多维数据集,元集群,单元,资源分配
图 1.阿里云中的Kubernetes生态系统自2015年以来,用于Kubernetes的阿里云容器服务(ACK)一直是阿里云中增长最快的云服务之一。 它为众多客户提供服务,还支持阿里巴巴的内部基础架构以及公司的其他云服务。
与来自世界一流的云提供商的类似容器服务一样,我们的首要任务是可靠性和可用性。 因此,已经为成千上万的Kubernetes集群创建了一个可扩展且可全球访问的平台。
在本文中,我们将分享在云基础架构上管理大量Kubernetes集群以及基础平台架构的经验。
参赛作品
Kubernetes已成为各种云工作负载的事实上的标准。 如图所示。 从顶部1开始,现在越来越多的Alibaba Cloud应用程序可在Kubernetes集群中运行:它们是有状态/无状态应用程序以及应用程序管理器。 对于参与构建和维护基础架构的工程师来说,管理Kubernetes一直是一个有趣且严肃的讨论主题。 当涉及到阿里云等云提供商时,可扩展性就显得尤为重要。 如何以这种规模管理Kubernetes集群? 我们已经讨论了管理大型10,000节点Kubernetes集群的最佳实践。 当然,这是一个有趣的缩放问题。 但是还有另一个规模尺度:
集群本身的数量。
我们与许多ACK用户讨论了该主题。 他们中的大多数人喜欢运行数十个(如果不是数百个)中小型Kubernetes集群。 这样做的合理原因是:限制潜在的损害,为不同的团队划分集群,创建用于测试的虚拟集群。 如果ACK希望使用此使用模型为全球用户提供服务,则它必须可靠,有效地管理20多个区域中的大量集群。
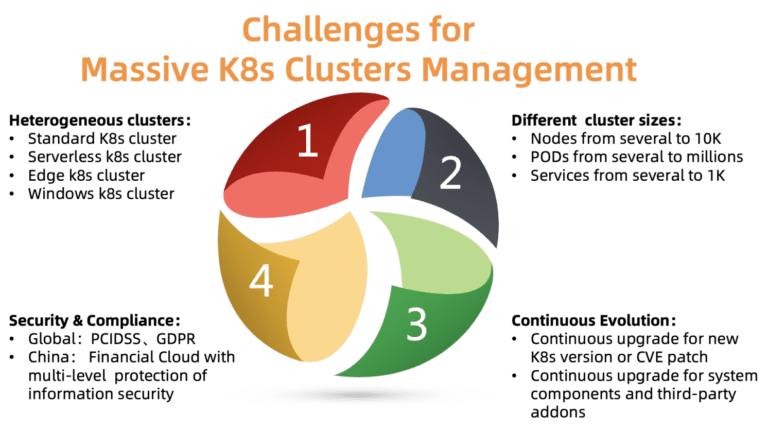 图 2.管理大量Kubernetes集群的挑战
图 2.管理大量Kubernetes集群的挑战如此规模的集群管理主要存在哪些问题? 如图所示,有四个问题要处理:
ACK必须支持各种类型的群集,包括标准群集,无服务器群集,Edge,Windows和其他一些群集。 不同的集群需要不同的参数,组件和托管模型。 一些客户需要针对其特定情况进行定制的帮助。
集群的大小各不相同:从一对具有几个吊舱的节点到成千上万个具有数千个吊舱的节点。 资源需求也有很大不同。 资源分配不当会影响性能,甚至导致故障。
Kubernetes正在迅速发展。 新版本每隔几个月发布一次。 客户始终准备尝试新功能。 因此,他们希望将测试负载放在新版本的Kubernetes上,而将工作负载放在稳定的版本上。 为了满足此要求,ACK必须在保持稳定版本的同时,不断向其客户提供Kubernetes的新版本。
群集分布在不同的区域。 因此,它们必须遵守各种安全要求和官方法规。 例如,欧洲的集群必须符合GDPR,中国的金融云必须具有更高的保护级别。 这些要求是强制性的,不能忽略这些要求,因为这给云平台客户带来了巨大的风险。
ACK平台旨在解决上述大多数问题。 当前,它可靠,稳定地管理着全球超过1万个Kubernetes集群。 让我们看看我们如何实现这一目标,包括由于设计/架构的几个关键原则。
设计方案
多维数据集和蜂窝
与集中式层次结构不同,基于单元的体系结构通常用于将平台扩展到单个数据中心之外或扩展灾难恢复的范围。
阿里云中的每个区域都包含多个区域(AZ),通常对应于一个特定的数据中心。 在广大地区(例如黄州),经常发现数千个运行ACK的Kubernetes客户端集群。
ACK使用Kubernetes本身来管理这些Kubernetes集群,也就是说,我们具有用于管理Kubernetes客户端集群的Kubernetes元集群。 这种架构也称为“多维数据集”(koK-on-kube,KoK)。 随着群集的部署变得简单和确定性,KoK体系结构简化了客户端群集的管理。 更重要的是,我们可以重用原生Kubernetes的功能。 例如,通过部署管理API服务器,使用etcd运算符管理多个etcd。 这样的递归总是带来特别的乐趣。
