这是有关numba的文章的第二部分。 首先是历史介绍和简短的numba使用手册。 在这里,我介绍了Haskell文章“ 比C ++更快的速度;这是经过修改的任务代码” 。 速度比PHP慢 (它比较了一种算法在不同语言/编译器中的性能),并提供了更详细的基准,图表和说明。 我马上说,我看到了这篇文章, 哦,这个缓慢的C / C ++ ,最有可能的是,如果您对C代码进行了这些更改,图片也会有所变化,但是即使在这种情况下,即使在此版本中,python仍然可以超过C的速度本身就是了不起的。

用numpy数组替换了Python列表(因此将v0[:]替换为v0.copy() ,因为在numpy中a[:]返回view而不是复制)。
为了了解性能行为的本质,我对数组中的元素数量进行了“扫描”。
在Python代码中,我将time.monotonic替换为time.perf_counter ,因为它更准确(单调为1us相对于1ms)。
由于numba使用jit编译,因此这种编译应该在某天进行。 默认情况下,它是在第一次调用该函数时发生的,并且不可避免地会影响基准测试的结果(尽管如果花了三个启动时间,您可能不会注意到这一点),并且在实际使用中也会感觉到。 有几种方法可以解决此现象:
1)将编译结果缓存到磁盘:
@njit(cache=True) def lev_dist(s1: AnyStr, s2: AnyStr) -> int:
然后将在程序的第一次调用时进行编译,并在随后的调用中将其从磁盘中拉出。
2)注明签名
编译将在python解析函数的定义时进行,并且第一次启动已经非常快。
原始字符串被传输(更确切地说是字节),但是最近已添加了对字符串的支持,因此签名非常怪异(请参阅下文)。 签名通常写得更简单:
@njit(nb.int64(nb.uint8[:], nb.uint8[:])) def lev_dist(s1, s2):
但随后您必须提前将字节转换为numpy数组:
s1_py = [int(x) for x in b"a" * 15000] s1 = np.array(s1_py, dtype=np.uint8)
或
s1 = np.full(15000, ord('a'), dtype=np.uint8)
您可以按原样保留字节并以这种形式指定签名:
@njit(nb.int64(nb.bytes(nb.uint8, nb.1d, nb.C), nb.bytes(nb.uint8, nb.1d, nb.C))) def lev_dist(s1: AnyStr, s2: AnyStr) -> int:
uint8中字节和numpy数组的执行速度(在这种情况下)是相同的。
3)预热缓存
s1 = b"a" * 15
然后,将在第一个调用上进行编译,而第二个调用将已经很快。
