在本文中,我想分享我使用此开源库的经验,以通过解析包含专家简历的
PDF / DOC / DOCX文件来实现一项任务的示例。
在这里,我还将描述实现用于准备数据集的工具的阶段。 然后,有可能在接收到的数据集上训练
BERT模型,作为从文本识别实体的任务的一部分(
命名为Entity Recognition-以下简称
NER )。
所以,从哪里开始。 自然,首先,您需要安装和配置环境以运行我们的工具。 我将在
Windows 10上安装。
在Habré上,已经有该库开发人员的几篇文章,这里只有详细的安装指南。 在本文中,我希望将所有内容整合在一起,从发布到模型培训。 我还将指出使用该库时遇到的一些问题的解决方案。
重要信息:安装时,务必遵守所有产品和组件的版本,因为不兼容的版本经常会出现问题。 TensorFlow库尤其如此。 甚至碰巧,对于某些任务,直到在GitHub上的必要提交,您都需要使用它。 在DeepPavlov的情况下,仅支持受支持的版本就足够了。
我将指出工作配置的产品版本,以及开始训练神经网络的笔记本电脑的规格。 我将提供一些链接,这些链接还描述了开源
DeepPavlov库的安装和配置。
DeepPavlov开发人员的有用链接
用于安装的组件版本
- Python 3.6.6-3.7
- Visual Studio社区2017(可选)
- Visual C ++生成工具14.0.25420.1
- NVIDIA CUDA 10.0.130_411.31_win10
- cuDNN-10.0-windows10-x64-v7.6.5.32
设置GPU支持的环境
- 安装Python或Python附带的Visual Studio Community 2017 。 在安装过程中,我使用了第二种方法,即安装具有Python支持的Visual Studio社区 。
当然,您必须手动将路径添加到文件夹C:\Program Files (x86)\Microsoft Visual Studio\Shared\Python36_64
到从Visual Studio安装Python的PATH系统变量中,但这对我来说不是问题,对我来说重要的是要知道我为Python安装了一个版本。
但这是我的情况,您可以单独安装所有内容。 - 下一步是安装Visual C ++生成工具 。
- 接下来,安装nVIDIA CUDA 。
重要信息:如果以前安装了nVIDIA CUDA库,则必须从nVIDIA删除所有以前安装的组件,直到视频驱动程序为止。 然后,在全新安装视频驱动程序的情况下,执行nVIDIA CUDA的安装。
- 现在为nVIDIA CUDA安装cuDNN 。
为此,您需要注册NVIDIA Developer Program会员资格(免费)。

- 下载CUD 10.0的 cuDNN版本

- 将档案解压缩到一个文件夹中
C:\Users\<_>\Downloads\cuDNN
- 将文件夹.. \ cuDNN的全部内容复制到我们已安装CUDA的文件夹中
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0
- 重新启动计算机。 可选,但我建议。
安装DeepPavlov
- 创建并激活虚拟Python环境。
重要说明:我是通过Visual Studio做到的。
- 为此,我为From Existing Python code创建了一个新项目。

- 我们进一步按一下最后一个窗口,但是在“ 完成”上,我们还未单击。 您必须取消选中“ 检测虚拟环境 ”

