称,那将是一件好事。 但是花了几个小时甚至几天的时间才能阅读文章和观看评论视频!
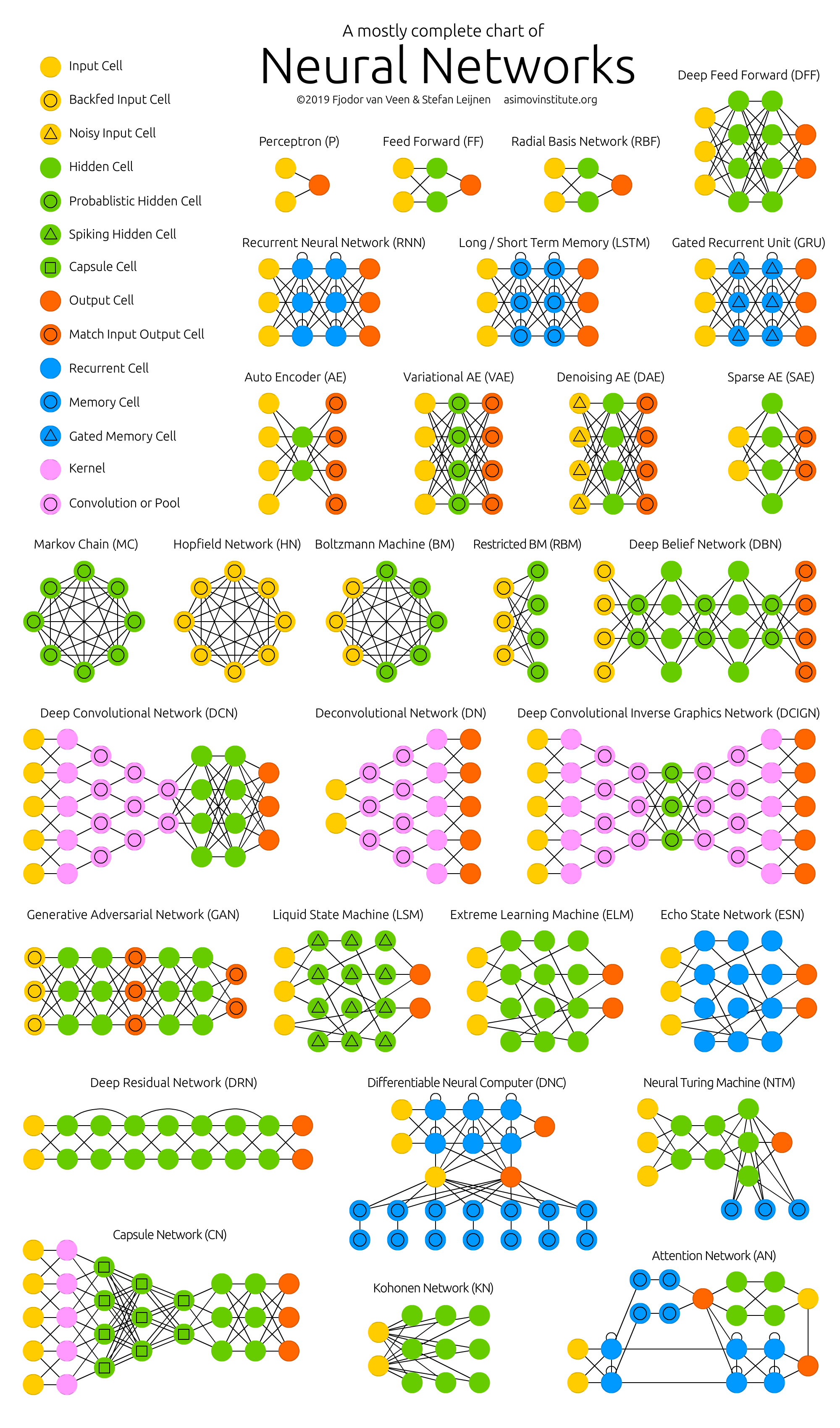
图2- 神经网络的动物园
我个人认为,大多数科学文章的作者都竭尽所能,以至于读者即使不理解这些零散的知识。 但是,十行句子中的“从天花板上取”公式的分词是另一篇文章的主题( 发布或灭亡问题)。
因此,有必要对神经网络上的信息进行系统化,从而提高理解和记忆的质量。 因此,分析人工神经网络的各个技术和体系结构的主要主题是以下任务: 找出所有这些东西在哪里移动 ,而不是单独地分离任何特定神经网络的设备。
这一切都去哪儿了。 主要结果:
- 在过去两年中,机器学习领域的初创公司数量急剧下降 。 可能的原因:“神经网络不再是新事物。”
- 每个人都将能够创建一个有效的神经网络来解决一个简单的问题。 为此,请从“模型动物园”中获取完成的模型,并在Google Dataset Search或免费的Jupyter Notebook云中的2.5万个Kaggle数据集的完成数据上训练神经网络的最后一层( 转移学习 )。
- 神经网络的大型制造商开始创建“模型动物园” (model zoo)。 有了它们,您可以快速进行商业应用:用于TensorFlow的TF Hub ,用于PyTorch的MMDetection,用于Caffe2的Detectron,用于Chainer的chainer-modelzoo 等 。
- 移动设备上的实时神经网络。 每秒10到50帧。
- 在电话(TF Lite),浏览器(TF.js)和家居用品 (物联网,互联网和Ting)中使用神经网络。 尤其是在已经在硬件级别支持神经网络的电话(神经加速器)中。
- “每个设备,衣服甚至是食物都将具有IP-v6地址并彼此通信” -Sebastian Trun 。
- 自2015年以来,机器学习出版物的增长已开始超过摩尔定律 (每两年翻一番)。 显然,需要文章分析神经网络。
