- 参赛作品
- 库连接
- 哪里上课
- 参加课程
- 类查询
╔═══╗╔═══╗╔═══╗╔═══╗╔╗─╔╗────╔═══╗╔══╗╔═══╗ ║╔══╝║╔═╗║║╔══╝║╔══╝║╚═╝║────║╔═╗║╚╗╔╝║╔══╝ ║║╔═╗║╚═╝║║╚══╗║╚══╗║╔╗─║────║╚═╝║─║║─║║╔═╗ ║║╚╗║║╔╗╔╝║╔══╝║╔══╝║║╚╗║────║╔══╝─║║─║║╚╗║ ║╚═╝║║║║║─║╚══╗║╚══╗║║─║║────║║───╔╝╚╗║╚═╝║ ╚═══╝╚╝╚╝─╚═══╝╚═══╝╚╝─╚╝────╚╝───╚══╝╚═══╝ 5HHHG HH HHHHHHH 9HHHA HHHHHHHH5 HHHHHHHHHHHHHHHHHH 9HHHHH5 5HHHHHHHHHHHHHHHHHHHHHHHHHHH HHHHHHHHHHHHHHHHHHHHHHHHHHHH ;HHHHHHHHHHHHHHHHHHHHHHHHHHA H2 HHHHHHHHHHHHHHHHHHHHHH HHHHHHHHHHHHHHHHHHHHHHH9 HHHHHHHHHHHHHHHHHHHHHHH AHHHHHHHHHHHHHHHHHHHHHH HHHHHHHHHHHHHHHHHHHHH9 iHS HHHHHHHHHHHHHHHHHHHHHHhh HHHHHHHHHHHHHHHHHH AA HHHHHHHHHHHHHH3 &H Hi HS Hr & H& H& Hi
参赛作品
我想告诉您有关我的PHP小库的开发。 她要解决什么任务? 我为什么决定写它,为什么对您有用? 好吧,尝试回答这些问题。
GreenPig (以下简称GP )是一个小型数据库助手,可以补充您使用的任何php框架的功能。
像任何GP工具一样,它也可以用于解决某些问题。 如果您更喜欢用纯sql编写数据库查询并且不使用Active Record和其他类似技术,这将对您很有用。 例如,我们有一个运行中的Oracle数据库,查询经常占据数十个连接,plsql函数,union all等的多个屏幕。 等等,所以除了用纯sql编写查询外,别无其他。
但是使用这种方法,就会出现一个问题:当用户搜索信息时,如何在sql查询的哪一部分生成? 首先, GP旨在通过php方便地编译任何复杂的请求。
但是是什么促使我编写了这个库(当然,除了获得有趣的经验之外)? 这是三件事:
首先,不是从数据库中获取标准的统一答案,而是从嵌套的树状数组中获取信息。
这是一个标准数据库示例的示例: [ [0] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 1 ['name'] => ' ()' ['value'] => 790 ], [1] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 2 ['name'] => ' ' ['value'] => 24 ], [2] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 3 ['name'] => ' ' ['value'] => 75 ], [3] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 10 ['name'] => ' ' ['value'] => 5 ], [4] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 8 ['name'] => ' ()' ['value'] => 0.12 ], [5] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 9 ['name'] => ' ' ['value'] => 1 ], [6] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 10 ['name'] => ' ' ['value'] => 5 ], [7] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 8 ['name'] => ' ()' ['value'] => 0.12 ], [8] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 