Clickhouse是Yandex创建的开源开源分析查询数据库管理系统(OLAP)数据库引擎。 Yandex,CloudFlare,VK.com,Badoo和世界各地的其他服务使用它来存储大量数据(每秒插入数千行或存储在磁盘中的PB级数据)。
在通常的“字符串” DBMS中,数据的存储顺序如下:MySQL,Postgres,MS SQL Server。
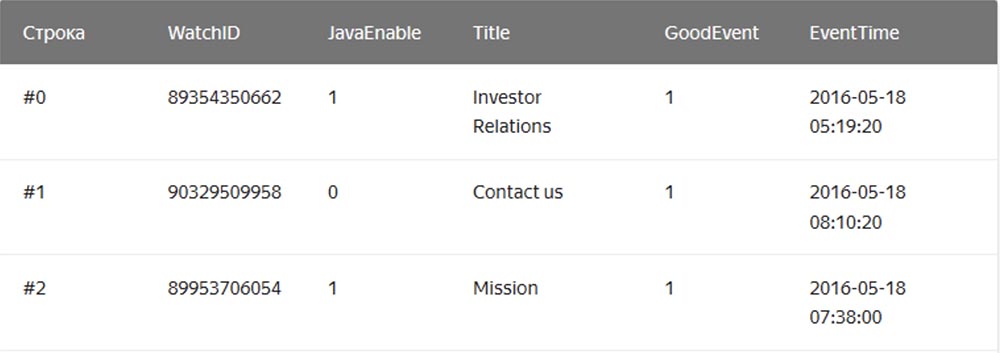
在这种情况下,与一行相关的值在物理上并排存储。 在列式DBMS中,来自不同列的值分别存储,并且一列的数据存储在一起:
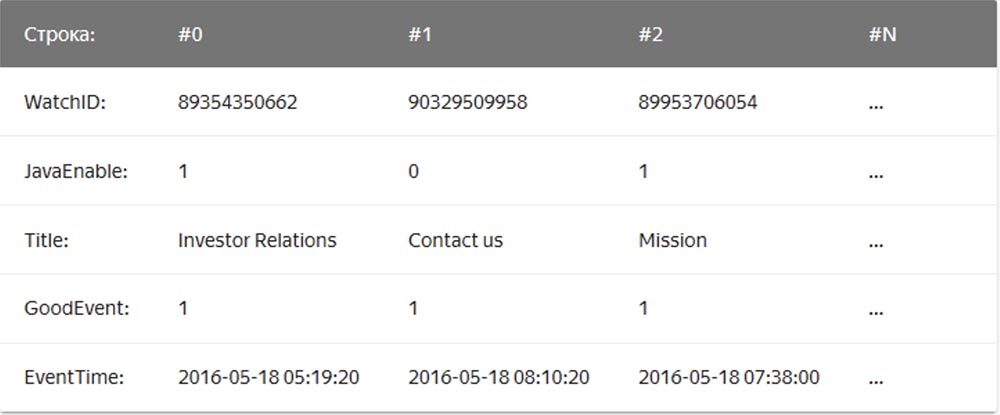
柱状DBMS的示例是Vertica,Paraccel(Acti矩阵,Amazon Redshift),Sybase IQ,Exasol,Infobright,InfiniDB,MonetDB(VectorWise,Actian Vector),LucidDB,SAP HANA,Google Dremel,Google PowerDrill,Druid,kdb +。
邮件
转发公司
Qwintry于2018年开始使用Clickhouse进行报告,其简单性,可扩展性,SQL支持和速度给人留下了深刻的印象。 这个DBMS的速度充满魔力。
简单性
Clickhouse只需一个命令即可在Ubuntu上安装。 如果您了解SQL,则可以立即开始使用Clickhouse来满足需要。 但是,这并不意味着您可以在MySQL中运行“显示创建表”并在Clickhouse中复制粘贴SQL。
与MySQL相比,在此DBMS中,表模式的定义在数据类型上有重要区别,因此,为了使工作更舒适,您仍然需要一些时间来更改表模式的定义并研究表引擎。
Clickhouse不需要任何其他软件就能很好地工作,但是如果您要使用复制,则需要安装ZooKeeper。 查询性能分析显示了出色的结果-系统表包含所有信息,并且所有数据都可以使用旧的无聊的SQL获得。
性能表现

ClickHouse数据库的设计非常简单-集群中的所有节点都具有相同的功能,并且仅使用ZooKeeper进行协调。 我们构建了一个由几个节点组成的小型集群并进行了测试,在此期间,我们发现该系统具有相当出色的性能,这与分析型DBMS基准中宣称的优势相对应。 我们决定仔细研究ClickHouse背后的概念。 研究的第一个障碍是缺少工具和ClickHouse社区的规模小,因此我们深入研究了此数据库管理系统的设计以了解其工作方式。
由于ClickHouse只是一个数据库,因此它不支持直接从Kafka接收数据(目前已经知道如何使用),因此我们在Go中编写了自己的适配器服务。 他从Kafka读取Cap'n Proto编码的消息,将其转换为TSV,然后通过HTTP接口将其批量插入ClickHouse。 后来,我们重写了此服务,以结合使用Go库和我们自己的ClickHouse接口来提高性能。 在评估接收数据包的性能时,我们发现了一件重要的事情-事实证明,在ClickHouse,此性能在很大程度上取决于数据包的大小,即同时插入的行数。 为了了解为什么会发生这种情况,我们检查了ClickHouse如何存储数据。
