高负载++莫斯科2018,大会堂。 11月9日,15:00
摘要和演讲:
http :
//www.highload.ru/moscow/2018/abstracts/4066Yuri Nasretdinov(VKontakte):该报告将讨论在我们公司中实施ClickHouse的经验-我们为什么需要它,我们需要存储多少数据,我们如何编写等等。

其他资源:
使用Clickhouse替代ELK,Big Query和TimescaleDB Yuri Nasretdinov: -大家好! 我的名字叫Yuri Nasretdinov,因为他们已经介绍了我。 我在VKontakte工作。 我将讨论如何将数据从服务器群(数万个)插入“ ClickHouse”。
什么是日志,为什么要收集它们?
我们将谈论的是:我们做了什么,为什么我们分别需要“ ClickHouse”-为什么选择它,无需专门配置就可以大致获得什么样的性能。 我将向您详细介绍缓冲表,它们所遇到的问题以及我们从开放源码KittenHouse和Lighthouse开发的解决方案。
为什么我们根本不需要做任何事情(在VKontakte上,一切都很好,对吗?)。 我们想收集调试日志(那里有数百TB的数据),也许以某种方式更方便地读取统计信息; 我们有成千上万的服务器,所有这些都需要完成。
我们为什么决定? 我们可能有用于存储日志的解决方案。 在这里-有一个这样的公共“后端VK”。 我强烈建议您订阅它。

什么是日志? 这是一个返回空数组的引擎。 “ VK”中的引擎被其他人称为微服务。 这样的贴纸在微笑(很多人喜欢)。 怎么会这样 好吧,听着!

一般而言,什么可以用来存储日志? 更不用说卡杜普了。 然后,例如,Rsyslog(存储在这些日志的文件中)。 迷幻药 谁知道什么是LSD? 不,不是这个LSD。 文件也分别存储。 好吧,ClickHouse是某种奇怪的版本。
Clickhouse和竞争对手:需求和机遇
我们想要什么? 我们希望我们不需要在操作时使用特殊的蒸汽浴,这样,它最好以最少的设置即开即用地工作。 我们想写很多,写得快。 我们希望将其保留数月,数年,即很长一段时间。 他们说,我们可能想解决他们遇到的某种问题,“这对我们来说不起作用”,但这是3个月前的事,我们希望能够在3个月前看到它”。 数据压缩-为什么会成为优势,这是可以理解的,因为占用的空间减少了。

我们有一个有趣的要求:有时我们写一些命令的输出(例如,日志),它的输出可能会非常平静地超过4 KB。 而且,如果该功能适用于UDP,则无需花费……连接不会有任何“开销”,对于大量服务器而言,这将是一个加号。

让我们看看开源为我们提供了什么。 首先,我们有一个日志引擎-这是我们的引擎; 他基本上什么都知道,即使排长队也可以写。 嗯,它不能透明地压缩数据-如果我们想...我们当然可以压缩大列,我们当然不愿意(如果可能)。 唯一的问题是他只能舍弃记忆中的东西。 其余的,为了阅读,您需要获取此引擎的binlog,因此,它需要花费相当长的时间。

还有哪些其他选择? 例如,卡杜普。 易于使用...谁相信Hadoup易于配置? 当然,有了录音,就没有问题了。 阅读时,有时会出现问题。 原则上,我会说不太可能,尤其是对于原木。 长期存储-当然,是的,数据压缩-是的,行很长-很明显,您可以编写。 但是要从大量服务器上进行记录...无论如何,我们必须自己做点什么!
Rsyslog。 实际上,我们将其用作备用,这样就可以在不进行转储的情况下读取binlog,但是它不能写入较长的行,原则上,它不能写入超过4 KB的字节。 数据压缩必须以相同的方式进行。 读取将来自文件。

然后是LSD的“坏”发展。 相同的事物本质上与“ Rsyslog”相同:它支持长行,但是它不知道如何使用UDP,事实上,由于这个原因,不幸的是,在那里有很多东西需要重写。 需要重做LSD,以便您可以从数以万计的服务器中进行记录。

