敬礼,哈布罗夫斯克。 正如我们已经写的,一月份有很多新产品发布,今天我们宣布OTUS开设新课程的集合- “ Game Developer for Unity” 。 期待课程的开始,我们正在与您分享有趣的材料的翻译。

我们正在使用面向数据的技术堆栈重建Unity核心。 像许多游戏工作室一样,我们在使用实体组件系统(ECS),C#任务系统(C#作业系统)和Burst编译器方面也看到了巨大的优势。 在Unite Copenhagen,我们有机会与Far North Entertainment聊天,并研究了他们如何在传统Unity项目中实现此DOTS功能。
Far North Entertainment是一家瑞典工作室,由五个工程朋友共同拥有。 自2018年初发布Down to Dungeon for Gear VR以来,该公司一直在致力于开发属于PC游戏经典流派的游戏,即僵尸生存模式中的世界末日游戏。 使该项目与众不同的是追逐您的僵尸数量。 在这方面,团队的愿景吸引了成千上万饥饿的僵尸跟随您成群结队。
但是,它们很快在原型设计阶段就遇到了许多性能问题。 即使在团队尝试通过
倾斜合并和
硝化实例化解决问题之后,创建,垂死,更新和设置所有数量的敌人的动画仍然是主要瓶颈。
这迫使工作室的技术总监安德列斯·爱立信(Andres Ericsson)将注意力转向DOTS,并将思维方式从面向对象转变为面向数据。 他说:“促成这一转变的关键思想是,您必须停止思考对象和对象的层次结构,而开始考虑数据,如何转换数据以及如何访问数据,” 。 他的话意味着,不必以解决现实生活中最普遍和抽象的问题的方式构建关注现实生活对象的代码体系结构。 对于像他一样面临世界观变化的人们,他提供了许多技巧:
问自己,您要解决的真正问题是什么,什么数据对于解决方案很重要。 您会一次又一次地以相同的方式转换相同的数据集吗? 您可以在处理器高速缓存的一行中容纳多少有用的数据? 如果对现有代码进行更改,请评估添加到缓存行的垃圾数据量。 是否可以将计算分为几个线程,还是我需要使用单个命令流?”团队开始了解到Unity组件系统中的实体只是组件流中的搜索标识符。 组件只是数据,而系统包含所有逻辑并过滤出具有特定签名(称为原型)的实体。 “我认为帮助我们形象化想法的见解之一就是将ECS引入SQL数据库。 每个原型都是一个表,其中每一列都是一个组件,每一行都是唯一的实体。 本质上,您使用系统为这些原型表创建查询并在实体上执行操作,” Anders说。
介绍DOTS
为了达成这种理解,他研究了
实体组件系统的文档,
ECS示例以及我们与Nordeus一起在Unite Austin上展示
的示例 。 有关面向数据的体系结构的一般信息对团队也很有帮助。 “
Mike Acton关于CppCon 2014的以数据为中心的体系结构的
报告正是我们首先看到这种编程方式的。”
Far North团队在
开发博客上发布了他们所学到的知识,今年9月,他们来到哥本哈根,分享了他们向Unity中面向数据的方法过渡的经验。
本文基于一份报告,它更详细地解释了其ECS,C#任务系统和Burst编译器的实现细节。 远北公司也从他们的项目中分享了很多代码示例。
僵尸数据组织
“我们面临的问题是在客户端对数千个对象的位移和旋转进行插值,” Anders说。 他们最初的面向对象方法是创建一个继承了通用
EntityView父类的抽象
ZombieView脚本。
EntityView是附加到
GameObject的
MonoBehaviour 。 它充当游戏模型的可视化表示。 每个
ZombieView均负责在其
Update函数中处理自己的运动和旋转插值。
这听起来很正常,直到您了解每个实体在内存中的任意位置。 这意味着,如果要访问成千上万个对象,CPU必须一次将它们从内存中移出,而且发生的速度非常慢。 如果将数据放到按顺序排列的整齐的块中,则处理器可以同时缓存一堆数据。 大多数现代处理器可以在一个周期内从缓存中接收大约128或256位。
团队决定将敌人转换为DOTS,以期解决客户端性能问题。 第一个是
ZombieView中的
Update函数。 团队确定了应将哪些部分划分为不同的系统,并确定了必要的数据。 第一个也是最明显的事情是位置和转弯的插值,因为游戏世界是一个二维网格。 两个浮点变量负责僵尸的前进方向,最后一个组成部分是目标位置,它跟踪敌人的服务器位置。
