
引言
我真的很喜欢编程,我是一个业余爱好者,1996年我第一次也是最后一次在编程上赚钱。 但是有时候我写一些东西来自动化日常任务。 大约一年前,发现了golang。 作为创建实用程序的工具,golang非常方便。 这样啊
需要处理大量(包含上千个,我看到专业人士的微笑)具有特殊地球物理信息的存档文件。 文件格式是文本,简单。 如果您突然对此感兴趣,那么这是LAS格式 。
LAS文件包含标头和数据。
数据实际上是CSV,只有制表符分隔符或空格。
标题包含对数据的描述,此处通常包含俄语文本。 这可能是字段的名称,文件中记录的检查的名称,等等。
这些文件是在不同的时间和不同的程序中创建的,事实是,在一个文件中,一部分用CP1251编码,一部分用CP866编码。 我需要处理这些文件,这意味着要理解。 因此,需要自动确定文件编码。
结果,他发明了一种在golang上的自行车,因此,诞生了一个小型库,能够检测代码页。
关于编码。 不久前在habr上有一篇关于编码的好文章, 文本编码是如何工作的。 “鳄鱼”从何而来。 编码原理。 概括和详细的分析 如果您想了解什么是“骨骼”,那么值得一读。
一开始我就做出了决定。 然后,我试图在golang上找到现成的可行解决方案,但失败了。 有两种解决方案,但两者都不起作用。
- 第一个“开箱即用”-golang.org/x/net/html/charset函数defineEncoding()
- 第二个库-github上的saintfish / chardet
两者肯定在某些编码上是错误的。 标准的代码通常无法确定文本文件中的几乎所有内容,这是可以理解的,这是针对html页面完成的。
搜索时,我经常遇到linux world- enca中现成的实用程序。 找到了针对WIN32 1.12版进行编译的版本。 我也会考虑的,那里有有趣的东西。 我为自己对Linux的完全不了解而立即道歉,这意味着可能还有更多解决方案,您也可以尝试使用这些代码来编写golang代码,但我现在再也没有看到。
编码自动检测解决方案的比较
准备了带有不同编码文件的目录softlandia \ cpd测试数据 。 文件的内容非常简短。 一行“编码CodePageName中的俄语”。 我添加了混合了编码和一些复杂案例的文件,并试图确定。
我认为结果很有趣。
观察1
enca在没有BOM的情况下无法确定UTF-16LE文件的编码-这很奇怪,好吧。 我尝试添加更多文本,但没有得到结果。
观察2. CP1251和KOI8-R的编码问题
第15和16行。enca命令有问题。
在这里,我将作一个解释,事实是,如果仅考虑字母字符,则CP1251(又名Windows 1251)和KOI8-R的编码非常接近。
表CP 1251
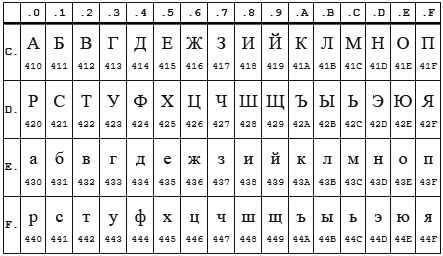
KOI8-R桌子

在这两种编码中,字母的位置都在0xC0到0xFF之间 ,但是其中一种编码为大写字母,另一种编码为小写字母。 显然enca使用小写字母。 事实证明,如果将以CP1251编码的字符串“ STP”发送到 enca程序,那么它将确定它是以KOI8-r编码的“强烈”字符串,将进行报告。 反向也可以。
观察3
只能使用UTF-8定义来信任html / charset标准库,但是要小心! 应该完全使用charset.DetermineEncoding() ,因为utf-16be编码文件上的utf8.Valid(b []字节)方法返回true 。
自己的自行车

编码的自动检测只能通过不精确的启发式方法进行。 如果我们不知道该文本文件是用哪种语言编写的以及以哪种编码编写的,则可以高精度地确定编码方式,但这将很困难……而且您将需要大量文本。
