这甚至不是在开玩笑,似乎这张特定的图片最准确地反映了这些数据库的本质,最后将清楚为什么:

根据DB-Engines排名,两个最受欢迎的NoSQL列基础是Cassandra(以下简称CS)和HBase(HB)。
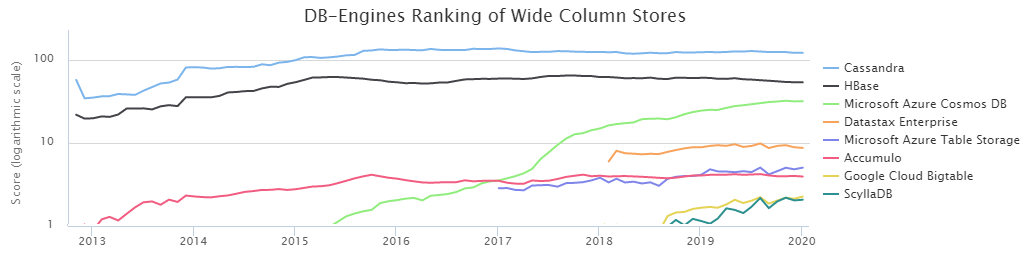
依照命运的意愿,我们位于Sberbank的数据加载管理团队与HB
长期合作密切。 在这段时间里,我们很好地研究了它的优缺点,并学会了如何烹饪。 但是,一直以来,以CS形式出现的替代方案使我感到疑惑:我们是否做出了正确的选择? 此外,DataStax进行的
比较结果表明,CS几乎可以击碎得分,轻松击败HB。 另一方面,DataStax是一个有兴趣的人,您不要在这里说什么。 而且,关于测试条件的相当少的信息令人尴尬,因此我们决定独立找出谁是BigData NoSql的王者,结果非常有趣。
但是,在继续进行测试的结果之前,有必要描述环境配置的基本方面。 事实是CS可以在数据丢失容忍模式下使用。 即 这是当只有一个服务器(节点)负责某个键的数据时,如果由于某种原因它掉线了,则该键的值将丢失。 对于许多任务而言,这并不重要,但对于银行业而言,这是例外而不是规则。 在我们的案例中,重要的是要拥有多个数据副本以进行可靠的存储。
因此,仅考虑三重复制的CS模式,即。 用以下参数创建案例:
CREATE KEYSPACE ks WITH REPLICATION = {'class' : 'NetworkTopologyStrategy', 'datacenter1' : 3};
此外,有两种方法可以确保所需的一致性。 一般规则:
NW + NR>射频
这意味着写入时来自节点的确认数(NW)加上读取时来自节点的确认数(NR)必须大于复制因子。 在我们的情况下,RF = 3,因此以下选项适用:
2 + 2> 3
3 +1> 3
由于对我们而言,保持数据尽可能可靠至关重要,因此选择了3 + 1方案。 此外,HB在类似的基础上工作,即 这样的比较会更诚实。
应当指出,DataStax在他们的研究中做的是相反的,他们为CS和HB都设置了RF = 1(对于后者,通过更改HDFS设置)。 这是一个非常重要的方面,因为在这种情况下,对CS性能的影响很大。 例如,下图显示了将数据加载到CS中所需的时间增加:
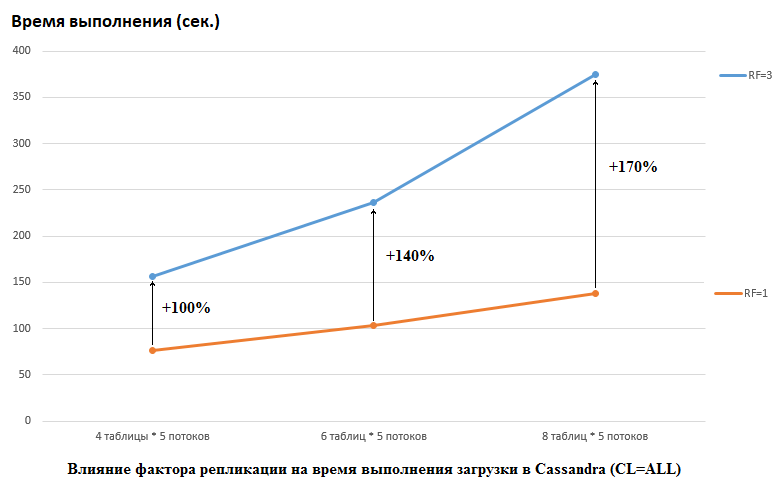
在这里,我们看到以下内容,竞争越多的线程写入数据,花费的时间越长。 这是自然的,但重要的是RF = 3的性能下降要高得多。 换句话说,如果我们在5个流中的每个流中写入4个表(总计20个),则RF = 3损失大约2倍(150秒RF = 3,而RF = 1则为75)。 但是,如果我们通过将数据加载到5个流中的每个流中的8个表中来增加负载(总计40个),那么丢失RF = 3已经是2.7倍(375秒对138秒)。
这也许部分是成功进行CS负载测试的DataStax测试的秘密,因为对于我们公司的HB而言,将复制因子从2更改为3无效。 即 对于我们的配置,光盘不是HB的瓶颈。 但是,还有许多其他陷阱,因为应该注意,我们的HB版本略有打补丁和模糊不清,环境完全不同,等等。 还要指出的是,也许我只是不知道如何正确准备CS,并且有一些更有效的处理方式,希望我能在评论中找到答案。 但是首先是第一件事。
所有测试都是在由4个服务器组成的铁群集上执行的,每个服务器都具有以下配置:
CPU:Xeon E5-2680 v4 @ 2.40GHz 64线程
磁盘:12个SATA HDD
Java版本:1.8.0_111
CS版本:3.11.5
参数cassandra.ymlnum_tokens:256
hinted_handoff_enabled:是
hinted_handoff_throttle_in_kb:1024
max_hints_delivery_threads:2
hints_directory:/ data10 / cassandra /提示
hints_flush_period_in_ms:10000
max_hints_file_size_in_mb:128
batchlog_replay_throttle_in_kb:1024
身份验证器:AllowAllAuthenticator
授权者:AllowAllAuthorizer
角色管理器:CassandraRoleManager
role_validity_in_ms:2000
Permissions_validity_in_ms:2000
certificate_validity_in_ms:2000
分区程序:org.apache.cassandra.dht.Murmur3Partitioner
data_file_directories:
-/ data1 / cassandra / data#每个dataN目录是一个单独的驱动器
-/ data2 / cassandra /数据
-/ data3 / cassandra /数据
-/ data4 /卡桑德拉/数据
-/ data5 / cassandra /数据
-/ data6 / cassandra /数据
-/ data7 /卡桑德拉/数据
-/ data8 / cassandra /数据
commitlog_directory:/ data9 / cassandra / commitlog
cdc_enabled:否
