长期以来,许多人一直在积极地或积极地使用或寻找以
文档形式存储和发布
文档的模型,这意味着对文档使用与编程代码相同的规则,工具和过程,例如,将其存储在存储库中,运行测试,编译和发布。在CI / CD中。 这种方法使您可以使用熟悉的开发工具来使文档保持最新的代码,版本并跟踪更改。
但是,与此同时,许多公司也拥有维基百科,多年来,其他团队和员工(例如项目经理)可以访问文档。 如果您想将存储和发布放在一个视图中,即与Confluence中的HTML发布停靠站一起怎么办? 在本文中,我将概述从Confluence中的存储库发布文档的任务的解决方案。
我长期以来一直在界面开发团队中积极
使用一种解决方案(RST-Sphinx + sphinxcontribbuilder捆绑包),我将提出其他解决方案作为替代方案,我将立即提出保留意见,即实际上我没有尝试过,只是研究了配置。
Sphinx doc + sphinxcontribbuilder
Sphinx (不要与同名的搜索索引混淆)是一个用Python编写的文档生成器,并被社区积极使用;它在其他环境中也能很好地工作。
我们不会再详细设置它,我只是保留一点,即开箱即用,它可以生成静态HTML,man,pdf和许多其他格式,并且要在存储库中正确地进行组装和发布,必须有index.rst文件(主页布局), conf.py(配置文件)和Makefile(一个描述格式生成过程的文件,在这里很有可能将其缝入docker并在其中运行
sphinx-build命令)。
Sphinx可以立即使用轻量级的* .rst(RestructuredText)布局生成停靠栏,但我们为那些更舒适的开发人员添加了写入Markdown(CommonMark风格)的功能(将MD转换为RST的
m2r扩展帮助了我们) 。
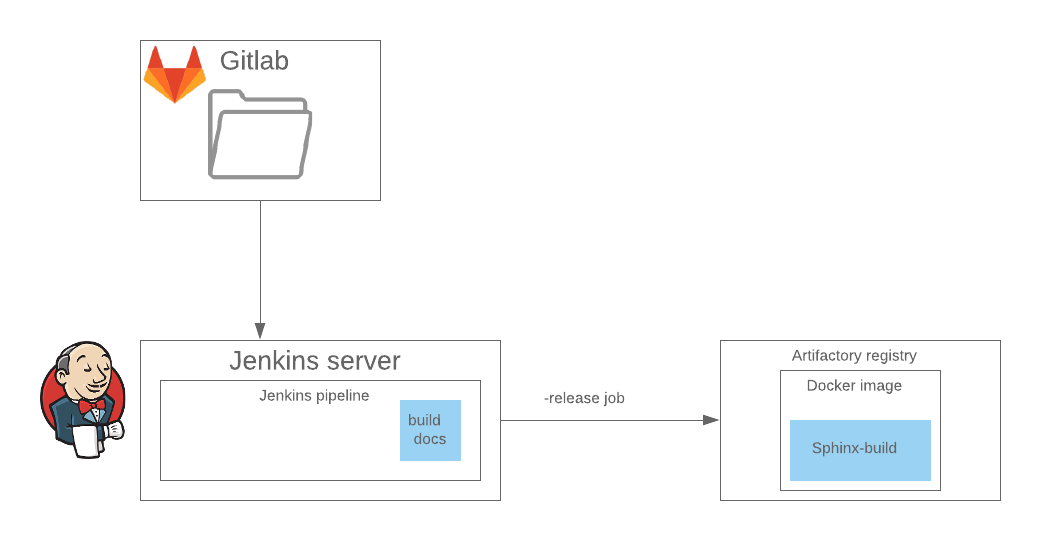
我们已经为Sphinx设置了整个环境,并且在Jenkins
管道中的单独阶段中缝合了文档程序集,因此我们继续使用
sphinxcontrib.confluencebuilder扩展程序,该扩展程序可以为Confluence收集本机格式的
扩展坞 ,然后发布它们。 在这种情况下,融合是HTML的文档输出格式之一。

为此,您需要在conf.py中连接扩展,以下是配置片段。
extensions = [ 'sphinxcontrib.confluencebuilder', 'm2r' ] templates_path = ['_templates'] source_suffix = ['.rst', '.md'] master_doc = 'index' exclude_patterns = [ u'docs/warning-plate.rst', u'FEATURE.md', u'CHANGELOG.md', u'builder/README.md' ]
然后配置扩展名,它具有一组设置:
confluence_publish = True
重要的一点是,即使未在toc中指定页面(.rst中的源),也未将其添加到exclude_patterns中,该页面仍将被发布,但位于层次结构之外。
Confluence中页面的名称将与页面的第一个标题相对应,例如,如果在example.rst文件中具有Example标头,并用等号加下划线,则它将成为Confluence中页面的名称。
卫生规则非常明显,但是仍然:创建一个具有授权数据的机器人,您将为其发布文档,这些文档可以作为环境变量在docker compose中进行传输,并在管道中使用。
当然,有陷阱。 首先,并非所有的RST语法都支持在Confluence(publication°□°)╯︵┻━┻中发布,如果要从一个来源收集HTML和Confluence,这是不便的。 不支持Container,hlist指令,几乎所有指令属性,例如,突出显示块代码中的行,目录中的编号,listtable的align和width。
支持的列表非常好 。
在令人愉快的支持中,包括在内,它使您可以重复使用不同文档之间的内容片段,自动doc从代码中汇编文档,数学公式用于数学公式,从jira绘制票证和过滤器(为此,您还需要在配置中注册Jira服务器),带编号的标头等等另一个,实际上是在1月3日进行了一次
重大更新 。
顺便说一下,从
2.7.3版开始,Pandoc便在Pandoc多转换器中提供了对Jira的支持,
Pandoc支持了相应的confluence Wiki标记。
对于不支持的那些宏和Confluence元素,有一个肮脏的hack。 RST有一个指令
... raw :: ,它有一个confluence属性,它接受conf标记,如果您确实需要某种宏-您可以在Confluence的页面编辑模式下复制它(源代码模式可以通过<>图标使用),并且将其“原始”代码粘贴到此处。 但是我没有教你这个