哦,这! 一个有趣的选项是ElasticSearch。 好吧,怎么说呢? 阅读一切都很好,也就是说,他阅读速度很快,但是写作却不太好。 首先,如果它压缩数据,则它非常弱。 全面的搜索最有可能需要比原始卷更多的海量数据结构。 很难利用,经常会出现问题。 而且,再次进入“弹性”-我们所有人都必须自己做。

在这里,ClickHouse-当然是理想的选择。 唯一的问题是,从成千上万的服务器进行记录是一个问题。 但她至少是一名,我们可以尝试以某种方式解决。 报告的其余部分是关于这个问题的。 您可以期待ClickHouse的整体表现如何?
我们如何嵌入? 合并树
你们当中有多少人没有听说过ClickHouse,不知道吗? 需要说明,没有必要吗? 非常快 插入速度为每秒1-2吉比特,每秒高达10吉比特的突发实际上可以承受这种配置-有两个6核Xeon(即不是最强大的Xeon),256 GB的RAM,每兆20 TB RAID(没有配置,默认设置)。 ClickHouse的开发人员Alexey Milovidov可能会哭泣,因为我们没有配置任何东西(一切都对我们有用)。 因此,如果数据被很好地压缩,则可以获得例如每秒约60亿行的扫描速度。 如果您喜欢在文本行上执行%-每秒1亿行,那似乎非常快。

我们如何嵌入? 好吧,您知道在“ VK”中-在PHP中。 来自每个PHP工作者的我们将HTTP粘贴到“ ClickHouse”中,并粘贴到每个条目的MergeTree板中。 谁看到此电路中的问题? 由于某些原因,并非所有人都举手。 告诉你。
首先,有很多服务器-因此,会有很多连接(错误)。 然后,最好在MergeTree中每秒插入一次数据。 谁知道为什么呢? 好的很好 我会告诉你更多有关此的内容。 另一个有趣的问题是,我们过去并没有进行分析,我们不需要充实数据,我们不需要中间服务器,我们希望直接嵌入“ ClickHouse”中(最好是直的,更好的)。

因此,如何在MergeTree中实现插入? 为什么最好每秒插入一次或更短? 事实是,“ ClickHouse”是一列数据库,并按主键的升序对数据进行排序,并且在插入时,文件数至少由按主键的升序对数据进行排序的列数创建(创建了单独的目录,磁盘上每次插入的一组文件)。 然后进行下一个插入,并在后台将它们合并为更大的“分区”。 由于对数据进行了排序,因此您可以“处理”两个排序的文件,而不会占用大量内存。
但是,正如您想象的那样,如果每次插入写入10个文件,则“ ClickHouse”将很快结束(或您的服务器),因此建议插入大捆装。 因此,我们从未在生产中启动第一个方案。 我们立即在这里发布了编号为2的一款:

假设在这里启动了大约一千台服务器,而其中只有PHP。 在每台服务器上都有我们的本地代理,我们称为“ Kittenhouse”,它与“ ClickHouse”保持一个连接,每隔几秒钟插入一次数据。 它不会将数据插入MergeTree中,而是插入到后台打印程序表中,该表用于不立即将数据直接插入MergeTree中。
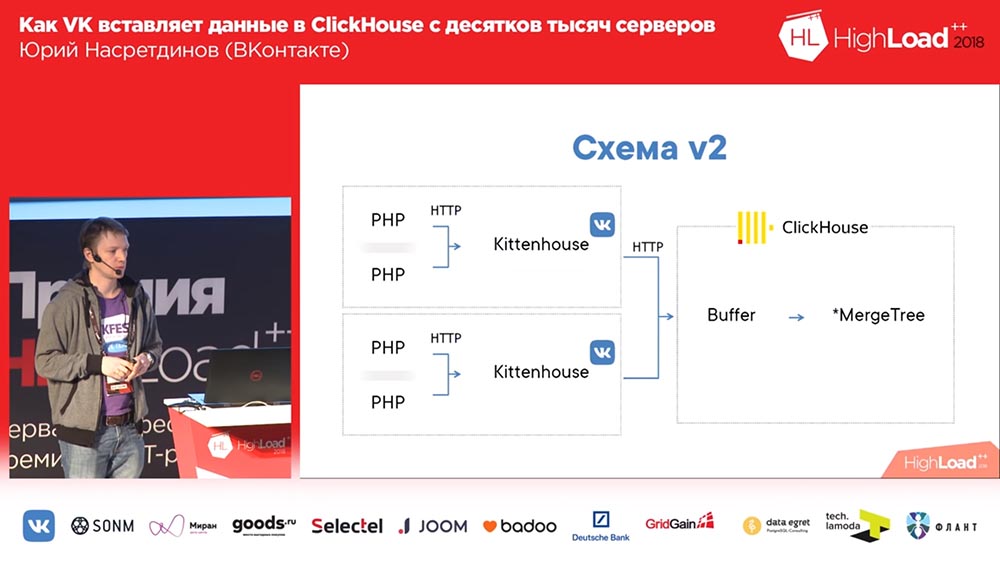
使用缓冲表
这是什么 缓冲区表是一块经过改组的内存(也就是说,您通常可以将其插入其中)。 它们由几部分组成,每个部分都作为一个独立的缓冲区工作,并且它们独立刷新(如果缓冲区中有很多块,那么每秒将有很多插入)。 您可以从这些表中读取数据,然后读取缓冲区和父表的内容的并集,但是此时记录被阻塞,因此最好不要从那里读取。 缓冲区表显示了非常好的QPS,也就是说,高达3000 QPS的插入将完全没有问题。 显然,如果服务器断电,则数据可能会丢失,因为它们仅存储在内存中。

同时,ALTER使带有缓冲区的方案变得复杂,因为您首先需要使用旧方案删除旧的缓冲区表(数据不会同时丢失,因为在删除表之前会刷新数据)。 然后,您“更改”所需的表并再次创建缓冲区表。 因此,虽然没有缓冲区表,但是数据不会在任何地方流动,但您甚至可以在磁盘上本地存储。

什么是Kittenhouse,它如何运作?
什么是KittenHouse? 这是一个代理。 猜猜是什么语言? 我在报告中收集了最多的炒作主题-Go,这是“ Clickhouse”,也许我还记得其他东西。 是的,它是用Go编写的,因为我真的不知道如何用C编写。

因此,它与每个服务器保持连接,可以写入内存。 例如,如果我们在“ Clickhouse”中写入错误日志,则“ Clickhouse”没有时间插入数据(毕竟,如果写入的数据太多),那么我们就不会从内存中膨胀-我们只是丢弃其余部分。 因为,如果我们每秒写入几个千兆字节的错误,那么可能会抛出一些。 小猫屋知道如何。 另外,它知道如何可靠地进行传递,即,它会写入本地计算机上的磁盘,并且偶尔(几秒钟一次)会尝试从该文件中传递数据。 首先,我们使用通常的“值”格式-而不是某些二进制格式,文本格式(如在常规SQL中一样)。

但是后来发生了。 我们使用了可靠的交付,编写了日志,然后决定(这是一个有条件的测试集群)……他们将其投入了几个小时,然后将其抬起,然后从数千台服务器开始插入-事实证明,Klickhouse仍然具有“ Thread on “连接”-因此,在一千个连接中,活动插入会导致服务器上的平均负载为一百零五。 令人惊讶的是,服务器接受了请求,但是仍然在一段时间后插入了这些数据。 但是服务器很难为其服务...
添加nginx
这种针对每个连接模型的线程的解决方案是nginx。 我们将nginx放在Clickhouse的前面,同时将平衡设置为两个副本(我们将插入速度提高了2倍,尽管事实并非如此),并限制了与Clickhouse,上游连接的数量,并因此限制了更多数量。比起50种化合物,插入似乎没有任何意义。