disk_failure_policy:停止
commit_failure_policy:停止
prepare_statements_cache_size_mb:
thrift_prepared_statements_cache_size_mb:
key_cache_size_in_mb:
key_cache_save_period:14400
row_cache_size_in_mb:0
row_cache_save_period:0
counter_cache_size_in_mb:
counter_cache_save_period:7200
saved_caches_directory:/ data10 / cassandra / saved_caches
commitlog_sync:定期
commitlog_sync_period_in_ms:10000
commitlog_segment_size_in_mb:32
seed_provider:
-类别名称:org.apache.cassandra.locator.SimpleSeedProvider
参数:
-种子:“ *,*”
parallel_reads:256#已尝试64-未发现差异
parallel_writes:256#已尝试64-未发现差异
parallel_counter_writes:256#已尝试64-未发现差异
parallel_materialized_view_writes:32
memtable_heap_space_in_mb:2048#尝试了16 GB-速度较慢
memtable_allocation_type:heap_buffers
index_summary_capacity_in_mb:
index_summary_resize_interval_in_minutes:60
tickle_fsync:否
rickle_fsync_interval_in_kb:10240
storage_port:7000
ssl_storage_port:7001
listen_address:*
broadcast_address:*
listen_on_broadcast_address:为true
internode_authenticator:org.apache.cassandra.auth.AllowAllInternodeAuthenticator
start_native_transport:正确
native_transport_port:9042
start_rpc:是
rpc_address:*
rpc_port:9160
rpc_keepalive:正确
rpc_server_type:同步
thrift_framed_transport_size_in_mb:15
增量备份:false
snapshot_before_compaction:否
auto_snapshot:为true
column_index_size_in_kb:64
column_index_cache_size_in_kb:2
parallel_compactors:4个
compaction_throughput_mb_per_sec:1600
sstable_preemptive_open_interval_in_mb:50
read_request_timeout_in_ms:100000
range_request_timeout_in_ms:200000
write_request_timeout_in_ms:40000
counter_write_request_timeout_in_ms:100000
cas_contention_timeout_in_ms:20000
truncate_request_timeout_in_ms:60000
request_timeout_in_ms:200000
slow_query_log_timeout_in_ms:500
cross_node_timeout:否
endpoint_snitch:GossipingPropertyFileSnitch
dynamic_snitch_update_interval_in_ms:100
dynamic_snitch_reset_interval_in_ms:600000
dynamic_snitch_badness_threshold:0.1
request_scheduler:org.apache.cassandra.scheduler.NoScheduler
server_encryption_options:
internode_encryption:无
client_encryption_options:
启用:false
internode_compression:直流
inter_dc_tcp_nodelay:假
tracetype_query_ttl:86400
tracetype_repair_ttl:604800
enable_user_defined_functions:否
enable_scripted_user_defined_functions:否
windows_timer_interval:1
transparent_data_encryption_options:
启用:false
tombstone_warn_threshold:1000
tombstone_failure_threshold:100000