ClickHouse用于存储数据的主引擎(或更确切地说,表引擎家族)是MergeTree。 从概念上讲,此引擎类似于Google BigTable或Apache Cassandra使用的LSM算法,但是它避免了建立中间内存表并将数据直接写入磁盘。 由于每个插入的数据包仅按“主键”主键排序,然后压缩并写入磁盘以形成一个段,因此,它具有出色的写入吞吐量。
没有内存表或任何数据“新鲜度”的概念也意味着只能添加它们;系统不支持更改或删除它们。 如今,删除数据的唯一方法是按日历月份删除数据,因为段永远不会越过月份边界。 ClickHouse团队正在积极致力于使此功能可自定义。 另一方面,这使记录和合并段无缝连接,因此接收带宽与并行插入的数量成线性比例,直到I / O或内核饱和为止。
但是,这个事实也意味着该系统不适合小包装,因此Kafka服务和插入用于缓冲。 此外,后台的ClickHouse继续不断执行段的合并,因此许多小信息将被合并并记录更多次,从而增加了记录强度。 在这种情况下,只要合并继续进行,太多无关的零件将导致刀片的节流。 我们发现,实时数据接收和接收性能之间的最佳折衷是每秒接收有限数量的插入表。
表读取性能的关键是在磁盘上索引和定位数据。 无论处理速度有多快,当引擎需要从磁盘扫描数TB的数据并仅使用其中的一部分时,这都需要时间。 ClickHouse是一个列存储,因此每个段都包含每个列(列)的文件以及每个行的排序值。 因此,可以首先跳过不在查询中的整个列,然后可以与矢量化执行并行处理几个单元格。 为了避免全面扫描,每个段都有一个较小的索引文件。
假定所有列均按“主键”排序,则索引文件仅包含第N行的标签(捕获的行),以便即使对于非常大的表也可以将其存储在内存中。 例如,可以将默认设置设置为“每第8192行标记一次”,然后将表的“微薄”索引设置为1万亿。 容易容纳到内存中的行仅占用122,070个字符。
系统开发
Clickhouse的开发和改进可以追溯到
Github仓库,并确保“成长”的过程正在以惊人的速度进行。
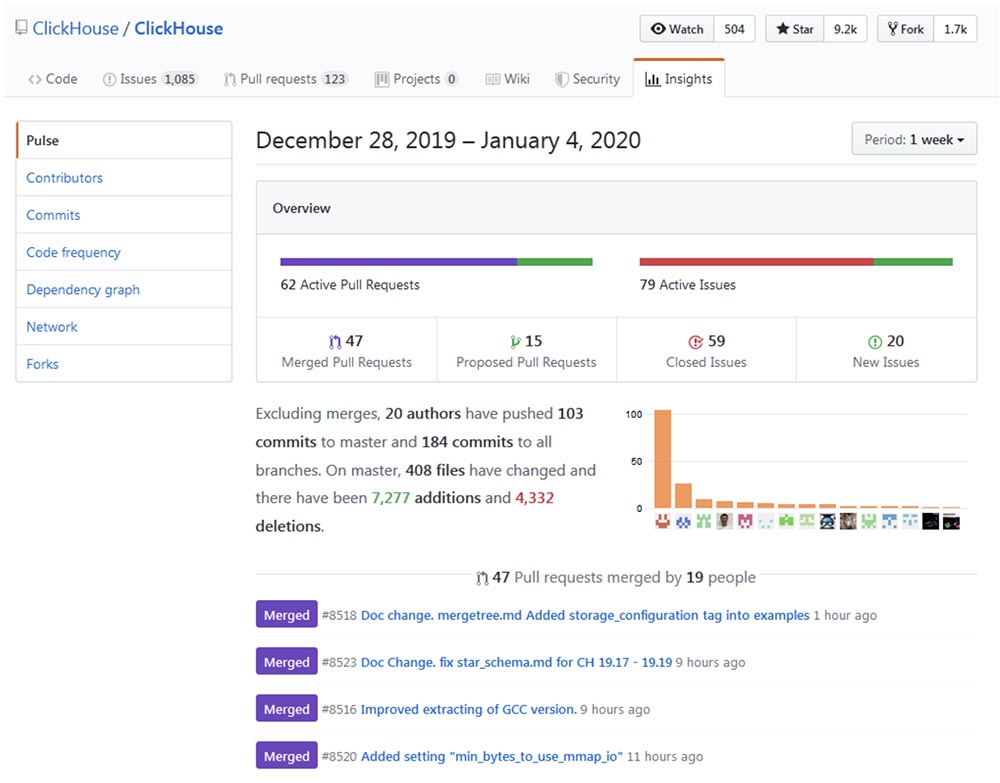
人气度
Clickhouse似乎呈指数级增长,尤其是在俄语社区中。 去年的高负载会议2018(莫斯科,2018年11月8日至9日)显示,诸如vk.com和Badoo之类的怪兽都使用Clickhouse,它们可以同时粘贴来自成千上万台服务器的数据(例如日志)。 在40分钟的视频中,
VKontakte团队的Yuri Nasretdinov讨论了如何完成此操作 。 不久,我们将在Habr上发布成绩单,以方便使用该材料。
应用领域
经过一段时间的研究,我认为ClickHouse可以在某些领域发挥作用或完全取代其他更传统和流行的解决方案,例如MySQL,PostgreSQL,ELK,Google Big Query,Amazon RedShift, TimescaleDB,Hadoop,MapReduce,Pinot和Druid。 以下是使用ClickHouse升级或完全替换上述DBMS的详细信息。
