 第一次才疼!
第一次才疼!大家好! 亲爱的朋友们,在本文中,我想分享基于
github.com/aidonchuk/retinanet-examples存储库的TensorRT,RetinaNet的经验(这是
nvidia的官方交钥匙的分支,这将使我们能够尽快开始在生产中使用优化的模型)。
滚动浏览ods.ai社区
频道时 ,我遇到了有关使用TensorRT的问题,并且大多数问题都在重复,因此我决定编写
尽可能全面的指南
,以基于TensorRT,RetinaNet,Unet和docker使用快速推理。
任务说明我建议以这种方式设置任务:我们需要标记数据集,在Pytorch1.3 +上训练RetinaNet / Unet网络,将接收到的权重转换为ONNX,然后将其转换为TensorRT引擎,然后在docker中运行整个过程,最好在Ubuntu 18上运行,最好在ARM(Jetson)*体系结构上使用,从而最大程度地减少了环境的手动部署。 结果,我们将准备好一个容器,不仅可以用于RetinaNet / Unet的导出和培训,还可以用于分类,分段和所有必要绑定的全面开发和培训。
阶段1.准备环境重要的是要注意,最近我完全放弃了台式机以及devbox上至少某些库的使用和部署。 您唯一需要创建和安装的是python虚拟环境和来自deb的cuda 10.2(可以将自己限制为单个nvidia驱动程序)。
假设您已经全新安装了Ubuntu18。请安装cuda 10.2(deb),在此我不会详细介绍安装过程,官方文档已经足够。
现在我们将安装docker,可以轻松找到docker安装指南,下面是一个示例
www.digitalocean.com/community/tutorials/docker-ubuntu-18-04-1-en ,已经提供19+版本。 好吧,不要忘记使不使用sudo的docker成为可能,它将更加方便。 一切都完成之后,我们这样做:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) curl -s -L https://nvidia.imtqy.com/nvidia-docker/gpgkey | sudo apt-key add - curl -s -L https://nvidia.imtqy.com/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit sudo systemctl restart docker
而且,您甚至不必查看官方资源库
github.com/NVIDIA/nvidia-docker 。
现在执行git clone
github.com/aidonchuk/retinanet-examples 。
剩下的只是一点点,为了开始将docker与nvidia-image结合使用,我们需要在NGC Cloud中注册并登录。 我们进入
ngc.nvidia.com ,进行注册,然后进入NGC云,请按屏幕左上角的SETUP或
单击此链接
ngc.nvidia.com/setup/api-key 。 点击“生成密钥”。 我建议保存它,否则下次访问它时,您将不得不重新生成它,并因此将其部署在新的独轮车上,重复此操作。
运行:
docker login nvcr.io Username: $oauthtoken Password: <Your Key> -
用户名只需复制。 好吧,考虑一下,环境已经部署好了!
阶段2.组装Docker容器在工作的第二阶段,我们将组装docker并熟悉其内部。
我们转到相对于retina-examples项目的根文件夹并运行
docker build --build-arg USER=$USER --build-arg UID=$UID --build-arg GID=$GID --build-arg PW=alex -t retinanet:latest retinanet/
我们通过将当前用户扔进来来收集docker-如果您在具有当前用户权限的已挂载VOLUME上编写某些内容,这将非常有用,否则会产生麻烦。
在Docker运行时,让我们探索Dockerfile:
FROM nvcr.io/nvidia/pytorch:19.10-py3 ARG USER=alex ARG UID=1000 ARG GID=1000 ARG PW=alex RUN useradd -m ${USER} --uid=${UID} && echo "${USER}:${PW}" | chpasswd RUN apt-get -y update && apt-get -y upgrade && apt-get -y install curl && apt-get -y install wget && apt-get -y install git && apt-get -y install automake && apt-get install -y sudo && adduser ${USER} sudo RUN pip install git+https://github.com/bonlime/pytorch-tools.git@master COPY . retinanet/ RUN pip install --no-cache-dir -e retinanet/ RUN pip install /workspace/retinanet/extras/tensorrt-6.0.1.5-cp36-none-linux_x86_64.whl RUN pip install tensorboardx RUN pip install albumentations RUN pip install setproctitle RUN pip install paramiko RUN pip install flask RUN pip install mem_top RUN pip install arrow RUN pip install pycuda RUN pip install torchvision RUN pip install pretrainedmodels RUN pip install efficientnet-pytorch RUN pip install git+https://github.com/qubvel/segmentation_models.pytorch RUN pip install pytorch_toolbelt RUN chown -R ${USER}:${USER} retinanet/ RUN cd /workspace/retinanet/extras/cppapi && mkdir build && cd build && cmake -DCMAKE_CUDA_FLAGS="--expt-extended-lambda -std=c++14" .. && make && cd /workspace RUN apt-get install -y openssh-server && apt install -y tmux && apt-get -y install bison flex && apt-cache search pcre && apt-get -y install net-tools && apt-get -y install nmap RUN apt-get -y install libpcre3 libpcre3-dev && apt-get -y install iputils-ping RUN mkdir /var/run/sshd RUN echo 'root:pass' | chpasswd RUN sed -i 's/PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config RUN sed 's@session\s*required\s*pam_loginuid.so@session optional pam_loginuid.so@g' -i /etc/pam.d/sshd ENV NOTVISIBLE "in users profile" RUN echo "export VISIBLE=now" >> /etc/profile CMD ["/usr/sbin/sshd", "-D"]
从文本中可以看到,我们将使用所有我们喜欢的工具,编译retinanet,分发基本工具以方便使用Ubuntu,并配置openssh服务器。 第一行只是nvidia映像的继承,我们在NGC Cloud中进行了登录,其中包含Pytorch1.3,TensorRT6.xxx和一堆库,这些库使我们能够为检测器编译cpp源代码。
阶段3.启动和调试Docker容器让我们继续使用容器和开发环境的主要情况,以启动,运行nvidia docker。 运行:
docker run --gpus all --net=host -v /home/<your_user_name>:/workspace/mounted_vol -d -P --rm --ipc=host -it retinanet:latest
现在,该容器位于ssh <curr_user_name> @localhost。 成功启动后,在PyCharm中打开项目。 接下来打开
