引言
为什么您需要了解语义差异技术?
- 我们可以在消费者潜意识中找到关于竞争对手的位置。 在我们看来,客户对我们的产品不好,但是如果我们发现按照我们最相关的标准,他们对竞争对手的不利影响会怎样?
- 我们可以发现我们的广告在针对同一类别(使命召唤或战地?)竞争对手的广告方面取得了多大的成功
- 定义定位时要处理的内容。 公司或产品的形象是否被视为“便宜”? 显然,在进行新的广告活动时,我们要么不得不停留在消费者意识的这个角落(并忍受这种状态),要么紧急改变发展的方向。 小米被定位为具有相同硬件(有条件)的旗舰产品的廉价替代品。 它们的位置经过了明确校准,使其与将自己定位为昂贵的著名竞争对手(苹果,三星等)区分开来。 这种情况下的主要问题之一是,与“便宜”一词的关联(即,整个方法作为一个整体在此基础上建立)也可能吸引“不好”或“劣质”的关联。
顺便说一句,当比较所选类别中的任何其他对象时,此方法也适用-您可以比较处理器,电话和新闻门户! 实际上,应用这种方法的想象力不受限制。
如何确定应根据什么标准比较我们的产品?
原则上,可以通过不同方式回答此问题-您可以尝试进行专家访谈,半结构化访谈或选择焦点小组方法。 您收到的某些类别可能会在Internet上找到-这应该不会打扰您。 请记住,研究的主要内容不是获得的数据的唯一性,而是其客观性和可靠性。
还应该指出,在各种教科书中,我不止一次遇到类似的短语:“通常,不良与寒冷,黑暗,低落有关; 好-温暖,明亮,高。” 试想一下,如果雪碧在下一个广告“摆脱口渴”之后看到自己的饮料仍然与温暖的饮料有关?
这就是为什么值得关注我们所使用的确切工具的原因-如果对于一个主要目的是放松的应用程序,我们在关联系列中获得“平静”一词,那么我们根本不需要为射击者获得相同的特征。 在某种程度上,评估是该方法最主观的部分,但请不要忘记,评估最初是专注于处理可能因消费者而异的关联系列(这就是为什么另一个重要因素将是对目标受众进行研究的原因,该研究经常进行使用问卷调查方法或结构化访谈)。
方法论
即使在此阶段开始之前,我们也必须确定要测试的广告消息(在此示例中,我们将分析所有内容)。 在我们的情况下,它们将是以下手机的广告:


为了便于掌握该方法,我们请了两名受访者。
第一步是确定要研究的类别。
假设使用焦点小组方法,我们能够确定以下9个类别(该数字并非取自上限-最初只是将这么多的标准分为3个相等的组-评估因子(E),强度因子(P)和活动因子(A) ,建议确定作者):
- 令人兴奋的1 2 3 4 5 6 7
- Banal 1 2 3 4 5 6 7唯一
- 天然1 2 3 4 5 6 7人工
- 便宜的1 2 3 4 5 6 7亲爱的
- Creative 1 2 3 4 5 6 7 Banal
- 排斥1 2 3 4 5 6 7吸引
- 明亮1 2 3 4 5 6 7暗
- 脏1 2 3 4 5 6 7干净
- 占优1 2 3 4 5 6 7次
第二阶段是编制问卷。
在方法论上正确的,针对两个广告的两个受访者的问卷将如下所示:

如您所见,最小值和最大值取决于行。 根据此方法的创建者Charles Osgood的说法,此方法有助于检查受访者的注意力以及参与过程的程度(已注意到并已澄清-超级!)。 但是,某些研究人员(尤其是无良的研究人员)可能不会更改比例,以免以后再将其反转。 因此,他们跳过了我们列表中的第四项。
第三阶段是数据收集,将其输入我们的规模。
从现在开始,您既可以开始在Excel中处理数据(就像我为方便起见所做的那样),然后继续手动进行所有操作-取决于您决定轮询的人数(对我来说,Excel更加方便,但是数量很少受访者会更快地进行手动计算)。