扩展MySQL和PostgreSQL
最近,我们将
Mautic新闻通讯平台的
ClickHouse部分替换为MySQL。 问题在于,由于设计不当,MySQL使用base64哈希表注册了每个发送的字母和字母中的每个链接,从而创建了一个巨大的MySQL表(email_stats)。 在仅向服务订阅者发送了1000万封信后,该表占用了150 GB的文件空间,MySQL开始对简单查询进行“钝化”。 为了解决文件空间问题,我们成功使用了InnoDB表压缩,将其压缩了4倍。 但是,仅仅为了阅读故事,在MySQL中存储超过20-30百万封电子邮件仍然没有任何意义,因为出于某种原因需要执行完整扫描的任何简单请求都将导致交换和I / O的大量负载,对于关于此,我们经常收到Zabbix警告。

Clickhouse使用两种压缩算法,可将数据量减少约
3-4倍 ,但在这种情况下,数据特别“可压缩”。

ELK更换
根据我们自己的经验,ELK堆栈(ElasticSearch,Logstash和Kibana,在这种情况下为ElasticSearch)需要的运行资源要比存储日志所需的资源多得多。 如果您需要良好的全文日志搜索(我不认为确实需要它),ElasticSearch是一个很棒的引擎,但是我想知道为什么事实上它已经成为标准的日志记录引擎。 它的接收性能与Logstash相结合,即使负载很小,也给我们带来了问题,并且需要增加RAM和磁盘空间。 作为数据库,由于以下原因,Clickhouse比ElasticSearch更好:
- SQL方言支持;
- 存储数据的最佳压缩率;
- 支持正则表达式正则表达式搜索,而不是全文搜索;
- 改进的查询计划和更高的整体性能。
当前,将ClickHouse与ELK进行比较时出现的最大问题是缺少运输日志的解决方案,以及缺少有关此主题的文档和培训工具。 同时,每个用户都可以使用《数字海洋指南》来配置ELK,这对于快速实施此类技术非常重要。 这里有一个数据库引擎,但是ClickHouse还没有Filebeat。 是的,这里有
流利的系统和用于处理日志日志的系统,还有一个
clicktail工具,用于将日志文件中的数据输入ClickHouse,但这需要更多时间。 但是,由于ClickHouse的简单性,它仍然处于领先地位,因此,即使是初学者,也可以基本安装它并在10分钟内开始完全使用它。
我偏爱极简主义的解决方案,并尝试使用FluentBit和ClickHouse一起使用该工具,该工具用于运送内存量很小的日志,同时避免使用Kafka。 但是,在没有代理层将数据从FluentBit转换为ClickHouse的情况下,必须先解决一些不兼容问题,例如
日期格式问题 。
作为Kibana的替代方案,您可以将
Grafana用作ClickHouse
后端 。 据我了解,这在渲染大量数据点时可能会导致性能问题,尤其是对于较旧版本的Grafana。 在Qwintry,我们还没有尝试过,但是不时有关于此的投诉出现在Telegram的ClickHouse支持频道上。