然后我们意识到这种方法通常都有缺点,因为这里只有一个Nginx。 因此,即使存在副本,如果此nginx放下,我们也会丢失数据,或者至少不在任何地方写入。 因此,我们进行了负载平衡。 我们还了解到,“ Clickhouse”仍然适用于日志,并且“守护程序”也开始在“ Clickhouse”中编写自己的日志-老实说,这非常方便。 我们仍将其用于其他“守护程序”。

然后他们发现了一个有趣的问题:如果您使用一种不太标准的方式以SQL模式插入,则将强制使用基于AST SQL的成熟语法分析器,这相当慢。 因此,我们添加了设置,以使这种情况永远不会发生。 我们进行了负载平衡,运行状况检查,以便即使有人死亡,我们仍然会保留数据。 我们已经有了足够的表格,因此我们需要具有不同的“ Clickhouse”集群。 我们开始考虑其他用途-例如,我们想从nginx模块编写日志,而它们无法使用RPC进行通信。 好吧,我想以某种方式教他们如何发送-例如,通过UDP在本地主机上接收事件,然后将其发送到“ Clickhouse”。
决策的第一步
最终方案开始看起来像这样(该方案的第四个版本):在Clickhouse前面的每台服务器上都有nginx(此外,在同一服务器上),它只是代理对本地主机的请求,连接数限制为50个。 现在,该方案已经在起作用,并且效果很好。

我们这样生活了大约一个月。 每个人都很高兴,添加表,添加,添加...总的来说,事实证明,我们添加缓冲区表的方式并不是很理想(可以这么说)。 我们在每张桌子中制作了16张作品,每隔几秒钟进行一次闪光间隔。 我们每个表有20个表,每秒有8个插入-那时“ Clickhouse”开始了……记录开始空白。 他们甚至都没有通过。默认情况下,Nginx发生了一件非常有趣的事情,即如果连接在上游终止,那么它只会为所有新请求提供“ 502”。

而在我们这里(我只是看了看我在“ Clickhouse”中的日志),大约有百分之五的请求失败了。 因此,磁盘利用率很高,有许多合并。 好吧,我做了什么? 自然,我并没有开始理解为什么连接和上游都将结束。
用反向代理替换Nginx
我决定我们需要自己进行管理,不要将其交给nginx-nginx不知道“ Clickhouse”中的表是什么,所以用反向代理替换了nginx,我也写了。
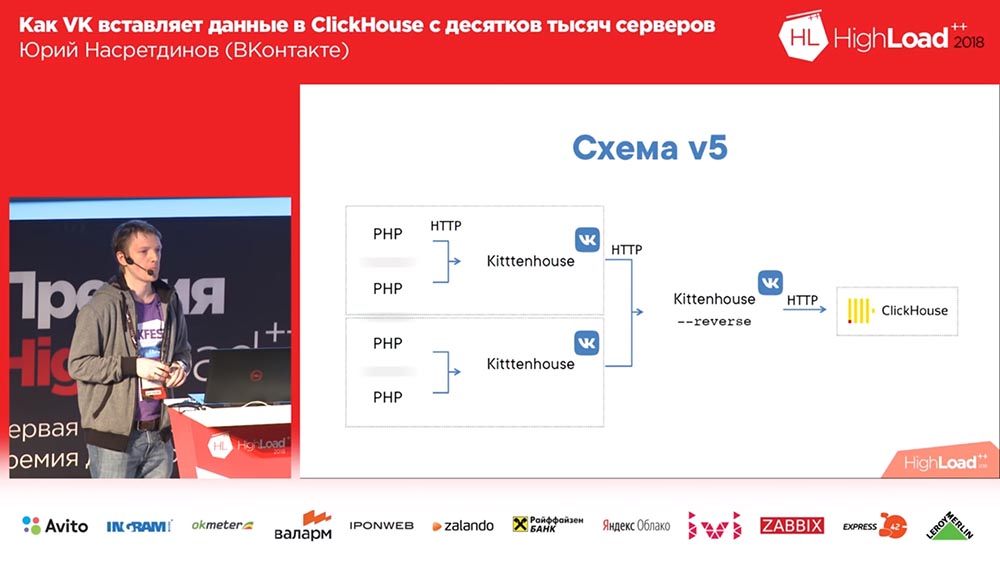
他在做什么? 它基于fasthttp库“ goosh”运行,即快速,几乎与nginx一样快。 抱歉,Igor,如果您在这里(请注意:Igor Sysoev是创建nginx Web服务器的俄罗斯程序员)。 他可以分别了解是哪种查询-INSERT或SELECT-他为不同类型的查询保留了不同的连接池。