9 ['name'] => ' ' ['value'] => 1 ], [9] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 10 ['name'] => ' ' ['value'] => 5 ], [10] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 8 ['name'] => ' ()' ['value'] => 0.12 ], [11] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 9 ['name'] => ' ' ['value'] => 1 ], [12] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 1 ['name'] => ' ()' ['value'] => 790 ], [13] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 2 ['name'] => ' ' ['value'] => 24 ], [14] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 3 ['name'] => ' ' ['value'] => 75 ], [15] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 1 ['name'] => ' ()' ['value'] => 790 ], [16] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 2 ['name'] => ' ' ['value'] => 24 ], [17] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 3 ['name'] => ' ' ['value'] => 75 ] ]
要获得树状数组,我们需要将结果自己转换为所需的形式,或者对每种产品进行N次数据库查询。 如果需要分页,甚至需要分页? GP能够解决这些问题。 这是GP示例的示例:
[ [1] => [ ['prod_type'] => 'car' ['properties'] => [ [1] => [ ['name'] => ' ()' ['value'] => 790 ] [2] => [ ['name'] => ' ' ['value'] => 24 ] [3] => [ ['name'] => ' ' ['value'] => 75 ] ] ] [4] => [ ['prod_type'] => 'phone' ['properties'] => [ [10] => [ ['name'] => ' ' ['value'] => 5 ] [8] => [ ['name'] => ' ()' ['value'] => 0.12 ] [9] => [ ['name'] => ' ' ['value'] => 1 ] ] ] ]
当然,同时方便分页和排序: ->pagination(1, 10)->sort('id') 。
第二个原因不是那么频繁,但是仍然会发生(在我看来,这是主要原因)。 如果某些实体存储在数据库中,并且这些实体的属性是动态的并且由用户设置,那么当您需要按其属性搜索实体时,您将必须添加(联接)具有属性值的同一表(使用次数为属性)。 因此,GP将帮助您连接所有表并使用几乎一个函数生成where查询。 在本文结尾处,我将详细分析这种情况。
最后,所有这些都应同时适用于Oracle数据库和mySql。 文档中还介绍了许多功能。
我有可能发明了另一辆自行车,但是我认真搜索,没有找到适合我的解决方案。 如果您知道可以解决这些问题的库-请在评论中写。
在直接检查图书馆本身和示例之前,我要说的是,这里只有本质,没有详细的解释。 如果您对GP的工作方式感兴趣,可以查看该文档 ,在该文档中,我试图详细解释所有内容。
库连接
该库可以通过composer安装: composer require falbin/green-pig-dao
然后,您需要编写一个工厂,通过该工厂将使用此库。
哪里上课
使用此类,您可以组成任何复杂程度的sql查询的where部分。
要求的原子部分