在同一区域内,根据客户端数量部署了多个Kubernetes元集群。 这些元簇称为细胞。 为了防止整个区域发生故障,ACK支持在一个区域中进行多活动部署:元集群将Kubernetes客户端集群向导的组件分布到多个区域中并同时启动它们,即以多活动模式启动它们。 为了确保向导的可靠性和有效性,ACK优化了组件放置,并确保API服务器和etcd彼此靠近。
该模型使您可以有效,灵活和可靠地管理Kubernetes。
元集群资源计划
正如我们已经提到的,每个区域中的元集群数量取决于客户数量。 但是,什么时候添加新的元集群? 这是一个典型的资源计划问题。 通常,在现有的子集群耗尽所有资源后,通常会创建一个新的集群。
以网络资源为例。 在KoK架构中,来自客户端集群的Kubernetes组件被部署为元集群中的Pod。 我们使用
Terway (图3),这是由阿里云开发的用于容器网络管理的高性能插件。 它提供了丰富的安全策略集,并允许您通过阿里云弹性网络接口(ENI)连接到虚拟私有云(VPC)客户端。 为了在元集群中的节点,pod和服务之间高效地分配网络资源,我们必须仔细监控虚拟私有云在元集群中对它们的使用。 网络资源耗尽时,将创建一个新的单元。
为了确定每个元集群中客户端集群的最佳数量,我们还考虑了成本,密度要求,资源配额,可靠性要求和统计信息。 基于所有这些信息,决定创建新的元集群。 请注意,小型集群将来会大大扩展,因此即使集群数量相同,资源消耗也会增加。 通常,我们为每个群集的增长留出足够的可用空间。
 图 3.网络架构Terway
图 3.网络架构Terway客户端集群中的扩展向导组件
向导组件具有不同的资源要求。 它们取决于群集中节点和Pod的数量,与APIServer交互的非标准控制器/运算符的数量。
在ACK中,每个Kubernetes客户端集群在大小和运行时要求上都不同。 没有用于托管向导组件的通用配置。 如果我们错误地为大型客户端设置了较低的资源限制,则其群集将无法应对负载。 如果保守地为所有群集设置上限,则会浪费资源。