Settings->Project Interpreter->Add->Ssh Interpreter
第一步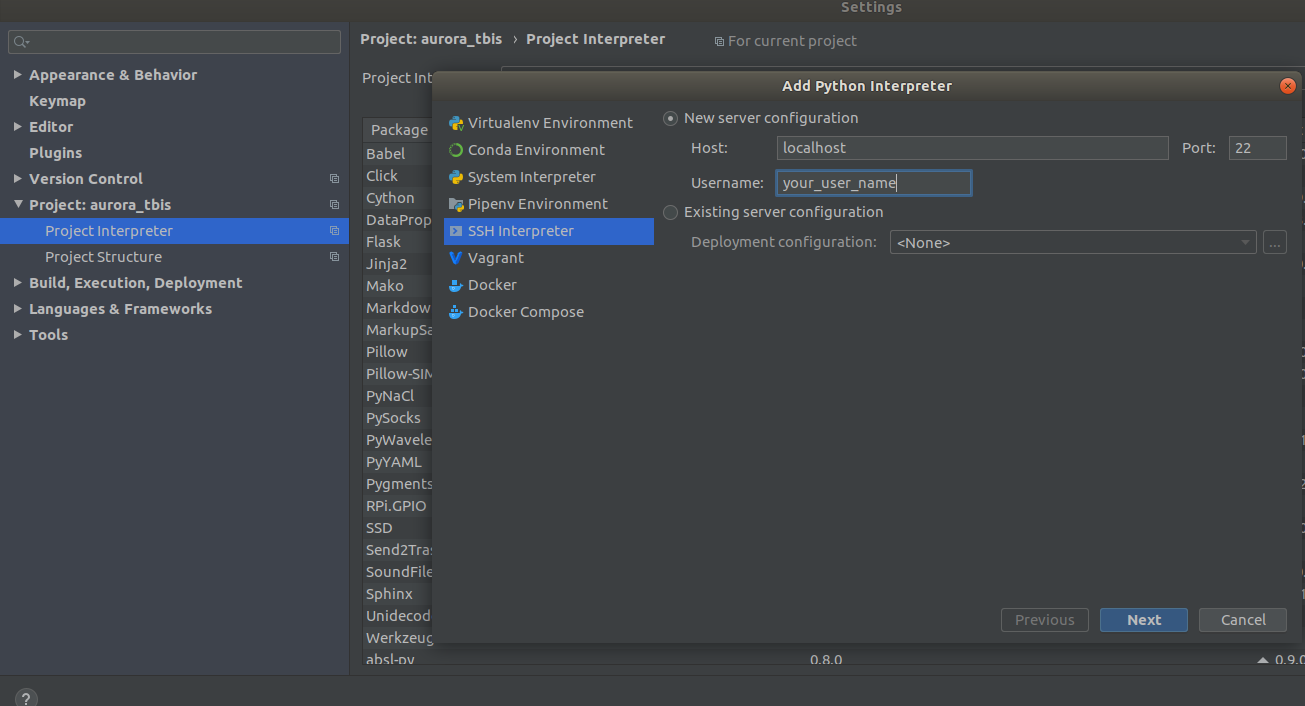 第二步
第二步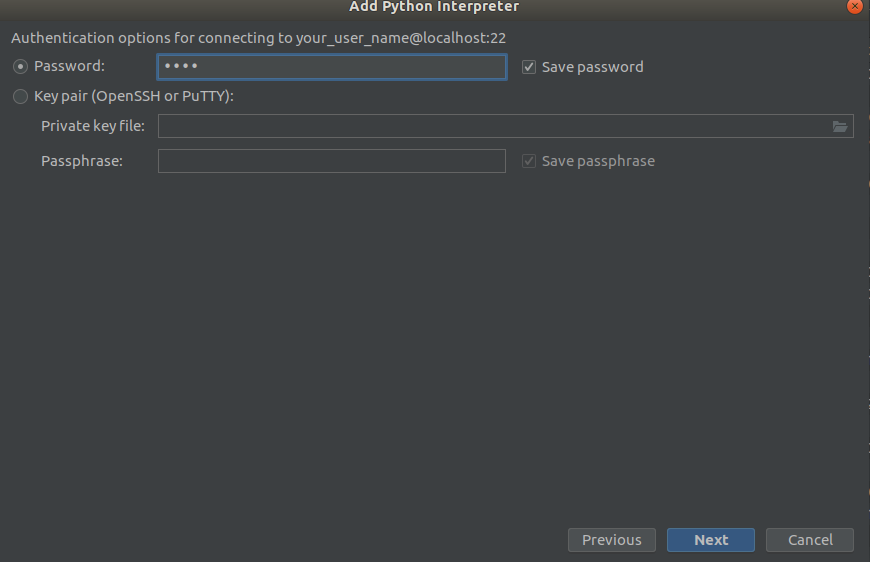 第三步
第三步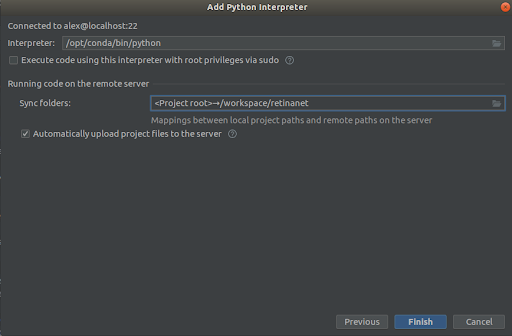
我们选择所有内容,如屏幕截图所示,
Interpreter -> /opt/conda/bin/python
-这将在python3.6和
Sync folder -> /workspace/retinanet
我们按完终点线,我们希望将其编入索引,就这样,环境就可以使用了!
重要! 索引后,立即从Docker提取Retinanet的已编译文件。 在项目根目录的上下文菜单中,选择
Deployment->Download
将显示一个文件和两个构建文件夹retinanet.egg-info和_so
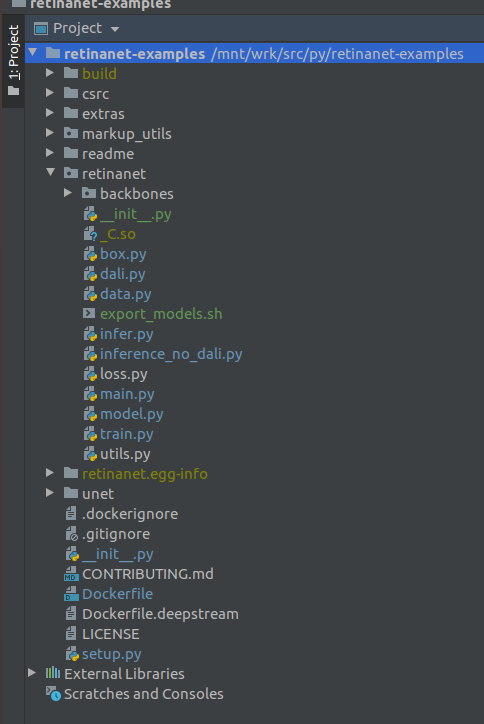
如果您的项目看起来像这样,那么环境将看到所有必需的文件,我们已经准备好学习RetinaNet。
阶段4.标记数据并训练检测器对于标记,我主要使用
supervise.ly-一个很好用且方便的工具,在最后一次修复一堆门框后,它的行为变得更好了。
假设您标记了一个数据集并下载了它,但是由于它是自己的格式,因此无法立即将其放入我们的RetinaNet中,为此我们需要将其转换为COCO。 转换工具位于:
markup_utils/supervisly_to_coco.py
请注意,脚本中的类别是一个示例,您需要插入自己的类别(无需添加类别类别)
categories = [{'id': 1, 'name': '1'}, {'id': 2, 'name': '2'}, {'id': 3, 'name': '3'}, {'id': 4, 'name': '4'}]
出于某种原因,原始存储库的作者决定除了培训COCO / VOC之外,您将不训练其他任何东西,因此我不得不稍稍修改源文件
retinanet/dataset.py
通过添加tutda,您最喜欢的增强程序albumentations.readthedocs.io/en/latest并从COCO中删除硬连线的类别。 如果要在大图片中查找小物体,并且数据集很小,=),则可能会散布较大的检测区域,但没有任何效果,但是在另一时间更有用。
通常,火车循环也很弱,最初它没有保存检查点,它使用了一些糟糕的调度程序,等等。 但是现在您要做的就是选择主干并执行
/opt/conda/bin/python retinanet/main.py
带有参数:
train retinanet_rn34fpn.pth --backbone ResNet34FPN --classes 12 --val-iters 10 --images /workspace/mounted_vol/dataset/train/images --annotations /workspace/mounted_vol/dataset/train_12_class.json --val-images /workspace/mounted_vol/dataset/test/images_small --val-annotations /workspace/mounted_vol/dataset/val_10_class_cropped.json --jitter 256 512 --max-size 512 --batch 32
在控制台中,您将看到:
Initializing model... model: RetinaNet backbone: ResNet18FPN classes: 2, anchors: 9 Selected optimization level O0: Pure FP32 training. Defaults for this optimization level are: enabled : True opt_level : O0 cast_model_type : torch.float32 patch_torch_functions : False keep_batchnorm_fp32 : None master_weights : False loss_scale : 1.0 Processing user overrides (additional kwargs that are not