Keras具有两个API,用于快速构建顺序和功能神经网络体系结构。 如果第一个只允许您构建神经网络的顺序体系结构,则可以使用Functional API以任意有向无环图的形式定义神经网络,这为构建复杂模型提供了更多机会。 本文是TensorFlow网站上的《功能API功能指南》的翻译版本。
引言
通过功能API,您可以比顺序API更灵活地创建模型;它可以处理具有非线性拓扑的模型,具有公共层的模型以及具有多个输入或输出的模型。
它基于这样一个事实,即深度学习模型通常是层的有向无环图(DAG)
功能API是用于
绘制图层的一组工具。
考虑以下模型:
(输入:784维向量)
↧
[致密层(64个元素,激活relu)]
↧
[致密层(64个元素,激活relu)]
↧
[致密层(10个元素,激活softmax)]
↧
(输出:10个类别的概率分布)
这是3层的简单图形。
要使用Functional API构建此模型,您需要首先创建一个输入节点:
from tensorflow import keras inputs = keras.Input(shape=(784,))
在这里,我们仅指示数据的维数:784维向量。 请注意,总是忽略数据量,我们仅指示每个元素的尺寸。 要输入用于图像`(32,32,3)`的尺寸,我们将使用:
img_inputs = keras.Input(shape=(32, 32, 3))
inputs返回的内容包含有关您计划转移到模型的数据的大小和类型的信息:
inputs.shape
TensorShape([None, 784])
inputs.dtype
tf.float32
通过在此
inputs对象上调用图层,可以在图层图中创建一个新节点:
from tensorflow.keras import layers dense = layers.Dense(64, activation='relu') x = dense(inputs)
“调用图层”类似于将箭头从“输入”绘制到我们创建的图层中。 我们将输入“传递”到
dense层,得到
x 。
让我们在图层图中添加更多的图层:
x = layers.Dense(64, activation='relu')(x) outputs = layers.Dense(10, activation='softmax')(x)
现在我们可以
Model在图层图中指定其输入和输出来创建
Model :
model = keras.Model(inputs=inputs, outputs=outputs)
让我们再次看一下完整的模型定义过程:
inputs = keras.Input(shape=(784,), name='img') x = layers.Dense(64, activation='relu')(inputs) x = layers.Dense(64, activation='relu')(x) outputs = layers.Dense(10, activation='softmax')(x) model = keras.Model(inputs=inputs, outputs=outputs, name='mnist_model')
让我们看看模型摘要是什么样的:
model.summary()
Model: "mnist_model" _________________________________________________________________ Layer (type) Output Shape Param
我们还可以将模型绘制为图形:
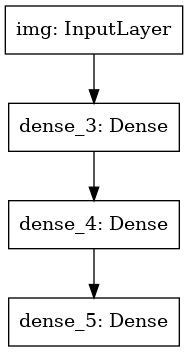
keras.utils.plot_model(model, 'my_first_model.png')
并可选地得出构造图上每一层的输入和输出的尺寸:
keras.utils.plot_model(model, 'my_first_model_with_shape_info.png', show_shapes=True)
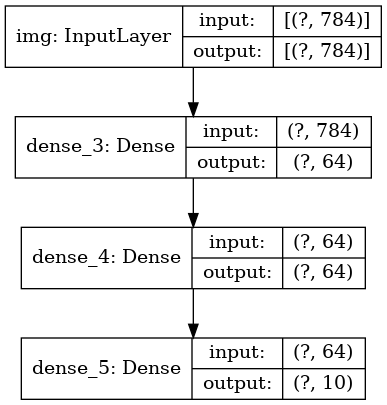
此图像和我们编写的代码相同。 在代码版本中,绑定箭头仅由调用操作代替。
“层图”是用于深度学习模型的非常直观的心理图像,而Functional API是创建紧密反映该心理图像的模型的方法。
培训,评估和结论
就像在顺序模型中一样,学习,评估和推导使用功能API构建的模型的工作。
考虑一个快速演示。
在这里,我们加载MNIST图像数据集,将其转换为矢量,在数据上训练模型(同时监视测试样本的工作质量),最后我们在测试数据上评估模型:
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data() x_train = x_train.reshape(60000, 784).astype('float32') / 255 x_test = x_test.reshape(10000, 784).astype('float32') / 255 model.compile(loss='sparse_categorical_crossentropy', optimizer=keras.optimizers.RMSprop(), metrics=['accuracy']) history = model.fit(x_train, y_train, batch_size=64, epochs=5, validation_split=0.2) test_scores = model.evaluate(x_test, y_test, verbose=2) print('Test loss:', test_scores[0]) print('Test accuracy:', test_scores[1])
保存和序列化
使用Functional API构建的模型的保存和序列化与顺序模型的保存和序列化完全相同。
保存功能模型的标准方法是调用
model.save( ),它允许您将整个模型保存在一个文件中。
以后,即使您不再有权访问创建模型的代码,也可以从该文件恢复相同的模型。
该文件包括:
- 模型架构
- 模型权重(在训练过程中获得)
- 模型训练配置(您在
compile传递的内容) - 优化器及其条件(如果有)(这使您可以从上次停止的地方继续训练)
model.save('path_to_my_model.h5') del model
使用同一层图定义多个模型
在Functional API中,通过在图层图中指定输入和输出数据来创建模型。 这意味着单层图可用于生成多个模型。
在下面的示例中,我们使用相同的图层堆栈来创建两个模型:
将输入图像转换为16维矢量的
(encoder)模型,以及用于训练的端到端
(autoencoder) (encoder)模型。
encoder_input = keras.Input(shape=(28, 28, 1), name='img') x = layers.Conv2D(16, 3, activation='relu')(encoder_input) x = layers.Conv2D(32, 3, activation='relu')(x) x = layers.MaxPooling2D(3)(x) x = layers.Conv2D(32, 3, activation='relu')(x) x = layers.Conv2D(16, 3, activation='relu')(x) encoder_output = layers.GlobalMaxPooling2D()(x) encoder = keras.Model(encoder_input, encoder_output, name='encoder') encoder.summary() x = layers.Reshape((4, 4, 1))(encoder_output) x = layers.Conv2DTranspose(16, 3, activation='relu')(x) x = layers.Conv2DTranspose(32, 3, activation='relu')(x) x = layers.UpSampling2D(3)(x) x = layers.Conv2DTranspose(16, 3, activation='relu')(x) decoder_output = layers.Conv2DTranspose(1, 3, activation='relu')(x) autoencoder = keras.Model(encoder_input, decoder_output, name='autoencoder') autoencoder.summary()
请注意,我们使解码架构与编码架构严格对称,以便使输出数据的维数与输入数据
(28, 28, 1) 。
Conv2D层
Conv2D到
Conv2D层,而
MaxPooling2D层将回到
MaxPooling2D层。
模型可以称为图层
您可以使用任何模型,就好像它是一个层一样,在
Input或另一层的输出上调用它。
请注意,通过调用模型,不仅可以重用其体系结构,还可以重用其权重。 让我们来看看它的作用。 这是另一种自动编码器的示例,当创建编码器模型,解码器模型并将它们连接到两个调用中以获得自动编码器模型时:
encoder_input = keras.Input(shape=(28, 28, 1), name='original_img') x = layers.Conv2D(16, 3, activation='relu')(encoder_input) x = layers.Conv2D(32, 3, activation='relu')(x) x = layers.MaxPooling2D(3)(x) x = layers.Conv2D(32, 3, activation='relu')(x) x = layers.Conv2D(16, 3, activation='relu')(x) encoder_output = layers.GlobalMaxPooling2D()(x) encoder = keras.Model(encoder_input, encoder_output, name='encoder') encoder.summary() decoder_input = keras.Input(shape=(16,), name='encoded_img') x = layers.Reshape((4, 4, 1))(decoder_input) x = layers.Conv2DTranspose(16, 3, activation='relu')(x) x = layers.Conv2DTranspose(32, 3, activation='relu')(x) x = layers.UpSampling2D(3)(x) x = layers.Conv2DTranspose(16, 3, activation='relu')(x) decoder_output = layers.Conv2DTranspose(1, 3, activation='relu')(x) decoder = keras.Model(decoder_input, decoder_output, name='decoder') decoder.summary() autoencoder_input = keras.Input(shape=(28, 28, 1), name='img') encoded_img = encoder(autoencoder_input) decoded_img = decoder(encoded_img) autoencoder = keras.Model(autoencoder_input, decoded_img, name='autoencoder') autoencoder.summary()
如您所见,可以嵌套一个模型:一个模型可以包含一个子模型(因为该模型可以视为一个层)。
嵌套模型的一个常见用例是
集合 。
举例来说,以下是将一组模型组合成一个对预测值求平均的模型的方法:
def get_model(): inputs = keras.Input(shape=(128,)) outputs = layers.Dense(1, activation='sigmoid')(inputs) return keras.Model(inputs, outputs) model1 = get_model() model2 = get_model() model3 = get_model() inputs = keras.Input(shape=(128,)) y1 = model1(inputs) y2 = model2(inputs) y3 = model3(inputs) outputs = layers.average([y1, y2, y3]) ensemble_model = keras.Model(inputs=inputs, outputs=outputs)
处理复杂的图拓扑
具有多个输入和输出的模型
Functional API简化了多个输入和输出的操作。 这不能使用顺序API来完成。
这是一个简单的例子。
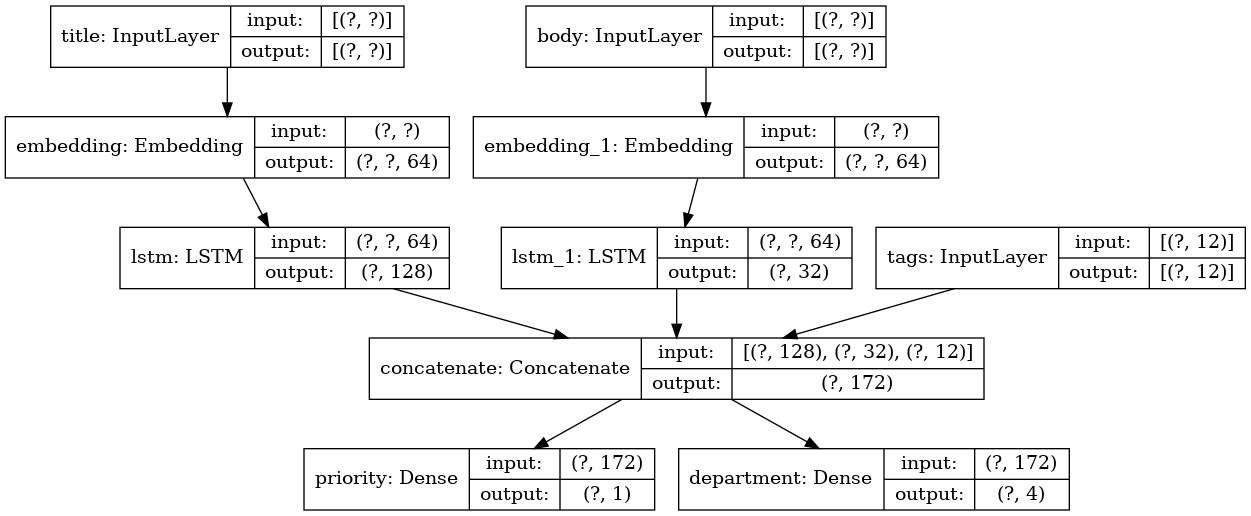
假设您正在创建一个系统,用于按优先级对客户应用程序进行排名,并将其发送给正确的部门。
您的模型将具有3个输入:
- 应用程序标题(文本输入)
- 应用程序的文本内容(文本输入)
- 用户添加的所有标签(分类输入)
该模型将有2个输出:
- 优先级得分介于0和1之间(标量S型输出)
- 必须处理应用程序的部门(有关多个部门的softmax输出)
让我们使用Functional API几行构建一个模型。
num_tags = 12
让我们画一个模型图:
keras.utils.plot_model(model, 'multi_input_and_output_model.png', show_shapes=True)
编译此模型时,我们可以为每个输出分配不同的损失函数。
您甚至可以为每个损失函数分配不同的权重,以改变它们对整体学习损失函数的贡献。
model.compile(optimizer=keras.optimizers.RMSprop(1e-3), loss=['binary_crossentropy', 'categorical_crossentropy'], loss_weights=[1., 0.2])
因为我们给输出层起了名字,所以我们也可以指定损失函数:
model.compile(optimizer=keras.optimizers.RMSprop(1e-3), loss={'priority': 'binary_crossentropy', 'department': 'categorical_crossentropy'}, loss_weights=[1., 0.2])
我们可以通过传递输入数据和标签的Numpy数组列表来训练模型:
import numpy as np
