很长时间以来,我一直在写有关numba以及将其速度与si进行比较的文章。 Haskell文章“ 比C ++快; 比PHP慢 ”。 在本文的评论中,他们提到了numba库,它可以神奇地将python中的代码执行速度近似为s中的速度。 在本文中,对numba进行了简短回顾(第1部分),然后对此情况进行了更为详细的分析( 第2部分 )。

python的主要缺点被认为是它的速度。 超频python几乎从其诞生的第一天就开始了: 皮 , psyco , 空的浅层 , 长尾小鹦鹉 , theano , nuitka , pythran , cython , pypy , numba 。
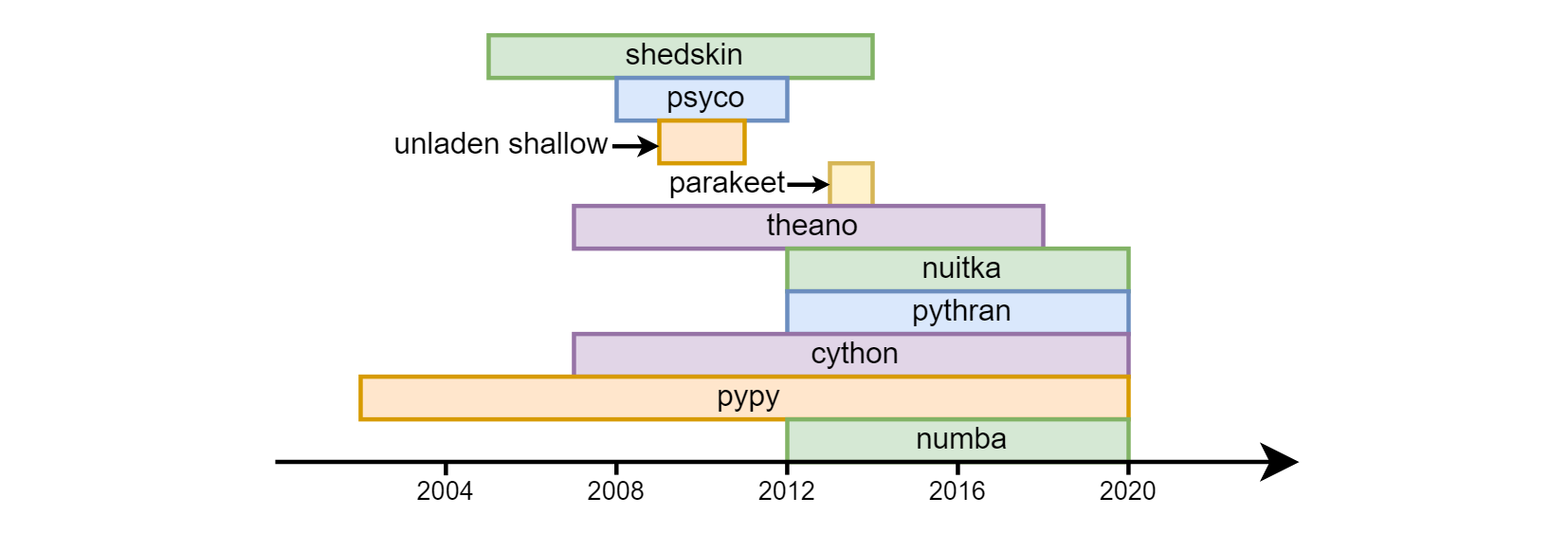
迄今为止,需求量最大的是后三个。 Cython (不要与cpython混淆)-在语义上与常规python完全不同。 实际上,这是一种独立的语言-C和python的混合体。 至于pypy (使用jit编译的python转换器的另一种实现)和numba (llvm中的代码编译库),它们采用了不同的方式。 pypy最初宣布支持所有python构造。 在numba中,他们从以下事实出发:它通常需要cpu绑定-分别进行数学计算,他们确定了与计算相关的语言部分,并开始对其进行超频,从而逐渐增加了“覆盖率”(例如,直到最近没有线路支持) ,现在她已经出现了)。 因此,不是整个程序都在numba超频,而是在单独的函数中进行超频,这使您可以将高速和向后兼容性与numba不支持的库结合起来。 在pypy和numba中都支持Numpy(有少量限制)。
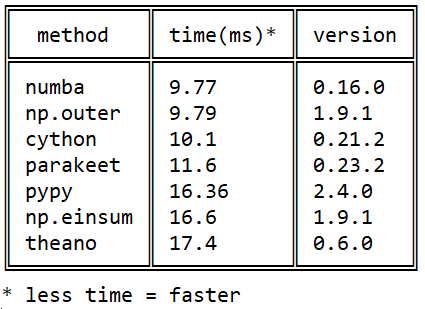 我与Numba的相识始于2015年,这个问题是关于stackoverflow的有关python中矩阵乘法速度的问题:python中的高效外部乘积
我与Numba的相识始于2015年,这个问题是关于stackoverflow的有关python中矩阵乘法速度的问题:python中的高效外部乘积
从那时起,每个库中发生了许多事件,但是关于numba / cython / pypy没有发生numba变化: numba通过使用本机处理器指令( cython不能jit)和pypy来取代cython ,这是因为llvm字节码的执行效率更高。
Numba在工作(处理高光谱图像)和教学(数值积分,求解微分方程)方面对我派上用场。