因此,即使我们没有时间来完成请求,“选择”也会通过,反之亦然。 并将数据分组到缓冲区表中-带有一个较小的缓冲区:如果有任何错误,语法错误等,因此它们会稍微影响其余数据,因为当我们简单地插入缓冲区表时,我们会发现“ bachi”,语法错误的所有错误仅影响这一小部分; 在这里,它们将已经影响大缓冲区。 小是1兆字节,也就是说,不是那么小。

插入同步并本质上替换nginx基本上与nginx之前的操作相同-Kittenhouse无需为此进行本地更改。 而且由于它使用fasthttp,因此速度非常快-您可以通过反向代理每秒发出超过10万次的单个插入请求。 从理论上讲,您可以在“小猫屋”反向代理中插入一行,但是我们当然不能。

该方案开始看起来像这样:Kittenhouse,一个反向代理将许多请求分组到表中,然后,缓冲表将它们插入到主请求中。
杀手-临时解决方案,小猫-永久
有一个有趣的问题……你们中有人使用过fasthttp吗? 谁将fasthttp与POST请求一起使用? 实际上,这样做是不值得的,因为默认情况下它会缓冲请求正文,并且我们将缓冲区大小设置为16 MB。 某个时刻插入的时间不再及时了,从成千上万的服务器中开始出现16兆字节的数据块,并且所有这些数据块在被分配给Clickhouse之前都已缓冲在内存中。 因此,内存用完了,内存不足杀手出现了,杀死了反向代理(或“ Clickhouse”,从理论上讲,它比反向代理“吃”得更多)。 重复该循环。 这不是一个很好的问题。 尽管我们仅在运行几个月后才发现此问题。
我做了什么 再说一次,我真的不太想了解到底发生了什么。 在我看来,很明显不需要缓冲到内存中。 虽然尝试了,但我无法修补fasthttp。 但是我找到了一种制作方法,因此无需修补任何内容,并提出了自己的HTTP方法-称为KITTEN。 嗯,这是合乎逻辑的-“ VK”,“小猫”……还有什么?

如果使用Kitten方法向服务器发送请求,则服务器应在逻辑上回答“喵”。 如果他回答了这个问题,那么可以认为他理解了该协议,然后我拦截了该连接(fasthttp中有这种方法),并且该连接进入了“原始”模式。 我为什么需要这个? 我想控制如何从TCP连接读取。 TCP具有一个奇妙的属性:如果没有人从那一侧读取数据,则记录开始等待,而内存并没有专门用于此。
因此,我一次从50个客户那里读取内容(从50个客户那里读取,因为即使来自另一个DC,50个客户肯定也足够)...这种方法的消耗量至少减少了20倍,但是老实说,我无法精确测量多少,因为它已经毫无意义(它已经处于错误级别)。 该协议是二进制的,即有一个表名和数据; 没有http标头,因此我没有使用网络套接字(不需要与浏览器进行通信-我制定了适合我们需求的协议)。 和他在一起,一切都很好。
缓冲表难过
最近,我们遇到了缓冲区表的另一个有趣功能。 这个问题已经比其他问题痛苦得多。 : «», «», , (, 60 ); Alter … «», «», , «» – , - , «» . ? ?

, , , . , , , «» ( – , , ), … , «» ( - «» ) – , - : ( , ), «» , - , . , «», – .