batch_size_warn_threshold_in_kb:200
batch_size_fail_threshold_in_kb:250
unlogged_batch_across_partitions_warn_threshold:10
compaction_large_partition_warning_threshold_mb:100
gc_warn_threshold_in_ms:1000
back_pressure_enabled:否
enable_materialized_views:true
enable_sasi_indexes:是
GC设置:
### CMS设置-XX:+ UseParNewGC
-XX:+ UseConcMarkSweepGC
-XX:+ CMSParallelRemarkEnabled
-XX:SurvivorRatio = 8
-XX:MaxTenuringThreshold = 1
-XX:CMSInitiatingOccupancyFraction = 75
-XX:+仅使用CMSInitiatingOccupancy
-XX:CMSWaitDuration = 10000
-XX:+ CMSParallelInitialMarkEnabled
-XX:+ CMSEdenChunksRecordAlways
-XX:+ CMSClassUnloadingEnabled
内存jvm.options分配了16 Gb(仍尝试32 Gb,未发现差异)。
创建表是通过以下命令执行的:
CREATE TABLE ks.t1 (id bigint PRIMARY KEY, title text) WITH compression = {'sstable_compression': 'LZ4Compressor', 'chunk_length_kb': 64};
HB版本:1.2.0-cdh5.14.2(在org.apache.hadoop.hbase.regionserver.HRegion类中,我们排除了MetricsRegion,它导致RegionServer上具有1000多个区域的GC)
非默认HBase选项zookeeper.session.timeout:120000
hbase.rpc.timeout:2分钟(秒)
hbase.client.scanner.timeout.period:2分钟(秒)
hbase.master.handler.count:10
hbase.regionserver.lease.period,hbase.client.scanner.timeout.period:2分钟
hbase.regionserver.handler.count:160
hbase.regionserver.metahandler.count:30
hbase.regionserver.logroll.period:4小时
hbase.regionserver.maxlogs:200
hbase.hregion.memstore.flush.size:1 GiB
hbase.hregion.memstore.block.multiplier:6
hbase.hstore.compactionThreshold:5
hbase.hstore.blockingStoreFiles:200
hbase.hregion.majorcompaction:1天(s)
用于hbase-site.xml的HBase服务高级配置代码段(安全阀):
hbase.regionserver.wal.codecorg.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec
hbase.master.namespace.init.timeout3600000
hbase.regionserver.optionalcacheflushinterval18000000
hbase.regionserver.thread.compaction.large12
hbase.regionserver.wal.enablecompressiontrue
hbase.hstore.compaction.max.size1073741824
hbase.server.compactchecker.interval.multiplier200
HBase RegionServer的Java配置选项:
-XX:+ UseParNewGC -XX:+ UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction = 70 -XX:+ CMSParallelRemarkEnabled -XX:ReservedCodeCacheSize = 256m
hbase.snapshot.master.timeoutMillis:2分钟(秒)
hbase.snapshot.region.timeout:2分钟(秒)
hbase.snapshot.master.timeout.millis:2分钟(秒)
HBase REST Server最大日志大小:100 MiB
HBase REST Server最大日志文件备份:5
HBase Thrift Server最大日志大小:100 MiB
HBase Thrift Server的最大日志文件备份数:5