为了找到可靠性和成本之间的微妙折衷,ACK使用了类型系统。 即,我们定义了三种类型的集群:小型,中型和大型。 每种类型都有一个单独的资源分配配置文件。 类型是根据向导组件的加载,节点数和其他因素确定的。 群集的类型可能会随时间变化。 ACK持续监视这些因素,并可以相应地增加/减少类型。 更改群集类型后,资源分配将自动更新,而无需用户干预。
我们正在努力从更细粒度的缩放和更准确的类型更新方面改进此系统,以使这些更改更顺畅地进行并具有更大的经济意义。
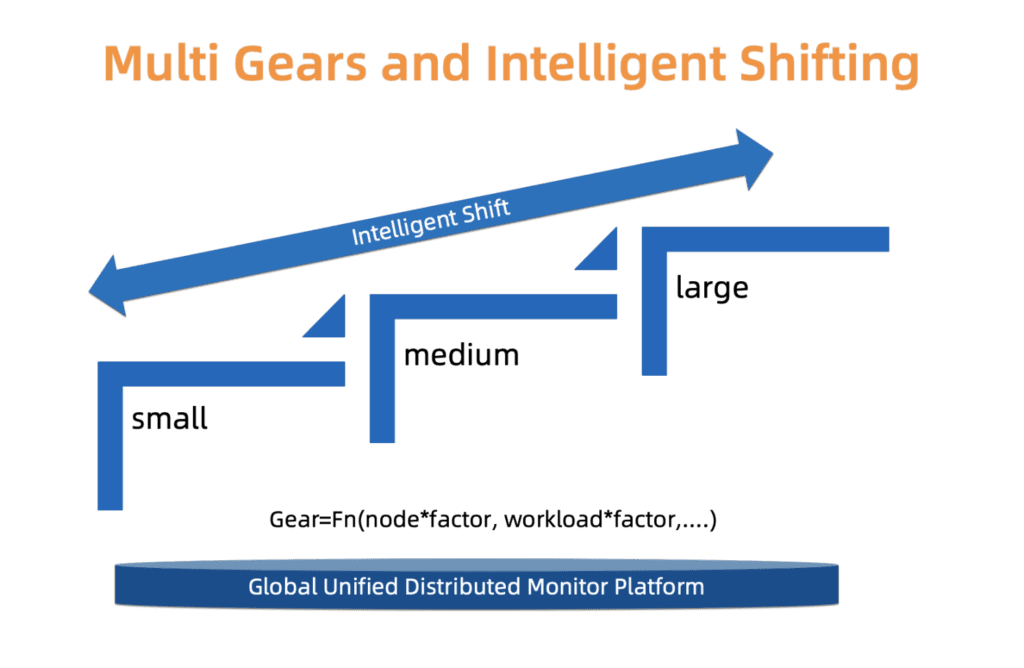 图 4.智能多级式切换
图 4.智能多级式切换客户集群的大规模发展
前面的部分描述了管理大量Kubernetes集群的某些方面。 但是,还有另一个问题需要解决:集群演化。
Kubernetes是云世界中的Linux。 它会不断更新,并变得更加模块化。 我们必须不断向客户提供新版本,修复漏洞和更新现有集群,以及管理大量相关组件(CSI,CNI,设备插件,调度程序插件和许多其他组件)。
以Kubernetes组件管理为例。 首先,我们为所有这些插件组件开发了一个集中式注册和管理系统。
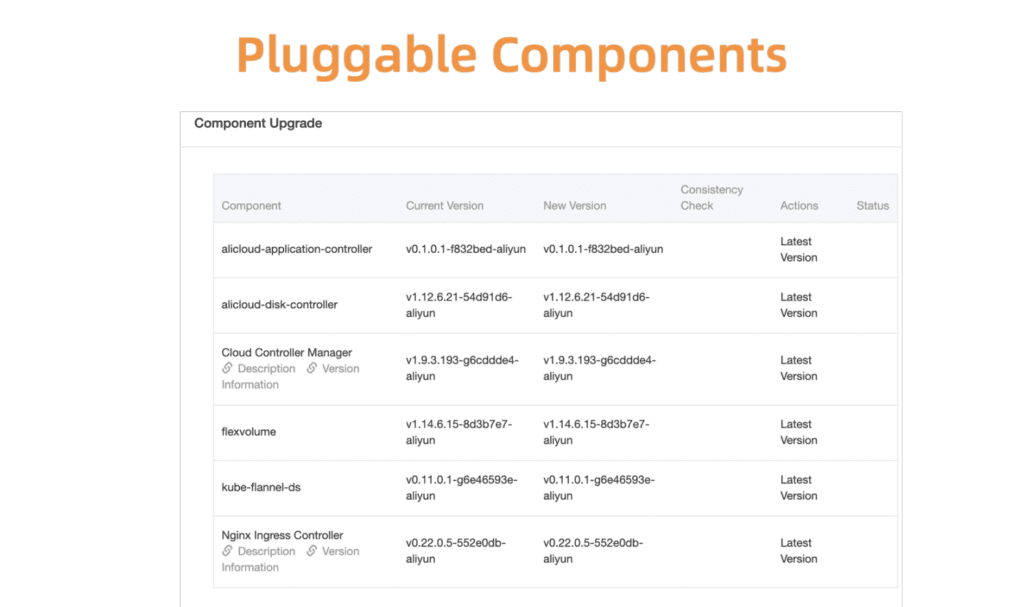 图 5.灵活的插件组件
图 5.灵活的插件组件在继续之前,您需要确保更新成功。 为此,我们开发了组件运行状况检查系统。 验证在升级之前和之后进行。
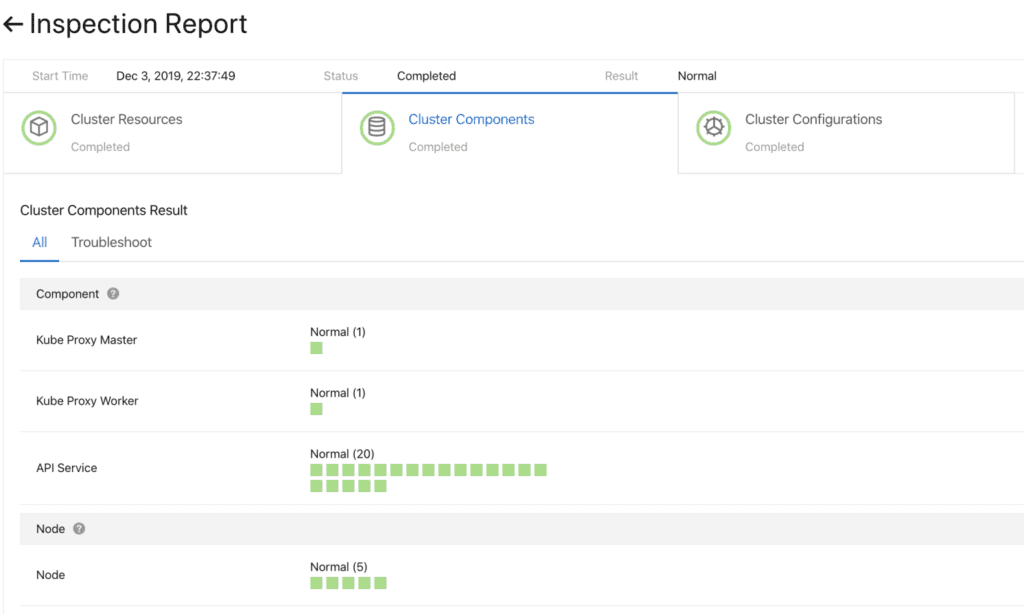 图 6.群集组件的初步检查
图 6.群集组件的初步检查为了快速可靠地更新这些组件,一个连续部署系统需要支持部分升级(灰度),暂停和其他功能。 标准Kubernetes控制器不太适合此用途。 因此,为了管理集群组件,我们开发了一套专用控制器,包括一个插件和一个辅助控制模块(sidecar管理)。