考虑查询的最小原子部分。 用数组描述: [, , ]
示例: ['name', 'like', '%%']
- 数组的第一个元素只是一个字符串,无需更改即可插入到sql查询中,因此,您可以在其中编写sql函数。 例如:
['LOWER(name)', 'like', '%%'] - 第二个元素也是插入到sql中的字符串,两个操作数之间没有变化。 它可以采用以下值: =,>,<,> =,<=,<>,例如,不喜欢,之间,不在之间,在,不在in 。
- 数组的第三个元素可以是数字或字符串类型。 该类将自动将生成的别名替换为sql查询的位置。
- 具有sql键的数组元素。 有时有必要将值插入到sql代码中而无需更改。 例如,应用功能。 这可以通过将“ sql”指定为键(对于第三个元素)来实现。 示例:
['LOWER(name)', 'like', 'sql' => "LOWER('$name')"] - 具有绑定键的数组元素是用于存储绑定的数组。 从安全角度来看,以上示例是错误的。 您无法在sql中插入变量-注入过多。 因此,在这种情况下,您将需要自己指定别名,例如:
['LOWER(name)', 'like', 'sql' => "LOWER(:name)", 'bind'=> ['name' => $name] ] - in运算符可以这样写:
['curse', 'not in', [1, 3, 5]] 。 Where类将此类条目转换为以下sql代码: curse not in (:al_where_jCgWfr95kh, :al_where_mCqefr95kh, :al_where_jCfgfr9Gkh) - 之间的语句可以这样写:
['curse', ' between', 1, 5] 。 Where类将此类条目转换为以下sql代码curse between :al_where_Pi4CRr4xNn and :al_where_WiPPS4NKiG
但是要小心,如果数组的第三和第四元素是字符串,则将应用特殊逻辑。 在这种情况下,可以认为该选择是从日期范围中进行的,因此,使用了将字符串转换为日期的sql函数。 转换为日期的功能(mySql和Oracle具有不同的日期),其参数取自一系列设置(在文档中有更多介绍)。 数组['build_date', 'between', '01.01.2016', '01.01.2019']将build_date between TO_DATE(:al_where_fkD7nZg5lU, 'dd.mm.yyyy hh24:mi::ss') and TO_DATE(:al_where_LdyVRznPF8, 'dd.mm.yyyy hh24:mi::ss')转换为sql: build_date between TO_DATE(:al_where_fkD7nZg5lU, 'dd.mm.yyyy hh24:mi::ss') and TO_DATE(:al_where_LdyVRznPF8, 'dd.mm.yyyy hh24:mi::ss')
复杂查询
让我们通过工厂创建该类的实例: $wh = GP::where();
要指示请求的“原子部分”之间的逻辑连接,必须使用linkAnd()或linkOr()函数。 一个例子:
使用linkAnd / linkOr函数时,所有数据都存储在Where- $ wh类的实例中。 此外,功能中指示的所有“原子部分” 都用括号括起来 。
任何复杂性的sql都可以通过三个函数来描述: linkAnd(), linkOr(), getRaw() 。 考虑一个例子:
Where类具有一个私有变量,用于存储原始表达式。 linkAnd()和linkOr()方法会覆盖此变量,因此,在构造逻辑表达式时,方法将嵌套在一起,并且带有原始表达式的变量包含从上次执行的方法获得的数据。
参加班
Join是一个生成sql代码的连接片段的类。 让我们通过工厂创建该类的实例: $jn = GP::leftJoin('coursework', 'student_id', 's.id') ,其中:
- 课程是我们将要参加的表。
- student_id-具有来自课程表的外键的列。
- s.id-应该与表一起写入联接的表的列(在这种情况下,表的别名为s)。
生成的sql: left JOIN coursework coursework_joM9YuTTfW ON coursework_joM9YuTTfW.student_id = s.id