.. raw:: confluence <ac:structured-macro ac:macro-id="c38bab13-b51e-4129-85ef-737eab8a1c47" ac:name="status" ac:schema-version=^_^quot quot^_^> <ac:parameter ac:name="colour">Green</ac:parameter> <ac:parameter ac:name="title">Is used</ac:parameter> </ac:structured-macro>
结果如下:

为什么我们需要将发布配置从本地存储库配置到测试页,而不是立即配置为“ prod”? 事实是,当您发布所有页面时,每次都会重新发布它们,并研磨手动进行的更改或该行(内联)中的注释。 因此,在处理文档时,我们决定将其发布在单独的页面中,例如dev模式,以便将发布的版本添加到审阅并收集评论。
在CI中,发布是在Jenkins管道中的一个单独阶段中实现的,在此阶段中,将在远程注册表上启动docker映像,该远程注册表以所需的配置实现sphinx-build。 最好立即跳过此步骤。
pipeline { agent { label "${AGENT_LABEL}" } stage("Documentation") { steps { ansiColor('xterm') { withCredentials([usernamePassword( credentialsId: "${DOCUMENTATION_BOT}", usernameVariable: 'CONFLUENCE_USERNAME', passwordVariable: 'CONFLUENCE_PASSWORD' )]) { sh "docker-compose -p $COMPOSE_ID run sphinx-doc confluence" } }} }
在舞台内部,实际上启动了
docker-compose -p release-branch-name运行sphinx-doc confluence 。 Jenkinsfile依次描述了相关性和执行步骤所处的环境,以及在目标中组装和更新信息的过程。 到目前为止的测试中,仅使用doc8和markdownlinter对.md和.rst进行语法检查。
另一个细微差别:每次发布页面子网时,Sphinx都会更新整个树,即每个页面。 也就是说,即使内容没有更改,也会创建一个更改,如果您在通道中配置了通知,那么它将被很多通知所阻塞。
其他几种方法
以汇合为后端的叶子
带有Mkdocs的Foliant文档工具,以及以Confluence形式存在于后台和后端的许多预处理器。 您
可以在此处阅读更多内容 ,但简而言之,它使用pandoc将md转换为HTML,然后将其发布在Confluence中。 您只需要配置后端并在环境中将pandoc安装为依赖项。
与第一种解决方案的不同之处在于:它可以将内嵌注释还原到页面发布之前的相同位置,允许您通过在配置中设置它们来创建页面,编辑它们的名称以及将内容插入到现有页面中,为此您需要手动设置页面上的叶子锚点合流。
它仅适用于Markdown上的源。
地铁
一个多功能工具,可以在Confluence中发布各种源格式,从Google Docs到Salesforce Quip,以及在Markdown中。
要发布,您需要将manifest.json文件放在.md文件所在的文件夹中,在其中指定要发布的文件,并为每个文件指定汇合页面ID。 页面标题将是文件(#)中的第一个标题。 该工具带有Markdown标记的一些变型,因此请注意
底座 。 附件和图片需要放在同一文件夹中,该工具还允许您直接在配置中指定目录的使用。
宝石md2conf
Ruby gem
md2conf ,它将Markdown转换为Confluence XHTML的本机。 然后,您可以编写Rake任务,该任务又可以通过Gitlab CI / Jenkins调用以推送到master,然后拉出Confluence API来发布页面。 为了不给您带来Ruby环境,请将此gem的依赖项包装在容器中。
这里描述
了如何向Confluence API发送请求。
它仅适用于Markdown上的源。
从Github上找到
实际上,社区中已经完成了许多这样的脚本或cli工具,但是我只尝试了md2conf,它们都分为两组。
那些只转换格式的文件(md,asciidoc,rst-> confluence / xhtml):我见过的最周到的就是这个(https://github.com/rogerwelin/markdown2confluence-server),作者立即编写了Dockerfile,该文件将cli工具作为REST服务器,然后您可以向它发送一个转换请求包。
对于那些自己立即实现对Confluence API的请求的用户 ,只需在配置中指定API密钥:
选择任何选项(取决于您的标记语言和堆栈),并根据您面临的任务收集管道。
PS:如果您在评论中分享其他找到的解决问题的方法,我将不胜感激。
如果您想和我更多地谈论这些话题,请参加5月18日的KnowledgeConf 2020 。