[Serializable] public struct PositionData2D : IComponentData { public float2 Position; } [Serializable] public struct HeadingData2D : IComponentData { public float2 Heading; } [Serializable] public struct TargetPositionData : IComponentData { public float2 TargetPosition; }
下一步是为敌人创建原型。 原型是属于某个实体的一组组件的集合,换句话说,它是组件的签名。
该项目使用预制件来确定原型,因为敌人需要更多组件,并且其中一些需要指向
GameObject的链接。 这样可以使您可以将组件的数据包装在
ComponentDataProxy中 ,这会将其转换为
MonoBehaviour ,然后可以将其附加到预制件上。 当您使用
EntityManager创建实例并通过预制时,它会创建一个实体,其中包含附加到预制的组件的所有数据。 所有组件数据都存储在称为
ArchetypeChunk的 16 KB内存块中。
这是在原型块中如何组织组件流的可视化:
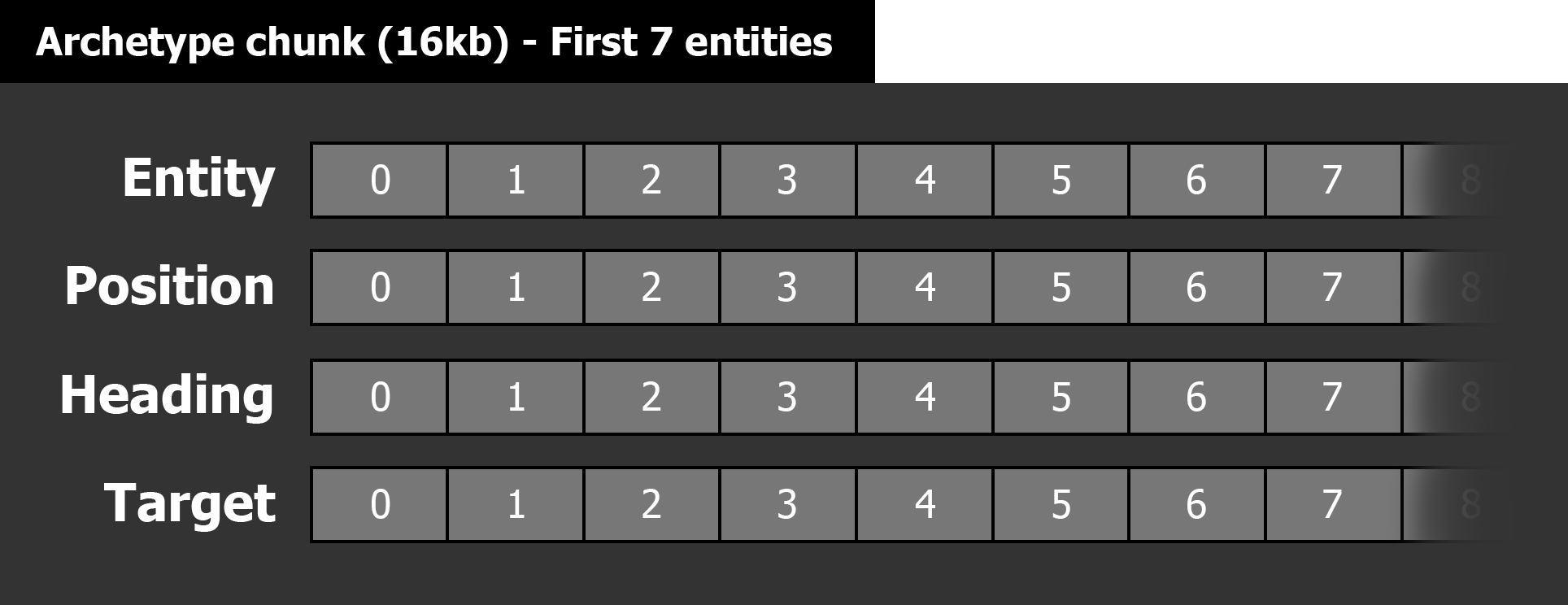 “原型块的主要优点之一是,在创建新对象时,您通常不需要重新分配束,因为已经预先分配了内存。 这意味着创建实体正在将数据写入原型块内部的组件流的末尾。 唯一需要再次执行堆分配的情况是在创建不适合块边界的实体时。 在这种情况下,将启动分配大小为16 KB的原型的新块,或者如果存在相同原型的空片段,则可以重新使用它。 然后,新对象的数据将记录在新块的组件流中
“原型块的主要优点之一是,在创建新对象时,您通常不需要重新分配束,因为已经预先分配了内存。 这意味着创建实体正在将数据写入原型块内部的组件流的末尾。 唯一需要再次执行堆分配的情况是在创建不适合块边界的实体时。 在这种情况下,将启动分配大小为16 KB的原型的新块,或者如果存在相同原型的空片段,则可以重新使用它。 然后,新对象的数据将记录在新块的组件流中 。
” Anders解释说。
僵尸的多线程
既然数据已经被密集打包并以一种方便的缓存方式存储在内存中,那么团队可以轻松地使用C#任务系统在多个CPU内核上并行运行其代码。
下一步是创建一个系统,该系统从具有
PositionData2D ,
HeadingData2D和
TargetPositionData组件的所有原型块中过滤掉所有实体。
为此,Anders和他的团队创建了
JobComponentSystem并在
OnCreate函数中构造了他们的请求。 看起来像这样:
private EntityQuery m_Group; protected override void OnCreate() { base.OnCreate(); var query = new EntityQueryDesc { All = new [] { ComponentType.ReadWrite<PositionData2D>(), ComponentType.ReadWrite<HeadingData2D>(), ComponentType.ReadOnly<TargetPositionData>() }, }; m_Group = GetEntityQuery(query); }
该代码宣布一个请求,该请求将筛选出世界上所有具有位置,方向和目的的对象。 接下来,他们希望使用C#任务系统为每个框架安排任务,以将计算分配到多个工作流程中。
“关于C#任务系统的最酷的事情是,它与Unity在其代码中使用的系统相同,因此我们不必担心可执行线程彼此阻塞,需要相同的处理器内核并导致性能问题。 “安德斯说。
团队决定使用
IJobChunk ,因为成千上万的敌人暗示存在大量原型块,这些原型块应在运行时与请求匹配。
IJobChunk在各种工作流程中分配正确的块。
每个帧都有一个新的
UpdatePositionAndHeadingJob任务
,负责处理游戏中敌人的位置和转弯的插值。
用于计划任务的代码如下:
protected override JobHandle OnUpdate(JobHandle inputDeps) { var positionDataType = GetArchetypeChunkComponentType<PositionData2D>(); var headingDataType = GetArchetypeChunkComponentType<HeadingData2D>(); var targetPositionDataType = GetArchetypeChunkComponentType<TargetPositionData>(true); var updatePosAndHeadingJob = new UpdatePositionAndHeadingJob { PositionDataType = positionDataType, HeadingDataType = headingDataType, TargetPositionDataType = targetPositionDataType, DeltaTime = Time.deltaTime, RotationLerpSpeed = 2.0f, MovementLerpSpeed = 4.0f, }; return updatePosAndHeadingJob.Schedule(m_Group, inputDeps); }
任务如下所示:
public struct UpdatePositionAndHeadingJob : IJobChunk { public ArchetypeChunkComponentType<PositionData2D> PositionDataType; public ArchetypeChunkComponentType<HeadingData2D> HeadingDataType; [ReadOnly] public ArchetypeChunkComponentType<TargetPositionData> TargetPositionDataType; [ReadOnly] public float DeltaTime; [ReadOnly] public float RotationLerpSpeed; [ReadOnly] public float MovementLerpSpeed; }
当工作线程从其队列中检索任务时,它将调用任务的核心。
这是执行核心的样子:
public void Execute(ArchetypeChunk chunk, int chunkIndex, int firstEntityIndex) { var chunkPositionData = chunk.GetNativeArray(PositionDataType); var chunkHeadingData = chunk.GetNativeArray(HeadingDataType); var chunkTargetPositionData = chunk.GetNativeArray(TargetPositionDataType); for (int i = 0; i < chunk.Count; i++) { var target = chunkTargetPositionData[i]; var positionData = chunkPositionData[i]; var headingData = chunkHeadingData[i]; float2 toTarget = target.TargetPosition - positionData.Position; float distance = math.length(toTarget); headingData.Heading = math.select( headingData.Heading, math.lerp(headingData.Heading, math.normalize(toTarget), math.mul(DeltaTime, RotationLerpSpeed)), distance > 0.008 ); positionData.Position = math.select( target.TargetPosition, math.lerp( positionData.Position, target.TargetPosition, math.mul(DeltaTime, MovementLerpSpeed)), distance <= 1 ); chunkPositionData[i] = positionData; chunkHeadingData[i] = headingData; } }