如何设定
几年前,安装出现问题,现在一切都解决了:它通过pip install numba和conda install numba都安装得同样好。 llvm已收紧并自动安装。
如何加快
要加速功能,必须在定义njit装饰器之前输入它:
from numba import njit @njit def f(n): s = 0. for i in range(n): s += sqrt(i) return s
加速40倍。
需要根,因为否则numba会识别算术级数的总和(!)并在恒定时间内对其进行计算。
吉特vs恩吉特
以前,只有@jit模式(而不是@njit ) @njit意义。 关键是在这种模式下,您可以使用numba不支持的操作:高速numba达到第一个这样的操作,然后减慢速度,直到函数执行以正常的Python速度继续进行,即使函数中没有遇到更多``禁止''的情况(所谓的对象模式),这显然是不合理的。 现在@jit逐渐放弃@jit ,始终建议使用@njit(或使用完整格式的@jit(nopython=True) ):在这种模式下,numba会在这种情况下发誓例外-最好重写它们,以免失去速度。
什么可以加速
在超频功能中,只能使用python和numba功能的一部分。 关于数字,所有运算符,函数和类都分为两部分:数字“理解”的部分和“不理解”的部分。
numba文档中有两个这样的列表(带有示例):
从这些列表中值得注意的是:
- numba可以“理解” Python列表,并在numpy“不理解”的末尾添加快速(摊销O(1))(尽管只有相同类型元素的同类),
- 不在基本python中的numpy数组。 也了解
- 元组:它们可以像普通的python一样包含不同类型的元素。
- 字典:numba拥有自己的类型化字典实现。 所有键都必须是相同的类型,与值完全相同。 python dict无法传递给numba,但是numba
numba.typed.Dict可以在python中创建并从numba转移到/从numba转移(而在python中,它的运行速度比python慢一点)。 - 但是,最近的str和byte只能作为输入参数创建(还好吗?)。
她根本不了解任何其他图书馆(尤其是scipy和pandas)。
但是,即使她理解的那部分语言也足以使numba主要关注的科学应用程序的大多数代码超频。
重要!