在创建类的实例时,我们已经描述了连接表的条件,但是可能有必要澄清和扩展条件。 linkAnd / linkOr函数将帮助您完成此操作: $jn->linkAnd(['semester_number', '>', 2])
生成的SQL: inner JOIN coursework coursework_Nd1n5T7c0r ON coursework_Nd1n5T7c0r.student_id = s.id and (semester_number > :al_where_M1kEcHzZyy)
如果有多个表要联接,则可以将它们合并到一个类中: CollectionJoin 。
类查询
这是使用数据库的主要类别,通过它可以选择,记录,更新和删除数据。 您还可以对从数据库获得的数据执行某些处理。
考虑一个典型的例子。
让我们通过工厂创建该类的实例: $qr = GP::query();
现在,我们将设置sql模板,将给定场景所需的值替换为sql模板,并说我们要获取一条记录,尤其是来自average_mark列的数据。
$rez = $qr->sql("select /*select*/ from student s inner join mark m on s.id = m.student_id inner join lesson l on l.id = m.lesson_id /*where*/ /*group*/") ->sqlPart('/*select*/', 's.name, avg(m.mark) average_mark', []) ->whereAnd('/*where*/', ['s.id', '=', 1]) ->sqlPart('/*group*/', 'group by s.name', []) ->one('average_mark');
结果: 3,16666666666666666666666666666666666667
从具有嵌套参数的数据库中选择
最重要的是,我没有机会在具有附加属性的树状视图中从数据库中进行选择。 因此,GP库具有这样的机会,并且嵌套的深度不受限制。
考虑操作原理的最简单方法是基于一个示例。 考虑一下,我们采用以下数据库架构:

表内容:
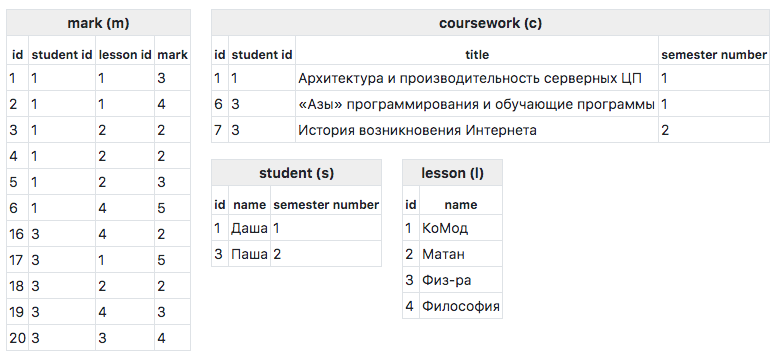
通常,在查询数据库时,您希望获得树状而非平坦的答案。 例如,通过运行以下查询:
SELECT s.id, s.name, c.id title_id, c.title FROM student s INNER JOIN coursework c ON c. student_id = s.id WHERE s.id = 3
我们得到一个一致的结果:
[ 0 => [ 'id' => 3, 'name' => '', 'title_id' => 6, 'title' => '«» ', ], 1=> [ 'id' => 3, 'name' => '', 'title_id' => 7, 'title' => ' ' ] ]
使用GP,您可以获得以下结果:
[ 3 => [ 'name' => '', 'courseworks' => [ 6 => ['title' => '«» '], 7 => ['title' => ' '] ] ] ]
要获得此结果,您需要将带有选项的数组传递给all函数(该函数返回所有查询行):
all([ 'id'=> 'pk', 'name' => 'name', 'courseworks' => [ 'title_id' => 'pk', 'title' => 'title' ] ])
函数聚合器( $option ,$ rawData)和所有( $options )中的$option数组是根据以下规则构建的:
- 数组键 -列名。 数组元素 -列的新名称,您可以输入旧名称。
- 数组值有一个保留字
pk 。 它说数据将按此列分组(数组键是该列的名称)。 - 在每个级别上,只有一个
pk 。 - 在聚合(结果)数组中,
pk声明的列中的值将用作键。 - 如果有必要将部分列的位置放低一些,则使用新的发明名称作为数组键,并将根据上述规则构造的数组用作值。
考虑一个更复杂的例子。 假设我们需要让所有学生获得其课程名称和所有学科的所有年级。 我们希望收到的不是平面图,而是树状图,没有重复。 以下是对数据库和结果的所需查询。