- 以下技术变得越来越流行:
- PyTorch-流行度正在迅速增长,并且似乎已经超过了TensorFlow。
- 自动选择AutoML超参数-流行度正在平稳增长。
- 精度逐渐降低,计算速度提高: 模糊逻辑 , 增强算法,不准确(近似)计算,量化(将神经网络的权重转换为整数并进行量化时),神经加速器。
- 图像转换为文本 , 文本转换为图像 。
- 现在可以实时在视频上创建三维对象 。
- DL中的主要内容是大量数据,但是收集和标记它们并不容易。 因此,正在开发使用神经网络的神经网络的自动注释 。
- 有了神经网络,计算机科学突然成为一门实验科学,并且出现了可再现性危机 。
- 当计算成为市场价值时,IT资金和神经网络的普及同时出现。 黄金和外汇的经济正在成为黄金货币的计算 。 请参阅我关于经济物理学的文章以及出现IT金钱的原因。
逐渐地,出现了一种新的ML / DL编程方法 (机器学习和深度学习),该方法基于该程序作为一组经过训练的神经网络模型的表示。
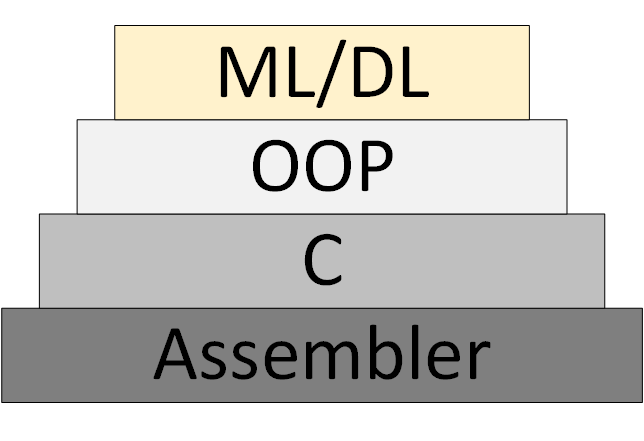
图3-ML / DL作为一种新的编程方法
但是,没有出现“神经网络理论” ,在此框架内人们可以系统地思考和工作。 现在所谓的“理论”实际上是实验性启发式算法。
不仅指向我的资源的链接:
- 数据科学通讯。 主要是图像处理。 谁想接收,让他发送电子邮件(foobar167 <gaff-gaf> gmail <dot> com)。 随着材料的积累,我发送了文章和视频的链接。
- 我已参加并希望参加的课程和文章的总清单 。
- 面向初学者的课程和视频 ,从中开始学习神经网络是值得的。 加上小册子“机器学习和人工神经网络简介”。
- 有用的工具 ,每个人都可以找到自己感兴趣的东西。
- 事实证明, 用于分析有关数据科学的科学文章的视频频道非常有用。 查找,订阅它们,并将链接发送给您的同事和我。 范例:
感谢您的关注!