主最大日志大小:100 MiB
主最大日志文件备份:5
RegionServer最大日志大小:100 MiB
RegionServer日志文件最大备份数:5
HBase Active Master检测窗口:4分钟
dfs.client.hedged.read.threadpool.size:40
dfs.client.hedged.read.threshold.millis:10毫秒
hbase.rest.threads.min:8
hbase.rest.threads.max:150
最大进程文件描述符:180,000
hbase.thrift.minWorkerThreads:200
hbase.master.executor.openregion.threads:30
hbase.master.executor.closeregion.threads:30
hbase.master.executor.serverops.threads:60
hbase.regionserver.thread.compaction.small:6
hbase.ipc.server.read.threadpool.size:20
区域移动线程:6
客户端Java堆大小(以字节为单位):1 GiB
HBase REST Server默认组:3 GiB
HBase Thrift Server默认组:3 GiB
HBase主站的Java堆大小(以字节为单位):16 GiB
HBase RegionServer的Java堆大小(以字节为单位):32 GiB
+ ZooKeeper
maxClientCnxns:601
maxSessionTimeout:120000
创建表:
hbase org.apache.hadoop.hbase.util.RegionSplitter ns:t1 UniformSplit -c 64 -f cf
alter'ns:t1',{NAME =>'cf',DATA_BLOCK_ENCODING =>'FAST_DIFF',COMPRESSION =>'GZ'}有一点很重要-DataStax描述没有说明创建HB表使用了多少个区域,尽管这对于大容量至关重要。 因此,对于测试,选择了数字= 64,这可以存储多达640 GB的数据,即 中型桌子。
在测试时,HBase有22,000个表和67,000个区域(如果没有上述补丁,这对于1.2.0版将是致命的)。
现在获取代码。 由于尚不清楚哪种配置对特定数据库更有利,因此以各种组合方式进行了测试。 即 在某些测试中,负载同时传递到4个表(所有4个节点都用于连接)。 在其他测试中,他们使用8个不同的表。 在某些情况下,批处理大小为100,在其他情况下为200(批处理参数-请参见下面的代码)。 值的数据大小为10字节或100字节(dataSize)。 在每个表中,总共写入并减去500万条记录。 同时,向每个表中写入/读取了5个流(流号为thNum),每个流都使用自己的键范围(计数= 1百万):
if (opType.equals("insert")) { for (Long key = count * thNum; key < count * (thNum + 1); key += 0) { StringBuilder sb = new StringBuilder("BEGIN BATCH "); for (int i = 0; i < batch; i++) { String value = RandomStringUtils.random(dataSize, true, true); sb.append("INSERT INTO ") .append(tableName) .append("(id, title) ") .append("VALUES (") .append(key) .append(", '") .append(value) .append("');"); key++; } sb.append("APPLY BATCH;"); final String query = sb.toString(); session.execute(query); } } else { for (Long key = count * thNum; key < count * (thNum + 1); key += 0) { StringBuilder sb = new StringBuilder("SELECT * FROM ").append(tableName).append(" WHERE id IN ("); for (int i = 0; i < batch; i++) { sb = sb.append(key); if (i+1 < batch) sb.append(","); key++; } sb = sb.append(");"); final String query = sb.toString(); ResultSet rs = session.execute(query); } }
因此,为HB提供了类似的功能:
Configuration conf = getConf(); HTable table = new HTable(conf, keyspace + ":" + tableName); table.setAutoFlush(false, false); List<Get> lGet = new ArrayList<>(); List<Put> lPut = new ArrayList<>(); byte[] cf = Bytes.toBytes("cf"); byte[] qf = Bytes.toBytes("value"); if (opType.equals("insert")) { for (Long key = count * thNum; key < count * (thNum + 1); key += 0) { lPut.clear(); for (int i = 0; i < batch; i++) { Put p = new Put(makeHbaseRowKey(key)); String value = RandomStringUtils.random(dataSize, true, true); p.addColumn(cf, qf, value.getBytes()); lPut.add(p); key++; } table.put(lPut); table.flushCommits(); } } else { for (Long key = count * thNum; key < count * (thNum + 1); key += 0) { lGet.clear(); for (int i = 0; i < batch; i++) { Get g = new Get(makeHbaseRowKey(key)); lGet.add(g); key++; } Result[] rs = table.get(lGet); } }
由于客户端必须注意HB中数据的均匀分布,因此关键的盐腌功能如下所示:
public static byte[] makeHbaseRowKey(long key) { byte[] nonSaltedRowKey = Bytes.toBytes(key); CRC32 crc32 = new CRC32(); crc32.update(nonSaltedRowKey); long crc32Value = crc32.getValue(); byte[] salt = Arrays.copyOfRange(Bytes.toBytes(crc32Value), 5, 7); return ArrayUtils.addAll(salt, nonSaltedRowKey); }
现在最有趣的是结果:

与图相同:
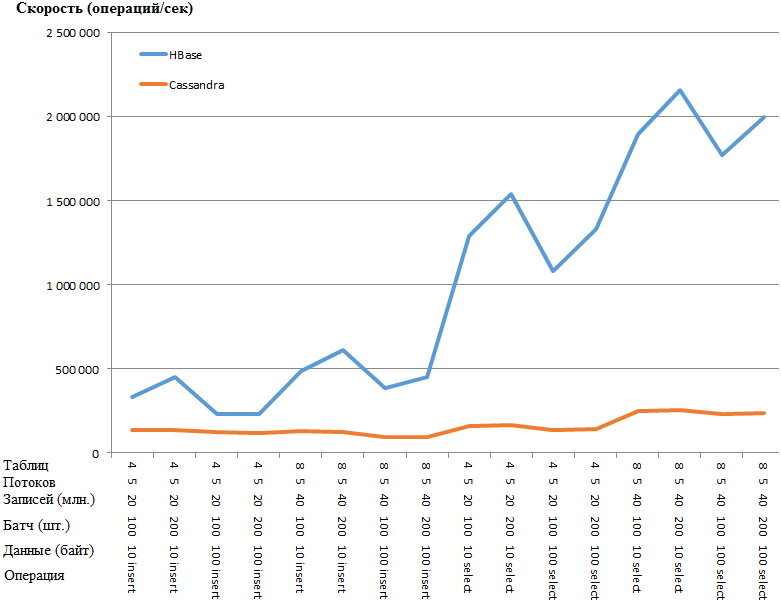
HB的优势是如此惊人,以至于CS设置中存在某种瓶颈。 但是,最明显参数的谷歌搜索和扭曲(例如parallel_writes或memtable_heap_space_in_mb)没有提供加速。 同时,原木是干净的,不要发誓。
数据均匀分布在节点之间,来自所有节点的统计信息大致相同。
这是带有节点之一的表的统计信息键空间:ks
读数:9383707
读取延迟:0.04287025042448576 ms
写数:15462012
写入延迟:0.1350068438699957 ms
等待冲洗:0
表:t1
SSTable数量:16
使用的空间(实时):148.59 MiB
已使用空间(总计):148.59 MiB
快照使用的空间(总计):0字节
使用的堆外内存(总计):5.17 MiB
SSTable压缩比:0.5720989576459437
分区数(估计):3970323
记忆细胞计数:0
Memtable资料大小:0个位元组
已使用的表外堆内存:0个字节
内存开关数:5
本地读取计数:2346045
本地读取延迟:NaN ms
本地写计数:3865503
本地写入延迟:NaN ms
等待冲洗:0
修复百分比:0.0
布隆过滤器误报:25
布隆过滤器错误率:0.00000
使用的Bloom筛选器空间:4.57 MiB
布隆过滤器使用的堆内存:4.57 MiB
所用堆内存的索引摘要:590.02 KiB
使用的堆内存压缩元数据:19.45 KiB
压缩分区的最小字节数:36
压缩分区的最大字节数:42
压缩分区的平均字节数:42
每片平均活细胞数(最近五分钟):NaN
每片最大活细胞数(最近五分钟):0
每片平均墓碑(最近五分钟):NaN
每片最大墓碑数(最近五分钟):0
删除的变异:0个字节
尝试减小批次的大小(直到一个接一个地发送)没有效果,只会变得更糟。 实际上,这实际上可能是CS的最高性能,因为在CS上获得的结果与从DataStax获得的结果相似-每秒约数十万次操作。 此外,如果查看资源利用率,您会发现CS使用更多的CPU和磁盘:
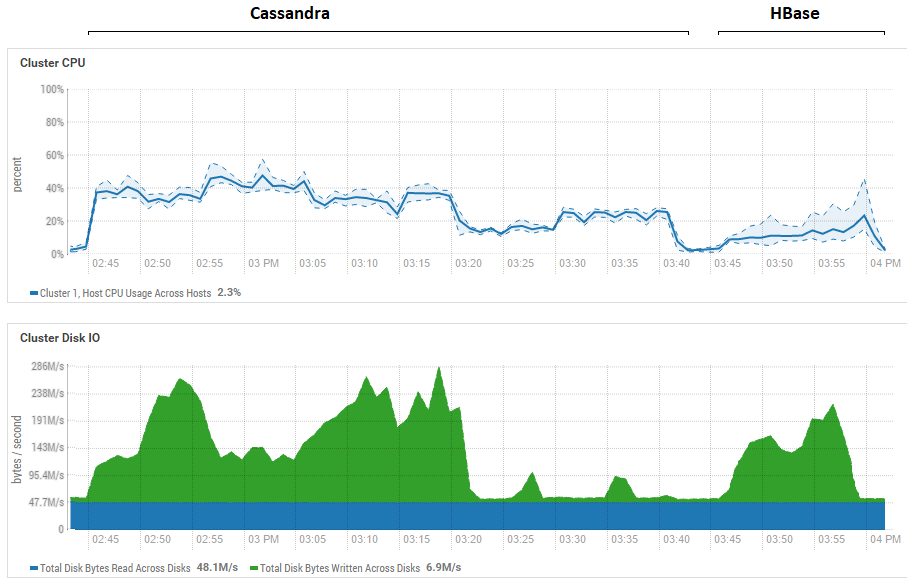 该图连续显示两个数据库在运行所有测试期间的利用率。
该图连续显示两个数据库在运行所有测试期间的利用率。关于HB的强大阅读优势。 可以看出,对于这两个数据库,读取期间的磁盘利用率都非常低(读取测试是每个数据库测试周期的最后一部分,例如,对于15:20到15:40的CS)。 对于HB,原因很明显-大多数数据都挂在内存中的memstore中,而某些数据则缓存在blockcache中。 至于CS,尚不清楚其工作原理,但是,磁盘利用率也不可见,但以防万一,试图打开row_cache_size_in_mb = 2048缓存并设置caching = {'keys':'ALL','rows_per_partition':' 2,000,000'},但情况更糟。