SELECT s.id student_id, s.name student_name, s.semester_number, c.id coursework_id, c.semester_number coursework_semester, c.title coursework_title, l.id lesson_id, l.name lesson, m.id mark_id, m.mark FROM student s LEFT JOIN coursework c ON c.student_id = s.id LEFT JOIN mark m ON m.student_id = s.id LEFT JOIN lesson l ON l.id = m.lesson_id ORDER BY s.id, c.id, l.id, m.id
结果不适合我们:
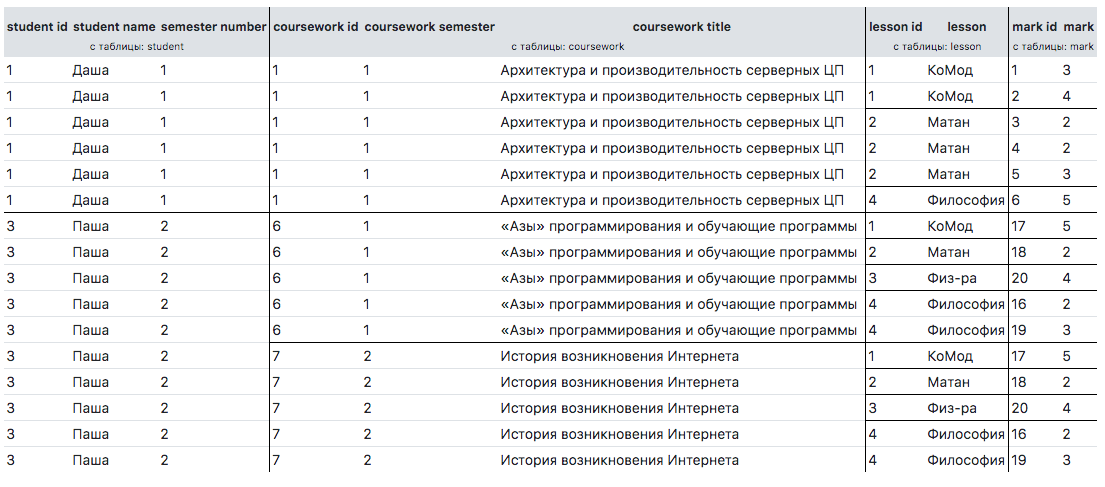
要完成此任务,您需要编写以下$option数组:
$option = [ 'student_id' => 'pk', 'student_name' => 'name', 'courseworks' => [ 'coursework_semester' => 'pk', 'coursework_title' => 'title' ], 'lessons' => [ 'lesson_id' => 'pk', 'lesson' => 'lesson', 'marks' => [ 'mark_id' => 'pk', 'mark' => 'mark' ] ] ];
数据库查询:
根据$option描述的规则, aggregator函数可以处理结构类似于数据库查询结果的任何数组。
$result变量包含以下数据:
[ 1 => [ 'name' => '', 'courseworks' => [ 1 => ['title' => ' '], ], 'lessons' => [ 1 => [ 'lesson' => '', 'marks' => [ 1 => ['mark' => 3], 2 => ['mark' => 4] ] ], 2 => [ 'lesson' => '', 'marks' => [ 3 => ['mark' => 2], 4 => ['mark' => 2], 5 => ['mark' => 3] ] ], 4 => [ 'lesson' => '', 'marks' => [ 6 => ['mark' => 5] ] ] ] ], 3 => [ 'name' => '', 'courseworks' => [ 1 => ['title' => '«» '], 2 => ['title' => ' '] ], 'lessons' => [ 1 => [ 'lesson' => '', 'marks' => [ 17 => ['mark' => 5] ] ], 2 => [ 'lesson' => '', 'marks' => [ 18 => ['mark' => 2] ] ], 3 => [ 'lesson' => '-', 'marks' => [ 20 => ['mark' => 4] ] ], 4 => [ 'lesson' => '', 'marks' => [ 16 => ['mark' => 2], 19 => ['mark' => 3] ] ], ] ] ]
顺便说一下,在使用聚合查询进行分页时,仅考虑最顶层,最基本的数据。 在上面的示例中,只有2行用于分页。
以搜索的名义与自己进行多次联合
如我先前所写,库的主要任务是简化用于选择查询的where部分的生成。 因此,在这种情况下,我们可能需要重复联接'nite同一表以进行where查询? 一种选择是,当我们拥有某个属性事先未知的产品时,这些属性将由用户添加,并且我们需要有机会通过这些动态属性来搜索产品。 用简化示例进行解释的最简单方法。
假设我们有一家在线商店出售计算机组件,并且我们没有严格的分类,我们将定期购买一个或另一个组件。 但是我们想将所有产品描述为一个实体并搜索所有产品。 因此,从业务逻辑的角度来看,可以区分哪些实体:
- 产品。 建立一切的最重要实体。
- 产品类型。 这可以表示为所有其他产品属性的根属性。 例如,在我们的小型商店中,只有:RAM,SSD和HDD。
- 产品特性。 在我们的实现中,任何属性都可以应用于任何类型的产品,选择权仍然取决于经理。 在我们的商店中,管理人员仅设置了3个属性:内存大小,外形尺寸和DDR。