None)... After processing overrides, optimization options are: enabled : True opt_level : O0 cast_model_type : torch.float32 patch_torch_functions : False keep_batchnorm_fp32 : None master_weights : False loss_scale : 128.0 Preparing dataset... loader: pytorch resize: [1024, 1280], max: 1280 device: 4 gpus batch: 4, precision: mixed Training model for 20000 iterations... [ 1/20000] focal loss: 0.95619, box loss: 0.51584, 4.042s/4-batch (fw: 0.698s, bw: 0.459s), 1.0 im/s, lr: 0.0001 [ 12/20000] focal loss: 0.76191, box loss: 0.31794, 0.187s/4-batch (fw: 0.055s, bw: 0.133s), 21.4 im/s, lr: 0.0001 [ 24/20000] focal loss: 0.65036, box loss: 0.30269, 0.173s/4-batch (fw: 0.045s, bw: 0.128s), 23.1 im/s, lr: 0.0001 [ 36/20000] focal loss: 0.46425, box loss: 0.23141, 0.178s/4-batch (fw: 0.047s, bw: 0.131s), 22.4 im/s, lr: 0.0001 [ 48/20000] focal loss: 0.45115, box loss: 0.23505, 0.180s/4-batch (fw: 0.047s, bw: 0.133s), 22.2 im/s, lr: 0.0001 [ 59/20000] focal loss: 0.38958, box loss: 0.25373, 0.184s/4-batch (fw: 0.049s, bw: 0.134s), 21.8 im/s, lr: 0.0001 [ 71/20000] focal loss: 0.37733, box loss: 0.23988, 0.174s/4-batch (fw: 0.049s, bw: 0.125s), 22.9 im/s, lr: 0.0001 [ 83/20000] focal loss: 0.39514, box loss: 0.23878, 0.181s/4-batch (fw: 0.048s, bw: 0.133s), 22.1 im/s, lr: 0.0001 [ 94/20000] focal loss: 0.39947, box loss: 0.23817, 0.185s/4-batch (fw: 0.050s, bw: 0.134s), 21.6 im/s, lr: 0.0001 [ 105/20000] focal loss: 0.37343, box loss: 0.20238, 0.182s/4-batch (fw: 0.048s, bw: 0.134s), 22.0 im/s, lr: 0.0001 [ 116/20000] focal loss: 0.19689, box loss: 0.17371, 0.183s/4-batch (fw: 0.050s, bw: 0.132s), 21.8 im/s, lr: 0.0001 [ 128/20000] focal loss: 0.20368, box loss: 0.16538, 0.178s/4-batch (fw: 0.046s, bw: 0.131s), 22.5 im/s, lr: 0.0001 [ 140/20000] focal loss: 0.22763, box loss: 0.15772, 0.176s/4-batch (fw: 0.050s, bw: 0.126s), 22.7 im/s, lr: 0.0001 [ 148/20000] focal loss: 0.21997, box loss: 0.18400, 0.585s/4-batch (fw: 0.047s, bw: 0.144s), 6.8 im/s, lr: 0.0001 Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.52674 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.91450 Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.35172 Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.61881 Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.00000 Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.00000 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.58824 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.61765 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.61765 Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.61765 Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.00000 Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.00000 Saving model: 148
要研究整个参数集,请看
retinanet/main.py
通常,它们是检测的标准,并有描述。 运行培训,然后等待结果。 可以在以下示例中找到推论的示例:
retinanet/infer_example.py
或执行命令:
/opt/conda/bin/python retinanet/main.py infer retinanet_rn34fpn.pth --images /workspace/mounted_vol/dataset/test/images --annotations /workspace/mounted_vol/dataset/val.json --output result.json --resize 256 --max-size 512 --batch 32
焦点损失和几个骨干已经内置到存储库中,并且它们
retinanet/backbones/*.py
作者在铭牌上给出了一些特征:
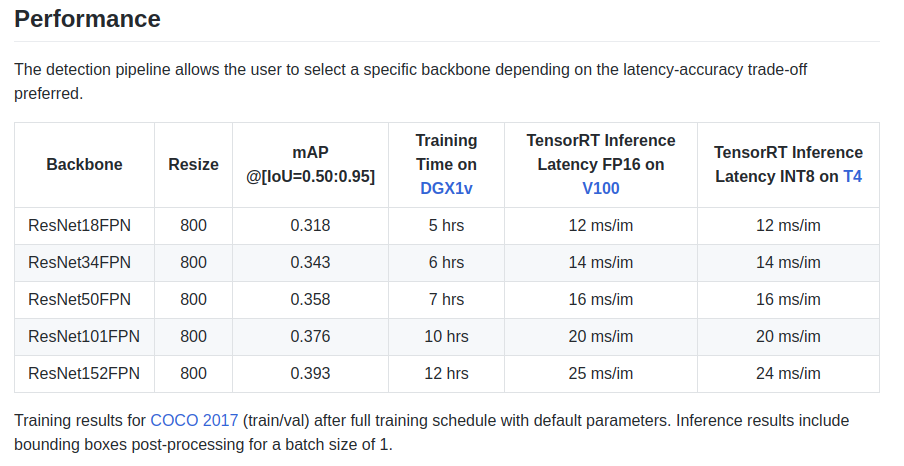
还有一个主干ResNeXt50_32x4dFPN和ResNeXt101_32x8dFPN,取自Torchvision。
希望我们对检测有所
了解 ,但是您绝对应该阅读官方文档,以
了解导出和日志记录模式 。
阶段5.使用Resnet编码器导出和推断Unet模型您可能已经注意到,用于分段的库已安装在Dockerfile中,尤其是精美的库
github.com/qubvel/segmentation_models.pytorch 。 在Yunet软件包中,您可以找到在TensorRT引擎中推断和导出pytorch检查点的示例。
从ONNX导出类似Unet的模型到TensoRT时的主要问题是需要设置固定的Upsample大小或使用ConvTranspose2D:
import torch.onnx.symbolic_opset9 as onnx_symbolic def upsample_nearest2d(g, input, output_size):
使用此转换,您可以在导出到ONNX时自动执行此操作,但是已经在TensorRT的版本7中解决了此问题,我们只需要等待很少的时间。
结论当我开始使用Docker时,我对其执行任务的性能感到怀疑。 在我的一个单元中,现在有多个摄像机创建了很多网络流量。
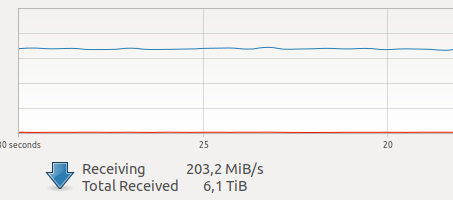
互联网上的各种测试表明,网络交互和在VOLUME上录制的开销相对较大,加上未知且可怕的GIL,并且由于拍摄帧,在网络上驱动程序并通过网络传输帧是
硬实时模式下的原子操作,因此会产生延迟在线对我来说至关重要。
但是什么都没发生=)
PS仍然需要添加您最喜欢的火车环以进行分段和制作!
谢谢啦感谢
ods.ai社区,没有它就不可能发展! 非常感谢DL,希望我能接受DL
n01z3的宝贵建议和非凡的敬业精神!
在生产中使用优化的模型!
Aurorai,llc