同样值得一提的是关于HB区域数目的重要观点。 在本例中,显示的值为64,如果将其减小并使其等于例如4,则读取速度下降2倍。 原因是memstore将更快地阻塞并且文件将更频繁地刷新,并且在读取时将需要处理更多文件,这对于HB来说是相当复杂的操作。 在实际条件下,可以通过考虑预植入和压缩的策略来解决,特别是,我们使用自制的实用程序来收集垃圾并在后台不断压缩HFiles。 对于DataStax测试,通常可能为每个表分配1个区域(这是不正确的),这将在某种程度上澄清为什么HB在其读取测试中损失这么多。
由此得出的初步结论如下。 假设在测试过程中没有发生重大错误,Cassandra就像一块巨大的粘土脚。 更准确地说,当她在一条腿上保持平衡时(如本文开头的图片中所示),她显示出相对较好的成绩,但是当她在相同条件下进行战斗时,她将完全输掉比赛。 同时,考虑到硬件的CPU使用率低,我们学会了在每个主机上安装两个RegionServer HB,从而使生产率提高了一倍。 即 考虑到资源利用率,CS的情况甚至更糟。
当然,这些测试是综合的,此处使用的数据量相对较少。 切换到TB时,情况可能会有所不同,但是如果对于HB我们可以加载TB,那么对于CS来说,这是有问题的。 即使与这些卷相比,它也经常引发OperationTimedOutException,尽管响应期望参数已经比默认参数增加了数倍。
我希望通过共同努力,我们将发现CS瓶颈,如果我们设法加快它的速度,那么我一定会在帖子末尾添加有关最终结果的信息。
UPD:以下准则适用于CS设置:
disk_optimization_strategy:旋转
MAX_HEAP_SIZE =“ 32G”
HEAP_NEWSIZE =“ 3200M”
-Xms32G
-Xmx32G
-XX:+ UseG1GC
-XX:G1RSetUpdatingPauseTimePercent = 5
-XX:MaxGCPauseMillis = 500
-XX:InitiatingHeapOccupancyPercent = 70
-XX:ParallelGCThreads = 32
-XX:ConcGCThreads = 8至于操作系统设置,这是一个相当长且复杂的过程(获取root,重新启动服务器等),因此未应用这些建议。 另一方面,两个数据库处于相同条件下,因此一切都是公平的。
在代码部分,为写入表的所有线程建立了一个连接器:
connector = new CassandraConnector(); connector.connect(node, null, CL); session = connector.getSession(); session.getCluster().getConfiguration().getSocketOptions().setConnectTimeoutMillis(120000); KeyspaceRepository sr = new KeyspaceRepository(session); sr.useKeyspace(keyspace); prepared = session.prepare("insert into " + tableName + " (id, title) values (?, ?)");
数据是通过绑定发送的:
for (Long key = count * thNum; key < count * (thNum + 1); key++) { String value = RandomStringUtils.random(dataSize, true, true); session.execute(prepared.bind(key, value)); }
这对录制性能没有重大影响。 为了提高可靠性,我使用YCSB工具启动了加载,结果完全相同。 以下是一个线程(4个线程中)的统计信息:
2020-01-18 14:41:53:180315秒:10,000,000次操作; 21589.1当前操作/秒; [清理:计数= 100,最大值= 2236415,最小值= 1,平均= 22356.39,90 = 4,99 = 24,99.9 = 2236415,99.99 = 2236415] [插入:计数= 119551,最大值= 174463,最小值= 273,平均= 2582.71,90 = 3491,99 = 16767,99.9 = 99711,99.99 = 171263]
[OVERALL],运行时间(毫秒),315539
[总体],吞吐量(运营/秒),31691.803548848162
[TOTAL_GCS_PS_Scavenge],计数,161
[TOTAL_GC_TIME_PS_Scavenge],时间(毫秒),2433
[TOTAL_GC_TIME _%_ PS_Scavenge],时间(%),0.7710615803434757
[TOTAL_GCS_PS_MarkSweep],计数,0
[TOTAL_GC_TIME_PS_MarkSweep],时间(毫秒),0
[TOTAL_GC_TIME _%_ PS_MarkSweep],时间(%),0.0
[TOTAL_GCs],计数,161
[TOTAL_GC_TIME],时间(毫秒),2433
[TOTAL_GC_TIME_%],时间(%),0.7710615803434757
[INSERT],运营,10,000,000