- 商品的价值。 买方将在搜索中推动的价值。
下图详细反映了上述所有业务逻辑。
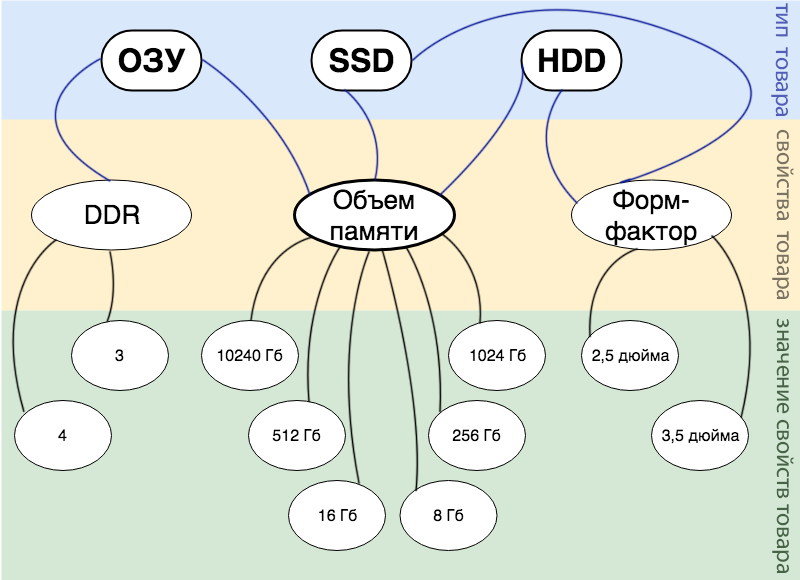
例如,我们有一个产品: 16 GB DDR 3 RAM 。 在图中,可以如下显示:
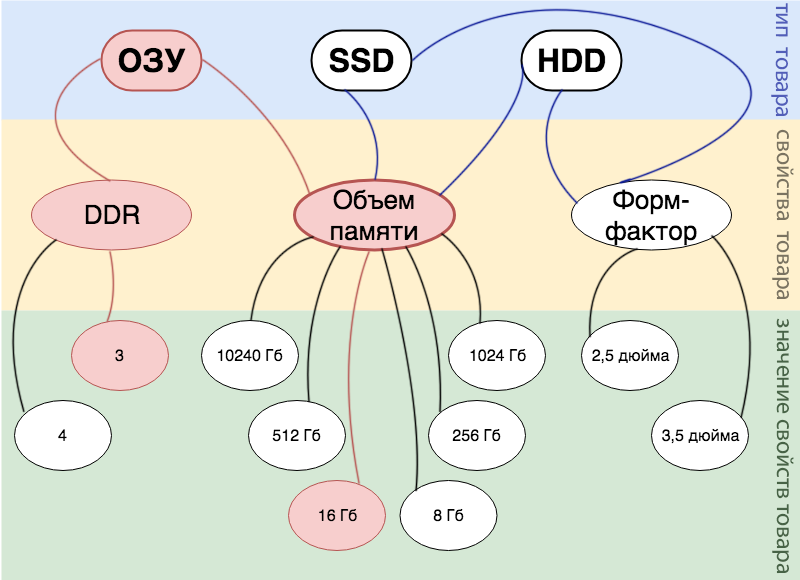
下图中清晰可见数据库的结构和数据:
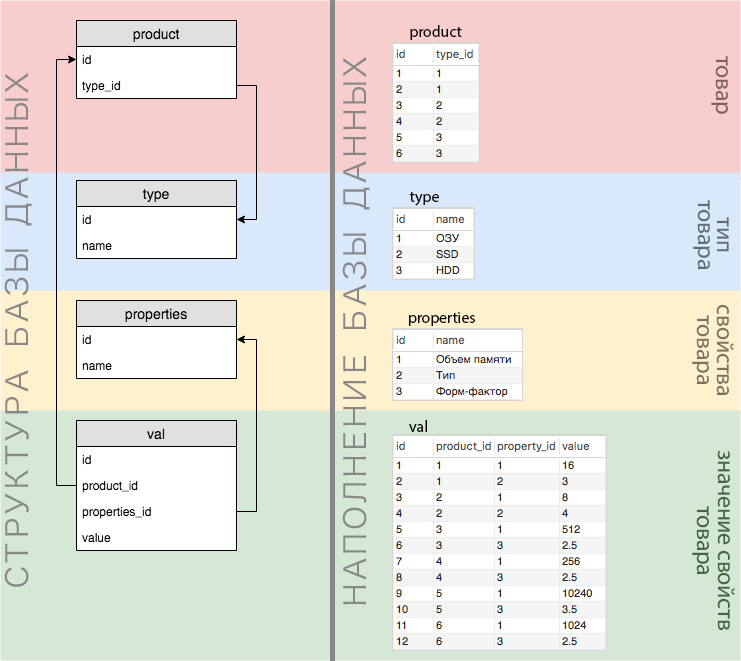
从图中可以看出,所有属性的所有值都存储在一个val表中(顺便说一下,在我们的简化版本中,所有属性都有数值)。 因此,如果我们要使用一堆AND同时搜索多个属性,则会得到一个空选择。
例如,购买者正在寻找适合这种要求的产品: 内存量应大于10 GB,形状因数应为2.5英寸 。 如果我们如下所示编写sql,则会得到一个空选择:
select * from product p inner join val v on v.product_id = p.id where (v.property_id = 1 and v.value > 10) AND (v.property_id = 3 and v.value = 2.5)
由于所有属性的值都存储在一个表中,因此要搜索多个属性,必须将要搜索的每个属性的表val联接在一起。 但是有一个细微差别,join是“水平”连接表的(对于“ union”一词,所有连接都是“垂直”连接的),以下是一个示例:

此结果不适合我们,我们希望在一列中查看所有值。 为此,您需要比执行搜索的属性多1倍的联接val表。

我们接近自动生成sql查询。 让我们看一下功能
whereWithJoin ($aliasJoin, $options, $aliasWhere, $where) ,它将完成所有工作:
- $ aliasJoin-基本模板中的别名,而不是具有连接的sql部分代替。
- $ options-一个数组,其中包含用于生成联接部分的规则的描述。
- $ aliasWhere-基本模板中的别名,它代替where sql部分。
- $ where是Where类的实例。
让我们看一个例子: whereWithJoin('/*join*/', $options, '/*where*/', $wh) 。
首先,创建$ options变量: $options = ['v' => ['val', 'product_id', 'p.id']];
v是表的别名。 如果在$ wh中找到给定的别名,则将通过join连接一个新的val表(其中product_id是val表的外键,而p.id是具有别名p的表的主键),将为其生成新的别名和该别名。将在其中替换v 。
$ wh是Where类的实例。 我们形成相同的请求: 内存应大于10 GB,并且外形尺寸应为2.5英寸。
$wh->linkAnd([ $wh->linkAnd([ ['v.property_id', '=', 1], ['v.value', '>', 10] ])->getRaw(),
创建where请求时,必须将带有id属性及其值的部分包装在方括号中,这告诉whereWithJoin()函数表别名在该部分中将是相同的。
$qr->sql("select p.id, t.name type_name, pr.id prop_id, pr.name prop_name, v.id val_id, v.value from product p inner join type t on t.id = p.type_id inner join val v on v.product_id = p.id inner join properties pr on pr.id = v.property_id /*join*/ /*where*/") ->whereWithJoin('/*join*/', $options, '/*where*/', $wh)
我们查看生成的sql,绑定和查询的执行时间: $qr->debugInfo() :