取代Google Big Query和Amazon RedShift(适用于大型公司的解决方案)
BigQuery的理想用例是下载1 TB的JSON数据并对它们执行分析查询。 Big Query是一款出色的产品,其可伸缩性很难高估。 它比在内部群集上运行的ClickHouse复杂得多,但是从客户端的角度来看,它与ClickHouse有很多共同点。 只要您为每个SELECT付费,BigQuery便可以迅速提高价格,因此这是一个真正的SaaS解决方案,它有其利弊。
当您执行大量计算量大的查询时,ClickHouse是最佳选择。 每天执行的SELECT查询越多,用ClickHouse替换Big Query的意义就越大,因为当处理许多TB的数据时,这种替换将为您节省数千美元。 这不适用于存储的数据,在Big Query中处理该数据非常便宜。
Altinity联合创始人Alexander Zaitsev的文章
“切换到ClickHouse”讨论了这种DBMS迁移的好处。
替换TimescaleDB
TimescaleDB是PostgreSQL的一个扩展,可以优化常规数据库中时间序列时间序列的工作(
https://docs.timescale.com/v1.0/introduction,https://habr.com/en/company/zabbix/blog/458530 / )。
尽管ClickHouse在时间序列利基市场中并不是严重的竞争对手,但是在查询分析的列结构和向量执行方面,在大多数情况下,处理分析查询要比TimescaleDB快得多。 同时,接收ClickHouse数据包数据的性能要高出大约3倍,此外,它使用的磁盘空间也要少20倍,这对于处理大量历史数据确实很重要:
https :
//www.altinity.com/blog/ClickHouse-for时间序列 。
与ClickHouse不同,在TimescaleDB中节省磁盘空间的唯一方法是使用ZFS或类似的文件系统。
即将发布的ClickHouse更新可能会引入增量压缩,这将使其更适合于处理和存储时间序列数据。 在以下情况下,TimescaleDB比裸身的ClickHouse可能是更好的选择:
- 带有少量RAM(<3 GB)的小型安装;
- 大量不想插入大片段的小INSERT;
- 更好的一致性,均匀性和ACID要求;
- PostGIS支持;
- 由于Timescale DB本质上是PostgreSQL,因此可以与现有PostgreSQL表合并。
与Hadoop和MapReduce系统竞争
Hadoop和其他MapReduce产品可以执行许多复杂的计算,但是它们通常会产生巨大的延迟,ClickHouse通过处理TB级的数据并几乎立即提供结果来解决此问题。 因此,ClickHouse在执行快速的交互式分析研究方面效率更高,这对于数据处理专家来说应该是很有趣的。
与黑皮诺和德鲁伊的竞争
ClickHouse最接近的竞争对手是Pinot和Druid,这是一种可线性扩展的圆柱状开源产品。
Roman Leventov在2018年2月1日发表的一篇文章中发表了比较这些系统的出色工作。