使用
Dataset对象调用fit时,应返回列表的元组(例如
([title_data, body_data, tags_data], [priority_targets, dept_targets])或字典的元组
({'title': title_data, 'body': body_data, 'tags': tags_data}, {'priority': priority_targets, 'department': dept_targets}) 。
培训资源模型
除了具有多个输入和输出的模型外,Functional API还简化了具有非线性连接的拓扑的操作,即,其中的模型没有串联连接。 此类模型也无法使用顺序API来实现(顾名思义)。
常见的用例是残余连接。
让我们为CIFAR10建立一个ResNet培训模型来演示这一点。
inputs = keras.Input(shape=(32, 32, 3), name='img') x = layers.Conv2D(32, 3, activation='relu')(inputs) x = layers.Conv2D(64, 3, activation='relu')(x) block_1_output = layers.MaxPooling2D(3)(x) x = layers.Conv2D(64, 3, activation='relu', padding='same')(block_1_output) x = layers.Conv2D(64, 3, activation='relu', padding='same')(x) block_2_output = layers.add([x, block_1_output]) x = layers.Conv2D(64, 3, activation='relu', padding='same')(block_2_output) x = layers.Conv2D(64, 3, activation='relu', padding='same')(x) block_3_output = layers.add([x, block_2_output]) x = layers.Conv2D(64, 3, activation='relu')(block_3_output) x = layers.GlobalAveragePooling2D()(x) x = layers.Dense(256, activation='relu')(x) x = layers.Dropout(0.5)(x) outputs = layers.Dense(10, activation='softmax')(x) model = keras.Model(inputs, outputs, name='toy_resnet') model.summary()
让我们画一个模型图:
keras.utils.plot_model(model, 'mini_resnet.png', show_shapes=True)

并教她:
(x_train, y_train), (x_test, y_test) = keras.datasets.cifar10.load_data() x_train = x_train.astype('float32') / 255. x_test = x_test.astype('float32') / 255. y_train = keras.utils.to_categorical(y_train, 10) y_test = keras.utils.to_categorical(y_test, 10) model.compile(optimizer=keras.optimizers.RMSprop(1e-3), loss='categorical_crossentropy', metrics=['acc']) model.fit(x_train, y_train, batch_size=64, epochs=1, validation_split=0.2)
层共享
Functional API的另一个很好的用途是使用公共层的模型。 通用层是在同一模型中重复使用的层的实例:它们研究与层图中的若干路径相关的特征。
公共层通常用于对来自相同空间(例如,来自具有相同字典的两个不同文本的文本)的输入数据进行编码,因为它们提供了这些不同数据之间的信息交换,从而使此类模型可以使用更少的数据进行训练。 如果某个单词出现在其中一个输入上,这将有助于在通过常规级别的所有输入上对其进行处理。
要在Functional API中共享层,只需多次调用该层的同一实例即可。 例如,此处的
Embedding层在两个文本输入上共享:
检索和重用图层图中的节点
由于您在Functional API中操作的图层图是静态数据结构,因此您可以对其进行访问和检查。 例如,这就是我们以图像形式构建功能模型的方式。
这也意味着我们可以访问中间层(图中的“节点”)的激活,并在其他地方使用它们。 例如,这对于提取特征非常有用!