“您可能会注意到,我们使用select而不是分支,这使我们摆脱了称为错误分支预测的影响。 select函数将评估两个表达式并选择一个与条件匹配的表达式,如果您的表达式不是那么难计算,我建议您使用select,因为它通常比等待CPU从不正确的分支预测中恢复要便宜。安德斯
爆裂提高生产力
将DOTS转换为敌人位置和路线插值的最后一步是启用Burst编译器。 对于安德斯来说,任务似乎非常简单:“由于数据位于相邻的数组中,并且由于我们使用Unity的新数学库,因此我们要做的就是向任务添加
BurstCompile属性。”
[BurstCompile] public struct UpdatePositionAndHeadingJob : IJobChunk { public ArchetypeChunkComponentType<PositionData2D> PositionDataType; public ArchetypeChunkComponentType<HeadingData2D> HeadingDataType; [ReadOnly] public ArchetypeChunkComponentType<TargetPositionData> TargetPositionDataType; [ReadOnly] public float DeltaTime; [ReadOnly] public float RotationLerpSpeed; [ReadOnly] public float MovementLerpSpeed; }
Burst编译器为我们提供了单指令多数据(SIMD); 可以处理多组输入数据并仅用一条指令创建多组输出数据的机器指令。 这有助于我们用正确的数据填充128位高速缓存总线上的更多位置。 Burst编译器与友好的缓存数据组合和作业系统相结合,使团队可以大大提高生产率。 这是他们通过评估每个转换步骤后的性能而编制的表。

这意味着Far North完全摆脱了与客户端位置和僵尸方向插值有关的问题。 现在,它们的数据以方便缓存的形式存储,并且缓存行仅填充有用的数据。 负载分配到所有CPU内核,并且Burst编译器使用SIMD指令生成高度优化的机器代码。
远北娱乐点的技巧和窍门
- 开始考虑数据流方面的问题,因为在ECS中,实体只是并行组件数据流中的搜索索引。
- 将ECS想象成一个关系数据库,其中原型是表,组件是列,实体是表(行)中的索引。
- 将数据组织成顺序的阵列,以使用处理器缓存和硬件预取。
- 在了解您要解决的实际问题之前,不必创建对象的层次结构并尝试找到通用的解决方案。
- 考虑垃圾收集。 避免在性能至关重要的区域中过度分配堆。 请改用新的本机Unity容器。 但是要小心,您必须处理手动清洁。
- 认识到抽象的价值,请注意调用虚拟函数的开销。
- 将所有CPU内核与C#任务系统一起使用。
- 分析硬件级别。 Burst编译器是否实际生成SIMD指令? 使用“爆发检查器”进行分析。
- 停止浪费缓存行为空。 将数据打包到高速缓存行中就像将数据打包到UDP数据包中。
对于那些已经在开发项目的人,Anders Ericsson希望分享的主要建议是:
“尝试确定游戏中存在性能问题的特定区域,并查看是否可以在以下方面专门应用DOTS:这个孤立的区域。 您无需更改整个代码库!”未来计划
“我们想在游戏的其他领域中使用DOTS,我们对Unite上关于DOTS动画,Unity Physics和Live Link的公告感到高兴。 我们想学习如何将更多游戏对象转换为ECS对象,并且看来Unity在实现这一目标方面取得了重大进展,”安德斯总结道。
如果您对远北团队还有其他疑问,建议您加入他们的
Discord !
查看
Unite Copenhagen DOTS播放列表,了解其他现代游戏工作室如何使用DOTS来创建出色的高性能游戏,以及基于DOTS的组件(如DOTS Physics,新的Conversion Workflow和Burst编译器)如何协同工作。
翻译已经结束,我们
邀请您参加免费的网络研讨会 ,其中将告诉您如何在一个小时内创建自己的僵尸射击游戏 。