对我来说,这个目标没有设定。 在假设有俄语的情况下确定编码就足够了。 其次,您需要确定少量字符-10个字符应具有相当确定的定义,通常最好是5-6个字符。
演算法
当我通过字母的位置发现编码KOI8-r和CP1251的重合时,我感到难过了几天……很明显,我不得不考虑一下。 原来是这样的。
关键决策:
- 我们将使用一个字节片,以与charset.DetermineEncoding()兼容
- UTF-8编码和BOM大小写分别检查
- 输入数据依次传递给每种编码。 各自计算两个整数标准。 他的两个标准之和更大,他赢了。
合规标准
第一准则
第一个条件是俄语字母中最受欢迎的字母数。
最常见的字母是: o,e,a和n,t,s,p,b,l,k,m,d,p,y 。 这些字母覆盖率达82%。 对于除KOI8-r和CP1251以外的所有编码,我仅使用前9个字母:o,e,a和n,t,s,p,c。 这足以进行可靠的确定。
但是对于KOI8-r和CP1251,我不得不修改该文件。 其中一些字母的代码重合,例如,字母o在CP1251中的代码为0xEE,而在KOI8-r中,此代码的字母为n 。 这些编码采用以下常用字母。 对于CP1251,我使用了a和n,c,p,b,l,k,i。 对于KOI8-r-o,a,u,t,s,b,l,k,m。
第二条准则
不幸的是,对于非常短的情况(俄语文本的总长度为5-6个字符),流行字母的出现级别为1-3个,并且KOI8-r和CP1251编码存在重叠。 我不得不介绍第二个标准。 辅音+元音计数 。
预期这种组合最常以俄语出现,因此,在这种编码对的数目较大的编码中,编码具有较大的标准。
这两个标准都经过计算,加总,收到的金额才是最终标准。
结果显示在上表中。
我遇到的功能
稍微了解一下与golang相关的魅力和问题。 本节可能仅对初学者来说很有趣,可以用golang编写。
问题所在
亲自绕过Go的50种阴影的一些水下卵石:陷阱,陷阱和常见的初学者错误 。
检查io.Reader类型的输入参数,过分担心并试图将水吹入水中,从其他人那里听到牛奶可怕的灼伤,这太过分了。 我用反射检查了像io.Reader这样的变量。
但事实证明,检查nil就足够了。 现在一切都变得简单
func CodePageDetect(r io.Reader, stopStr ...string) (IDCodePage, error) {
调用bufio.NewReader(r).Peek(ReadBufSize)悄悄地通过了以下测试:
var data *os.File res, err := CodePageDetect(data)
在这种情况下,Peek()返回错误。
一旦踩到按值传递数组的耙。 尝试更改存储在地图中的元素,在范围内遍历它们时有点愚蠢……
欢欣鼓舞
很难确切地说出是从lint和编译器中不断握手还是主动使用range,还是全部一起使用,但是实际上没有任何入侵可以使索引越界。
当然,与垃圾收集器一起生活非常好。 我想我仍然必须掌握自动分配/释放内存的技巧,但是到目前为止,白痴的笑容还没有离开我的脸。
强大的打字能力也是一种幸福。
因此,具有功能类型的变量可以轻松实现同一类型对象的各种行为。
奇怪的是,他不得不坐在调试器中,重新读取代码通常会得到结果。
小狗从开箱即用的许多工具中获得乐趣,当编译器,语言,库和IDE Visual Studio Code和谐地为您工作时,这是一种美妙的感觉。
感谢falconandy提供的建设性和有用的提示。
多亏他
- 翻译了关于testify的测试,它们确实变得更具可读性
- 固定测试数据文件路径以与Linux兼容
- 走过一头棉inter-但他发现了一个真正的错误(该死的副本/过去)
我继续添加测试,发现了未定义UTF16的情况。 已更新。 现在即使没有俄语字母也能检测到UTF16以及LE和BE