- 点击完成 。
- 现在您需要创建一个虚拟环境。

- 默认情况下,我们保留所有内容。

- 在命令行上打开项目文件夹。 并执行命令:
.\env\Scripts\activate.bat

- 现在一切就绪,可以安装DeepPavlov了 。 我们执行命令:
pip install deeppavlov
- 接下来,您需要安装具有GPU支持的TensorFlow 1.14.0 。 为此,运行命令:
pip install tensorflow-gpu==1.14.0
- 几乎一切都准备就绪。 您只需要确保TensorFlow将使用图形卡进行计算即可。 为此,我们编写了一个简单的脚本devices.py ,其内容如下:
from tensorflow.python.client import device_lib print(device_lib.list_local_devices())
或tensorflow_test.py :
import tensorflow as tf tf.test.is_built_with_cuda() tf.test.is_gpu_available(cuda_only=False, min_cuda_compute_capability=None)
- 运行devices.py之后 ,我们应该看到类似以下内容:
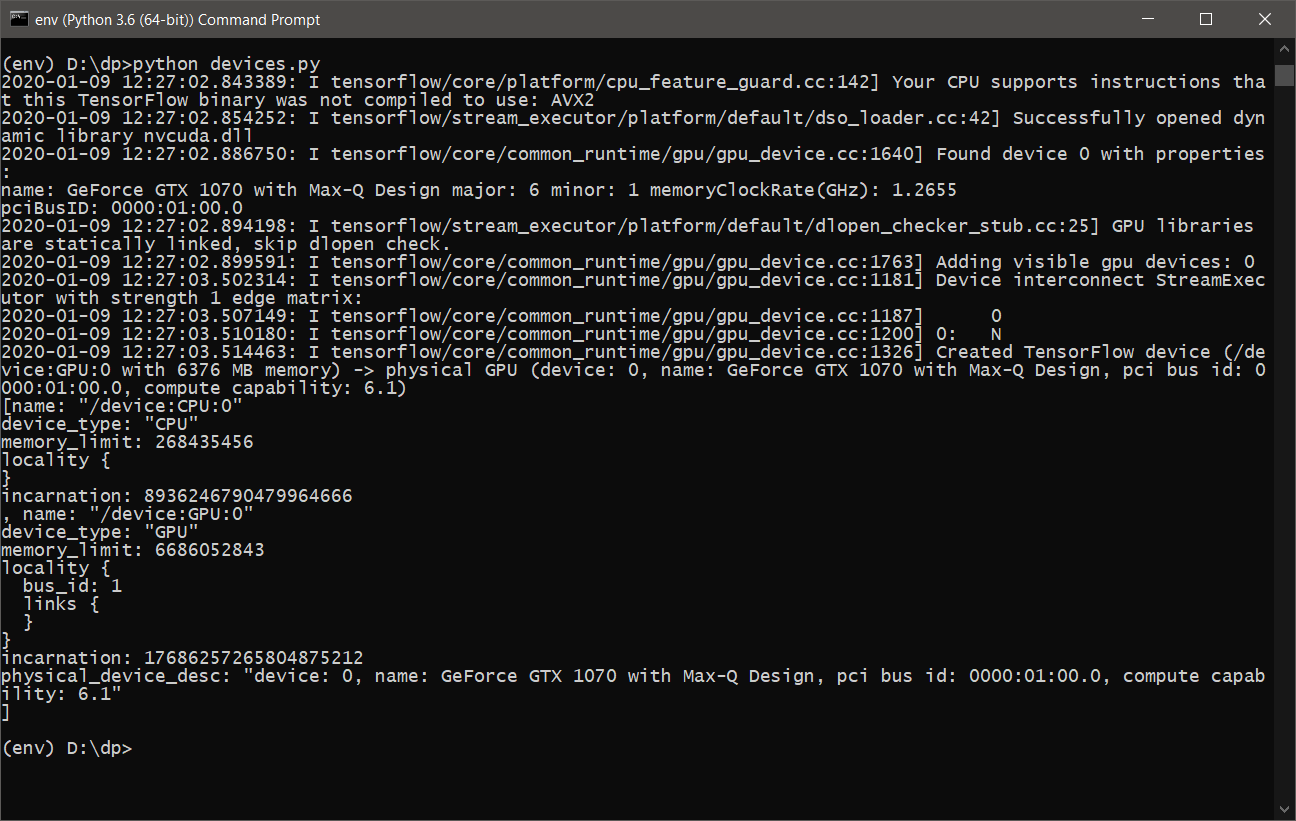
- 现在,您可以学习并使用带有GPU支持的DeepPavlov 。
REST API上的DeepPavlov
为了启动和安装REST API服务,您需要运行以下命令:
- 在活动的虚拟环境中安装
python -m deeppavlov install ner_ontonotes_bert_mult
- 从DeepPavlov服务器下载ner_ontonotes_bert_mult模型
python -m deeppavlov download ner_ontonotes_bert_mult
- 运行REST API
python -m deeppavlov riseapi ner_ontonotes_bert_mult -p 5005
该模型将在
http:// localhost:5005上可用。 您可以指定您的端口。
默认情况下,将默认下载所有模型。
C:\Users\<_>\.deeppavlov
设置DeepPavlov进行培训
在开始学习过程之前,我们需要配置
DeepPavlov ,以使学习过程不会因“视频卡上的内存已满”错误而“崩溃”。 为此,我们为每个模型提供了配置文件。
就像在开发人员的示例中一样,我还将使用
ner_ontonotes_bert_mult模型。
DeepPavlov的所有默认配置都位于路径上:
<_>\env\Lib\site-packages\deeppavlov\configs\ner
就我而言,该文件的名称将类似于
ner_ontonotes_bert_mult.json模型。
对于我的笔记本电脑配置,我必须将
训练块中的
batch_size值更改为4。