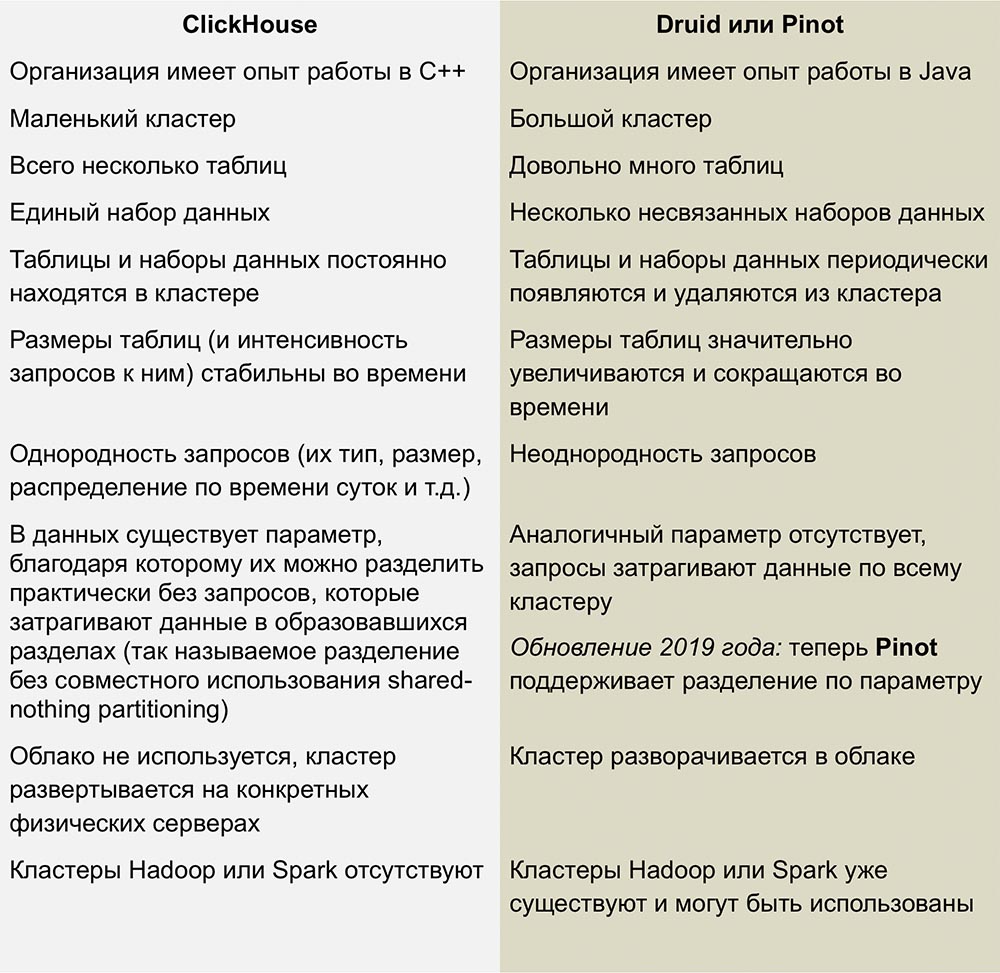
本文需要更新-它指出ClickHouse不支持UPDATE和DELETE操作,这对于最新版本并不完全正确。
我们对这些DBMS没有足够的经验,但是我不喜欢用于运行Druid和Pinot的基础架构的复杂性-这是一堆由Java围绕的“活动部件”。
Druid和Pinot是Apache孵化器项目,Apache的GitHub项目页面上详细介绍了其开发进度。 黑皮诺于2018年10月出现在孵化器中,德鲁伊出生于8个月前-2月。
缺乏有关AFS工作原理的信息给了我一些甚至是愚蠢的问题。 我想知道黑皮诺(Pinot)的作者是否注意到阿帕奇基金会(Apache Foundation)更倾向于德鲁伊(Druid),对竞争对手的这种态度是否引起嫉妒? 如果支持前者的赞助商突然对后者感兴趣,那么德鲁伊的发展会放缓,黑比诺会加速吗?
ClickHouse的缺点
不成熟:显然,这仍然不是一项无聊的技术,但是在任何情况下,在其他柱状DBMS中都找不到类似的东西。
小插入不能很好地高速运行:必须将插入分成大块,因为小插入的性能会与每行中的列数成比例地降低。 这就是ClickHouse在磁盘上存储数据的方式-每列意味着1个或更多文件,因此要插入1行包含100列,必须打开并写入至少100个文件。 这就是为什么需要中介来缓冲插入内容(除非客户端本身提供缓冲)的原因-通常这是Kafka或某种队列管理系统。 您还可以使用缓冲区表引擎稍后将大数据块复制到MergeTree表中。
表联接受服务器RAM的限制,但至少它们在那里! 例如,Druid和Pinot根本没有这样的连接,因为它们很难直接在不支持在节点之间移动大量数据的分布式系统中实现。
结论
在未来的几年中,我们计划在Qwintry中广泛使用ClickHouse,因为此DBMS可在性能,低开销,可伸缩性和简单性之间实现出色的平衡。 我非常确定,一旦ClickHouse社区提出了更多在中小型安装环境中使用它的方法,它将很快开始迅速传播。
一点广告:)
感谢您与我们在一起。 你喜欢我们的文章吗? 想看更多有趣的资料吗? 通过下订单或向您的朋友推荐,
为开发人员提供基于云的VPS, 最低 价格为4.99美元 ,
这是我们为您发明的入门级服务器的
独特类似物: 关于VPS(KVM)E5-2697 v3(6核)的全部真相10GB DDR4 480GB SSD 1Gbps从$ 19还是如何划分服务器? (RAID1和RAID10提供选件,最多24个内核和最大40GB DDR4)。
阿姆斯特丹的Equinix Tier IV数据中心的戴尔R730xd便宜2倍吗? 仅
在荷兰,我们有
2台Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100电视 ! 戴尔R420-2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB-$ 99起! 阅读有关
如何构建基础架构大厦的信息。 使用价格为9000欧元的Dell R730xd E5-2650 v4服务器的上等课程?