(, ) – «» query_thread_log. , - . 840 (100 ). , (, , , ) «» (inserts). , «» – «» . , – , . 怎么了 , ! .

, ? «». .
«KitttenHouse»
, ? . ! : , , - . , .

, «», – , (, - ) , , – .

? . , , 10 , – -, , . , , , , – , «», 100 - – , , , . , . , .
, , . : , - , , , read only . ? . – - , - … ( , «», ClickHouse) ? ? , . . : , . , . .
. . , - ?.. «»? - … «»? , , . , . , .

– . , . , : , , ( ), – , .

Sequel Pro, «», . : «, -?» ? 2018-? , «» (MySQL) , «», ! «», – , .
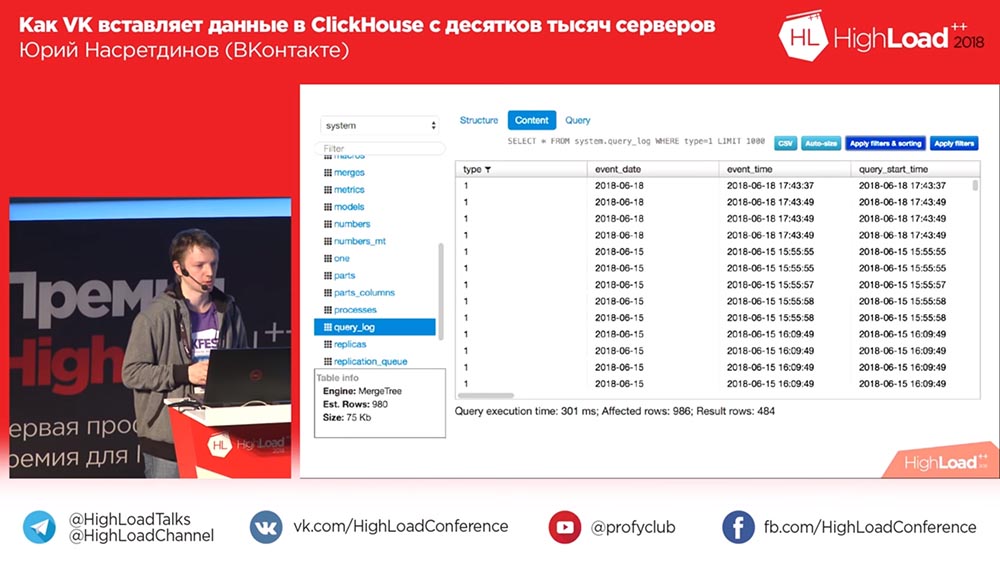
, , , , , , , , affected rows ( ), . .
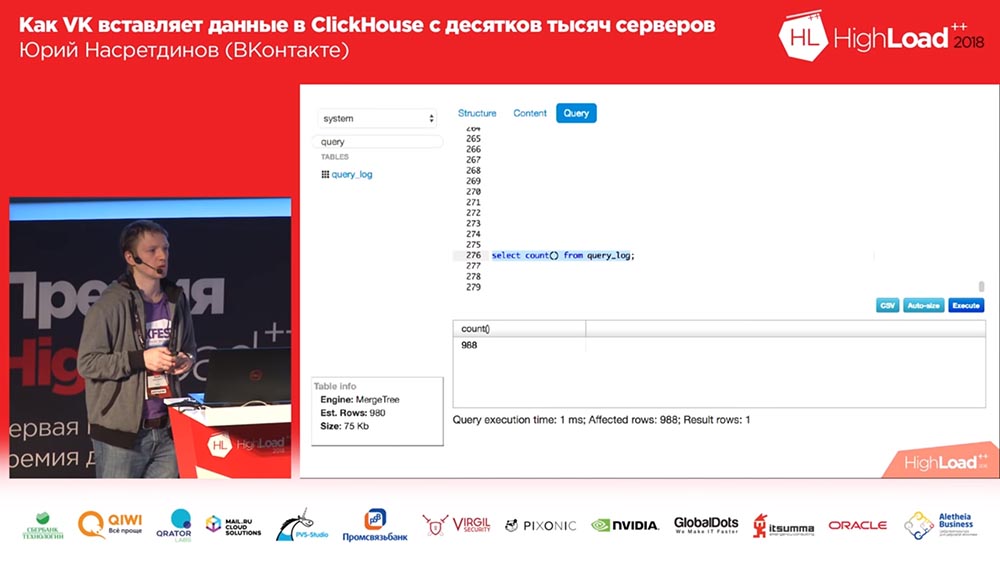
. «», . - - . .
«»
, «», , . , , – . , … , , .