例如,BroadcastJob控制器旨在更新每台工作计算机上的组件或检查每台计算机上的节点。 广播作业在群集中的每个节点上运行一个Pod,例如DaemonSet。 但是,DaemonSet始终支持pod的连续操作,而BroadcastJob则将其最小化。 广播控制器还会在新连接的节点上启动Pod,并使用必要的组件初始化节点。 在2019年6月,我们打开了OpenKruise自动化引擎的源代码,我们自己在公司内部使用了它。
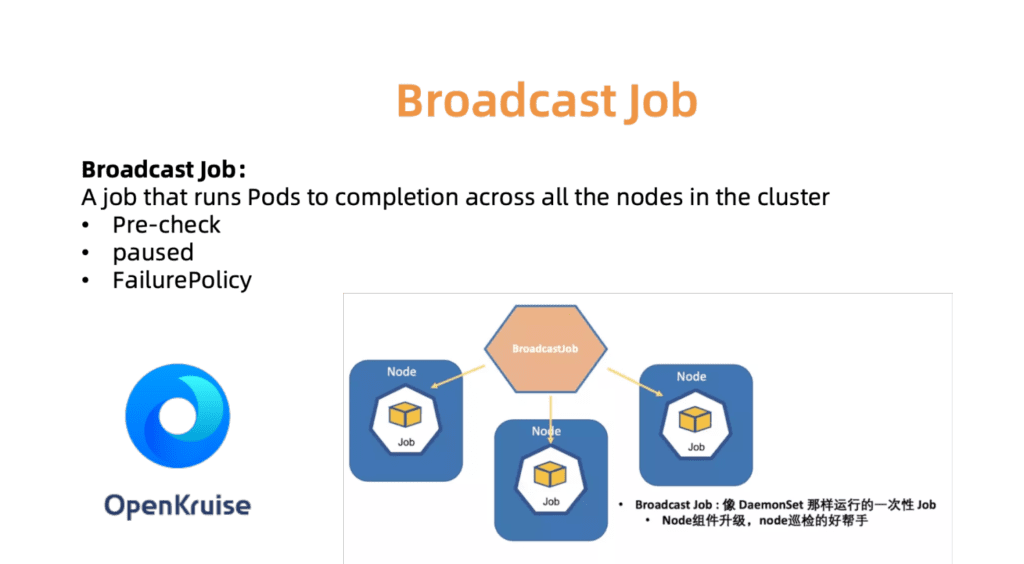 图 7. OpenKurise在所有站点组织广播分配。
图 7. OpenKurise在所有站点组织广播分配。为了帮助客户选择正确的群集配置,我们还提供了一组预定义的配置文件,包括无服务器,Edge,Windows和Bare Metal配置文件。 随着业务范围的扩大和客户需求的增长,我们将添加更多配置文件以简化繁琐的设置过程。
 图 8.适用于不同场景的高级和灵活的群集配置文件
图 8.适用于不同场景的高级和灵活的群集配置文件全球数据中心可观察性
如下图所示。 9日,阿里云容器在全球20个地区部署。 在这种规模的情况下,ACK的关键任务之一就是轻松监视正在运行的集群的状态:如果客户端集群遇到问题,我们可以快速响应情况。 换句话说,您需要提出一个解决方案,该解决方案将使您能够高效,安全地从所有区域的客户端群集中收集实时统计信息,并以可视方式呈现结果。
 图 9.阿里云容器服务在全球二十个地区的全球部署
图 9.阿里云容器服务在全球二十个地区的全球部署与许多Kubernetes监视系统一样,我们将Prometheus作为主要工具。 对于每个元集群,Prometheus代理收集以下指标:
- 操作系统指标,例如主机资源(处理器,内存,磁盘等)和网络带宽。
- 元集群和客户端集群管理系统的指标,例如kube-apiserver,kube-controller-manager和kube-scheduler。