[INSERT],AverageLatency(美国),3114.2427012
[INSERT],MinLatency(美国),269
[INSERT],MaxLatency(美国),609279
[INSERT],95thPercentileLatency(美国),5007
[INSERT],99thPercentileLatency(美国),33439
[INSERT],返回= OK,10000000
在这里,您可以看到一个流的速度约为每秒32,000个记录,工作了4个流,结果为12.8万。似乎没有什么可以挤出当前的磁盘子系统设置了。
关于阅读更有趣。 多亏了同志的建议,他才得以从根本上加速前进。 读取不是在5个流中进行的,而是在100个流中进行的。增加到200个不会产生效果。 还添加到构建器中:
.withLoadBalancingPolicy(新的TokenAwarePolicy(DCAwareRoundRobinPolicy.builder()。build()))
结果,如果较早的测试显示159644个操作(5个流,4个表,100个批处理),则现在:
100个线程,4个表,批处理= 1(单独):301969个操作
100个线程,4个表,批处理= 10:447608操作
100个线程,4个表,批处理= 100:625655个操作
由于批处理的结果更好,因此我对HB进行了类似的*测试:
 *由于在400个线程中工作时,较早使用的RandomStringUtils函数将CPU加载了100%,因此它被更快的生成器所取代。
*由于在400个线程中工作时,较早使用的RandomStringUtils函数将CPU加载了100%,因此它被更快的生成器所取代。因此,加载数据时线程数的增加会使HB性能有所提高。
至于阅读,这是几种选择的结果。 应
0x62ash的请求,在读取之前已执行了flush命令,并且还提供了其他几个选项进行比较:
Memstore-从内存读取,即 在刷新到磁盘之前。
HFile + zip-从GZ算法压缩的文件中读取。
HFile + upzip-无需压缩即可读取文件。
一个有趣的功能是值得注意的-小文件(请参见“数据”字段,其中写入了10个字节)的处理速度较慢,尤其是在压缩时。 显然,这只有在达到一定大小后才可能实现,显然一个5 GB的文件将不会以超过10 MB的速度处理,但是它清楚地表明,在所有这些测试中,仍然没有犁various的领域来研究各种配置。
出于兴趣,我更正了YCSB代码,以处理100件HB批次以测量延迟等。 以下是写入表的4个副本的工作结果,每个副本具有100个线程。 结果是:
一次操作= 100条记录[OVERALL],运行时间(ms),1165415
[总体],吞吐量(操作数/秒),858.06343662987
[TOTAL_GCS_PS_Scavenge],计数,798
[TOTAL_GC_TIME_PS_Scavenge],时间(毫秒),7346
[TOTAL_GC_TIME _%_ PS_Scavenge],时间(%),0.6303334005483026
[TOTAL_GCS_PS_MarkSweep],计数,1
[TOTAL_GC_TIME_PS_MarkSweep],时间(毫秒),74
[TOTAL_GC_TIME _%_ PS_MarkSweep],时间(%),0.006349669431061038
[TOTAL_GCs],计数,799
[TOTAL_GC_TIME],时间(毫秒),7420
[TOTAL_GC_TIME_%],时间(%),0.6366830699793635
[INSERT],运营,1,000,000
[INSERT],AverageLatency(美国),115893.891644
[插入],MinLatency(美国),14528
[INSERT],MaxLatency(美国),1470463
[INSERT],95thPercentileLatency(美国),248319
[插入],99thPercentileLatency(美国),445951
[插入],返回= OK,1,000,000
19/01/20 13:19:16 INFO client.ConnectionManager $ HConnectionImplementation:关闭zookeeper会话ID = 0x36f98ad0a4ad8cc
19/01/20 13:19:16信息zookeeper.ZooKeeper:会话:0x36f98ad0a4ad8cc已关闭
19/01/20 13:19:16信息zookeeper.ClientCnxn:EventThread关闭
[OVERALL],运行时间(毫秒),1165806
[总体],吞吐量(操作数/秒),857.7756504941646
[TOTAL_GCS_PS_Scavenge],计数,776
[TOTAL_GC_TIME_PS_Scavenge],时间(毫秒),7517
[TOTAL_GC_TIME _%_ PS_Scavenge],时间(%),0.6447899564764635
[TOTAL_GCS_PS_MarkSweep],计数,1
[TOTAL_GC_TIME_PS_MarkSweep],时间(毫秒),63
[TOTAL_GC_TIME _%_ PS_MarkSweep],时间(%),0.005403986598113236
[TOTAL_GCs],计数,777