否则,几分钟后我的视频卡“窒息”,学习过程因错误而中断。
Nobook配置
- 型号: MSI GS-65
- 处理器: Core i7 8750H 2200 MHz
- 安装的内存量: 32 GB DDR-4
- 硬盘: 512 GB SSD
- 显卡: GeForce GTX 1070 8192 Mb
数据集准备工具
为了训练模型,您需要准备一个数据集。 数据集由三个文件
train.txt ,
valid.txt和
test.txt组成 。 在以下百分比列中细分数据-80%,有效并测试10%。
BERT模型的数据集如下:
Ivan B-PERSON Ivanov I-PERSON Senior B-WORK_OF_ART Java I-WORK_OF_ART Developer I-WORK_OF_ART IT B-ORG - I-ORG Company I-ORG Key O duties O : 0 Java B-WORK_OF_ART Python B-WORK_OF_ART CSS B-WORK_OF_ART JavaScript B-WORK_OF_ART Russian B-LOC Federation I-LOC . O Petr B-PERSON Petrov I-PERSON Junior B-WORK_OF_ART Web I-WORK_OF_ART Developer I-WORK_OF_ART Boogle B-ORG IO ' O ve O developed O Web B-WORK_OF_ART - O Application O . Skills O : O ReactJS B-WORK_OF_ART Vue B-WORK_OF_ART - I-WORK_OF_ART JS I-WORK_OF_ART HTML B-WORK_OF_ART CSS B-WORK_OF_ART Russian B-LOC Federation I-LOC . O ...
数据集的格式如下:
<_><><_>
重要提示:句子结尾后必须有换行符。 如果要约包含超过75个令牌,则还必须换行,否则学习模型时该过程将失败。
为了准备数据集,我编写了一个Web界面,可以在其中将
DOC / PDF / DOCX文件上传到服务器,将其解析为纯文本,然后将该文本通过具有REST API访问权限的活动模型传递,同时将结果保存在中间数据库中。 为此,我使用
MongoDB 。
完成上述操作后,您可以继续构建满足我们需求的数据集。
为此,我在书面Web界面中创建了一个单独的面板,可以在其中按数据集标记进行搜索,然后更改标记的类型和标记文本本身。
该工具还知道如何根据单词列表自动根据请求更新用户指定的令牌类型。
通常,该工具可帮助实现部分工作的自动化,但是您仍然必须进行大量手动工作。
还实现了一个用于检查结果并将数据集分为三个文件的接口。
DeepPavlov培训
因此,我们进入了最有趣的部分。 对于学习过程,您首先需要下载
ner_ontonotes_bert_mult模型,如果尚未下载,则需要完成从
DeepPavlov部分
到上面
的REST API的前两个步骤。
在开始学习过程之前,您必须完成两个步骤:
- 使用经过训练的模型完全删除文件夹:
C:\Users\<_>\.deeppavlov\models\ner_ontonotes_bert_mult
由于此模型是在不同的数据集上训练的。 - 将准备好的数据集文件train.txt,valid.txt,test.txt复制到该文件夹中
C:\Users\<_>\.deeppavlov\downloads\ontonotes
现在您可以开始学习过程。
要开始训练,您可以编写以下形式的简单
train.py脚本:
from deeppavlov import configs, train_model ner_model = train_model(configs.ner.ner_ontonotes_bert_mult, download=False)
或使用命令行:
python -m deeppavlov train <_>\env\Lib\site-packages\deeppavlov\configs\ner\ner_ontonotes_bert_mult.json
结果
我在具有115,540个令牌的数据集上训练了一个模型。 该数据集由100个员工简历文件生成。 学习过程花了我5个小时18分钟。
该模型具有以下含义:
- 精度:76.32%;
- 召回率:72.32%;
- FB1:74.27;
- 损失:5.4907482981681681826;
在编辑了数据集自动生成中的几个问题之后,我收到了以下
损失 。 但总的来说,我对结果感到满意。 当然,关于使用此库,我仍然有很多问题,我在这里所描述的只是九牛一毛。
我真的很喜欢该库的简单性和易用性。 至少对于
NER任务。 我将很高兴讨论该库的其他功能,并希望有人会从本文中找到有用的材料。