C代码(clang -O3 -march =本机) #include <stdio.h> #include <stdlib.h> #include <string.h> #include <time.h> static long lev_dist (const char *s1, unsigned long m, const char *s2, unsigned long n) { // unsigned long m, n; unsigned long i, j; long *v0, *v1; long ret, *temp; /* Edge cases. */ if (m == 0) { return n; } else if (n == 0) { return m; } v0 = malloc (sizeof (long) * (n + 1)); v1 = malloc (sizeof (long) * (n + 1)); if (v0 == NULL || v1 == NULL) { fprintf (stderr, "failed to allocate memory\n"); exit (-1); } for (i = 0; i <= n; ++i) { v0[i] = i; } memcpy (v1, v0, sizeof(long) * (n + 1)); for (i = 0; i < m; ++i) { v1[0] = i + 1; for (j = 0; j < n; ++j) { const long subst_cost = (s1[i] == s2[j]) ? v0[j] : (v0[j] + 1); const long del_cost = v0[j + 1] + 1; const long ins_cost = v1[j] + 1; #if !defined(__GNUC__) || defined(__llvm__) if (subst_cost < del_cost) { v1[j + 1] = subst_cost; } else { v1[j + 1] = del_cost; } #else v1[j + 1] = (subst_cost < del_cost) ? subst_cost : del_cost; #endif if (ins_cost < v1[j + 1]) { v1[j + 1] = ins_cost; } } temp = v0; v0 = v1; v1 = temp; } ret = v0[n]; free (v0); free (v1); return ret; } int main () { char s1[25001], s2[25001], s3[25001]; int lengths[] = {1000, 2000, 5000, 10000, 15000, 20000, 25000}; FILE *fout; fopen_s(&fout, "c.txt", "w"); for(int j = 0; j < sizeof(lengths)/sizeof(lengths[0]); j++){ int len = lengths[j]; int i; clock_t start_time, exec_time; for (i = 0; i < len; ++i) { s1[i] = 'a'; s2[i] = 'a'; s3[i] = 'b'; } s1[len] = s2[len] = s3[len] = '\0'; start_time = clock (); printf ("%ld\n", lev_dist (s1, len, s2, len)); printf ("%ld\n", lev_dist (s1, len, s3, len)); exec_time = clock () - start_time; fprintf(fout, "%d %.6f\n", len, ((double) exec_time) / CLOCKS_PER_SEC); fprintf (stderr, "Finished in %.3fs\n", ((double) exec_time) / CLOCKS_PER_SEC); } return 0; }
比较是在Windows(Windows 10 x64,Python 3.7.3,numba 0.45.1,clang 9.0.0,intel m5-6y54 skylake)下进行的:和在Linux(debian 4.9.30,python 3.7.4,numba 0.45.1, clang 9.0.0)。
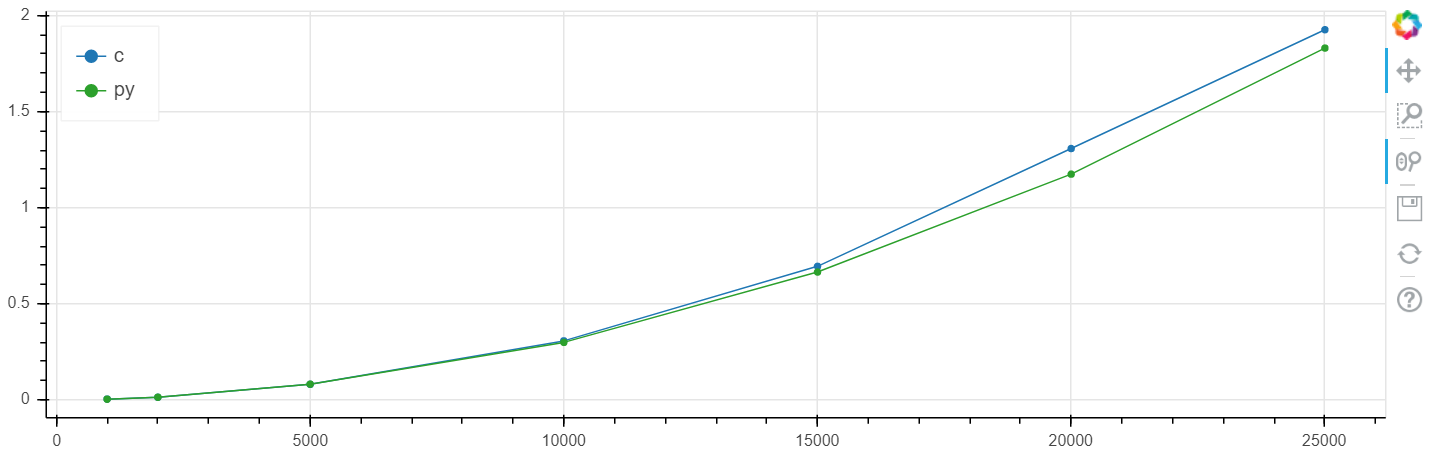
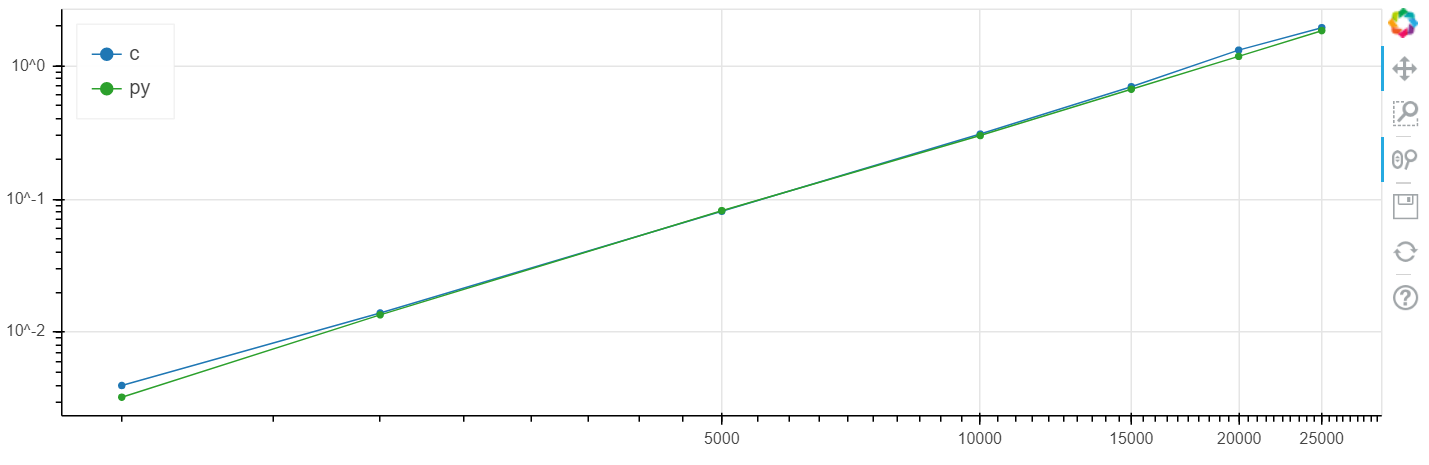
X是数组的大小,y是时间(以秒为单位)。
Windows线性比例:
Windows对数刻度:
Linux线性比例:

Linux对数刻度
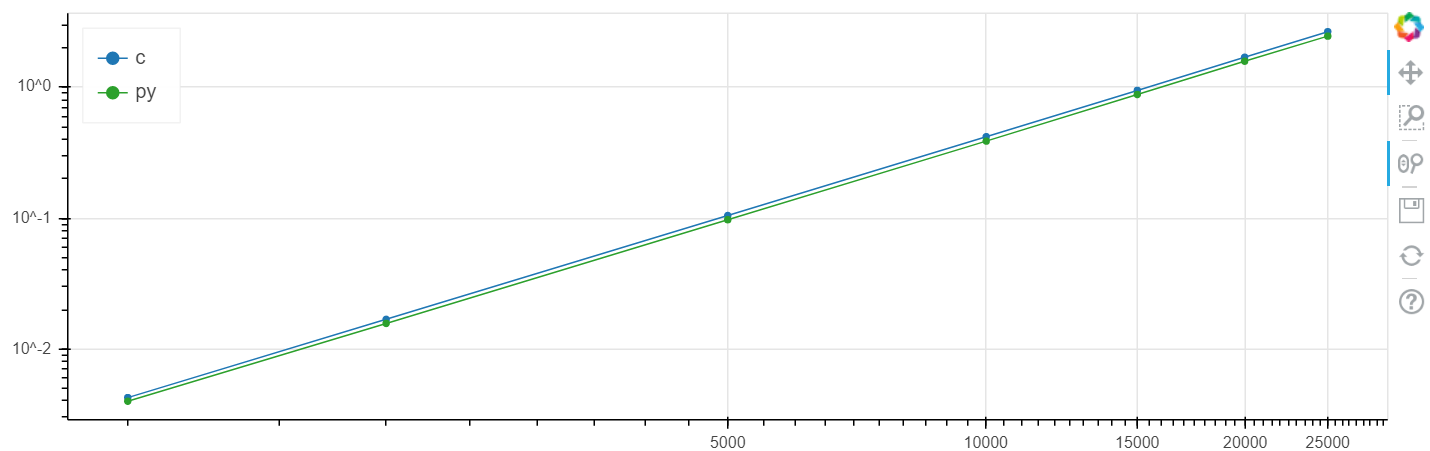
在此问题中,与clang相比,速度提高了百分之几,通常高于统计误差。
我在不同的任务上反复进行了此比较,通常,如果numba可以加速某些东西,则它可以将其加速到与速度C一致的误差范围内的速度(不使用汇编器插入)。
我重复一遍,如果您从哦对C中的代码进行更改,这种慢速的C / C ++情况可能会改变。
我很高兴听到评论中的问题和建议。
PS在指定数组的签名时,最好显式设置交替行/列的方式:
因此numba不会想到'C'(si)这个或'A'(si / fortran自动识别)-由于某种原因,即使对于一维数组,这也会影响性能,因为这有这样一种原始语法: uint8[:,:] this' A'(自动检测), nb.uint8[:, ::1]是'C'(si), np.uint8[::1, :]是'F'(fortran)。
@njit(nb.int64(nb.uint8[::1], nb.uint8[::1])) def lev_dist(s1, s2):