[TOTAL_GC_TIME],时间(毫秒),7580
[TOTAL_GC_TIME_%],时间(%),0.6501939430745767
[INSERT],运营,1,000,000
[INSERT],AverageLatency(美国),116042.207936
[插入],MinLatency(美国),14056
[INSERT],MaxLatency(美国),1462271
[INSERT],95thPercentileLatency(美国),250239
[插入],99thPercentileLatency(美国),446719
[插入],返回= OK,1,000,000
19/01/20 13:19:16 INFO client.ConnectionManager $ HConnectionImplementation:关闭zookeeper会话ID = 0x26f98ad07b6d67e
19/01/20 13:19:16 INFO zookeeper.ZooKeeper:会话:0x26f98ad07b6d67e关闭
19/01/20 13:19:16信息zookeeper.ClientCnxn:EventThread关闭
[OVERALL],运行时间(毫秒),1165999
[总体],吞吐量(运营/秒),857.63366863951
[TOTAL_GCS_PS_Scavenge],计数,818
[TOTAL_GC_TIME_PS_Scavenge], Time(ms), 7557
[TOTAL_GC_TIME_%_PS_Scavenge], Time(%), 0.6481137633908777
[TOTAL_GCS_PS_MarkSweep], Count, 1
[TOTAL_GC_TIME_PS_MarkSweep], Time(ms), 79
[TOTAL_GC_TIME_%_PS_MarkSweep], Time(%), 0.006775305982252128
[TOTAL_GCs], Count, 819
[TOTAL_GC_TIME], Time(ms), 7636
[TOTAL_GC_TIME_%], Time(%), 0.6548890693731299
[INSERT], Operations, 1000000
[INSERT], AverageLatency(us), 116172.212864
[INSERT], MinLatency(us), 7952
[INSERT], MaxLatency(us), 1458175
[INSERT], 95thPercentileLatency(us), 250879
[INSERT], 99thPercentileLatency(us), 446463
[INSERT], Return=OK, 1000000
20/01/19 13:19:17 INFO client.ConnectionManager$HConnectionImplementation: Closing zookeeper sessionid=0x36f98ad0a4ad8cd
20/01/19 13:19:17 INFO zookeeper.ZooKeeper: Session: 0x36f98ad0a4ad8cd closed
20/01/19 13:19:17 INFO zookeeper.ClientCnxn: EventThread shut down
[OVERALL], RunTime(ms), 1166860
[OVERALL], Throughput(ops/sec), 857.000839860823
[TOTAL_GCS_PS_Scavenge], Count, 707
[TOTAL_GC_TIME_PS_Scavenge], Time(ms), 7239
[TOTAL_GC_TIME_%_PS_Scavenge], Time(%), 0.6203829079752499
[TOTAL_GCS_PS_MarkSweep], Count, 1
[TOTAL_GC_TIME_PS_MarkSweep], Time(ms), 67
[TOTAL_GC_TIME_%_PS_MarkSweep], Time(%), 0.0057419056270675145
[TOTAL_GCs], Count, 708
[TOTAL_GC_TIME], Time(ms), 7306
[TOTAL_GC_TIME_%], Time(%), 0.6261248136023173
[INSERT], Operations, 1000000
[INSERT], AverageLatency(us), 116230.849308
[INSERT], MinLatency(us), 7352
[INSERT], MaxLatency(us), 1443839
[INSERT], 95thPercentileLatency(us), 250623
[INSERT], 99thPercentileLatency(us), 447487
[INSERT], Return=OK, 1000000
, CS AverageLatency(us) 3114, HB AverageLatency(us) = 1162 (, 1 = 100 ).
— HBase. , SSD . , , , 4 , 400 , . : — . . ScyllaDB , …