在超频功能中,只能调用超频功能,而不是超频功能。
(尽管可以从超频而不是超频调用超频功能)。
全球
在超频函数中,全局变量变为常量:在编译函数时,它们的值是固定的( 示例 )。 =>不要在超频功能中使用全局变量(常量除外)。
签名
在每个函数的编号中,映射了一种或几种类型的输入和输出参数,即 签名。 首次调用该函数时,将生成签名并自动编译相应的二进制函数代码。 与其他类型的参数一起启动时,将创建新的签名和新的二进制文件(保留旧的二进制文件)。 因此,从使用这些类型的参数的第二次运行开始,每个签名的执行速度都会发生“退出模式”。 所以要么
- 通过启动较小尺寸的输入数组来“预热缓存”,或者
- 指定参数
@jit(cache=True)将编译的代码在后续程序启动期间自动加载保存到磁盘上(尽管实际上今天的首次启动仍然比后续启动慢一些,但比不使用cache=True要快) 。
还有第三种方式。 签名可以手动设置:
from numba import int16, int32 @njit(int32(int16, int16)) def f(x, y): return x + y >>> f.signatures [(int16, int16)]
当您使用装饰器中指定的签名运行函数时,第一次运行将很快:编译将在python看到函数定义的那一刻发生,而不是在第一次开始时发生。 可以有几个签名,其顺序很重要。
警告:这最后一种方法不安全。 numba的作者警告说,用于指定类型的语法将来可能会更改,在这方面,不带签名的@jit / @njit是更安全的选择。
f.signatures仅在python发现签名时才开始显示签名,也就是说,在第一个函数调用之后,或者如果手动设置了签名。
除了f.signatures还可以通过f.inspect_types()查看签名-除了输入参数的类型之外,此函数还将显示输出参数的类型以及所有局部变量的类型。
除了输入和输出参数的类型之外,还可以手动指定局部变量的类型:
from numba import int16, int32 @njit(int32(int16, int16), locals={'z': int32}) def f(x, y): z = y + 10 return x + z
整型
在numba中,整数没有像“简单” python中那样长的算术运算符,但是存在从int8到int64的各种宽度的标准类型(文档中的类型表 )。 还有int_ (和float_ )类型,使用这些类型,您可以使numba选择最佳的字段宽度(从她的角度来看)。
类
通常支持类(@jitclass),但是到目前为止,它是实验性的,因此最好避免现在使用它们(根据我的经验,现在,使用它们比没有使用它们要慢得多)。
自定义dtypes
Numba支持numpy的类的某种替代方法-结构化数组,或者换句话说,自定义dtype。 它们以与常规numpy数组相同的速度工作,它们索引起来稍微方便些(例如a['y2']比a[3]更具可读性)。 有趣的是,在numba中,与numpy不同,允许使用更简洁的a.y2以及常规语法a['y2'] 。 但是,总的来说,它们在numba中的支持还有很多需要改进的地方,并且在numba中使用它们进行的某些操作(甚至在numpy中是显而易见的)记录得非常简单。
显卡
它能够在GPU上执行超频代码,并且与同一个代码(例如pycuda或pytorch)形成对比,不仅在nvidia上,而且在amd'shnyh卡上。 到目前为止,我对此所知甚少。 这是一篇关于Habre 2016 Python和C语言中GPU计算性能比较的文章。 在那里,获得了与C相当的速度。
提前编译
numba中有一种正常的(即不是jit)编译( 文档 )模式,但是这种模式不是主要的模式,我不理解。
自动并行化
有些任务(例如,将一个矩阵乘以一个数字)自然会并行化。 但是有些任务的执行不能并行化。 使用@njit(parallel=True)装饰器@njit(parallel=True) numba会分析超频函数的代码,找到无法独立并行化的部分,并在不同的CPU内核上同时运行它们( 文档 )。 以前,您只能使用@vectorize ( documentation )手动并行化函数,这需要更改代码。
在实践中,它看起来像这样:add parallel=True ,测量速度,如果幸运的话,结果更快-我们将其放慢,将其删除。 (**更新如本文第二部分的注释所述,此标志有很多未解决的错误)
GIL发布
可以并行执行以@jit(nogil=True)装饰@jit(nogil=True)并在不同线程中运行的函数。 为避免争用情况,必须使用线程同步。
文档
Numbe仍然缺乏明智的文档。 她在,但并非一切都在她里面。
最佳化
手动优化代码时存在一些不可预测性:非pythonic代码通常比pythonic运行更快。
对于对此主题感兴趣的人,我可以为scipy 2017会议推荐numba大师班级的视频 (github上有源代码 )。 它确实很长并且部分过时(例如,已经支持行),但是它有助于获得一个大致的概念:特别是关于pythonic / unpythonic, jit (parallel = True)等。
在第二部分中,我们将考虑使用本文开头提到的代码中的numba。