- 来自kubernetes-state-metrics和cadvisor的度量标准。
- Etcd指标,例如磁盘写入时间,数据库大小,节点之间的吞吐量等。
使用典型的多层聚合模型收集全局统计信息。 来自每个元集群的监视数据首先在每个区域中聚合,然后发送到中央服务器,该服务器显示了全局情况。 一切都通过联合机制起作用。 每个数据中心中的Prometheus服务器都收集该数据中心的指标,并且中央Prometheus服务器负责汇总监视数据。 AlertManager连接到中央Prometheus,并在必要时通过DingTalk,电子邮件,SMS等发送警报。可视化-使用Grafana。
在图10中,监视系统可以分为三个级别:
离中心最远的图层。 Prometheus Edge Server在每个元集群上运行,从同一网络域内的元集群和客户端集群收集指标。
Prometheus级联层功能是从多个区域收集监视数据。 这些服务器在较大的地理区域(例如中国,亚洲,欧洲和美洲)运行。 随着群集在某个区域中的增长,可以对其进行划分,然后在每个新的大型区域中都将出现级联级别的Prometheus服务器。 使用此策略,您可以根据需要无缝扩展。
中央Prometheus服务器连接到所有级联服务器并执行最终数据聚合。 为了提高可靠性,在不同区域中提出了两个连接到同一级联服务器的中央Prometheus实例。
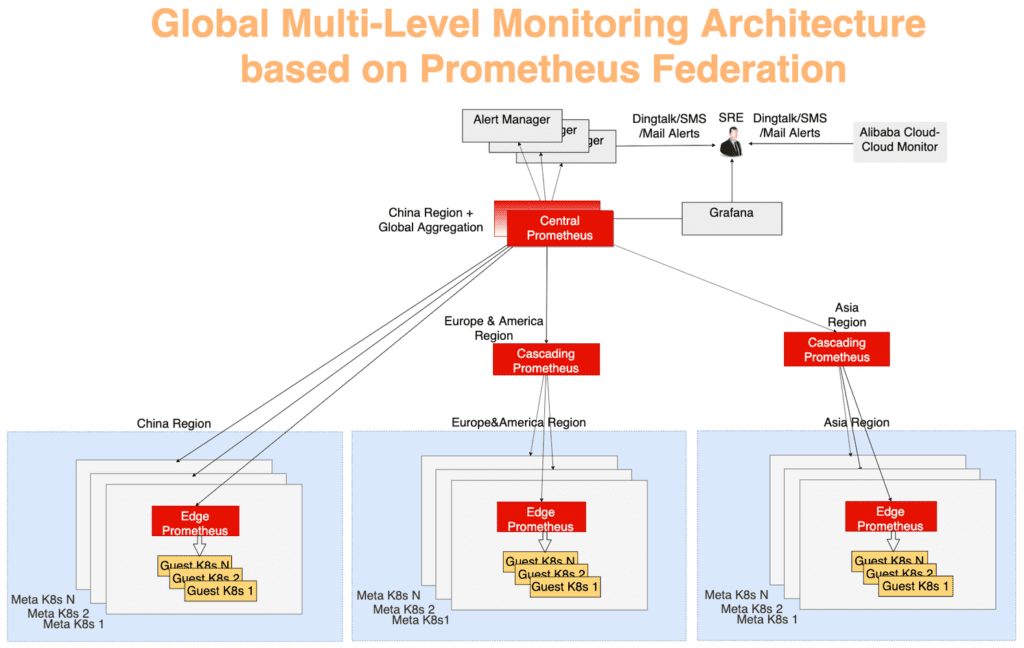 图 10.基于Prometheus联合机制的全球多层监视体系结构
图 10.基于Prometheus联合机制的全球多层监视体系结构总结
基于Kubernetes的云解决方案将继续改变我们的行业。 阿里云容器服务提供了安全,可靠和高性能的托管-这是Kubernetes最好的云托管服务之一。 阿里云团队坚信开源和开源社区的原则。 我们一定会继续分享我们在云技术的运营和管理领域的知识。