TCP? , «» UDP. TCP… , , : «, ! , UDP». , TCP . , , – - ; , .
«» «» HighLoad Siberia, « »… , … , , . - , - , – , ( , , ).
. ! Github
. «» .
 :
: – , . , VHS.
( – ): – VHS, ?
 :“您也无法完全确定Clickhouse将如何工作!” 朋友们,有5分钟的提问时间!
:“您也无法完全确定Clickhouse将如何工作!” 朋友们,有5分钟的提问时间!问题
观众提问(以下简称-H): -下午好。 非常感谢您的报告。 我有两个问题。 我先轻描淡写一个:方案(3、4、7 ...)上“ Kittenhouse”名称中字母t的数量是否会影响猫的满意度?
联合国: -数量多少?
Z: -字母t。 有3吨,有3吨。
联合国: -我真的纠正过这个吗? 当然可以! 这些是不同的产品-我一直都在骗你。 好吧,我在开玩笑-事实并非如此。 啊,在这里! 不,是同一回事,我被封了。
 Z:
Z: -谢谢。 第二个问题很严重。 据我了解,在“ Clickhouse”中,缓冲区表仅存在于内存中,它们没有缓冲到磁盘,因此不是持久性的。
联合国: -是的。
Z: -同时,在客户端上对磁盘进行缓冲,这意味着可以保证这些相同日志的交付。 但是在Clickhouse,这不能保证。 解释由于什么原因如何执行保证...此机制更加详细
联合国: -是的,理论上没有矛盾,因为当“ Clickhouse”跌落时,您可以检测到现实中的一百万种不同方式。 如果“ Clickhouse”崩溃(如果未正确完成),则可以粗略地回顾一下您写下来的日志,然后从一切正常的时刻开始。 让我们在一分钟前倒回它,也就是说,据信它在一分钟内闪烁了所有内容。
Z: -也就是说,小猫屋将窗户保持更长的时间,如果跌倒,可以识别并放松窗户吗?
联合国: -但这是理论上的。 实际上,我们不这样做,可靠的交付是从零到无穷大的时间。 但平均一个。 我们感到满意的是,如果“ Clickhouse”由于某种原因崩溃或服务器“重新启动”,那么我们会损失一点。 在所有其他情况下,什么都不会发生。
Z: -你好 从一开始,在我看来,您从报告一开始就确实会使用UDP。 您拥有http等等所有内容……据我所知,您描述的大多数问题都是由该特定解决方案引起的……
联合国: -我们使用什么TCP?
Z: -实际上,是的。
联合国: -不。
Z: -正是因为fasthttp出现了问题,而连接却出现了问题。 如果仅使用UDP,则可以节省时间。 好吧,长消息或其他问题会出现问题...
联合国: -什么?
 Z:
Z: -对于长消息,由于它可能不适合MTU,所以还有其他问题。。。那可能会出现问题。 问题是:为什么不是UDP?
联合国: -我相信开发TCP / IP的作者比我聪明得多,并且知道如何更好地对数据包进行序列化(这样就可以了),同时调整发送窗口,不要使网络过载,并给出有关什么的反馈读取,而不是从另一侧进行计数...在我看来,所有这些问题也都在UDP中,只有这样我才能编写比自己已经编写的代码还要多的代码,以便自己实现相同的事情,而且很可能是不好的。 我什至不喜欢用C编写,不喜欢在那里...
Z: -方便! 发送正常,什么都不期望-您绝对异步。 回来了,一切都很好的通知-这意味着一切都已经到来了。 没有来-这意味着不好。
联合国: -我既需要又需要另一个-我需要能够在保证交货的情况下进行发送,而不必保证交货。 这是两种不同的方案。 有些日志我不需要丢失或在合理范围内不丢失。