让我们来看一个例子。 这是一个VGG19模型,其缩放比例已在ImageNet上进行了预训练:
from tensorflow.keras.applications import VGG19 vgg19 = VGG19()
这些是通过查询图形数据结构获得的中间模型激活:
features_list = [layer.output for layer in vgg19.layers]
我们可以使用这些特征来创建一个新的特征提取模型,该模型返回中间级别的激活值-我们可以在3行中全部完成
feat_extraction_model = keras.Model(inputs=vgg19.input, outputs=features_list) img = np.random.random((1, 224, 224, 3)).astype('float32') extracted_features = feat_extraction_model(img)
与其他情况一样,这在实现神经样式转换时很方便。
通过编写自定义层来扩展API
tf.keras具有广泛的内置层。 以下是一些示例:
卷积层:
Conv1D ,
Conv2D ,
Conv3D ,
Conv2DTranspose等
MaxPooling1D层:
MaxPooling1D ,
MaxPooling2D ,
MaxPooling3D ,
AveragePooling1D等
RNN层:
GRU ,
LSTM ,
ConvLSTM2D等。
BatchNormalization ,
Dropout ,
Embedding等
如果您找不到所需的内容,则可以通过创建自己的层来扩展API。
所有图层都继承了
Layer类并实现:
定义该层执行的计算的
call方法。
创建图层权重的
build方法(请注意,这只是一种样式约定;您也可以在
__init__创建权重)。
这是
Dense层的简单实现:
class CustomDense(layers.Layer): def __init__(self, units=32): super(CustomDense, self).__init__() self.units = units def build(self, input_shape): self.w = self.add_weight(shape=(input_shape[-1], self.units), initializer='random_normal', trainable=True) self.b = self.add_weight(shape=(self.units,), initializer='random_normal', trainable=True) def call(self, inputs): return tf.matmul(inputs, self.w) + self.b inputs = keras.Input((4,)) outputs = CustomDense(10)(inputs) model = keras.Model(inputs, outputs)
如果您希望自定义图层支持序列化,则还必须定义
get_config方法,该方法返回图层实例的构造函数参数:
class CustomDense(layers.Layer): def __init__(self, units=32): super(CustomDense, self).__init__() self.units = units def build(self, input_shape): self.w = self.add_weight(shape=(input_shape[-1], self.units), initializer='random_normal', trainable=True) self.b = self.add_weight(shape=(self.units,), initializer='random_normal', trainable=True) def call(self, inputs): return tf.matmul(inputs, self.w) + self.b def get_config(self): return {'units': self.units} inputs = keras.Input((4,)) outputs = CustomDense(10)(inputs) model = keras.Model(inputs, outputs) config = model.get_config() new_model = keras.Model.from_config( config, custom_objects={'CustomDense': CustomDense})
(可选)您还可以实现
from_config (cls, config)类方法,该方法负责根据给定的配置字典重新创建图层实例。 默认
from_config如下所示:
def from_config(cls, config): return cls(**config)
何时使用功能性API
如何确定何时最好使用Functional API创建新模型,或者直接将
Model子类化?
通常,Functional API更加高级且易于使用,它具有许多子类模型不支持的功能。
但是,在创建不容易描述为有向无环层图的模型时,对模型进行子类化可为您提供极大的灵活性(例如,您无法使用Functional API实现Tree-RNN,您需要直接对
Model进行子类化)。
功能性API的优势:
下面列出的属性对于顺序模型(也是数据结构)都是正确的,但对于子类模型(是Python代码,不是数据结构)都是正确的。
Functional API生成较短的代码。
没有
super(MyClass, self).__init__(...) ,没有
def call(self, ...):等
比较:
inputs = keras.Input(shape=(32,)) x = layers.Dense(64, activation='relu')(inputs) outputs = layers.Dense(10)(x) mlp = keras.Model(inputs, outputs)
带有子类版本:
class MLP(keras.Model): def __init__(self, **kwargs): super(MLP, self).__init__(**kwargs) self.dense_1 = layers.Dense(64, activation='relu') self.dense_2 = layers.Dense(10) def call(self, inputs): x = self.dense_1(inputs) return self.dense_2(x)
您的模型在编写时已通过验证。
在Functional API中,输入规范(shape和dtype)是预先创建的(通过Input),并且每次调用该层时,该层都会检查传递给它的规范是否符合其假设;如果不是这种情况,您将收到一条有用的错误消息。
这样可以确保您启动使用Functional API构建的任何模型。 所有调试(与收敛调试无关)将在模型构建过程中静态发生,而不是在运行时发生。 这类似于编译器中的类型检查。
您的功能模型可以用图形表示,也可以测试。
您可以以图形的形式绘制模型,并且可以轻松地访问图形的中间节点,例如,提取并重用中间层的激活,如我们在前面的示例中看到的:
features_list = [layer.output for layer in vgg19.layers] feat_extraction_model = keras.Model(inputs=vgg19.input, outputs=features_list)
由于Functional模型比一段代码更像是一种数据结构,因此可以安全地序列化它,并且可以将其保存为单个文件,从而使您无需访问源代码即可重新创建完全相同的模型。
功能性API弱点
它不支持动态架构。
Functional API将模型作为DAG层进行处理。 对于大多数深度学习架构而言,这都是正确的,但并非对所有人都适用:例如,递归网络或Tree RNN不满足此假设,因此无法在Functional API中实现。
有时,您只需要从头开始编写所有内容。
在编写高级体系结构时,您可能需要做一些超越“定义DAG层”的事情:例如,您可以在模型的实例上使用几种自定义训练和输出方法。 这需要子类化。
合并和合并各种API样式
重要的是要注意,在功能API或模型的子类之间进行选择不是将您限制为一类模型的二进制解决方案。
tf.keras API中的所有模型都可以相互交互,无论是顺序模型,功能模型还是从头开始编写的子类模型/层。您始终可以将功能模型或顺序模型用作子类模型/层的一部分: units = 32 timesteps = 10 input_dim = 5
, Layer Model Functional API
call :
call(self, inputs, **kwargs) inputs (. ),
**kwargs ( ).
call(self, inputs, training=None, **kwargs) training , .