第四阶段是恢复秤。
如果您决定采用“正确”的方法,现在您会发现应该将比例尺设为单个值。 在这种情况下,我决定最大值为“ 7”,最小值为“ 1”。 因此,即使列仍保持完整。 我们“恢复”剩余的值(我们反映出值-1 <=> 7,2 <=> 6,3 <=> 5,4 = 4)。
现在,我们的数据将以以下形式呈现:
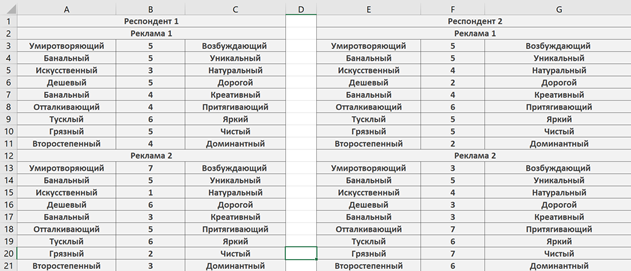
第五阶段是平均和一般指标的计算。
最受欢迎的指标是每个等级的“获胜者”(“最佳”)和每个等级的“失败者”(“最差”)。
我们通过标准的总和除以被调查者的数量获得每个品牌针对所选特征及其后续比较的所有商标。
重新调整后的每个广告的平均值:
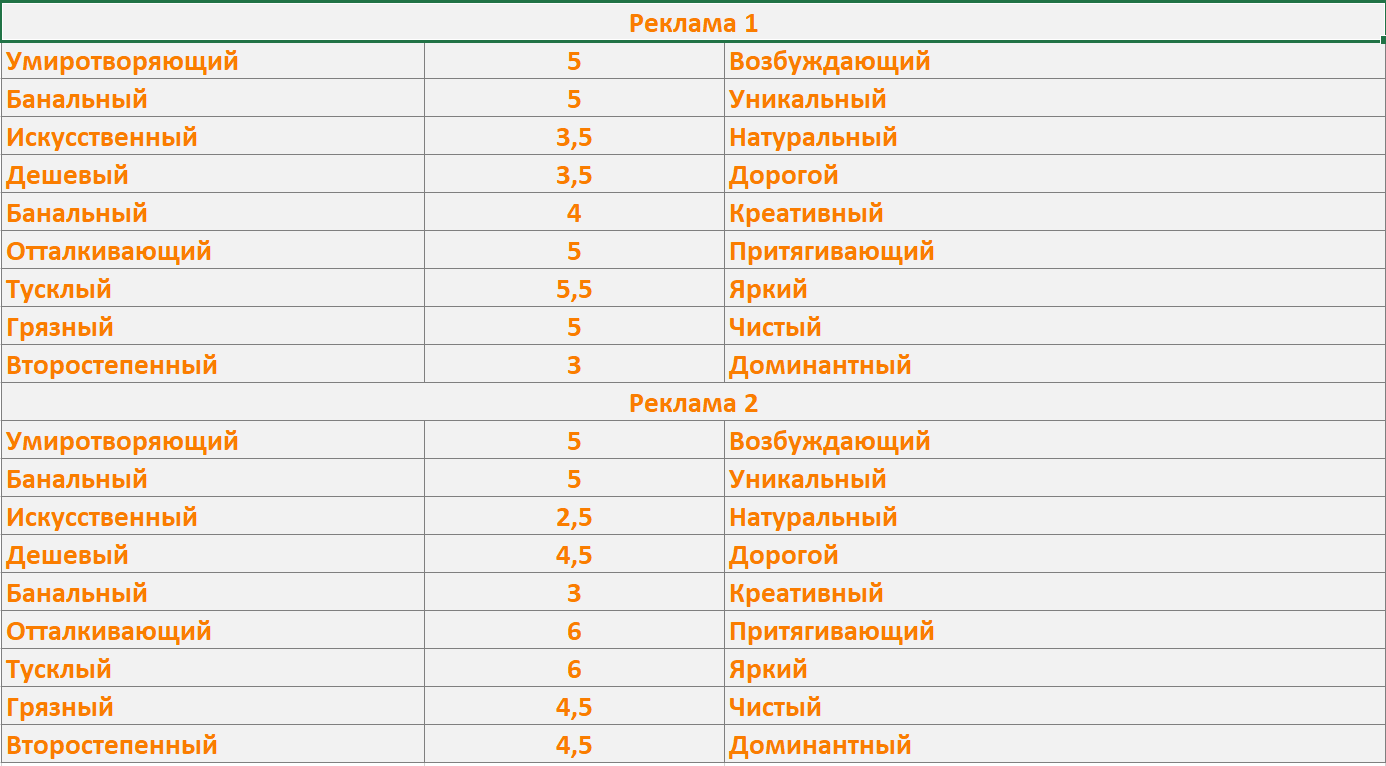
- 令人兴奋和安抚-相同的指标(5)。
- 平庸而独特-相同的指标(5)。
- 最自然-广告1。
- 最昂贵的是广告2。
- 最有创意的是广告1。
- 最吸引人-广告2。
- 最亮的是广告2。
- 最干净的是广告1。
- 最主要的是广告2。
现在我们转向广义指标。 在这种情况下,我们必须根据从所有受访者收到的所有特征的所有估计来总结每个品牌(我们的平均值在这里很有用)。 因此,我们定义了“绝对领导者”(可能有2个,甚至3个)。
总分-广告1(39.5分)。 广告2(41分)。
优胜者-广告2。
最主要的是,您清楚地意识到,差距不大的获胜者很容易被捕食。
第六阶段是感知图的构建。
从安格森(Angerson)和科学制表者入手科学之刻起,这是最让人接受的眼镜之一。 在进行报告时,正是他们的眼神更加清晰,与查尔斯(Charles)相比,查尔斯(Charles)还从更精确的科学和心理学中借鉴了这一观点。 它们有助于从视觉上向您确切反映您的品牌/广告/产品的位置。 通过为两个轴分配两个值来构造它们-例如,X轴将成为脏清洁标准的名称,而Y轴将变成暗淡的。
制作地图:
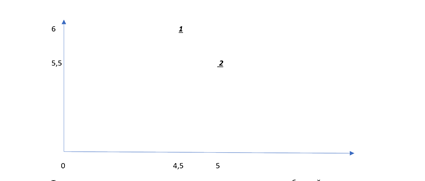
现在,我们可以清楚地看到代表着一家知名公司的两种商品在消费者心中的确切含义。
感知卡的主要优点是方便。 分析消费者的喜好和各种品牌的形象非常容易。 反过来,这对于创建有效的广告消息也非常重要。 用于在任何基础上评估产品的规模。
总结
如您所见,缩写方法并不难理解,它不仅可以被社会和市场研究方法领域的专家应用,而且可以被普通用户应用。