Z: -我不会花时间。 应该对此进行更长时间的讨论。 谢谢啦
主持人: -谁有问题-天上的笔!
 Z:
Z: -嗨,我是Sasha。 报告中间的某处感觉到,除了TCP之外,还有可能使用现成的解决方案-一种“ Kafka”。
联合国: “嗯……我告诉过你我不想使用中间服务器,因为……对于卡夫卡来说,事实证明我们有一万台主机; 实际上,我们有更多-数以万计的主机。 如果使用Kafka,没有任何代理,也可能会造成伤害。 另外,最重要的是,它仍然提供“延迟”,并提供您需要的额外主机。 而且我不想拥有它们-我想要...
Z: -但最终结果还是。
联合国: -不,没有主人! 所有这些都可以在Clickhouse主机上使用。
Z: -但是小猫屋呢?相反,-他住在哪里?
 联合国:
联合国: -在Klickhouse主机上,他不向磁盘写入任何内容。
Z: -好,可以说。
主持人: -满意吗? 我们可以给薪水吗?
Z: -是的,是的。 实际上,为了得到相同的东西,有很多拐杖,而现在-在我看来,关于TCP主题的先前答案与这种情况相矛盾。 感觉就像您可以在更少的时间内完成所有事情。
联合国: -为什么我不想使用“ Kafka”,因为在Telegram的“ Clickhouse”电报中有很多投诉,例如,丢失了“ Kafka”的消息。 不是来自卡夫卡本身,而是来自卡夫卡和Klikhaus的融合; 或那里没有连接。 粗略地讲,那么Kafka的客户端就必须写了。 我认为不会获得更简单,更可靠的解决方案。
Z: -告诉我,你为什么不尝试一些线路或类似的公共巴士? 既然您说有可能与您异步地通过队列驱动日志本身,并以异步方式通过队列获取响应呢?
 联合国:
联合国: -请建议可以使用哪些队列?
Z: -任何,即使不能保证他们会按部就班。 任何Redis,RMQ ...
联合国: -我有一种感觉,即使在一台拉出Clickhouse的主机上(从几台服务器的意义上来说),Redis很可能也无法拉出这样的插入卷。 我无法提供任何证据来证实这一点(我没有对其进行基准测试),但在我看来,Redis并不是此处的最佳解决方案。 原则上,您可以将此系统视为即兴消息队列,但这仅适用于“ Clickhouse”
主持人: -尤里,非常感谢。 我建议在此结束问题和答案,并说问这个问题的人中的哪一部分会给我们一本书。
联合国: -我想把书给第一个提出问题的人。
主持人: -太好了! 太好了! 太好了! 非常感谢!
一点广告:)
感谢您与我们在一起。 你喜欢我们的文章吗? 想看更多有趣的资料吗? 通过下订单或向您的朋友推荐给
开发人员的基于云的VPS, 最低 价格为4.99美元 ,
这是我们为您发明的入门级服务器的
独特类似物: 关于VPS(KVM)E5-2697 v3(6核)的全部真相10GB DDR4 480GB SSD 1Gbps从$ 19还是如何划分服务器? (RAID1和RAID10提供选件,最多24个内核和最大40GB DDR4)。
阿姆斯特丹的Equinix Tier IV数据中心的戴尔R730xd便宜2倍吗? 仅
在荷兰,我们有
2台Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100电视 ! 戴尔R420-2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB-$ 99起! 阅读有关
如何构建基础架构大厦的信息。 使用价格为9000欧元的Dell R730xd E5-2650 v4服务器的上等课程?