call(self, inputs, mask=None, **kwargs) mask ( RNN, ).
call(self, inputs, training=None, mask=None, **kwargs) — .
另外,如果您在自定义图层或模型上实现`get_config`方法,则使用它创建的功能模型将被序列化和克隆。下面是一个小示例,其中我们使用从头编写的自定义RNN功能模型: units = 32 timesteps = 10 input_dim = 5 batch_size = 16 class CustomRNN(layers.Layer): def __init__(self): super(CustomRNN, self).__init__() self.units = units self.projection_1 = layers.Dense(units=units, activation='tanh') self.projection_2 = layers.Dense(units=units, activation='tanh') self.classifier = layers.Dense(1, activation='sigmoid') def call(self, inputs): outputs = [] state = tf.zeros(shape=(inputs.shape[0], self.units)) for t in range(inputs.shape[1]): x = inputs[:, t, :] h = self.projection_1(x) y = h + self.projection_2(state) state = y outputs.append(y) features = tf.stack(outputs, axis=1) return self.classifier(features)
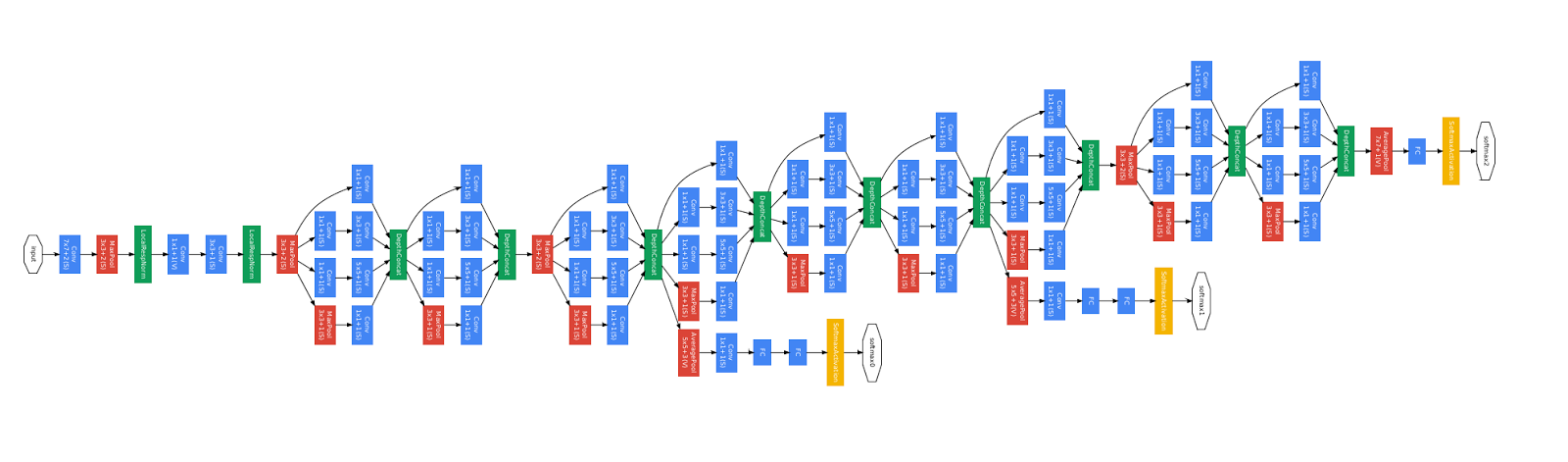
到此,我们的函数式API指南结束了!现在,您拥有了一套强大的工具来构建深度学习模型。经过验证后,翻译也将出现在Tensorflow.org上。 如果您想参与将Tensorflow.org网站的文档翻译成俄语,请以个人身份或评论联系。 任何更正或评论表示赞赏。 作为说明,我们使用了GoogLeNet模型的图像,它也是有向无环图。