[ [ 'type' => 'info', 'sql' => 'select p.id, t.name type_name, pr.id prop_id, pr.name prop_name, v.id val_id, v.value from product p inner join type t on t.id = p.type_id inner join val v on v.product_id = p.id inner join properties pr on pr.id = v.property_id inner JOIN val val_mIQWpnHhdQ ON val_mIQWpnHhdQ.product_id = p.id inner JOIN val val_J0uveMpwEM ON val_J0uveMpwEM.product_id = p.id WHERE ( val_mIQWpnHhdQ.property_id = :al_where_leV5QlmOZN and val_mIQWpnHhdQ.value > :al_where_ycleYAswIw ) and ( val_J0uveMpwEM.property_id = :al_where_dinxDraTOE and val_J0uveMpwEM.value = :al_where_wZJhUqs74i )', 'binds' => [ 'al_where_leV5QlmOZN' => 1, 'al_where_ycleYAswIw' => 10, 'al_where_dinxDraTOE' => 3, 'al_where_wZJhUqs74i' => 2.5 ], 'timeQuery' => 0.0384588241577 ] ]
$qr->rawData() :
[ [ 'id' => 3, 'type_name' => 'SSD', 'prop_id' => 1, 'prop_name' => ' ', 'val_id' => 5, 'value' => 512 ], [ 'id' => 3, 'type_name' => 'SSD', 'prop_id' => 3, 'prop_name' => '-', 'val_id' => 6, 'value' => 2.5 ], [ 'id' => 4, 'type_name' => 'SSD', 'prop_id' => 1, 'prop_name' => ' ', 'val_id' => 7, 'value' => 256 ], [ 'id' => 4, 'type_name' => 'SSD', 'prop_id' => 3, 'prop_name' => '-', 'val_id' => 8, 'value' => 2.5 ], [ 'id' => 6, 'type_name' => 'HDD', 'prop_id' => 1, 'prop_name' => ' ', 'val_id' => 11, 'value' => 1024 ], [ 'id' => 6, 'type_name' => 'HDD', 'prop_id' => 3, 'prop_name' => '-', 'val_id' => 12, 'value' => 2.5 ] ]
$qr->aggregateData() :
[ 3 => [ 'type' => 'SSD', 'properties' => [ 1 => [ 'name' => ' ', 'values' => [ 5 => ['val' => 512] ] ], 3 => [ 'name' => '-', 'values' => [ 6 => ['val' => 2.5] ] ] ] ], 4 => [ 'type' => 'SSD', 'properties' => [ 1 => [ 'name' => ' ', 'values' => [ 7 => ['val' => 256] ] ], 3 => [ 'name' => '-', 'values' => [ 8 => ['val' => 2.5] ] ] ] ], 6 => [ 'type' => 'HDD', 'properties' => [ 1 => [ 'name' => ' ', 'values' => [ 11 => ['val' => 1024] ] ], 3 => [ 'name' => '-', 'values' => [ 12 => ['val' => 2.5] ] ] ] ] ]
, , whereWithJoin() , .
whereWithJoin() , , n , m . n m 1 id . , AND .
GitHub .